
本文转自:知乎
作者:金雪锋
前段时间,中科大ADSL实验室通过ResNet50和Bert-Base两个标杆模型对开源AI框架MindSpore在GPU上的训练性能进行了评测,MindSpore的表现还是很不错的,性能领先于业界主流的框架:
https://zhuanlan.zhihu.com/p/350343159zhuanlan.zhihu.com
很多人发消息问,MindSpore在昇腾上的性能好,容易理解,那MindSpore在GPU上为什么也能有如此好的性能?
项目组总结了两篇文章来解答:
- 第一篇重点讲MindSpore在GPU上的一些通用优化
- 第二篇重点讲MindSpore通过图算融合在编译器上的优化
这么分的原因是,这次评测的ResNet50与Bert-Base这两个模型非常具有代表性,不仅仅是因为应用广泛,而是这两个模型代表了框架的两种能力:
1、ResNet50有许多重型算子,对数据/计算算子以及框架的性能要求很高,计划用第一篇文章-GPU上的一些通用优化技巧来说明;
2、Bert则有许多小算子,特别考验框架的算子融合优化能力,第二篇恰好来描述MindSpore在图算融合以及算子自动生成能力。
另外,在GPU上的性能优化,MindSpore大量采用高校/伙伴贡献的Idea和代码,这里也要谢谢这些社区的贡献者。
基于GPU硬件的深度学习训练性能优化是一个端到端的系统问题,涉及到编译,执行调度,计算,通信,数据,分布式,算法等非常多的技术领域,可以从不同的角度进行切入。例如从GPU训练加速的角度考虑,可以分为GPU单卡性能优化,以及多卡上如何提升加速比;从数据和计算的角度考虑,可以分为数据预处理的优化,以及网络中算子的计算优化;另外从内存优化的角度出发,需要考虑如何降低内存以及显存的占用量,以及在运行中内存使用和管理的性能。上述每一项又会涉及到较多的技术细节问题。
本文重点从GPU算子优化,分布式多机多卡加速比的提升,以及数据与计算Pipeline并行三个视角出发,介绍神经网络在GPU上训练的通用性能优化方法。

- GPU算子性能优化
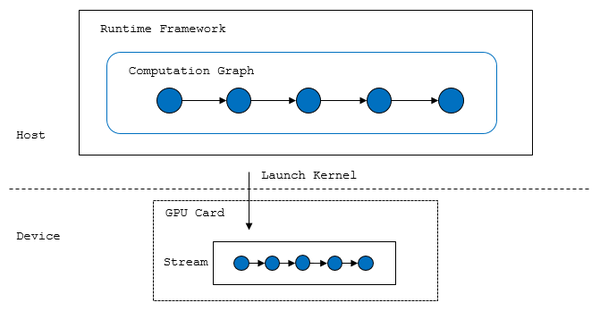
在网络训练中,占比最大的是算子的计算时间,因此算子的性能好坏对整体性能有着决定性的影响,我们知道网络中的算子在图结构上大致可以分为前向算子,后向算子,以及优化器算子三大部分,而在大多数的训练框架中,计算图中的算子在GPU上的执行会被编排成一个拓扑序,如下图所示,根据该拓扑序依次将Kernel下发到CUDA的stream中调度执行,也就意味着大多数情况下算子在GPU上是被串行执行,按照这个执行模式,在算子的性能优化上主要考虑几个方面,一个是单算子的性能要尽可能的好,另一方面是考虑算子间的融合优化,此外还要考虑提前消除不必要的算子执行。
另外在训练时我们需要考虑所使用单算子的精度,例如FP32或者FP16,而在整网训练中,通常框架会提供是否开启自动混合精度(AMP)的功能,简单来讲,网络中不同的算子使用不同的精度进行训练,在MindSpore中自动混合精度训练的详细方案可以参考:
混合精度 - MindSpore r0.5 documentationwww.mindspore.cn
使用混合精度进行网络训练时,由于相互依赖的算子之间采用不同的计算精度以及不同的format,在输入输出以及模型权重上需要做精度转换以及Tensor的转置操作,因此单纯从开启AMP的训练图结构上来说是存在很大的性能开销,而之所以采用混合精度训练,最重要的原因是Nvidia在Volta,Ampere等架构中针对FP16提供了专用的硬件计算单元TensorCore。
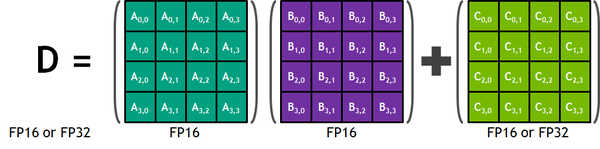
每个Tensor Core都提供一个4*4*4的矩阵处理阵列,该阵列执行以下操作D\=A*B+C,其中A,B,C和D是4*4矩阵,矩阵乘法输入A和B是FP16矩阵,而D和累加矩阵C可以是FP16或FP32矩阵,每个Tensor Core在一个时钟周期内执行64个浮点混合精度计算。Tesla V100在混合精度训练时,主要用于MatMul、Convolution、RNN、Attention等网络结构中。
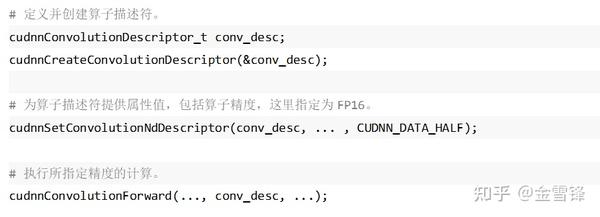
Nvidia提供了两种使用TensorCore的方式,一种是通过cuDNN、cuBLAS提供的API,例如Conv算子,可以直接指定算子精度,这种方式是主流框架包括MindSpore所使用的方式。cuDNN对所提供算子的输入Tensor和Filter数据定义了枚举类型cudnnDataType\_t,具体指包含:CUDNN\_DATA\_FLOAT、CUDNN\_DATA\_HALF、CUDNN\_DATA\_INT8、CUDNN\_DATA\_INT32等类型,分别对应FP32、FP16、INT8、INT32。仍以卷积,在使用cuDNN时通过如下步骤可以完成Conv的FP16计算:
另外一种方式是使用CUDA提供的Low-Level TensorCore编程API WMMA,其提供了一组API用于操作指定matrix的数据加载,matrix相乘以及累加操作,从而允许用户可以更加精细化的控制数据在TensorCore上的切分策略。
Tensor Core在带来大幅的性能提升同时,使用上也存在一些约束, 例如官方文档建议,Conv2D算子输入、输出Channel最好为8的整数倍(实际在MindSpore中首个Conv的输入图片Pad成为4通道);又如Tensor Core对NHWC的Tensor format性能更高,当算子输入数据为NCHW格式时,cuDNN虽然也可以自动对输入数据进行转置,但是随之也增加了额外操作的性能损失,对此不同的框架默认会采用不同的format,而一些框架也允许用户在训练时指定输入Tensor的format是NCHW或是NHWC,例如MindSpore在一些算子例如Conv或者BatchNorm的定义中提供了指定format的参数:

