
本文转自:知乎
作者:djh
1、简介
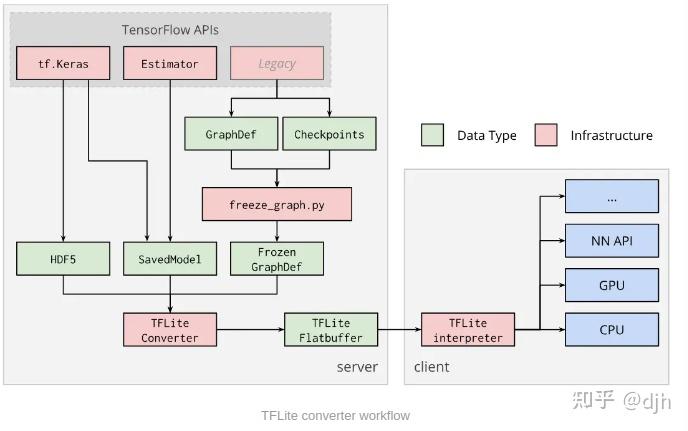
Tensorflow Lite 的基本框架如上。数据存储的结构是Flatbuffer。执行上次结构支持Keras 和Estimator和Legacy等等。而下层支持NN API、GPU等等。
2、模型转换
要先将ckpt转成pb,在让pb转tflite格式。
ckpt转pb
import tensorflow as tf
from tensorflow.python.framework import graph_util
output_node_names = "heats_map_regression/pred_keypoints/BiasAdd"
input_checkpoint = "modelfilter.ckpt"
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=True)
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
output_graph="frozen_modeld.pb"
with tf.Session() as sess:
saver.restore(sess, input_checkpoint) #恢复图并得到数据
output_graph_def = graph_util.convert_variables_to_constants( # 模型持久化,将变量值固定
sess=sess,
input_graph_def=input_graph_def,# 等于:sess.graph_def
output_node_names=output_node_names.split(","))# 如果有多个输出节点,以逗号隔开
with tf.gfile.GFile(output_graph, "wb") as f: #保存模型
f.write(output_graph_def.SerializeToString()) #序列化输出pb转tflite
graph_def_file = "outquantizemodel/frozen_graph.pb" input_arrays = ["MobilenetV2/input"] output_arrays = ["heats_map_regression/pred_keypoints/BiasAdd"] converter = tf.contrib.lite.TFLiteConverter.from_frozen_graph(graph_def_file, \ input_arrays, output_arrays,input_shapes={"MobilenetV2/input":[1,600,800,3]}) converter.inference_type = tf.contrib.lite.constants.QUANTIZED_UINT8 converter.quantized_input_stats = {input_arrays[0]: (127.5, 127.5)} # mean, std_dev,需要自己从训练集(增强后,输入网络之前的)统计出来 tflite_model = converter.convert() open("outquantizemodel/eval_graph_filequantize.tflite", "wb").write(tflite_model) 3、模型执行C++ Android
当然你可以使用Python执行,python执行的好处是可以对比pb模型运行的结果。
也可以使用Android java执行。
而使用C++执行代码,可以更加好的掌控,模型的运行过程和效率。方面我们后续优化。
https://github.com/tensorflow/tensorflow.gitgithub.com
在github 中下载源码。接下来我们使用bazel 编译出C++版本的Tensorflow Lite 。
首先1:建立tensorflow/test目录。在目录下书写自己要运行的代码,和build配置文件。
目录结构大概是这样子的。

C文件大概是这样子的
test.cc
bool modelInit(const char* model_file, int numthreads) {
model = tflite::FlatBufferModel::BuildFromFile(model_file);
tflite::InterpreterBuilder(*model, resolver)(&interpreter);
if (!interpreter) {
LOGI("Failed to construct interpreter");
} else {
LOGI("construct interpreter is ok !!");
}
if (interpreter->AllocateTensors() != kTfLiteOk) {
LOGI("Failed to allocate tensors!");
}
// input_tensor = interpreter->tensor(interpreter->inputs()[0]);
interpreter->SetNumThreads(numthreads);
// load model ..., init interpreter
djh = &a;
return true;
}
bazel的配置文件大概是如下:
package(default_visibility = ["//visibility:public"])
load("//tensorflow/lite:build_def.bzl", "tflite_linkopts", "tflite_copts")
cc_binary(
name = "libtest.so",
srcs = [
"test.cc",
"test.h"
],
linkopts=[
"-shared",
"-Wl,-soname,libtest.so",# for gun compile (ex: ubuntu, android)
# "-Wl,-install_name,libtest.dylib", # for clang (ex: mac)
],
linkshared = 1,
copts = tflite_copts(),
visibility = ["//visibility:public"],
deps = [
"//tensorflow/lite:framework",
"//tensorflow/lite/kernels:builtin_ops",
]
)在tensorflow 文件夹下使用bazel命令进行编译。
bazel build --crosstool_top=//external:android/crosstool --cpu=arm64-v8a --host_crosstool_top=@bazel_tools//tools/cpp:toolchain --cxxopt="-std=c++11" //test:libtest.so
编译成功后可以在Android很方便的使用so。
4、模型大小优化
我们看到这个so编译出来是很大的,有20M左右。所以我们要对这个so进行裁剪。如何裁剪,裁剪掉不需要的算子保留自己的算子就行了。
最简单的方式就是在register中不用注册这么多我们用不到的算子。只保留我们要用到的几个,至于你的模型用到了哪些,你可以在pb中解析出来。
找到register.cc文件在register.cc中我们保留我们自己的,然后重新编译。
BuiltinOpResolver::BuiltinOpResolver() {
AddBuiltin(BuiltinOperator_ADD, Register_ADD(),
/* min_version */ 1,
/* max_version */ 2);
AddBuiltin(BuiltinOperator_CONV_2D, Register_CONV_2D(),
/* min_version */ 1,
/* max_version */ 3);
AddBuiltin(BuiltinOperator_DEPTHWISE_CONV_2D, Register_DEPTHWISE_CONV_2D(),
/* min_version */ 1,
/* max_version */ 3);
AddBuiltin(BuiltinOperator_SUB, Register_SUB(),
/* min_version */ 1,
/* max_version */ 2);
}
5、模型汇编优化
汇编优化是为了提升速度。当然,在Tensorflow Lite中以及有很多NEON的汇编优化了。但是还是有些算子没有优化到,我觉得有可能google不屑于优化吧。但是对于如果我们的系统芯片不是很好的情况下,我觉得还是要优化的。比如SUB算子。只是一个普通的减法,但是对于图片来说,每个像素都要做减法,加起来就是几万次的减法。例如600*800的图片做一次均值。
def _preprocess_subtract_imagenet_mean(inputs):
"""Subtract Imagenet mean RGB value."""
