
本文转自:知乎
作者:金雪锋
大家好,今天给大家带来MLSys 2021的一篇论文,来自Facebook AI Research的《VALUE LEARNING FOR THROUGHPUT OPTIMIZATION OF DEEP NEURAL NETWORKS》。这是本系列分享关于Tuning的第三篇论文,足以见得在深度学习领域算子Tuning的重要性。
如今机器学习的使用无处不在,神经网络的执行效率在很多场景下变得尤为重要。AI算子框架如Halide、TVM等利用算子调度(Schedule)将深度学习模型拆分成众多的算子。然而为算子寻找出优秀的调度,是一件困难的事情。自动调整(Auto-tuning)任务,希望在合法的算子空间中找出最佳的算子调度并完成实测。这篇论文通过强化学习(Value Iteration)+ CostModel(BiLSTM)来解决auto-tuning问题。
论文的主要的贡献点在于:
- 提出一种可以生成合法候选调度(schedule)的方式;
- 提出一种高精度的预测调度运行时间的Cost Model;
- 提出一种基于Cost Model的迭代式Value function,用于贪心地从空间中寻找最佳候选调度,比以往的方法速度提升2到3个数量级;
- 在这一系列的技术帮助下,优化后的神经网络比Halide提升1.5x,比TVM提升2.6x。
背景与基础
论文以Halide为基础,支持schedule的split、reorder、vectorize、parrallel、compute\_at、store\_at等操作。原始的DSL可以通过这一系列的操作转化成目标高性能schedule。与Halide相仿,论文同样将一个算子生成任务称作pipeline,而同一个pipeline的不同阶段称为stage。
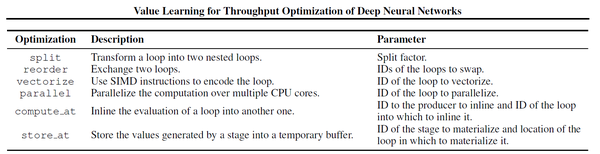
图1. 支持的基本原语
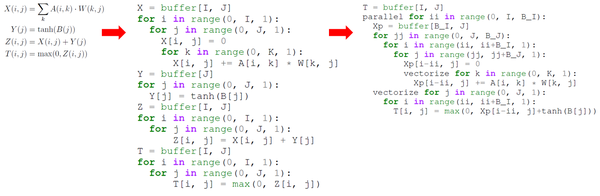
图2. 由原始DSL到简单的schedule,再变换成高性能的schedule
空间生成
论文将空间生成分成5个部分:
- 在每一个stage中,将每一个变量v拆分成3重子循环(split);
- 在1 的基础上增加重排(reorder);
- 尝试对每个loop添加向量化选项(vectorize);
- 在满足生产者-消费者模型的条件下,增加临时buffer和inline(compute\_at、store\_at);
- 选择loop进行并行化(parallelize)。
经过这5个阶段后,空间将会变得庞大起来。论文通过一定的方式去减少空间大小,如:向量化时只考虑因子是向量本身的整数倍的情况。在常见网络中,平均每个stage有大约30万个选择。
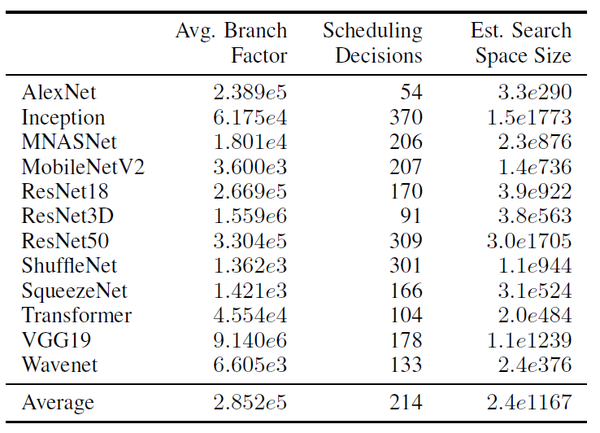
图3 常见网络的空间大小
寻找最佳调度
论文采取基于Value function搜索最佳调度,采用了马尔科夫决策过程,MDP。
【注】关于马尔可夫决策过程、强化学习的相关学习可以参考https://www.cnblogs.com/pinard/p/9426283.html。
通过一个Value Function V(s)来评估当前pipeline的“最低运行时间”。整体搜索流程如下:(1)输入一个pipeline(包含n个stages,按照拓扑序排列)、输入估价函数V(s)、设置初始化状态state0;(2)按照stage的顺序寻找当前stage最佳的调度决策,首先生成一系列的候选调度决策;(3)然后对于每一个调度决策s,计算其V(s),保留最大值vi以及对应决策si;(4)返回n个stages的决策s1...sn。N-stage的pipeline,每个stage平均调度决策为M的情况下,需要计算的总次数是M*N,而不是M^N。这样可以使得我们能以很快的速度计算完全部的结果。

