
文章转自知乎:CVer计算机视觉
带有ResNet-101的YolactEdge在Jetson AGX Xavier上的速度高达30.8 FPS,在RTX 2080 Ti上的速度为172.7 FPS,AP性能超强!速度是目前主流方法的3-5倍,代码于1小时前刚刚开源!
注:文末附【图像分割】学习交流群
YolactEdge: Real-time Instance Segmentation on the Edge (Jetson AGX Xavier: 30 FPS, RTX 2080 Ti: 170 FPS)

作者单位:UC Davis, 亚马逊(算是原YOLACT团队了)
代码:haotian-liu/yolact\_edge
论文:https://arxiv.org/abs/2012.12259
我们提出了YolactEdge,这是第一种竞争性实例分割方法,可以在小型边缘设备上以实时速度运行。具体来说,在550x550分辨率的图像上,带有ResNet-101主干的YolactEdge在Jetson AGX Xavier上的运行速度高达30.8 FPS(在RTX 2080 Ti上的运行速度为172.7 FPS)。
演示Demo如下:



为了实现这一目标,我们对基于图像的最新实时方法YOLACT进行了两项改进:
(1)TensorRT 优化,同时谨慎权衡速度和准确性
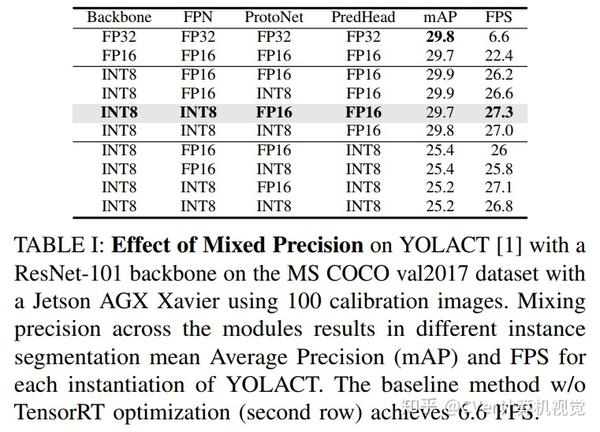
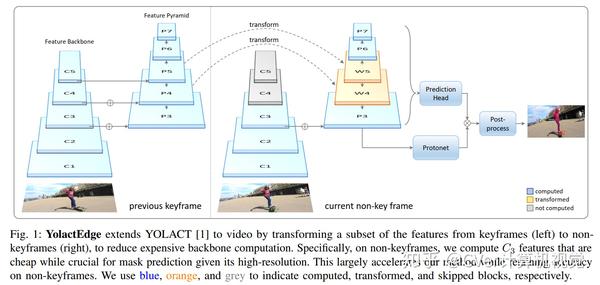
(2)利用新的特征warping模块视频中的Temporal Redundancy。
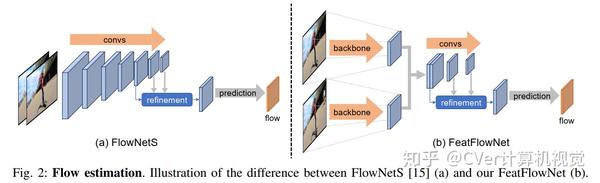
实验结果
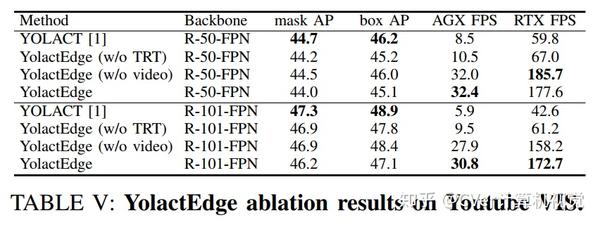
在YouTube VIS和MS COCO数据集上进行的实验表明,与现有的实时方法相比,YolactEdge的速度提高了3-5倍,同时具有极好的mask和box检测精度。 我们还进行消融研究,以剖析我们的设计选择和模块。


推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

