
文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)
原文地址 | 文本数据增强
原文作者 | 角灰
最近在做新闻标题分类,找了篇数据增强的文章学习学习:
一篇就够!数据增强方法综述
本文实现了EDA(简单数据增强)和回译:
一. EDA
1.1 随机替换

import random
import jieba
import numpy as np
import paddle
from paddlenlp.embeddings import TokenEmbedding
# 从词向量中按余弦相似度找与某个词的topk近义词
def get_similar_tokens_raw(query_token, k, token_embedding):
W = np.asarray(token_embedding.weight.numpy())
x = np.asarray(token_embedding.search(query_token).reshape(-1))
cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
# argpartition在k个位置放第k大的索引,左边比他小,右边比他大,复杂度仅o(n)
# 取-k则在-k和他右边的为topk,对他们再排次序就好了
indices = np.argpartition(flat, -k)[-k:]
indices = indices[np.argsort(-flat[indices])] # 取负从大到小排
return token_embedding.vocab.to_tokens(indices)
# 随机替换
def random_replace(words,token_embedding,prob=0.1,max_change=3):
change_num=0
for idx in range(len(words)):
prob_i=prob*(len(words[idx])-0.5) # -0.5使得长度1的词概率乘2,不易选中
if random.uniform(0,1)<prob_i: # 词越长,越容易被替换
sim_words=get_similar_tokens_raw(words[idx],k=5,token_embedding=token_embedding)
words[idx]=random.choice(sim_words)
change_num+=1
if change_num>=max_change:
break
return words由于get_similar_tokens_raw一次只能取一个词的近义词较慢,于是改成了一次取多个词的近义词,效果如下: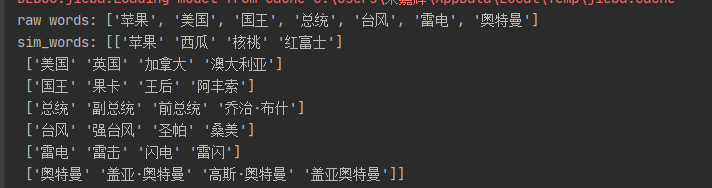
# 查询多个词的topk近义词
def get_similar_tokens_multi(query_tokens, k, token_embedding):
n_tokens=len(query_tokens)
W = paddle.to_tensor(token_embedding.weight.detach(),dtype='float16')
q_idx=token_embedding.search(query_tokens)
x = paddle.to_tensor(q_idx,dtype='float16').transpose((1,0))
cos = paddle.matmul(W, x) / paddle.sqrt(paddle.sum(W * W, axis=1,keepdim=True) * paddle.sum(x * x,keepdim=True) + 1e-9)
def sort_row_by_idx(input, indices):
assert input.shape == indices.shape
row, col = input.shape
indices = indices * col + np.arange(0, col)
indices = indices.reshape(-1)
input = input.reshape(-1)[indices].reshape(row, -1)
return input
part_indices = np.argpartition(cos.numpy(), -k, axis=0)
out = sort_row_by_idx(cos.numpy(), part_indices)[-k:, :]
new_idx = np.argsort(-out, axis=0)
# 用新的索引对旧的part的索引排序
indices = sort_row_by_idx(part_indices[-k:, :], new_idx).reshape(-1)
sim_tokens=token_embedding.vocab.to_tokens(indices)
sim_tokens=np.array(sim_tokens).reshape(k,n_tokens)
if k>=2:sim_tokens=sim_tokens[:-1,:]
return sim_tokens.transpose()
# 相应的随机替换(此函数会多返回个近义词列表,供随机插入使用)
def random_replace(words,token_embedding,prob=0.1,max_change=3):
words=np.array(words)
probs=np.random.uniform(0,1,(len(words),))
words_len=np.array([len(word) for word in words])-0.5 # 惩罚1的
probs=probs/words_len
mask=probs<prob
if sum(mask)>1:
replace_words=words[mask].tolist()
sim_words=get_similar_tokens_multi(query_tokens=replace_words,k=5,token_embedding=token_embedding)
choosed=[]
for row in sim_words:
choosed.append(np.random.choice(row))
words[mask]=np.array(choosed)
