
写在之前
深度学习模型广泛地应用于图像、文本、音频等领域,并发挥出了巨大作用。而在生物制药领域,研究人员也正在通过深度学习模型来辅助药物分子的设计、表征和优化,以此来减少资源成本,其在虚拟筛选等环节中发挥很好的作用,缩短药物分子研发的周期,从而降低研发成本。
分子表示
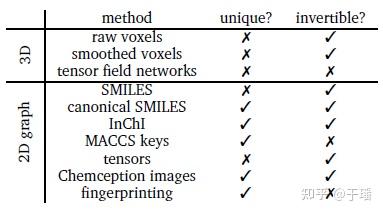
首先来看一下如何来表示一个分子,我们最常见的一般是化学表达式,但这并不适用于深度学习模型的输入。分子表示是指用于每个分子的数字编码,表示的方法必须捕获每个分子的基本结构信息,从分子结构中创建适当的表示称为特征化。一般表示需要有两个重要属性:唯一性和可逆性。唯一性意思就是每个分子结构为单一表示,可逆性指每个表示与单个分子相关联。大部分用于分子生成的表示都是可逆的,但并不一定是唯一的,原因例如旋转、平移等。下图列举了常用的分子表示方法(包含2D和3D表示)。
传统深度学习方法
循环神经网络(RNN)
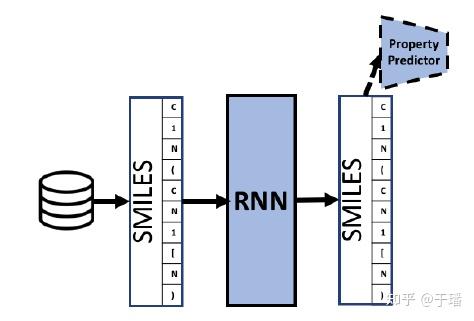
为什么首先提到RNN呢,因为对于VAE、GAN进行分子生成的方法,RNN是重要的序列生成基础,RNN类方法的训练loss往往通过在序列空间中最大化似然概率。
以RNN为基础的分子生成模型结构如下图,分子表示以SMILES为例(其表示应用最为广泛)
变分自编码器(VAE)
若单纯使用RNN会存在着长期依赖的问题,生成效果并不好,因此引入了VAE的结构来优化生成效果。VAE是从变分理论推导出来的,相关原理可参考我之前写的一篇文章。
于璠:MindSpore深度概率推断算法与概率模型zhuanlan.zhihu.com
那么基于VAE架构的分子生成模型则如下图所示:
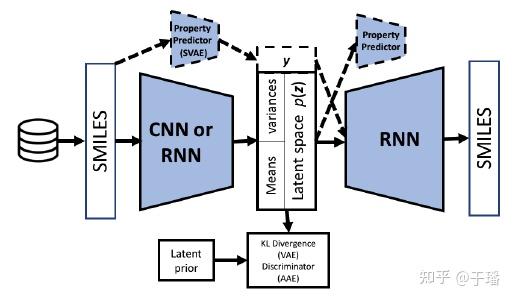
encoder部分可用CNN或RNN来提取分子特征,之后压缩到隐层空间中,通过VAE采样隐层向量,接RNN decoder来解码生成分子SMILES表达式,采样的存在也使得生成的分子多样性得到一定的保证。
生成对抗网络(GAN)
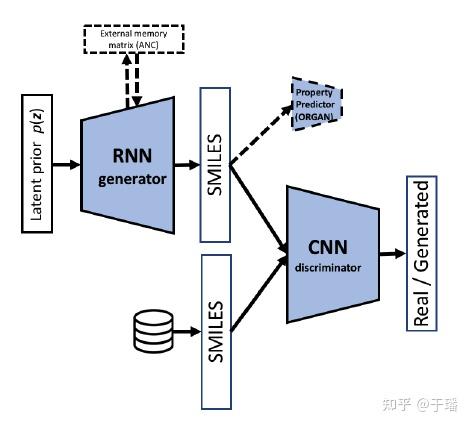
当然以RNN为基础的GAN网络通过生成对抗的方式也广泛应用于分子生成任务,引入了一个Discriminator,通过Discriminator来判别输入的SMILES是属于reconstruct之后的SMILES,还是属于真实的数据,这样相当于额外增加了loss。模型结构如下图:
--------此处为分割线-------
近些年来,Transformer在NLP领域大放光采,它们摒弃了基于RNN结构的序列依赖特性,引入了全新的attention机制,让处于序列任意位置的单元都能看到全局信息,促进了NLP预训练模型的发展。引入这个思想,分子如上文所说可以表达为图或者序列,那么分子预训练模型则应运而生,其在分子表征、生成以及各类下游任务中均取得了不错的效果。下面介绍一下基于文本表示(SMILES)的方法和基于图(2D)的方法。
基于SMILES的预训练模型
这方面比较有代表性的是业界的X-MOL预训练模型,该模型基于文本表示为输入,学习分子的SMILES表达,先看一下总的模型结构图
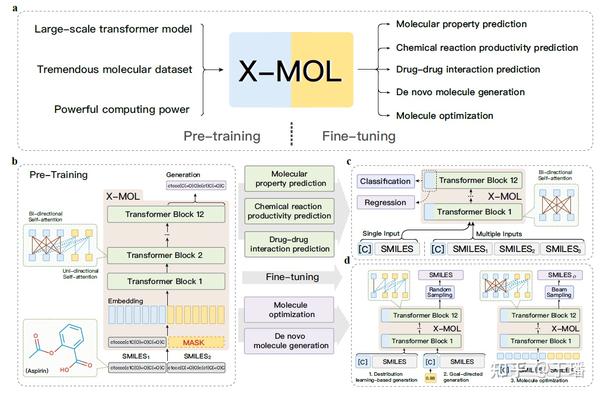
a)指X-MOL的工作流,包括pre-training和fine-tuning两大模块; b)指基于encoder-decoder的语言模型 c)指X-MOL用于不同下游任务的微调 d)指X-MOL用于不同生成任务