不同的算子采用不同的精度以及不同的format会带来转换的开销,如果不进行优化,这部分转换的开销会抵消掉TensorCore带来的硬件加速收益。训练中网络的Tensor转换来自两个部分,一个是相邻算子间的精度和format差异,上游算子的计算输出Tensor需要和下游算子输入Tensor保持同样的精度和format,如果不一致,需要执行精度Cast以及format的Transpose;另一个是模型权重的Cast以及Transpose,原因是模型的权重是框架预先在GPU显存中分配并写入,而写入的精度为FP32,format为NCHW,因此算子在读取权重参与计算时,需要按照算子预期的精度和format进行相应转换,另外一些框架采用双权重的方法避免了权重的运行时转换。
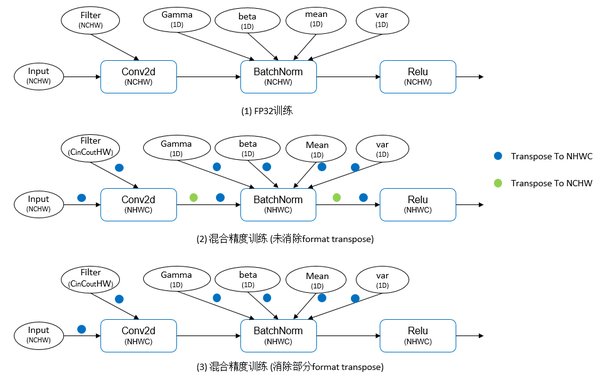
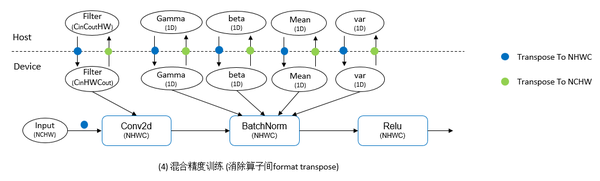
解决的方法是通过图优化的方式进行精度转换和format转置的自动消除。如下图所示,在MindSpore的训练中,网络模型权重和输入数据默认使用NCHW格式,因此在全精度训练时,算子的输入输出format保持一致,不需要做转置操作。而在自动混合精度训练中,模型权重和数据为NCHW格式,而大部分算子采用了NHWC格式,因此存在大量的转置操作,以保证算子的计算结果format与原始输入数据保持一致,而大量的转置操作会吞没TensorCore带来的硬件加速。仔细观察图结构可以发现,由于混合精度模式中网络的大部分算子都采用了NHWC格式,因此在相同format的算子间并不需要进行转置操作,既相邻且具有相同format的算子之间的两次Tranpose可以进行抵消。经过图上的转置消除优化后,在单Step训练中仅包含输入Tensor以及模型权重的转置,但这样看来还是存在较大的开销。
为了进一步消除单Step训练中的转置开销,可以想到将模型权重在GPU显存上直接按照NHWC的format进行保存,而仅在需要将权重在Host和GPU显存之间进行拷入拷出时才进行format转换,既权重在Host侧内存中采用NCHW格式保存,初始训练时拷贝到GPU显存时转换为NHWC格式,在模型训练结束后并拷贝到Host内存时,再恢复为NCHW格式,因此在训练过程中就避免了模型的权重转置开销。
上面讲了自动混合精度训练以及TensorCore的硬件加持,另外一个很重要的性能优化手段是计算图优化以及算子融合。例如在Bert的网络结构中存在大量的小算子,一方面增加了框架和设备的调度开销,另一方面也增加了内存以及内存拷贝的开销,通过算子之间的计算融合,一方面使得计算中间数据直接在SM内的Register中完成计算,减少对Global Memory的读写次数,大幅提升算子性能;另外一方面也可以减少运行时的调度开销,并给nvcc编译器执行低层次优化提供了空间。在MindSpore中从两种方式探索解决图优化和算子融合的问题,一个是自动优化方式,在MindSpore中叫做图算融合+AKG (Auto Kernel Generator),可以根据指定Pattern自动完成图算融合,有关AKG的技术细节可以参考:https://github.com/mindspore-ai/akg。另外一种方式是手工融合优化,下面我们以ResNet50为例,介绍几种手工融合的常见场景,在ResNet50中存在一种残差结构,称为Residual Unit,其中一种结构如下图所示:
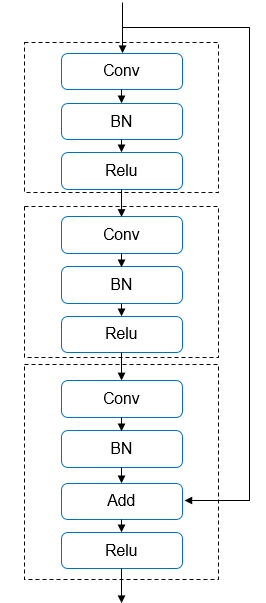
这个Residual Unit在网络中重复出现,其中Conv, BN和Relu算子在cuDNN中都有高性能的实现,进一步查看cuDNN的API手册,可以发现cuDNN中BN算子cudnnBatchNormalizationForwardTrainingEx已经为这种残差结构做了特殊的优化,算子API如下所示(部分参数省略):
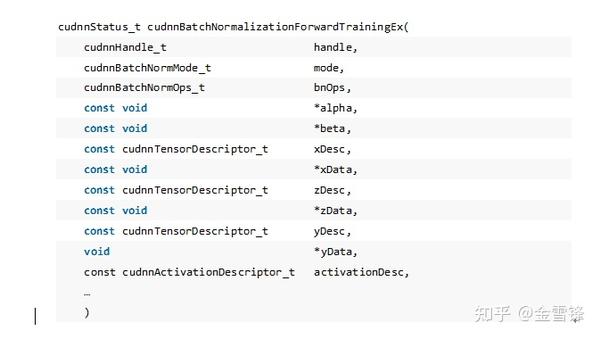
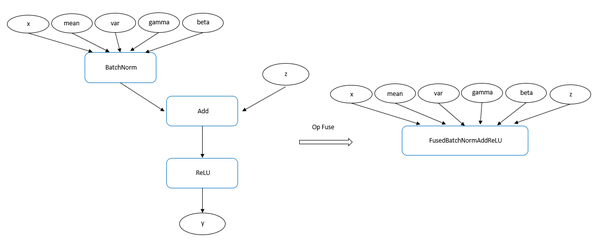
其中参数xData,yData分别表示BN算子的输入和Relu算子输出,而zData是cuDNN为Residual Unit结构中的Add算子单独提供的实现,目的是将BN、Add算子融合起来,activationDesc可以将激活函数也和BN融合起来,最后完成了BN、Add、Relu三个算子的融合,而在MindSpore中对应的Kernel实现为FusedBatchNormReLU算子,这样就避免了BatchNorm和Add计算的中间结果保存和加载操作。
上面介绍BN+Add+Relu的融合属于简单直接调用cuDNN库函数既可实现,稍微复杂一些的场景就需要自己来实现了,下面我们再介绍两个手工实现融合的例子。如果网络训练中使用了自动混合精度,以及权重正则化,那么在网络中的优化器算子附近会出现precision cast、loss scale、weight decay,以及optimizer这么几个算子,现在我们考虑可以把这四个算子融合起来,新创建一个叫做FusedWeightScaleOptimizer的新融合优化器算子。可以看到将四个算子融合为单算子后,至少可以获得在运行时减少三次kernel下发开销的收益。
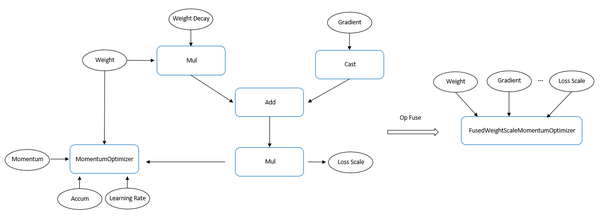
上述例子属于典型的相邻算子融合,此外还有一种非相邻算子的融合,典型的有多优化器的融合。例如在ResNet50网络中有上百个优化器算子,这些优化器算子之间并没有直接的数据或执行的依赖关系,只要输入的梯度被相应的反向算子计算出来,该优化器算子既可执行,因此可以将多个优化器算子进行融合,进一步降低执行链路上的开销。
除了计算上的优化,计算过程中对于设备存储的高效使用也是性能优化的重要因素,GPU上的存储类型有HBM、Shared Memory、各级Cache以及Register,而不同存储类型的访存带宽存在很大的差异,例如在Tesla V100上HBM2, L2 Cache, Register的带宽分别为900G/Sec, 2155G/Sec和>20000GB/Sec。在Kernel中合理利用这些快慢存储,有助于提升算子的性能,例如对于Shared Memory,在性能上和L1 Cache接近,在提供更高的带宽和更低的延迟的同时,还可以提供显式编程接口,为开发者提供灵活的使用方式。