return words.tolist(),sim_words.flatten().tolist()
return words.tolist(),[]
if __name__ == '__main__':
token_embedding=TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 近义词查找
words=['苹果','美国','国王','总统','台风','雷电','奥特曼']
sim_words=get_similar_tokens_multi(query_tokens=words,k=5,token_embedding=token_embedding)
print('raw words:',words)
print('sim_words:',sim_words)1.2 随机插入
随机在语句中插入n个词 (从随机替换返回的近义词列表sim_words采样,如果sim_words=None,则从原句中随机采样)
def random_insertion(words,sim_words=None,n=3):
new_words = words.copy()
for _ in range(n):
add_word(new_words,sim_words)
return new_words
def add_word(new_words,sim_words=None):
random_synonym = random.choice(sim_words) if sim_words else random.choice(new_words)
random_idx = random.randint(0, len(new_words) - 1)
new_words.insert(random_idx, random_synonym) # 随机插入1.3 随机删除
对句子中每个词依概率p随机删除,此处按词长度加权,越长越不易被删除,代码如下:

def random_deletion(words,prob=0.1):
probs=np.random.uniform(0,1,(len(words),))
words_len=np.array([len(word) for word in words])
# 对长词加大权重,防止被删除重要词
probs=probs*words_len
mask=probs>prob
return np.array(words)[mask].tolist()1.4 随机置换临近词
人在读阅句子时,往往乱打顺序也能理句解意,不信您回过去再读一遍哈哈,代码如下:
# 先获取词索引,再对某个词添加个噪声noise∈[0,n],n(window_size)一般取3,然后
# 重新排序后就能达到目的了
def random_permute(words,window_size):
noise=np.random.uniform(0,window_size,size=(len(words),))
idx=np.arange(0,len(words))
new_idx=np.argsort(noise+idx)
return np.array(words)[new_idx].tolist()二. 回译
回译是机器翻译里常用的对单语语料进行增强方法:对目标端单语语料t,利用反向翻译模型(tgt2src)生成源端的伪数据s’,从而让正向的src2tgt翻译模型使用伪平行语料(s’,t)继续训练。
本文使用预训练的mbart50(50种语言)进行回译,可以对原始语料zh,进行如下方向翻译:
中->法->xxxx->英->中,简单起见本文就进行中英中回译:
回译示例: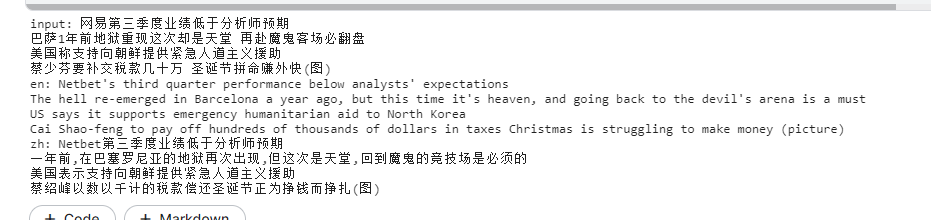
import torch
from transformers import MBartForConditionalGeneration,MBart50TokenizerFast
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
model.eval()
batch_sentences=['网易第三季度业绩低于分析师预期',
'巴萨1年前地狱重现这次却是天堂 再赴魔鬼客场必翻盘',
'美国称支持向朝鲜提供紧急人道主义援助',
'蔡少芬要补交税款几十万 圣诞节拼命赚外快(图)']
print('input:','\n'.join(batch_sentences))
# 中->英
tokenizer.src_lang='zh_CN' # 设置输入为中文
batch_tokenized = tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,padding=True, pad_to_max_length=True)
input_dict = {'input_ids':torch.LongTensor(batch_tokenized['input_ids']).to(device),
"attention_mask":torch.LongTensor(batch_tokenized['attention_mask']).to(device)}
batch_tokens=model.generate(**input_dict,forced_bos_token_id=tokenizer.lang_code_to_id['en_XX']) # 输出为英文
en_sent=tokenizer.batch_decode(batch_tokens, skip_special_tokens=True)
print('en:','\n'.join(en_sent))
# 英->中
tokenizer.src_lang='en_XX' # 设置输入为英文
batch_tokenized = tokenizer.batch_encode_plus(en_sent, add_special_tokens=True,padding=True, pad_to_max_length=True)
input_dict = {'input_ids':torch.LongTensor(batch_tokenized['input_ids']).to(device),
"attention_mask":torch.LongTensor(batch_tokenized['attention_mask']).to(device)}
