
转载于:知乎
作者: 金雪锋
最近小伙伴们分析了《Cortex: a compiler for recursive deep learning models》这篇论文,给大家分享一下,此论文第一作者为卡耐基梅隆大学的Pratik Fegade,第二作者为OctoML的陈天奇。研究项目受到NSF及大量工业界的资助。笔者从作者和背后金主来头能感受到这份研究同时受到学术界和工业界的高度关注。文章中提出cortex,即采用编译器思想为递归深度学习模型做快速推理优化。得益于端到端优化,cortex在快速推理上相比业界其他方案获得了14X提升。
1 背景动机
自动驾驶、聊天机器人等应用场景对深度学习模型的推理延迟要求甚为严格。但是减少递归类或者拥有动态控制流的深度学习模型的推理时延是非常困难的。这类模型的代表有TreeLSTM,MV-RNN,LSTM,GRU等。为了降低递归类和动态类模型时延,当前方案如DyNet、Cavs、 PyTorch,主要利用硬件厂商提供的算子加速库(如Nividia GPU的cuDNN)来减低时延。但是这种方案缺点也很明显:加速库支持的模型不够广泛,不能做算子融合和model persistence优化。作者认为可以将已有的编译前馈网络的技术应用到递归网络上,来获得更大的优化,但是面临如下问题:
C1.如何有效的表示递归控制流。
C2.如何优化递归控制流。
C3.如何对动态模型进行静态优化。
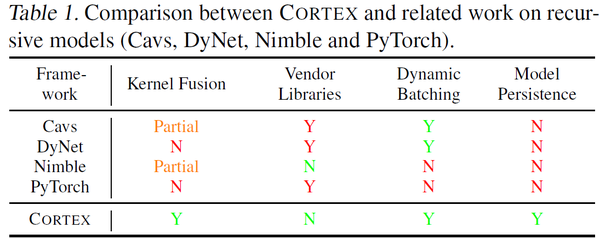
为解决上述问题,作者开发了cortex框架。cortex的前端让用户有效的表示递归和迭代网络模型,然后cortex针对不同后端生成高效的代码。cortex解决问题C1的原理是根据通常递归模型控制流只取决与输入数据结构这一特征,将递归计算转换为循环迭代。解决问题C2和C3的思路是利用调度原语来进行包括特化(specialization)、动态合批(dynamic batching)、计算外提(computation hoisting)等优化。在cortex框架中,算子不再是黑盒函数调用(TVM使用te来表达算子),这样就创造了大量的算子融合机会,同时避免了动态合批优化带来的开销。cortex与类似框架的比较如下Table 1。
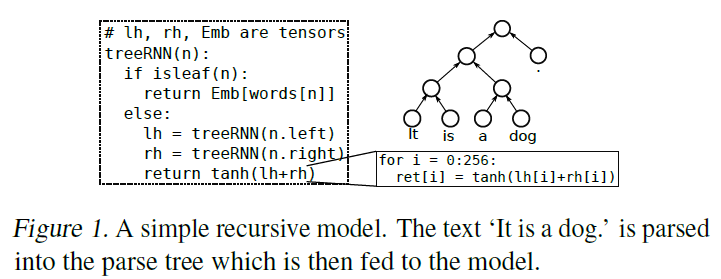
下面的fig 1是本文的演示模型:
2 cortex框架总览
cortex的作者发现递归模型通常具备如下性质:
P1 所有控制流依赖数据的连接结构,不依赖动态计算出来的数据的值。
P2 所有的递归函数能够在任何张量计算之前调用。
P3 数据结构节点的直接孩子递归函数之间是相互独立:函数的入参不依赖于前面的兄弟函数的结果。
结合这些性质,作者推导出能够将递归控制流转换为循环迭代控制流。
cortex的编译运行工作流程如下fig2。