该工作中提到的“SMILES is all you need”这种思想也比较有意思,将SMILES表达式新采用knowledge embedding的形式,包含三种策略的embedding,分别为link embedding,ring embedding和type embedding,之后和传统的embedding(Char embedding,Pos embedding以及id embedding)进行结合。
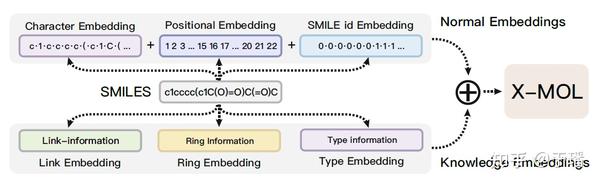
link embedding主要设计了将结构信息的每个原子、键和符号的连接信息合并到SMILES中;SMILES使用一对数字来表示环形结构,两个相同的数字代表一个开环原子和闭环原子,那么在这种情况下,数字代表连接信息和环结构,因此设计了环嵌入来包含环结构信息的数量对;SMILES需要引入额外的字符来表示结构,不同类型的字符设计了类型嵌入来包含类型信息。
基于GNN的预训练模型
这方面有代表性的为GROVER模型,其思想主要为基于graph transformer的节点、边和图任务来学习分子的丰富结构信息。该模型中,一个分子可以被抽象成一个图结构
代表的是n个节点,即原子的个数; 代表的是边的条数,即原子间的连接边。在图学习中,主要有两类学习任务:节点级分类/回归和图级分类/回归。GROVER包含两类子模型:Node GNN transformer和Edge GNN transformer,来看一下GNN transformer的总体结构
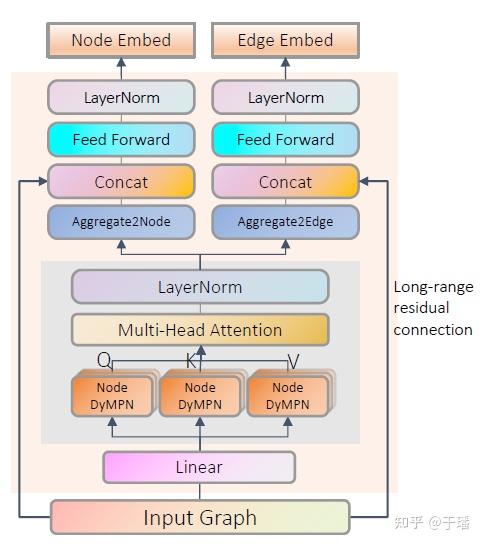
GTransformer可以进行双层信息提取:1)消息传递过程捕获局部图的结构信息,这一步采用GNN模型输出q,k,v。2)q,k,v输入到Transformer中进行全局节点间的特征提取。通过双层的信息提取来更好的表达分子结构信息。
另外,远程残差连接(Long-range residual connection)将输入特征的初始节点/边特征信息直接连接到Gtransformer的最后一层,而不是原始transformer架构中的多个短层残差连接。这样有什么好处呢,1)和普通残差连接一样,可以通过减轻梯度消失问题来改进训练过程;2)远程残差连接可以缓解消息传递过程中的过度平滑问题。
模型中的动态消息传递网络(dyMPN)采样随机消息传递方案,被证明比没有随机化的普通消息传递网络更好的泛化性能。
GROVER预训练过程采用了多个自监督任务,如下图所示:
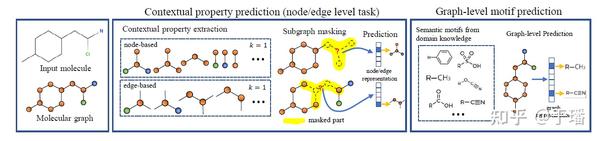
该模型在预训练过程中不使用监督标签,而是提取出了新的自监督学习任务:上下文属性预测(节点/边级)和图级基序预测。
下游任务
上述两类预训练模型的下游任务均在MoleculeNet榜单上进行了验证,经典的下游任务如下图所示。
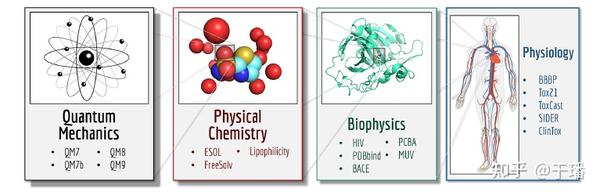
下游任务涵盖量子力学、物理化学、生物和生理等领域,主要为分类和回归任务,例如计算常见有机小分子的水溶性,属性预测等,可以在这些下游任务上一定程度验证模型的表征效果。
另外,分子表征还可以应用于化学反应产品预测、药物间相互作用、分子生成及分子优化等方面,对于药物研发的流程进行诸多方面的AI赋能。
本篇文章就到这里啦,欢迎大家批评指正哈。目前,我们团队也在药物分子预训练模型进行了一些探索,另外我们也努力在药物研发的更多环节进行AI的赋能,也希望感兴趣的朋友能一起探讨下AI科学计算带来的更多应用。

