

6 月 19-25 日,备受全球瞩目的国际顶级视觉会议 CVPR2021(Computer Vision and Pattern Recognition,即国际机器视觉与模式识别)在线上举行,但依然人气爆棚,参会者的激情正如夏日般火热。
今年阿里云多媒体 AI 团队(由阿里云视频云和达摩院视觉团队组成,以下简称 MMAI)参加了大规模人体行为理解公开挑战赛 ActivityNet、当前最大时空动作定位挑战赛 AVA-Kinetics、超大规模时序行为检测挑战赛 HACS 和第一视角人体行为理解挑战赛 EPIC-Kitchens 上的总共6 个赛道,一举拿下了 5 项冠军和 1 项亚军,其中在 ActivityNet 和 HACS 两个赛道上连续两年蝉联冠军!
顶级挑战赛战绩显赫
大规模时序动作检测挑战赛 ActivityNet 于 2016 年开始,由 KAUST、Google、DeepMind 等主办,至今已经成功举办六届。
该挑战赛主要解决时序行为检测问题,以验证 AI 算法对长时视频的理解能力,是该领域最具影响力的挑战赛之一。历届参赛者来自许多国内外知名机构,包括微软、百度、上交、华为、商汤、北大、哥大等。
今年阿里云 MMAI 团队最终以 Avg. mAP 44.67% 的成绩获得该项挑战赛的冠军!

图 1 ActivityNet 挑战赛证书
时空动作定位挑战赛 AVA-Kinetics由 2018 年开始,至今已成功举办四届,由 Google、DeepMind 和 Berkeley 举办,旨在时空两个维度识别视频中发生的原子级别行为。
因其难度与实用性,历年来吸引了众多国际顶尖高校与研究机构参与,如 DeepMind、FAIR、SenseTime-CUHK、清华大学等。
今年阿里云 MMAI 团队以 40.67% mAP 击败对手,获得第一!

图 2 AVA-Kinetics 挑战赛获奖证书
超大规模行为检测挑战赛 HACS 始于 2019 年,由 MIT 主办,是当前时序行为检测任务中的最大挑战赛。该项挑战赛包括两个赛道:全监督行为检测和弱监督行为检测。
由于数据量是 ActivityNet 的两倍以上,因此具有很大的挑战性。历届参赛队伍包括微软、三星、百度、上交、商汤、西交等。
今年阿里云 MMAI 团队同时参加两个赛道,并分别以 Avg. mAP 44.67% 和 22.45% 双双夺冠!

图 3 HACS 挑战赛两个赛道的获奖证书
第一视角人体动作理解挑战赛 EPIC-Kitchens 于 2019 年开始,至今已经举办三届,由 University of Bristol 主办,致力于解决第一视角条件下的人体动作和目标物体的交互理解问题。
历年的参赛队伍包括百度、FAIR、NTU、NUS、Inria-Facebook、三星(SAIC-Cambridge)等。
今年阿里云 MMAI 团队参加其中时序动作检测和动作识别两个赛道,分别以 Avg. mAP 16.11% 和 Acc. 48.5% 获得两项挑战赛的冠军和亚军!

