
来源:知乎
作者:金雪峰
本次小伙伴们带来的是PLDI 2021的论文《DNNFusion-Accelerating Deep Neural Networks Execution with Advanced Operator Fusion》分析,里面对fusion做了一个分类,很有参考价值
论文链接:
https://dl.acm.org/doi/10.1145/3453483.3454083dl.acm.org
背景与动机
深度学习网络在编译阶段可以展开为算子图结构,典型的算子如Add, Softmax,Conv等等,由于深度学习网络层数深,结构复杂,生成的算子数量众多,带了巨大的计算资源在和时间的消耗。业界对于加速算子的计算展开了一定研究,比较经典的方法是将多个算子重新组合成一个新的算子,同时对生成的代码进行底层的性能优化,较知名的如TensorfLow XLA, TVM[1]等等。融合成新算子后计算相对于多个单算子分别计算的好处是可以实现内存复用,并提高GPU、CPU、寄存器等计算资源的利用率。之前的研究在进行算子融合变换时对算子的属性要求相对严格,而错过了一些可以融合的优化机会,并没有彻底的利用好硬件性能。我们需要更通用的融合策略,从而能全面覆盖所有可融合场景。
本文概述
本文提出依据算子属性对算子合理的进行类别划分,按类型融合,具有更好覆盖性和融合识别能力,加速了计算。 模型命名为DNNFusion,主要包括三部分:1)代数化简部分,即将图层上的数学表达替换为更高效的模式 2)算子融合部分,依据自定义的类别划分和融合算法将1或多个算子融合成一个新算子 3)后续优化。
方案介绍
代数化简
代数化简是一个在算子层加速中较通用的手段,即将某种特定的tensor计算转化为数学上等价的tensor计算,转化后的计算方式须较转化之前的计算方式计算量更小。下图为几个转化案例:
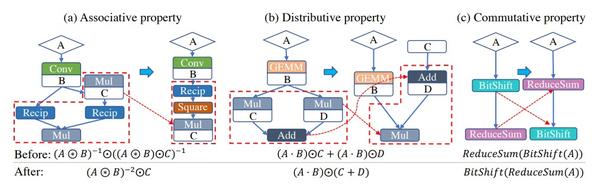
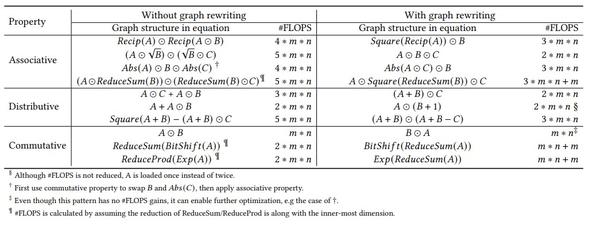
DNNFusion中也应用了代数化简,作者将代数化简分为结合律、分配律和交换律三类,共包含45条结合律化简,38条分配律化简和66条交换律化简。下图具体列举了一些实例。
算子融合
算子融合时将多个算子融合成一个新算子,可以实现内存复用,并提高计算机资源的利用率。经典工具如TVM 采用相对固定的schedule模板,本文提出了将算子类型分类,并根据类别进行融合的方法,提高了处理过程中的灵活性和覆盖性。
对于算子类别,本文作者将其分为One-to-One,One-to-Many, Many-to-Many, Reorganize, Shuffle五类,具体如下:
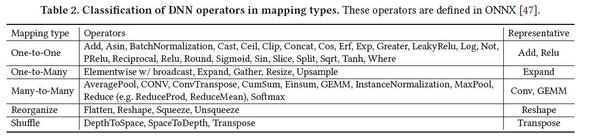
作者给予了各类的数学表达:

这里面我们考虑input和output tensor中不同index上的数字的映射关系,One-to-One表示
input上的i位与output上i位存在一对一映射关系;One-to-Many表示input上的i位与output上多位是映射关系;One-to-Many表示input上多位与output上多位是映射关系;Reorganize和Shuffle同样也是一对一映射关系,但是二者相对One-to-One的不同是,从input到output的映射存在index的转换,比如input的i位数字可能映射到output的j位数字,其中Shuffle相对于Reorganize更为严格,其index映射关系须为permutation类。
那么对于基础算子我们已经给予好了分类,接下来就是融合策略,在指定融合策略的时候我们只需考虑相邻两个算子是否融合即可,因为当相邻两个算子形成一个融合算子后,我们将这个融合算子视为一个新的独立算子,并通过递归继续考虑其与前后算子是否可以继续融合。
那么如何定义融合后形成的新算子类型呢,作者给出的方案是:如果A和B都是同一种类型x,那么融合后的AB依旧是x;如何A是x,B是y, 那么选取x和y中较复杂的类型来作为AB的类型。具体来说One-to-One的复杂度最低,Reorganize和Shuffle的复杂度居中,One-to-Many 和Many-to-Many的复杂度最高。具体转换关系见下图:
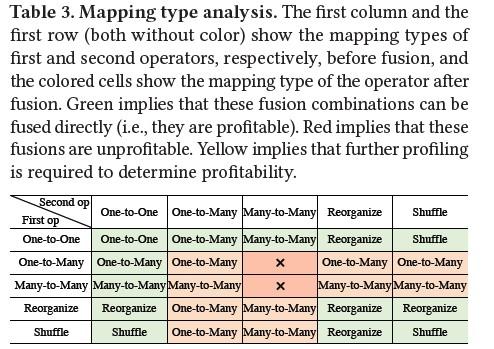
那么最后一个问题便是:什么时候可以融合呢?
