
在之前发布Transformer in Transformer(TNT)网络架构及其在ImageNet的实验结果后,TNT收到了广泛关注,也有人疑问TNT在更多任务,比如目标检测、图像分割上表现如何?因此,我们也持续演进,将TNT应用在检测分割任务上,用纯Transformer结构来更多视觉任务,其效果也是显示出优越性,比ViT、PVT等都更好一些。
论文:
Transformer in Transformerarxiv.org
开源代码:
huawei-noah/CV-Backbonesgithub.com
TNT网络结构
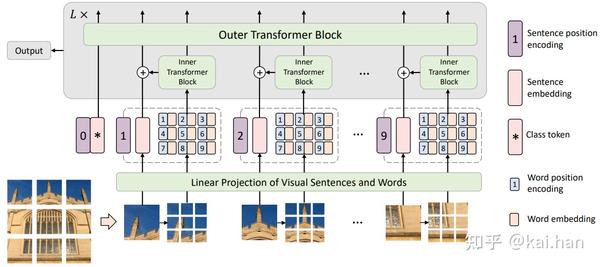
首先,回顾一下Transformer in Transformer的基础网络架构。如下图所示,我们将一张输入图片切分为多个图像块(视觉句子),每个视觉句子可以进一步划分为视觉单词。TNT在同一层使用内外两个transformer block分别对视觉单词和视觉句子进行特征提取和关系建模。视觉单词的特征会通过一个线性映射然后加到视觉句子的特征上,增强视觉句子在细粒度表达上的不足。最终,class token会把所有视觉句子的特征做一个汇总,作为整张图片的特征表示。
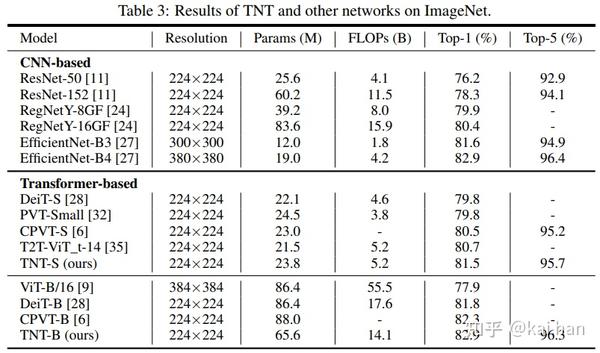
- 纯transformer目标检测
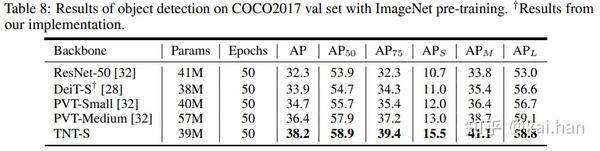
我们用TNT作为Backbone,和DETR(End-to-end object detection with transformers)结合,构建了一个纯transformer结构的目标检测器。在COCO目标检测任务上,TNT要优于现有的DeiT和PVT等。
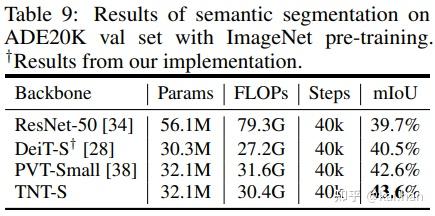
纯transformer图像分割
我们用TNT作为Backbone,和Trans2Seg(Segmenting transparent object in the wild with transformer)结合,构建了一个纯transformer结构的图像分割模型。在ADE20K图像分割任务上,TNT要优于现有的DeiT和PVT等。
代码解读
TNT的代码已经开源在:https://github.com/huawei-noah/CV-Backbones/tree/master/tnt\_pytorch
代码实现很简单,输入图片首先处理成Patch和sub-patches:

网络结构和原有ViT的区别在于使用TNT block代替原有block:
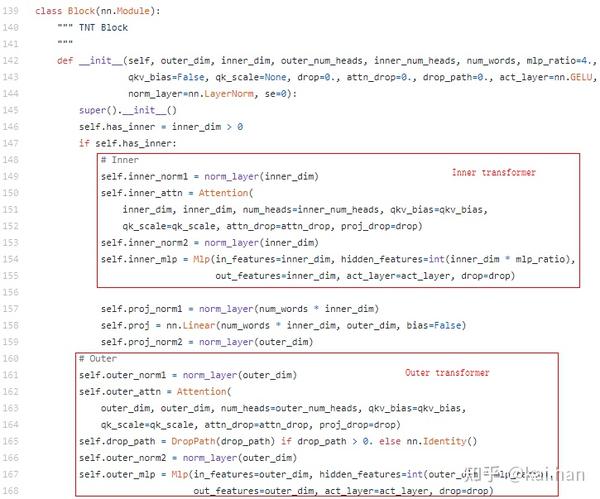
其余部分和原ViT保持一致。
- -
END
原文:知乎
作者:kai.han
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