图 4 EPIC-Kitchens 挑战赛获奖证书
四大挑战的关键技术探索
行为理解挑战赛主要面临四大挑战:
首先是行为时长分布广,从 0.5 秒到 400 秒不等,以一个 200 秒的测试视频为例,每 1 秒采集 15 帧图像,算法必须在 3000 帧图像中精确定位。
其次是视频背景复杂,通常具有很多不规则的非目标行为嵌入在视频中,极大的增加了行为检测的难度。
再者是类内差较大,相同行为的视觉表现会因个体、视角、环境的变换而发生明显的变化。
最后是算法检测人体动作还面临人体之间的互相遮挡、视频分辨率不足、光照、视角等变化多样的其他干扰。
在本次挑战赛中,该团队之所以能够取得如此出色的成绩,主要是由其背后先进技术框架 EMC2 支撑,该框架主要对如下几个核心技术进行探索:
(1)强化基础网络的优化训练
基础网络是行为理解的核心要素之一。
在本次挑战赛中,阿里云 MMAI 团队主要对以下两方面进行探索:深入研究 Video Transformer (ViViT);探索 Transformer 和 CNN 异构模型的互补性。
作为主要的基础网络,ViViT 的训练同样包括预训练和微调两个过程,在微调过程,MMAI 团队充分分析包括输入尺寸、数据增广等变量的影响,找到适合当前任务的最佳配置。
此外,考虑 Transformer 和 CNN 结构互补性,还使用了 Slowfast、CSN 等结构,最终通过集成学习分别在 EPIC-Kitchens、ActivityNet、HACS 上取得 48.5%、93.6%、96.1% 的分类性能,相较于去年的冠军成绩,有着明显的提升。
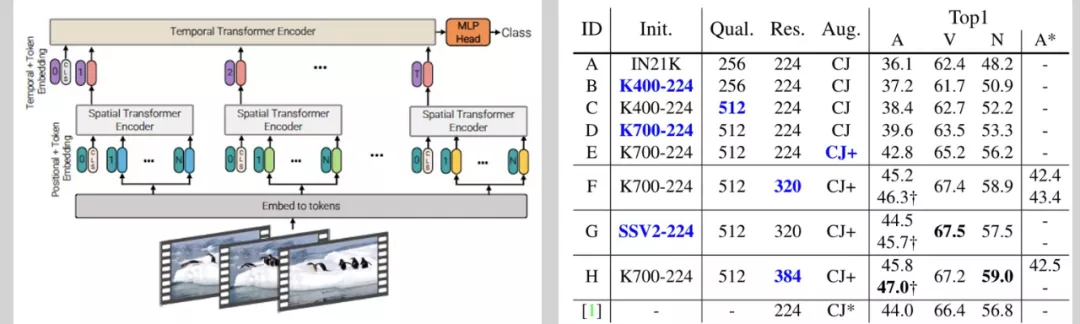
图 5 ViViT 的结构及其性能
(2)视频理解中的实体时空关系建模
对于时空域动作检测任务而言,基于关系建模学习视频中的人 - 人关系、人 - 物关系、人 - 场景关系对于正确实现动作识别,特别是交互性动作识别而言是尤为重要的。
因此在本次挑战赛中阿里云 MMAI 重点对这些关系进行建模分析。
具体地,首先定位视频中的人和物体,并分别提取人和物的特征表示;为了更加细粒度地建模不同类型的动作关系,将上述特征与全局视频特征在时空域结合以增强特征,并分别在不同的时域或空域位置间应用基于 Transformer 结构的关系学习模块,同时不同位置的关联学习通过权重共享的方式实现对关联区域的位置不变性。
为了进一步建模长序时域关联,我们构建了结合在线和离线维护的两阶段时序特征池,将视频片段前后的特征信息融合到关联学习当中。
最后,经过关联学习的人体特征被用于进行动作识别任务,基于解耦学习的方式实现了在动作类别长尾分布下对困难和少量样本类别的有效学习。
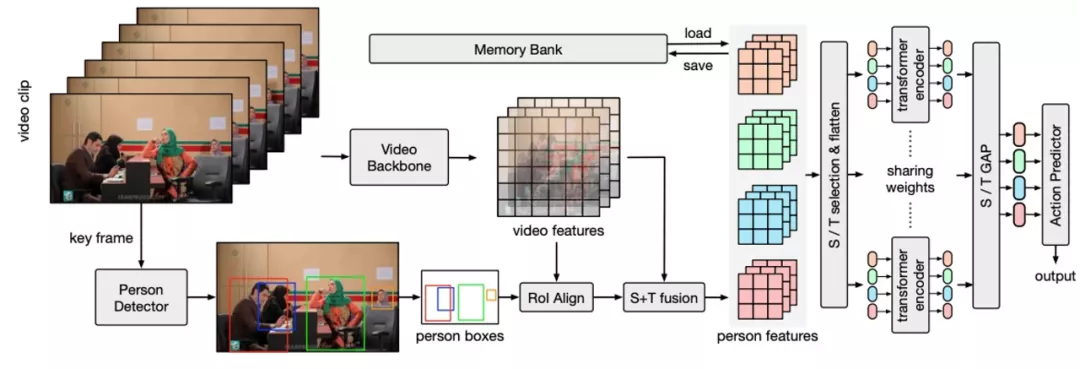
图 6 关系建模网络
(3)基于动作提名关系编码的长视频理解
在动作理解相关的多项任务上,在有限的计算条件下,视频持续时间较长是其主要的挑战之一,而时序关系学习是解决长时视频理的重要手段。
在 EMC2 中,设计了基于动作提名关系编码的模块来提升算法的长时感知能力。