而在Kernel访问Global Memory时,数据会经由L1/L2 Cache进行缓存,通常是以128字节或者32字节内存事务来实现,具体是由GPU架构、访问类型和编译选项共同决定的。以L1 Cache为例,一行L1 Cache是128字节,它映射到Global Memory中一段128字节对齐的地址空间。如果Warp中的每个线程访问4字节的数据,Warp中的首个线程访问的地址是128字节对齐的,并且全部32个相邻线程访问的连续的地址时,Warp可以通过一次内存事务读取128字节的数据。
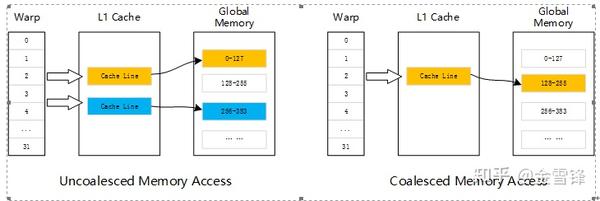
以Exp算子为例,通常执行框架在分配设备显存时会考虑对齐,确保分配的内存地址是字节对齐的,与此同时,算子在执行计算时,会按照顺序对Input和Output数据进行读写,以提升内存访问效率。

Global Memory是GPU设备上空间最大的存储介质,对此CUDA提供了cudaMalloc和cudaFree来申请和释放该区域存储,实际上这两个API的使用开销还是比较大的,业界普遍采用框架自身进行管理,既采用二次分配的方案,而该方案又可以分为动态和静态两种思路。静态分配是依据计算图的结构以及算子之间的数据依赖关系提前进行分析,编排分配,训练过程中没有实际的物理或逻辑上的显存申请和释放发生;动态分配是采用内存池的方式,类似操作系统对于物理内存的管理机制,好处是不用提前根据模型进行编排,使用更加灵活,例如在动态图的场景下没有办法针对计算图进行提前的编排,但是在训练过程中依然需要显示执行逻辑上的申请和释放操作,依然会有轻微的开销。
- 多机多卡性能优化
使用稍大规模的数据集进行训练以及在实际的生产环境中, 经常会使用到GPU多卡的数据并行方法对训练进行加速, 而AllReduce是当前广泛使用的一种多卡训练算法,在GPU上的NCCL集合通信库中提供了实现,而后在Horovod等主流深度学习框架中被广泛地使用。
相较于单卡训练,多卡数据并行训练在计算图结构上的差异主要是引入了AllReduce通信算子,而如上所述,在GPU上训练时通常将计算图按照依赖关系进行拓扑排序,排序后单卡和多卡数据并行的计算拓扑图如下所示:
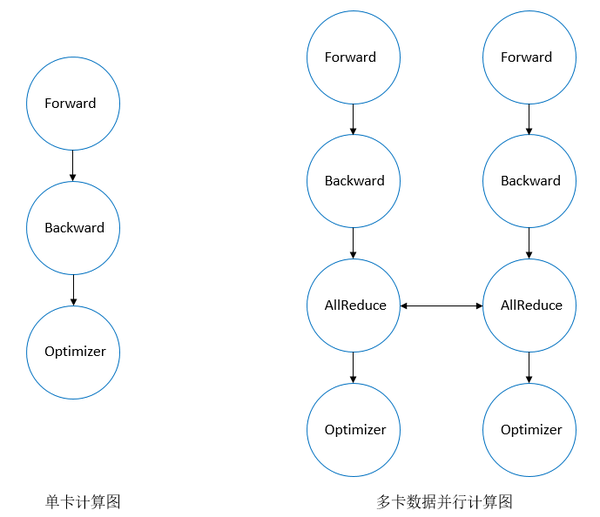
单卡执行训练拓扑图由正向算子, 反向算子以及优化器组成, 而多卡数据并行主要引入了用于多卡间梯度同步的AllReduce算子。
如果直接按照计算图的拓扑序列执行, 整个执行过程将严格按照串行执行,导致了拓扑图中所有的计算和通信相互等待. 而计算和通信对于物理资源的诉求却并没有直接的竞争, 如果能够将计算和通信算子并行执行, 可以对整体训练起到加速的效果. 这便是GPU多卡数据并行训练中计算/通信并行加速的基本思路。
算子间的并行执行在GPU设备上是通过Multi Stream来实现,有关CUDA提供的Stream以及Multi-Stream的并发和同步机制的详细解释可以参考Nvidia官方的介绍。
