
转载于:知乎
作者: 金雪锋
IOS论文出自MIT的韩松实验室,第一作者为Yaoyao Ding, 这是他在韩松实验室实习时的成果。现有的CNN推理加速技术关注于优化算子内部的并行度,但是随着硬件性能快速提升,现有单算子顺序执行的调度并不能充分运用硬件算力,硬件较多算力处于空闲状态得不到有效利用。作者研究利用多算子的并行执行技术以加速CNN推理的方法,并提出了算子间并行调度器- IOS,通过一种新的动态调度的算法实现了自动化的多算子的并行执行。实验数据表明,在新式的CNN基准网络中,IOS比现有最好的算子库(例如TensorRT)性能提升1.1倍到1.5倍。 相关的实验代码已开源(https://github.com/mit-han-lab/inter-operator-scheduler)。
背景和动机
CNN近年来不断的在各种任务上刷新最好成绩,当然模型也变得更复杂,所需算力也在不断增加,如何实现CNN模型的高效推理成为在实际部署中的迫切需求。并行可以优化推理效率,Tensorflow和Pytorch均使用了算子内并行。但随着高性能硬件的快速迭代,仅仅算子内并行难以高效利用硬件资源。为了充分利用硬件算力,最近已有多项工作研究了多算子并行技术,这些并行方法通过启发式算法找到多个算子,并将这些算子并发执行。例如MetaFlow [2]。但是目前的启发式算法多关注于局部并行性的优化,得不到全局最优调度。例如图1所示的CNN,传统的顺序调度会分为四段,每段执行一个卷积算子;而基于贪心的调度会将卷积算子[a], [c], [d]并行起来,如图1-2,性能提升14%, 同时IOS得到的调度如图1-3所示,性能提升22%。示例中,贪心调度的方法不能得到最优效果有两个原因。首先,基于贪心的调度会将更多的算子放在早期执行段而较少的算子放在后续段,导致后续段的资源利用率低;其次太多的算子同时执行可能会导致资源竞争,从而导致性能下降。相比IOS调度,贪心调度的第一段存在资源竞争,第二段存在资源利用率低。
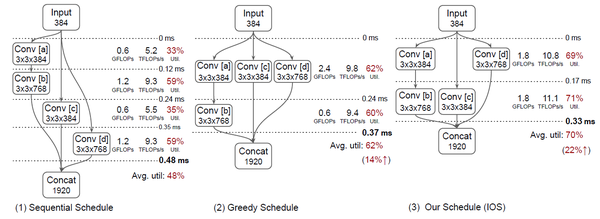
图1 顺序调度,贪心调度和IOS调度示意图
针对各种不同的CNN结构、运行硬件和推理配置,仅仅依靠手工和人力难以设计出所有场景下的高效调度。作者提出了IOS,一种利用多算子并行加速CNN推理的调度算法。IOS使用了动态规划算法以较小的搜索成本在可行的调度空间中得到一个高度优化的调度。IOS论文主要有以下三个贡献:
- 作者指出来CNN推理的一个主要瓶颈:现有的算子内并行不能充分利用现代硬件的高并行性,特别是近年的新式的多分支CNN模型的推理。
- 作者提出了一种动态规划算法以寻找高度优化的调度以提高多算子并行。这种算法是平台无关的,可以作为通用技术应用于主流的深度学习平台TensorFlow和TVM。
- 作者将IOS应用于多种硬件和推理配置,结果表明IOS调度的推理速度比现有的深度学习库提升1.1倍至1.5倍。
具体方法