具体地,利用基础行为检测网络生产出密集的动作提名,其中每个动作提名可以粗略视为特定动作实体发生的时间区间。
然后基于自注意力机制,在时间维度上对这些提名实体进行时序关系编码,使得每个动作提名均能感知到全局信息,从而能够预测出更加准确的行为位置,凭借此技术,EMC2 在 AcitivityNet 等时序行为检测上取得冠军的成绩。
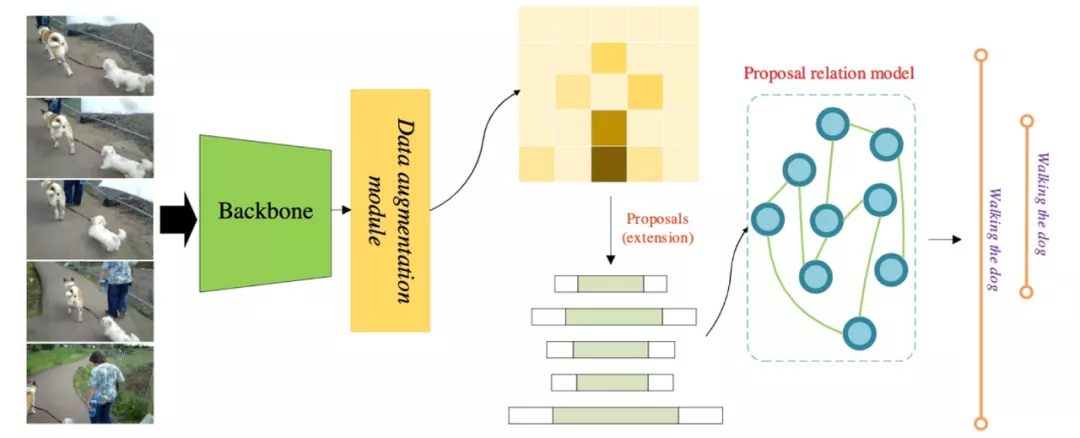
图 7 动作提名间的关系编码
(4)基于自监督学习的网络初始化训练
初始化是深度网络训练的重要过程,也是 EMC2 的主要组件之一。
阿里云 MMAI 团队设计了一种基于自训练的初始化方法 MoSI,即从静态图像训练视频模型。
MoSI 主要包含两个组件:伪运动生成和静态掩码设计。
首先根据滑动窗口的方式按照指定的方向和速度生成伪视频片段,然后通过设计合适的掩码只保留其局部区域的运动模式,使网络能够具有局部运动感知的能力。最后,在训练过程中,模型优化目标是成功预测输入伪视频的速度大小和方向。
通过这种方式,训练的模型将具有感知视频运动的能力。在挑战赛中,考虑到不使用额外数据的规则,仅在有限的挑战赛视频帧做 MoSI 训练,便可取得明显的性能提升,保证了各项挑战赛的模型训练质量。
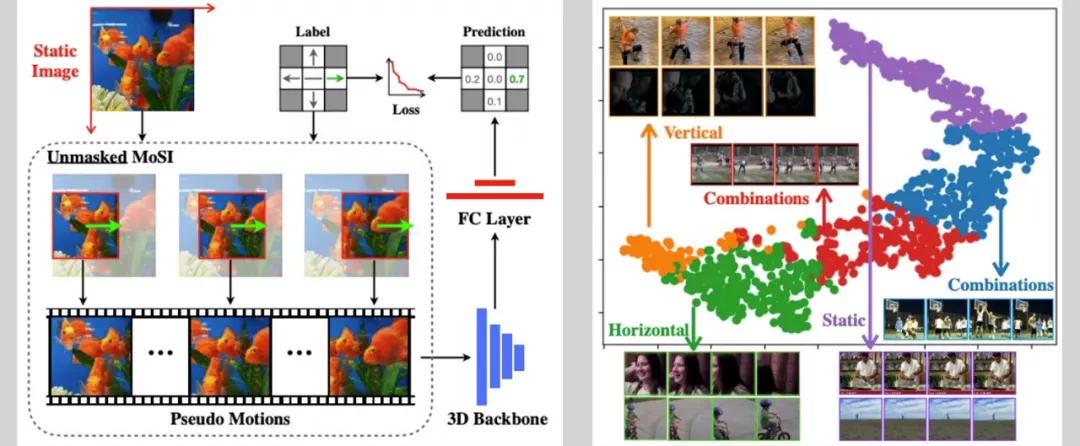
图 8 MoSI 训练过程及其语意分析
“视频行为分析一直都被认为是一项非常具有挑战性的任务,主要源于其内容的多样性。
尽管基础机器视觉中各种先进的技术被提出,我们在此次竞赛的创新主要包括:
1)对自监督学习和 Transformer+CNN 异构融合的深度探索;
2)视频中不同实体间关系建模方法的持续研究。
这些探索确认了当前先进技术(如自监督学习)对视频内容分析的重要性。
此外,我们的成功也说明了实体关系建模对视频内容理解的重要作用,但其并没有得到业界足够的关注。” 阿里巴巴高级研究员金榕总结道。
基于视频理解技术打造多媒体 AI 云产品
基于 EMC2 的技术底座,阿里云 MMAI 团队在进行视频理解的深度研究同时,也积极进行了产业化,推出了多媒体 AI(MultiMedia AI)的技术产品:Retina 视频云多媒体 AI 体验中心(点击👉 多媒体 AI 云产品体验中心 进行体验 )。
该产品实现视频搜索、审核、结构化和生产等核心功能,日处理视频数据数百万小时,为客户在视频搜索、视频推荐、视频审核、版权保护、视频编目、视频交互、视频辅助生产等应用场景中提供了核心能力,极大提高了客户的工作效率和流量效率。

图 9 多媒体 AI 产品
目前,多媒体 AI 云产品在传媒行业、泛娱乐行业、短视频行业、体育行业以及电商行业均有落地:
1)在传媒行业,主要支撑央视、人民日报等传媒行业头部客户的业务生产流程,极大提升生产效率,降低人工成本,例如在新闻生成场景中提升了 70% 的编目效率和 50% 的搜索效率;