batch_tokens=model.generate(**input_dict,forced_bos_token_id=tokenizer.lang_code_to_id['zh_CN']) # 输出为中文
zh_sent=tokenizer.batch_decode(batch_tokens, skip_special_tokens=True)
print('zh:','\n'.join(zh_sent))
'''
mbart50覆盖如下语言:
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI
'''# 离线回译增强,将文本文件按行回译,
import torch
from functools import partial
from transformers import MBartForConditionalGeneration,MBart50TokenizerFast
from tqdm import tqdm
def get_data_iterator(input_path):
with open(input_path, 'r', encoding="utf-8") as f:
for line in f.readlines():
line=line.strip()
yield line
# 迭代器: 生成一个batch的数据
def get_batch_iterator(data_path, batch_size=32,drop_last=False):
keras_bert_iter = get_data_iterator(data_path)
continue_iterator = True
while True:
batch_data = []
for _ in range(batch_size):
try:
data = next(keras_bert_iter)
batch_data.append(data)
except StopIteration:
continue_iterator = False
break
if continue_iterator:# 刚好一个batch
yield batch_data
else: # 不足一batch
if not drop_last:
yield batch_data
return StopIteration
@torch.no_grad()
def batch_translation(batch_sentences,model,tokenizer,src_lang,tgt_lang,max_len=128):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
tokenizer.src_lang=src_lang
# token2id
encoded_inputs=tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,
padding=True, pad_to_max_length=True)
# max_length=max_len, pad_to_max_length=True)
# list->tensor
encoded_inputs['input_ids']=torch.LongTensor(encoded_inputs['input_ids']).to(device)
encoded_inputs['attention_mask']=torch.LongTensor(encoded_inputs['attention_mask']).to(device)
# generate
batch_tokens = model.generate(**encoded_inputs, forced_bos_token_id=tokenizer.lang_code_to_id[tgt_lang])
# decode
tgt_sentences = tokenizer.batch_decode(batch_tokens, skip_special_tokens=True)
return tgt_sentences
def translate_file(src_path,tgt_path,src_lang,tgt_lang,batch_size=32,max_len=128):
# data
batch_iter=get_batch_iterator(src_path,batch_size=batch_size)
# model
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
src2tgt_fn = partial(batch_translation, model=model, tokenizer=tokenizer,
src_lang=src_lang, tgt_lang=tgt_lang,max_len=None)
result=[]
i=0
for batch_sentences in tqdm(batch_iter):
tgt_sentences = src2tgt_fn(batch_sentences)
result.extend(tgt_sentences)
if i%100==0:
print(f'src:{batch_sentences[0]}==>tgt:{tgt_sentences[0]}')
i+=1
# write 2 file
with open(tgt_path,'w',encoding='utf-8') as f:
f.write('\n'.join(result))
print(f'write 2 {tgt_path} success.')
if __name__ == '__main__':
src_path='train.txt'
mid_path='train.en'
tgt_path='train_back.txt'
# translate zh to en
translate_file(src_path, mid_path, src_lang='zh_CN', tgt_lang='en_XX', batch_size=16)
# translate en to zh
translate_file(mid_path, tgt_path, src_lang='en_XX', tgt_lang='zh_CN', batch_size=16)总结:
数据增强作用有限,接下来准备在相关任务数据上继续预训练。
参考:
1.一篇就够!数据增强方法综述
2.回译
3.mbart50
4.机器翻译:基础和模型