- 问题抽象
计算图: CNN网络可以抽象为计算图 G = (V,E), CNN计算图是有向无环图,其中V表示算子集合,而E表示算子之间的边集合,边代表算子之间的数据依赖。图2-1就是一个简单的CNN网络对应的计算图。
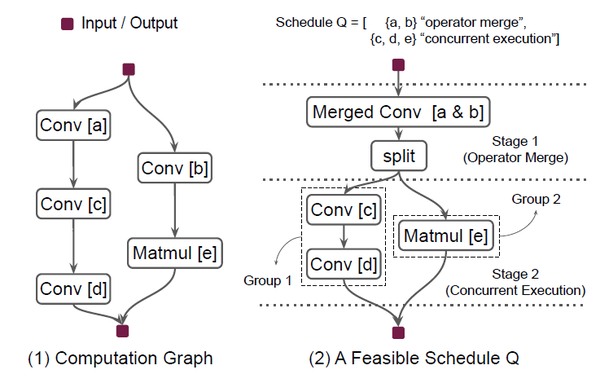
图2 计算图与可行调度
段:为了充分利用CNN结构中的多算子间并行,作者将CNN计算图分为多段,各段之间按序执行,而在相同段的多个算子会根据相应的并行策略执行。图2-2展示了一个可行的调度策略, 计算图被分为两段,第一段包含算子[a & b],第二段包含算子[c], 算子[d]和算子[e]。
并行策略:作者定义了两种并行策略:算子合并和并发执行,ISO会考虑这两种并行策略,并自动选择对当前段更有效率的并行策略。并行策略选择时会综合考虑算子类型,输入算子形状和当前硬件设备等因素。算子合并是将具有相同类型算子合并为一个算子,算子超参数可以不一样。例如,具有相同步长不同卷积核尺寸的两个卷积算子可以合并,小卷积核可以通过填充0去适配大卷积核,这样就可以将这两个卷积核堆叠在一起。如图2-2,如果卷积[a]有128个3*3卷积核而卷积[b]有256个3*3卷积核,就可以使用算子合并,将两个算子的卷积核堆叠起来,用具有384个3*3的卷积核的合并卷积[a&b]替换卷积[a]和[b], 同时也需要增加split算子以分离得到卷积[a]和[b]的输出。算子合并可以增加并行性,也可以较少存储的访问。并发执行是将同一段的算子划分为多个组,有依赖的算子会被划分在同一组,不同组的算子可以并发执行。如图2-2所示,第二段的三个算子被分为两组,一组包含卷积[c]和卷积[d], 另一组包含矩阵乘算子[e]。
- IOS算法
IOS采用一种动态规划的算法以搜索最优的算子调度。
给定计算图G的顶点集合V,V的一个子集 S会将顶点集分为V – S和S,如果V – S和S之间的所有边E’都是从子集V – S指向子集S, S即称为V的一个尾段(Ending)。如图3-2所示,S’是顶点V的一个尾段,而图3-3中S’就不是一个尾段,3-4表示了将整个计算图按照尾段递归划分的方法进行了段划分。
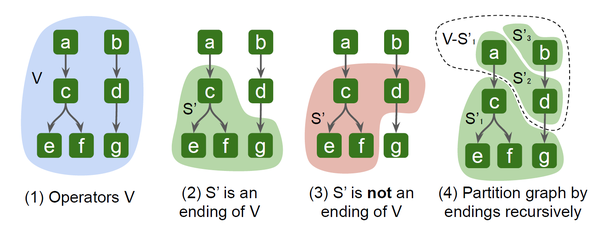
图3 计算图,尾段,非尾段,尾段迭代划分
IOS采用动态规划的方法迭代的搜索最优尾段,直到未调度的顶点集为空。cost[S]表示顶点集S的最优调度的延迟,S’表示顶点集S的一个尾段,那么IOS的动态规划算法的状态转移如下公式表示, 即S的最优延迟是所有可能尾段S’的延迟和剩余顶点集S-S’的最优延迟之和的最小值。