编译流程的开始是RA(递归api)如所示。用户可以指定调度原语来指定递归计算如何转换成循环迭代,如所示。编译器接下来根据用户的调度原语生成ILIR(Irregular Loop IR)。ILIR是张量编译器IR的扩展,能够支持表达间接内存访问(indirect memory accesses)和可变循环边界。ILIR是基于循环的,且不限定数据的结构。经过RA lowering之后,所有的递归控制流变成了循环迭代,所有的数据结构存取变成了潜在的间接内存访问。对于循环的优化比如循环展开、切分等张量编译器进行的优化可以在这里进行。之后就是生成平台相关的代码,如所示。
运行时的工作流程与编译阶段的转换相互对应。开始时递归数据结构是指针链接的序列、树或者DAG,如所示,会被转换成为数组,如,这个过程叫线性化(linearized)。线性化使得生成的迭代代码能够遍历数据结构。注意线性化不涉及任何张量计算,所以作者在host CPU上进行线性化。
接下来的3 4 5 6节会对上面提到的过程详细描述。
3 RA
RA对于输入计算使用算子组成的DAG图来表示,如下图listing 1。

此图即为fig1 网络的RA。除了计算,用户需要提供输入数据结构的一些基本信息比如每个节点最多有多少孩子,数据结构的类型(sequence、tree、DAG)。
listing 1中25、26行是调度原语。
cortex支持以下调度原语:
动态合批:参考Neubig提出的动态合批(实时的使用合批算子,在含有动态控制流模型中,对单个batch并行)。作者在线性化时进行了动态合批,fig 2中的即为最终结果。
特化(specialization):递归计算有大量的条件语句,条件语句会阻止计算外提和常量传播,并且有执行开销。所以cortex允许用户对条件语句的两个分支进行特化。Listing 2即为递归模型的ILIR,注意此时对叶子计算的循环嵌套已经与对内部根节点的循环嵌套分隔开了,这是对listing 1 26行特化原语的响应。

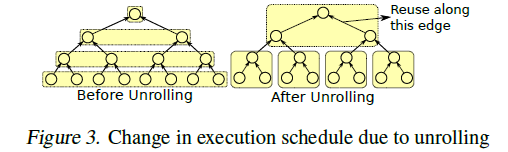
循环展开(unrolling):循环展开改变了节点的处理顺序如fig 3所示。父节点的执行时机与子节点的执行时机更加靠近,这样就能使用芯片的缓存复用子节点的中间状态。如图fig 3右边所示,每一个方框里的两个回边上数据可以复用。
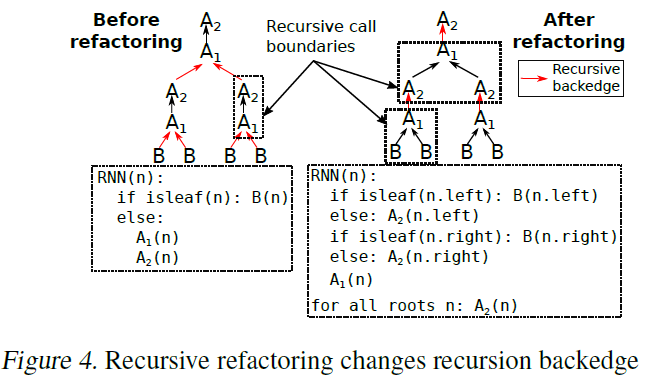
递归重构(recursive refactoring):跨递归调用的算子间难以融合。针对这种场景,可以通过递归重构来改变递归的回调边。如fig 4 所示,左边的计算A1,A2和B构成的张量算子图中,A2对A1存在依赖,此时,递归回调边从B/A2 到A1,对A1(n)和A2(n.left)或者A2(n.right)的融合很难进行,因为他们跨越了递归调用函数边界。重构改变了边界(现在回调边是从A1到A2),A1(n)、A2(n.left)、A2(n.right)现在处于同一个函数中因而可以融合。
4 递归转换(Lowering)成循环
4.1 RA转换(RA Lowering)
RA到ILIR变换本质就是递归到迭代的变换。因而,作者构造了所有变换中使用的临时张量。以Listing 2中的ILIR为例,创建了lh和rh这两个临时张量。同时创建张量rnn,保存计算结果。每个递归函数,在这里是一个树的节点,都会使用这3个张量保存数据。
递归重构和循环展开这两个调度原语在lowering之前的转换输入RA计算阶段就处理了。特化条件分支(调度原语)是通过产生两个版本的计算来处理的。数据结构线性化和ILIR针对不同节点采用了对应版本的计算。在lowering阶段会产生以线性化输出为循环变量的嵌套循环迭代。ILIR默认对节点进行迭代,但是用户指定动态合批时,ILIR对节点的batches进行迭代。
4.2 数据结构线性化
在运行时,数据结构线性化器会遍历输入的链表结构并且将它转换成数组。基于循环的计算会使用这个数组。线性化器的伪代码如下:

线性化器在RA转换期间生成。在没有特化和动态合批时,线性器本质上以输入程序相同的方式遍历数据结构,同时保留节点的顺序。这个节点顺序能够满足数据依赖并且能在张量计算时使用。在文章中的例子中,数据结构线性器就是去除了张量计算的输入程序。
4.3计算外提和常量传播
递归模型通常为基本场景设置初始值。如果所有叶子的初始值相同,对叶子的相同计算就是冗余。当转换成ILIR时,这类计算就会提到递归的外面。
5 ILIR
ILIR的计算和优化是分开的。计算用算子组成的DAG表示。优化主要通过调度原语来控制。
注意listing 2中,rnn的下标变量node是循环变量n\_idx的非仿射变换函数。同时注意第7行是对节点batch的循环,由于batches的长度不一,循环具有可变边界。对此,作者扩展了张量编译器(TVM)的三个功能:(1)非仿射下标表达式(2)可变循环边界(3)条件算子。具体讨论如下:
5.1 间接内存访问(indirect memory access)
作者将非仿射下标表达式当做对未知函数(关于循环变量的)的间接内存访问(strout et al 2018)。
边界推断: 在编译时,张量编译器会推断输出程序的所有算子的循环边界。对于算子op产生张量t,编译器首先计算t的哪些区域是它的消费者需要的。这个区域数值会转换成op的循环边界。在listing 2的ILIR中,张量lh、rh,rnn维度为2,但是ILIR对于每个算子却有3重循环。因此,ILIR需要明确的指出张量维度和算子的循环嵌套的对应关系。
张量数据排布:IILIR提供排布原语,能够对张量维度进行分割,重排,融合。
当中间张量存在scratchpad Memory时, 如fig 5中的A1, 使用非仿射表达式索引会得到稀疏填充的张量。这种稀疏张量浪费宝贵的memory。如图fig 5中左边所示,A1的一半空间没有使用。对于这种场景,作者使用循环迭代空间作为张量的下标如fig 5右边所示。这就是在scratchpad Memory上分配更小张量的办法。这个办法同时也让间接内存访问变成了仿射访问。

5.2 条件算子
对于模型中的isleaf条件,作者在ILIR中增加了条件算子,条件算子的输入包含两个子图和一个条件,会被lowering为if 语句。在文章的例子中,如果用户不特化isleaf,ILIR就会生成一个条件算子。
6 实验结果
Cortex相对Pytorch的加速可以高达400倍。作者将这里的显著提升的归因于Pytorch无法进行动态合批,也没有算子融合。
Cortex相对Cavs的加数可以达到14X。
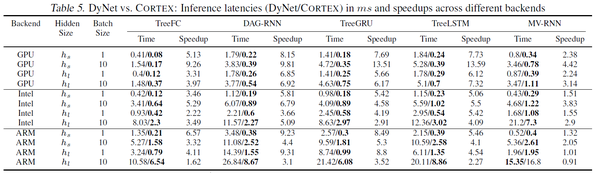
Cortex相对DyNet的加数也可以达到14X。与DyNet的详细对比数据见下面table5.
7 总结
不依赖芯片厂商的算子加速库,cortex能够进行大范围的算子融合,能够进行端到端优化(上至递归控制流,下至张量代数运算),因而显著减少了推理时延。作者认为cortex证明了使用通用编译器技术能够有效的支持ML模型高效的动态执行。作者打算将本文中的技术可以进一步扩展应用到模型训练以及非递归网络模型上。
笔者认为,自从transformer出现以后nlp越来越聚焦到Bert等网络上,LSTM/RNN受到的关注在持续降低,对递归网络的优化的潜在价值可能会逐步缩水。不过,作者对TVM进行的扩展应该是通用的,不受网络模型限制。
8 参考
1 《Learning to optimize Halide with tree search and random programs》
2 《Integrated runtime and compile-time approach for parallelizing structured and block structured applications》
3 《A polyhedral compiler for expressing fast and portable code》
4 《End to end learning for self-driving cars》
5 《Automatic batching as a compiler pass in PyTorch》
6 《An automated end-to-end optimizing compiler for deep learning》
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