2)在泛娱乐行业以及短视频行业,主要支撑集团内业务方优酷、微博、趣头条等泛娱乐视频行业下视频结构化、图像 / 视频审核、视频指纹搜索、版权溯源、视频去重、封面图生成、集锦生成等场景,帮助保护视频版权、提高流量分发效率,日均调用数亿次;
3)在体育行业,支撑第 21 届世界杯足球赛,打通了视觉、运动、音频、语音等多模态信息,实现足球赛事直播流跨模态分析,相比传统剪辑效率提升一个数量级;
4)在电商行业,支撑淘宝、闲鱼等业务方,支持新发视频的结构化,视频 / 图像审核,辅助客户快速生成短视频,提升分发效率。
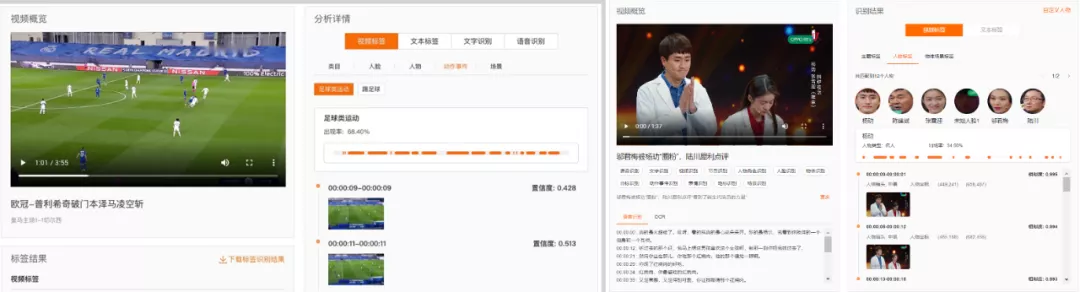
图 10 多媒体 AI 对体育行业和影视行业标签识别
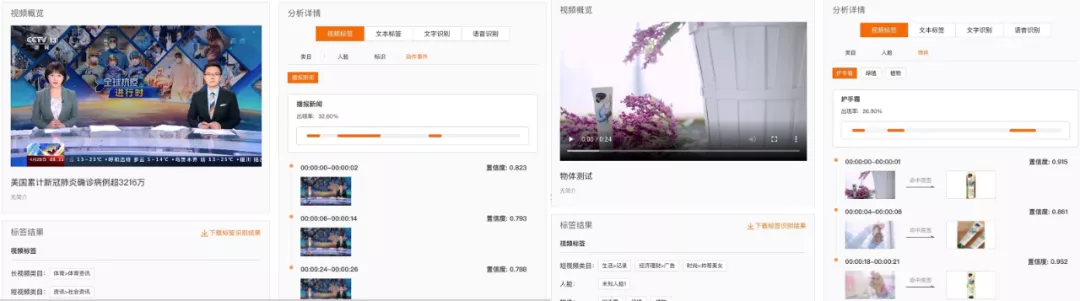
图 11 多媒体 AI 对传媒行业和电商行业的标签识别
在 EMC2 的支撑下,Retina 视频云多媒体 AI 体验中心具有如下优势:
1)多模态学习:利用视频、音频、文本等海量多模态数据,进行跨媒体理解,融合不同领域知识的理解 / 生产体系;
2)轻量化定制:用户可自主注册需要识别的实体,算法对新增实体标签可实现 “即插即用”,且对新增类别使用轻量数据可接近已知类别效果;
3)高效能:自研高性能音视频编解码库、深度学习推理引擎、GPU 预处理库,针对视频场景 IO 和计算密集型特点定向优化,在不同场景达到近 10 倍性能提升;
4)通用性强:多媒体 AI 云产品在传媒行业、泛娱乐行业、短视频行业、体育行业以及电商行业等均有落地应用案例。
“视频非常有助于提升内容的易理解、易接受和易传播性,在过去的几年我们也看到了各行各业,各种场景都在加速内容视频化的进程,整个社会对于视频产量的诉求越来越强烈,如何高效、高质的生产出符合用户需求的视频,就成为了核心问题,这里面涉及到了非常多的细节问题,例如热点的发现、大量视频素材的内容理解、多模检索、基于用户画像 / 场景的模板构建等,这些都需要大量的依赖视觉 AI 技术的发展,MMAI 团队结合行业、场景不断的改进在视觉 AI 方面的技术,并基于此打磨和构建业务级的多媒体 AI 云产品,使得视频得以高质、高效的进行生产,从而有效的推进各行各业、各场景的内容视频化进程。” 阿里云视频云负责人毕玄评价道。
在本次 CVPR2021 中,MMAI 通过多项学术挑战赛一举击败多个国内外强劲对手,拿下了多项冠军,是对其过硬的技术的有力验证,其云产品多媒体 AI 已经服务多个行业的头部客户,并将持续创造多行业应用价值。
👇点击体验
多媒体 AI 云产品体验中心:http://retina.aliyun.com
源码开源地址:https://github.com/alibaba-mm...
参考文献:
[1] Huang Z, Zhang S, Jiang J, et al. Self-supervised motion learning from static images. CVPR2021: 1276-1285.
[2] Arnab A, Dehghani M, Heigold G, et al. Vivit: A video vision transformer[J]. arXiv preprint arXiv:2103.15691, 2021.