mean_rgb = tf.reshape(_MEAN_RGB, [1, 1, 1, 3])
return inputs - mean_rgb800×600×3 = 1440000 就做了这么多长的减法。
Tensorflow Lite 没有优化之前是怎么做的。如下就是通道for循环,这样的代码是很损耗性能的。
for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
float in1 = input1_data[y * desc1.strides[1] + x * desc1.strides[2] + c * desc1.strides[3]];//max 1439999
float in2 = input2_data[c * desc2.strides[3]];
int offset = ( y * dims_data[2] + x) * dims_data[3] + c;//max 1439999
}
}
}
}
这个代码在我的Android 高通660上运行了17ms左右。我将它改成汇编。
inline void BroadcastSub4DSlowDjh(const ArithmeticParams& params,
const RuntimeShape& input1_shape,
const float* input1_data,
const RuntimeShape& input2_shape,
const float* input2_data,
const RuntimeShape& output_shape,
float* output_data) {
float in2bufz1[4] = {123.15f, 115.90f, 103.06f, 123.15f};
float in2bufz2[4] = {115.90f, 103.06f, 123.15f, 115.90f};
float in2bufz3[4] = {103.06f, 123.15f, 115.90f, 103.06f};
for (int b = 0; b < 1440000; b+=12) {
// _MEAN_RGB = [123.15, 115.90, 103.06]
float32x4_t in1_vecz1 = vld1q_f32(&input1_data[b]);
float32x4_t in2_vecz1 = vld1q_f32(in2bufz1);
float32x4_t in1_vecz2 = vld1q_f32(&input1_data[b+4]);
float32x4_t in2_vecz2 = vld1q_f32(in2bufz2);
float32x4_t in1_vecz3 = vld1q_f32(&input1_data[b+8]);
float32x4_t in2_vecz3 = vld1q_f32(in2bufz3);
float32x4_t ret_vecz1 = vsubq_f32(in1_vecz1, in2_vecz1);
float32x4_t ret_vecz2 = vsubq_f32(in1_vecz2, in2_vecz2);
float32x4_t ret_vecz3 = vsubq_f32(in1_vecz3, in2_vecz3);
float out1 = vgetq_lane_f32(ret_vecz1, 0);
float out2 = vgetq_lane_f32(ret_vecz1, 1);
float out3 = vgetq_lane_f32(ret_vecz1, 2);
float out4 = vgetq_lane_f32(ret_vecz1, 3);
float out5 = vgetq_lane_f32(ret_vecz2, 0);
float out6 = vgetq_lane_f32(ret_vecz2, 1);
float out7 = vgetq_lane_f32(ret_vecz2, 2);
float out8 = vgetq_lane_f32(ret_vecz2, 3);
float out9 = vgetq_lane_f32(ret_vecz3, 0);
float out10 = vgetq_lane_f32(ret_vecz3, 1);
float out11 = vgetq_lane_f32(ret_vecz3, 2);
float out12 = vgetq_lane_f32(ret_vecz3, 3);
output_data[b] = out1;
output_data[b + 1] = out2;
output_data[b + 2] = out3;
output_data[b + 3] = out4;
output_data[b + 4] = out5;
output_data[b + 5] = out6;
output_data[b + 6] = out7;
output_data[b + 7] = out8;
output_data[b + 8] = out9;
output_data[b + 9] = out10;
output_data[b + 10] = out11;
output_data[b + 11] = out12;
}
速度变成了5ms左右。
6、总结
总的来说,Tensorflow Lite基本上是不错的,在Arm架构运行上效率较高。当然也还有其他很多地方可以优化的,比如内存,其他API接口的优化,等等。
说几个Tensorflow 不好的地方,1、转换太麻烦了 2、GPU的版本对应NN api要支持,如果没有支持就不能用了。
其他
关注我不迷路,目前只是一些入门级的小文章,后面会有AI系列文章推送。
https://github.com/yazone/ai_learning_path更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