具体来说, (1) IOS算法会首先枚举调度中所有可能的算子段,并预估出算子段的延迟,每个可能的算子段都有两种候选的并行策略:算子合并和算子并发,IOS会进行预估并选择延迟最小的并行策略;(2) 根据预估数据,选择出延迟之和最小的最优尾段,同时也可得到除去尾段之后的前段,然后迭代的为前段选择出最优调度。如下图4所示。图4-1描述了原始的计算图,4-2列出了所有的可能的前段和前段对应的最短延时,依据动态规划可以得到最优的调度如4-3和4-4所示,即首先得到最优尾段 {b, c}, 然后得到 剩余子集的最佳尾段 {a}, 此时队列Q为空,调度结束。为了避免候选的算子段枚举及延迟预估导致算法时间开销长,作者还在候选算子段生成过程中使用了剪枝算法,只有满足特定的条件才会被视为有效的候选段。
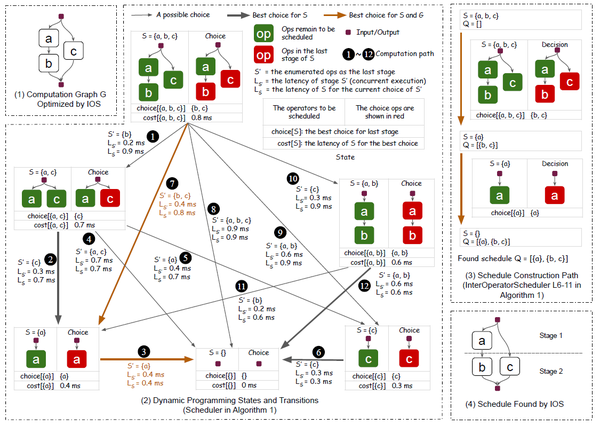
图4 基于动态规划的IOS调度示例
实验结果
IOS属于框架不敏感算法,作者基于python实现了IOS调度算法,并使用C++实现了执行引擎。该执行引擎是基于商业库cuDNN,也支持算子间的并行。为了支持多组算子并发执行,IOS将不同组的算子分配到不同的CUDA流,当有充足的执行资源时,不同的CUDA流会并发执行。实验中采用了cuDNN 7.6.5, CUDA 10.2, NVIDIA driver 450.51.05, 并与 TensorRT 7.0.0.11 和 TVM 0.7 做了对比。作者在实验中选取了四个新式的CNN网络: Inception V3, RandWire, NasNet-A, 和SqueezeNet。 下表1列出了实验网络的基本模块的数量,算子数和主要的算子类型。由于一些CNN网络具有较少的多算子并行的场景,比如ResNet-50和ResNet-34, IOS只能取得2%和5%加速,故没有针对这些网络做详细评估。根据选定的剪枝参数,Inception V3 和 SqueezeNet的IOS耗时少于1分钟,Randwire和NasNet耗时在90分钟以内。
表1 实验网络
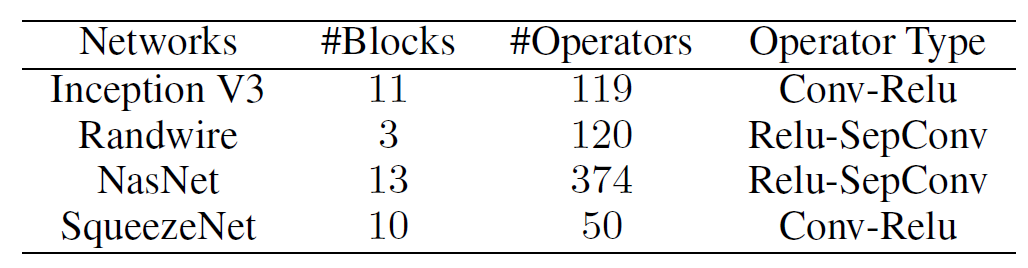
图5列出了五种不同的调度方法的吞吐量的对比,其中吞吐量数据按照最佳吞吐量做了归一化处理。五种调度方法包括:顺序调度(Sequential schedule),贪心调度(Greedy),只使用算子合并的IOS调度(IOS-Merge),只使用算子并行的IOS调度(IOS-Parallel),和择优使用算子合并和算子并行的IOS调度(IOS-Both)。从图5可看出,IOS-Both调度方法明显优于其他四种调度,贪心调度在Rand-Wire和NasNet上效果不错,但是在SqueezeNet上因为同步开销造成性能下降。IOS-Both因为同时考虑了两种并行策略,其优化效果好于只考虑一种并行策略的IOS-Merge或IOS-Parallel。
图6列出了IOS调度与5种基于cuDNN的主流框架的推理性能对比。五种基于cuDNN的框架分别为:Tensorflow, Tensorflow-XLA, TASO, TVM-cuDNN [3], TensorRT。从图6可知,IOS在5个基准网络上吞吐量都优于其他框架,并比其余框架中的最好性能还有1.1倍至1.5倍提升。