[3] Feichtenhofer C, Fan H, Malik J, et al. Slowfast networks for video recognition. ICCV2019: 6202-6211.
[4] Tran D, Wang H, Torresani L, et al. Video classification with channel-separated convolutional networks. ICCV2019: 5552-5561.
[5] Lin T, Liu X, Li X, et al. Bmn: Boundary-matching network for temporal action proposal generation. ICCV2019: 3889-3898.
[6] Feng Y, Jiang J, Huang Z, et al. Relation Modeling in Spatio-Temporal Action Localization[J]. arXiv preprint arXiv:2106.08061, 2021.
[7] Qing Z, Huang Z, Wang X, et al. A Stronger Baseline for Ego-Centric Action Detection[J]. arXiv preprint arXiv:2106.06942, 2021.
[8] Huang Z, Qing Z, Wang X, et al. Towards training stronger video vision transformers for epic-kitchens-100 action recognition[J]. arXiv preprint arXiv:2106.05058, 2021.
[9] Wang X, Qing Z., et al. Proposal Relation Network for Temporal Action Detection[J]. arXiv preprint arXiv:2106.11812, 2021.
[10] Wang X, Qing Z., et al. Weakly-Supervised Temporal Action Localization Through Local-Global Background Modeling[J]. arXiv preprint arXiv:2106.11811, 2021.
[11] Qing Z, Huang Z, Wang X, et al. Exploring Stronger Feature for Temporal Action Localization
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云技术交流群,和作者一起探讨音视频技术,获取更多行业最新信息。