虽然CUDA为算子间并行提供了Multi Stream机制,具体神经网络训练中的并行控制逻辑在不同系统上仍有不同的算法以及工程实现方式, 以Horovod为例,Horovod以Tensor Fusion为核心概念来解决计算和通信的并行问题。如下图所示,在训练过程中,其中一个训练进程充当了协调者的角色,其余训练进程则通过协调者达成何时真正开始启动执行AllReduce操作,而在正式启动AllReduce通信的时候,通信的参与方实际进行交换的是内部通过Buffer缓存的一组梯度数据,这组梯度数据通过一次或多次通信完成了AllReduce计算过程,而这一通信过程和部分反向算子可以并行执行,从而将通信的时间隐藏在了计算时间内,缩短了端到端的训练时间。
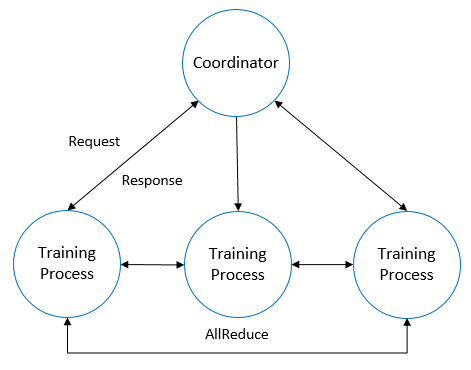
通过GPU Multi-Stream实现计算算子和通信算子的多流并行上,需要考虑两个维度的控制,一个是总共需要多少Stream,另一个是单次AllReduce通信的数据量如何切分,或者说通信和计算如何做到最大程度的交叠。
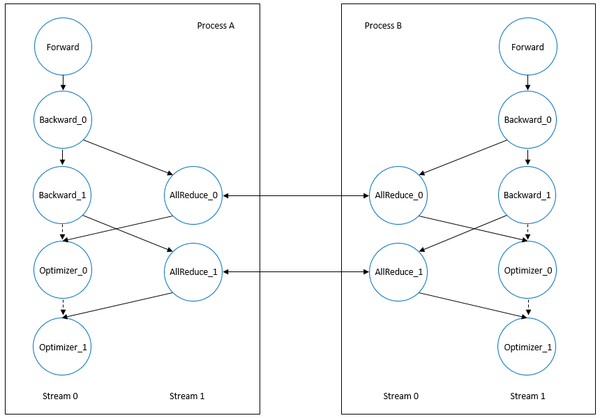
上面展示的是两个训练进程之间计算、通信如何做到基本的并行,这里描述的是使用双流的场景,其中正向算子,反向算子以及优化器使用了stream 0, 集合通信算子使用stream 1。从图上可以容易看出Backward\_1和AllReduce\_0可以实现并行执行,而Optimizer\_0和AllReduce\_1同样可以实现并行执行。然而这样仅仅是理论上的理想状况,实际训练时的场景要复杂一些,例如需要按照什么样的大小来对多个Backward和AllReduce算子进行切分,这里又涉及到物理上使用的计算设备的性能以及网络带宽的大小;Backwark\_1和AllReduce\_0的执行时间能够完全重叠的前提是Backward\_1在GPU上的算子执行时间和AllReduce\_0的通信时间要大致相当;以及stream 0和stream 1之间同步的开销,多个AllReduce算子能否再拆分到多个stream进行并行加速等。
系统实现上,MindSpore通过自动并行机制对计算、通信并行逻辑提供了更细粒度和更灵活的控制,开放Python层API允许用户手动配置AllReduce算子的切分策略,进行精细化的性能调优。
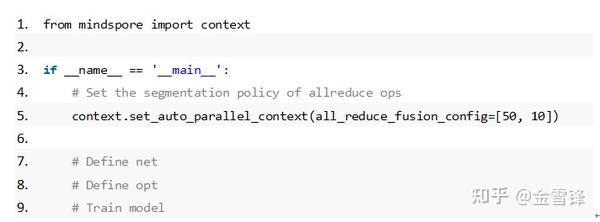
上面展示的代码片段中,一共包含60个AllReduce算子,按照配置所示切分、融合成为了两个AllReduce算子,即可与对应的反向算子形成并行关系。这样的方式虽然能够找到较优的并行时序,在实际生产中需要大量的反复调试,另一个自然的思路是做自动切分融合,然而如上文所述,达到理想的并行效果,不但需要考虑模型自身的特点,例如梯度的数量,大小等,还需要考虑实际的物理运行环境,包括单机以及分布式环境,因此自动切分并达到最优性能的方式需要考虑较多的影响维度,MindSpore目前也正在探索和尝试自动切分的技术方案。
多卡AllReduce并行加速的技术手段, 除了考虑计算、通信并行之外, 还有一些性能提升的思路,例如梯度的量化、压缩等技术也值得关注,并且随着底层计算、网络等硬件的创新,整体的多卡训练性能会持续提升。