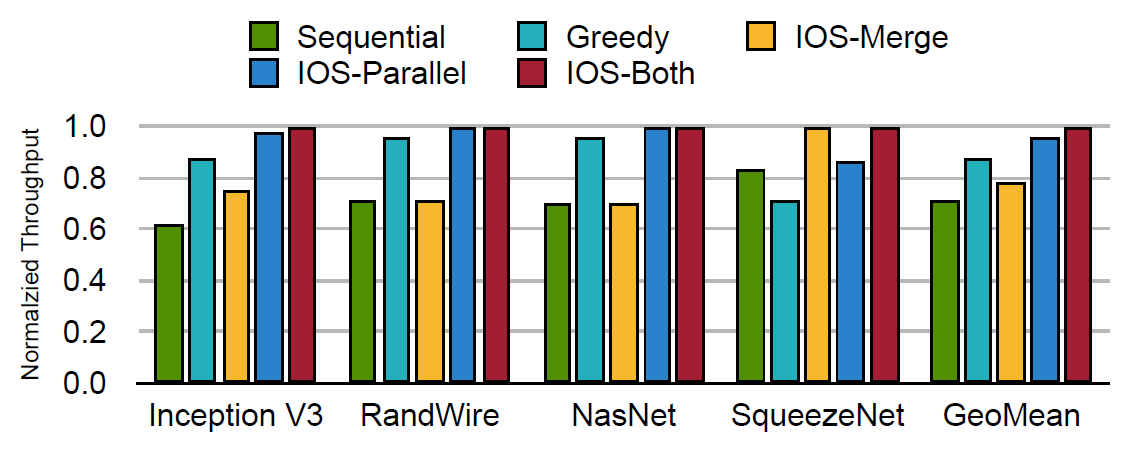
图5 五种调度策略吞吐量比较
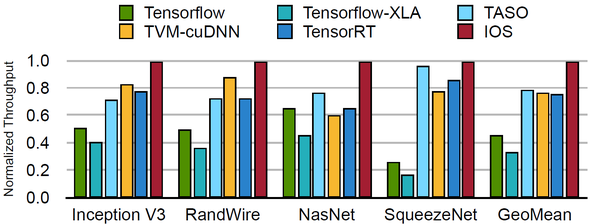
图6 IOS与基于cuDNN框架吞吐量比较
IOS的其他实验结果数据还表明, IOS调度比顺序调度能同时使能更多的活跃线程束,即达到更高的资源利用率;IOS可以通过调整剪枝参数以加快算法的运行时间,但性能提升效果可能会打折扣;对Inception V3网络上,在不同的批处理大小或不同的硬件环境下,网络的计算特征会发生变化,IOS得到的调度也不一样,但IOS的优化效果都优于顺序调度、TVM-cuDNN框架、TASO, 和TensorRT框架。
总结:
笔者认为IOS算法利用多算子的合并或者多算子的并发执行确实可以提高多分支结构的CNN的推理性能,提高硬件资源的利用率,基于类似出发点的优化方法还有Rammer [4]。
但IOS也有一定的使用局限性,即对于resnet类单分支结构的CNN网络优化效果较为一般,文中也有介绍,同时IOS不适用算力资源有限的CNN推理场景,比如移动端推理和嵌入式场景下的推理。IOS方法目前仅关注CNN推理,是否可以应用于CNN训练,文中未见相关的讨论和实验。
参考文献:
[1] Ding Yaoyao, Ligeng Zhu, Zhihao Jia, Gennady Pekhimenko, Song Han, “IOS: Inter-Operator Scheduler for CNN Acceleration”, MLSys 2021
[2] Zhihao Jia, James Thomas, Todd Warszawski, Mingyu Gao, Matei Zaharia, and Alex Aiken, “Optimizing DNN Computation with Relaxed Graph Substitutions”, MLSys 2019
[3] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, Arvind Krishnamurthy, “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning”, OSDI 2018
[4] Lingxiao Ma, Zhiqiang Xie, Zhi Yang, Jilong Xue, Youshan Miao, Wei Cui, Wenxiang Hu, Fan Yang, Lintao Zhang, and Lidong Zhou, “Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks”, OSDI 2020
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