图4,基于Value function搜索最佳调度
这种设计下,auto-tune的效果很大程度上取决于Cost Model的准确程度。论文提供了一种基于BiLSTM+特征工程的思路来解决估价问题。
论文中包含了三类特征:(1)与调度无关的指令特征,例如浮点数加减法、index下标计算、内存访问特征等等;(2)调度相关特征,例如向量化的数量、循环轴相关特征、inline相关特征、CPU利用率、影响性能的辅助消耗特征等等;(3)派生类型特征,如算术强度等。
论文构建了一个双向LSTM用作预测运行时间,结构如图所示。N个stages对应N个LSTM cell,最后汇总N个结果,得到整个pipeline的总结果。Cost Model的训练使用了13352个piplines,每个pipeline平均包含1184个调度。Loss的设计包含了预测值P、平均实际运行值M、重要程度C、减重程度D。
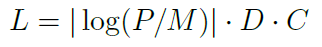
图5,Cost Model的Loss设计
【注】文章中的Cost Model是指用于预测经过完整调度的pipeline时间模型(BiLSTM),Value Function是已经应用部分调度后的pipeline可能达到的最佳时间预估函数。
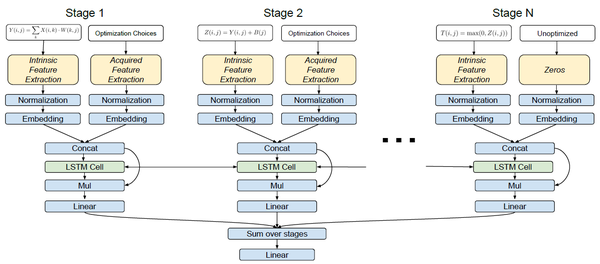
图6, BiLSTM结构图
迭代式Value Function训练
为了训练出更加精确的模型V(s),论文采用迭代式优化Value Function:(1)对于一系列的pipelines以及上一个Value Function Vi-1,通过Algorithm1获得对应的最佳调度序列s0…sn;(2)对于任意一个调度sj,通过BeamSearch的方式(即Beam形式的Algorithm1),获得后面的调度tj+1…tn,同时获得s0..sj,tj+1..tn调度序列的BenchMark结果r,更新Vi(sj)。

图7, 迭代优化Value Function流程
【注】关于Value Iteration过程,可以参考https://zhuanlan.zhihu.com/p/33229439
结果对比
- Cost Model。Cost Model的对比项主要是平均预测误差、最大预测误差、决定系数。由实验结果可以看出,论文的结果均远超于Halide、TVM。
- 整体的结果对比:加速效果与搜索时间对比。

图8,Cost Model实验对比
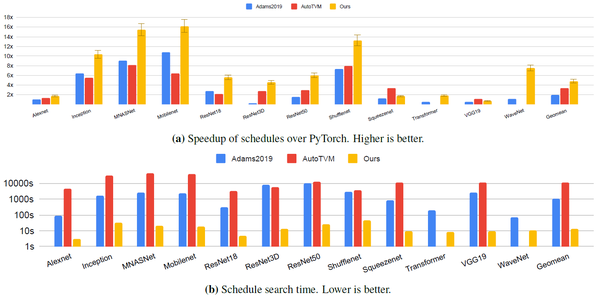
图9,加速实验、搜索时间实验
总结
下面总结一下已经分析的三篇论文对tuning问题的思考与处理方法(TVM-Ansor[3]、Google-TPU[2]、MIT-TIRAMISU[4]、Facebook-本篇[1])差异。在tuning的基础流程上,各个研究机构是相似的,都是遵循空间生成、Cost Model训练与预测、空间中搜索寻找最优解。而在关键问题上(Cost Model和搜索),各家又各有不同。