- 数据计算并行优化
训练数据作为训练任务的输入, 对深度学习训练任务的整体性能起到了决定性的作用. 神经网络训练中数据处理的逻辑较为复杂,涉及数据的预处理以及数据增强, 而大量的训练数据因为物理内存大小的限制, 经常无法完整加载进入内存, 需要磁盘做为辅助存储, 因此训练任务中数据模块对于计算和IO都会产生较大的压力。为了达到整体的训练性能最优,需要网络计算和数据处理形成相互配合的稳定流水线,而为了达到两者协调的配合,要求对所处环境中各个维度的物理资源进行合理的分配, 避免数据和计算相互竞争物理资源。
MindSpore也为数据预处理与数据增强提供了一套Pipeline子系统,基于数据处理的Pipeline架构,提供了多种数据处理操作,包括复制、分批、洗牌、映射,入下图所示:

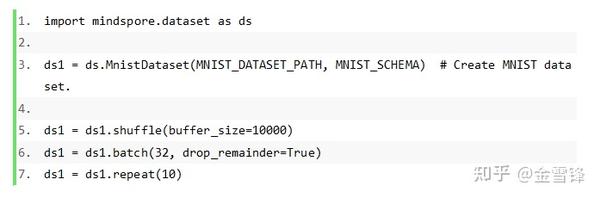
如下示例中,读取MNIST数据集时,对数据进行shuffle、batch、repeat操作,具体先对数据进行混洗,再将每32条数据组成一个batch,最后将数据集重复10次。有关MindSpore数据处理更详细的设计思路可以参考另外一篇文章:AI框架中数据处理的挑战与解决思路。
从训练整体性能的角度考虑,数据处理系统设计有两个核心层面的诉求,其中一个诉求点是数据处理需要和计算性能进行匹配,具体讲就是数据处理的速度不能慢于计算的速度,自身需要一个高性能的Pipeline;另外一点就是数据处理所占用的物理资源尽可能的低,尽量不影响到计算的性能,试想如果单纯为了追求数据处理的高性能而占用了全部的计算资源,整体训练过程的性能最终也会受到影响。在追求高性能的同时也要最大程度地降低系统的资源使用,对于系统的设计和实现都提出了较大的挑战。
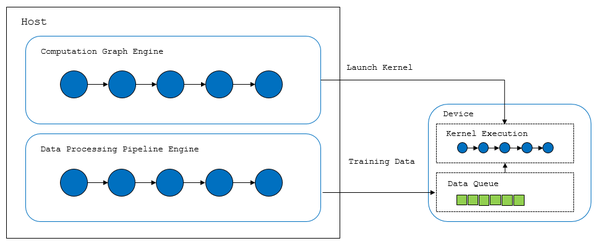
如上所示为MindSpore的数据与计算部分如何配合工作的示意图,为了解决数据处理自身的性能问题,在数据处理的各关键环节中都尽量的采用了多线程来并行处理任务;而在数据处理与计算进行交互上,采用了在设备侧的显存上开辟一个存放已处理好的训练数据的数据队列,数据处理模块与计算模型分别各自异步的向队列中写入以及读取数据,只有满足数据写入的速度不低于训练计算的速度,系统整体训练性能才有能达到最优的可能性。
另外一个提升数据传输速度的手段是使用CUDA提供的Pinned Memory。Host内存是默认是可换页的,意味着操作系统可以将其换出到磁盘上,Host的虚拟地址和物理地址的映射关系存在不确定性,导致可换页内存无法被GPU直接访问。对此,CUDA允许将Host内存进行页锁定,从而允许DRAM和GPU之间通过DMA控制器进行搬移,提升传输性能。
深度学习框架以及训练性能的优化是一个非常复杂的系统工程,需要精巧的设计以及细致的实现,虽然经过了几代系统的演进,至今在诸如编译器优化,高性能计算系统,大规模数据处理,以及硬件加速上的发展仍然日新月异,这些都为AI的快速发展提供了源源不断的动力支持。
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