上图中的绿色区域代表一定可以融合的场景,红色区域代表(One-to-Many与Many-to-Many, Many-to-Many与Many-to-Many)代表一定不能融的场景,橙色区域部分代表不确定融合后是否有收益,作者用了ML的方式来根据具体场景来判断是否融合。
具体为什么这么做的原因作者给予了解释:
One-to-One与其它:One-to-One类型与其他类型融合可减少多余数据拷贝,占用寄存器少,融合有收益;
- Reorganize、Shuffle与其它:Reorganize、Shuffle仅在One-to-One上加了特殊点对点映射函数,本质没有变化,理由同a
- One-to-Many与Many-to-Many:Expand+Conv为例,Conv希望可以连续的读取内存数据,而Expand可能将该数据打散,性能劣化;
- Many-to-Many 与Many-to-Many: Conv+Conv为例,算子过于复杂,影响cache和寄存器的合理使用,性能劣化
- Many-to-Many 与One-to-Many:需要分情况讨论:例如Conv+Expand,如Expand只针对一维扩展,则影响不到conv的计算;而Conv+Resize,Resize会影响多个维度的数据,从而影响conv的计算;所以这种模式是否有收益待定。
后续优化
主要包括两点,第一是一些变形算子的消除,比如在一些情况下变形算子的output只被一个算子用,变形后的data locality的好处并不能抵消拷贝数据带来的时间消耗,这种情况会对变形算子进行消除,下图为一个例子:
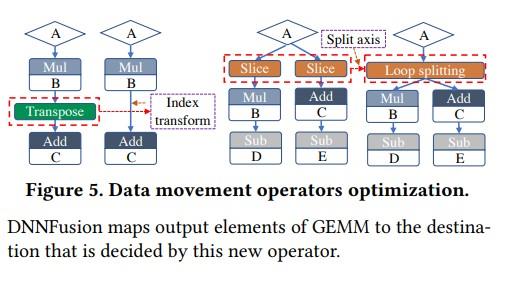
第二点是从全局角度消除不必要format转化,以Transpose为例,从算子图全局考虑往往会有多个transpose等算子对tensor进行format转换,作者希望在保证结果一致的前提下,尽可能消除不必要的format转换。作者使用了贪心算法,从受format影响最大的复杂算子(Conv、GEMM、Softmax等)出发,为其选取最优format,延伸开来,统一其他算子的format并消除不必要format转换。
实验评估
作者选取了多种神经网络模型的推理部分进行mobile端实验,实验中DNNFusion会以PatDNN[2](该团队之前提出的针对算子的底层代码加速工具) 为基础,结果如下(OurB代表不开DNNFusion,即为baseline):
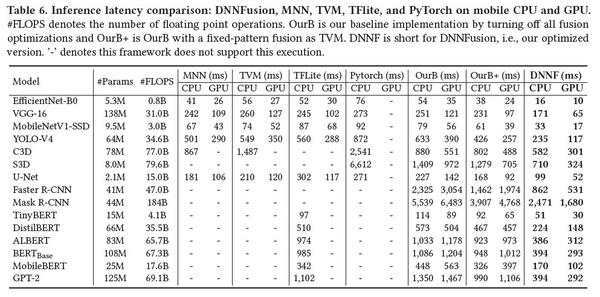
可见该模型在mobile端的模型推理上加速效果明显。
Reference
1. Tianqi Chen\, Thierry Moreau\, Ziheng Jiang\, Lianmin Zheng\, Eddie Yan\, Haichen Shen\, Meghan Cowan\, Leyuan Wang\, Yuwei Hu\, Luis Ceze\, Carlos Guestrin\, and Arvind Krishnamurthy. 2018. TVM: An automated end-to-end optimizing compiler for deep learning. In OSDI 2018. 578–594
2. Wei Niu\, Xiaolong Ma\, Sheng Lin\, Shihao Wang\, Xuehai Qian\, Xue Lin\, Yanzhi Wang\, and Bin Ren. 2020. Patdnn: Achieving real-time DNN execution on mobile devices with pattern-based weight pruning. In ASPLOS 2020. 907–922