首先在Cost Model上,从模型选择上来说,基于XLA的TPU-tune选择了GNN、TIRAMISU和Facebook使用LSTM、Ansor则采用一种特殊的packed-XGBoost。不同的机构的AI框架与设计都大有不同,各个论文给出的speedup很难从数值上直接断定“哪个模型更好”。具体模型落在具体场景的性能优劣,可能是一个工程问题。但是从设计思路上来说,它们不约而同的采取“子模块建模+求和”的方式,将一个子图转化成若干子模块来建模:TPU-tune的opcode、TIRAMISU基于loop的computation、Facebook的stages和Ansor的stages。这些子模块都可以被单独建模(如一个LSTM cell或者单个xgboost的预测值等),汇总之后就可以用来表达整个子图的最终结果。想要更精确的Cost model,则重点关注建模子模块(features)即可。从这点上来看,是跟子图整体式建模有区别的。
在搜索算法上,TPU-tune的论文侧重点在于Cost Model,理论上来说任意搜索算法都适用;TIRAMUSA采用的是树搜索Beam search或MCTS,Beam search属于一种贪心但是有一定的容忍度,而MCTS则为搜索加入了反馈,以希望修正误差;Facebook采用的是另一种强化学习的思路Value Iteration;而Ansor则采用的是Guided random search中的Evolutionary algorithm。从搜索算法而言,越来越多的机构采取各种强化学习(RL)的方式处理搜索,RL确实是一种更理想的方式,毕竟“调option、调切分”这件事某种程度上来说跟“agent在environment上探索然后根据reward去调整”实在太像。但是就目前而言,tuning框架上似乎还是没有像AlphaGo一样的模型能直接证明RL比传统的搜索方式有优势。传统的搜索方式没有模型引导[3],但是更方便研究人员加入各式各样的策略去解决搜索方向问题;RL则通过模型去学习策略[1],而能不能学到复杂有效的策略又成一个难题。
总体而言,AI框架处于一个百花齐放的时代,而其下的算子(子图)框架、tuning框架也多种多样。从学术研究上来说,很多方面都可以有进一步的尝试:优化空间生成、更精确的建模、搜索的速度与方向引导等等;从工程上来说,让tuning优美的落地不同层级的AI场景,实现更快的搜索生成更高性能的算子,同样需要工程师们做出更多的努力。
参考文献
[1]Steiner, B., Cummins, C., He, H., and Leather, H., “Value Function Based Performance Optimization of Deep Learning Workloads”, arXiv e-prints, 2020.
[2] Kaufman S J, Phothilimthana P M, Zhou Y, et al. A Learned Performance Model for Tensor Processing Units[J]. arXiv preprint arXiv:2008.01040, 2020.
[3] Zheng L, Jia C, Sun M, et al. Ansor: Generating high-performance tensor programs for deep learning[C]//14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020: 863-879.
[4] Merouani M, Leghettas M H, Pr R B D T A, et al. A Deep Learning Based Cost Model for Automatic Code Optimization in Tiramisu[D]. Master’s thesis, École nationale supérieure d’informatique, Algiers, Algeria, 2020.
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

