
前段赵捷、蒋力、田野以及淡孝强几位老师进行了分享,同时我也介绍了一下个人对AI编译器的理解以及MindSpore团队在这个领域的一些实践。
今天抽了点时间,结合以前分享的材料(前面写了比较多的关于AI编译器方面博文,但是以前的博文都是偏向于散点),以及昇思-MindSpore的实践,系统把内容梳理一下,希望给大家一个相对完整的AI编译器的视图,对大家有所启发。
文章主要分为四个部分:
- AI编译器的概览
- AI编译器的挑战
- MindSpore的实践
- 未来的展望
1、AI编译器的概览
AI编译器的定义
首先介绍一下,个人对AI编译器的一个理解:
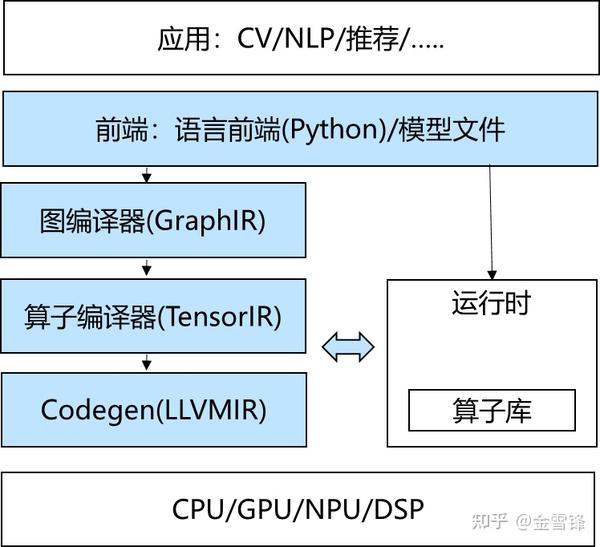
与传统编译器相比,AI编译器是一个领域特定的编译器,有四个明显的特征:
1、Python为主的动态解释器语言前端
与传统编译器不同,AI编译器通常不需要Lexer/Parser,而是基于前端语言(主要是Python)的AST将模型解析并构造为计算图IR,侧重于保留shape、layout等Tensor计算特征信息,当然部分编译器还能保留控制流的信息。
这里的难点在于,Python是一种灵活度极高的解释执行的语言,AI编译器需要把它转到静态的IR上。
2、多层IR设计:
为什么需要多层IR设计,主要是为了同时满足易用性与高性能这两类需求。为了让开发者使用方便,框架前端(图层)会尽量对Tensor计算进行抽象封装,开发者只要关注逻辑意义上的模型和算子;而在后端算子性能优化时,又可以打破算子的边界,从更细粒度的循环调度等维度,结合不同的硬件特点完成优化。因此,多层IR设计无疑是较好的选择。
- 图编译器:
如MindSpore的MindCompiler(MindIR)、TF的XLA(HLO),TVM的Relay等,重点关注非循环相关的优化。除了传统编译器中常见的常量折叠、代数化简、公共子表达式等优化外,还会完成Layout转换,算子融合等优化,通过分析和优化现有网络计算图逻辑,对原有计算逻辑进行拆分、重组、融合等操作,以减少算子执行间隙的开销并且提升设备计算资源利用率,从而实现网络整体执行时间的优化。
- 算子编译器
如MindSpore AKG、CANN TBE、TVM(HalideIR)等。针对Low-level IR主要有循环变换、循环切分等调度相关的优化,与硬件intrinsic映射、内存分配等后端pass优化。其中,当前的自动调度优化主要包含了基于搜索的自动调度优化(如ansor[8])和基于polyhedral编译技术的自动调度优化(如TC和MindAKG[9])
- Codegen
当前基本上收敛在LLVM上。
最后还有一个是MLIR,它实际上一种编译的基础设施。
3、面向神经网络的特定优化
- 数据类型-Tensor:AI领域,计算被抽象成张量的计算,这就意味着AI编译器中主要处理的数据类型也是张量,这个是非常重要的前提。
- 自动微分:BP是深度学习/神经网络最有代表的部分,目前相对已经比较成熟,基于计算图的自动微分、基于Tape和运算符重载的自动微分方案、基于source2source的自动微分都是现在主流的方案。
- 自动并行:随着深度学习的模型规模越来越大,模型的并行优化也成为编译优化的一部分,包括:数据并行、算子级模型并行、Pipeline模型并行、优化器模型并行和重计算等。
4、DSA芯片架构的支持
•SIMT、SIMD、Dataflow:AI的训练和推理对性能和时延都非常敏感,所以大量使用加速器进行计算,所以AI编译器其实是以加速器为中心的编译器,这个也是区别于通用编译器的一个特征。
AI编译器的发展历程
我个人把它分为三个阶段:

第1阶段-朴素的AI编译器:
AI框架的早期主要是两个抽象,一个是基于张量的计算图,分为图和算子;另外一个动态图和静态图。动态图基本上和AI编译器没有太多关联,静态图采用了部分编译器的思想,比如图优化的时候会使用一些硬件无关的优化(表达式化简/常量折叠等)、硬件相关的优化(手工的算子融合)。
问题:
- 表达上:静态图的表达式非Python原生的,开发者主要通过框架提供的API进行显示构图,易用性上不好;
- 性能上:开发者定义的算子粒度未必最能发挥硬件的性能;硬件厂商的提供的缺省的算子库也未必是最优的,在模型和shape确定的情况下,可能还有更有的算子实现;DSA芯片出现加剧了性能上的挑战。
第2阶段-专用的AI编译器:
主要的两个特征:
- 表达上,动态图和静态图趋于一致,意味着AI编译的入口更加与Python原生的表达接近;
- 出现相对独立的AI编译器,聚焦在打开图和算子边界进行融合优化,发挥芯片的算力。
问题:
- 表达上,图层和算子层的表达还是分开的,算法工程师主要关注图层的表达,算子的表达和实现主要是框架开发者和芯片开发者来提供。
- 功能泛化的问题:动静转换的成功率、动态shape、稀疏、分布式并行优化等更多的需求无法满足
- 效率和性能的平衡:算子实现上在schedule、tiling、codegen上缺乏自动化手段,门槛高。
第3阶段-通用的AI编译器:
主要的特征:
•图算统一表达;
•更泛化的优化能力:动静统一、动态shape、稀疏、复数、自动并行等;
•图算融合优化、算子自动生成。
总的来说,个人感觉当前的阶段还是处于2.0~2.3阶段,大家想尽快构建通用AI编译器的能力,但是还有许多关键的问题还没有完全解决。
2、AI编译器发展的驱动力和挑战
个人认为,AI编译器发展的驱动力和挑战主要还是三个:
- Python的静态化
- 怎么发挥硬件的性能,特别是DSA类的芯片
- 如何处理NN的特定优化:自动微分、自动并行等等
挑战1:Python的静态化
Python静态化是指通过JIT等技术,让Python程序进行静态的编译优化,提升性能、方便部署,Python静态化是AI编译器开始工作的一个起点。
业界Python静态化的两种方式:
- 通用Python JIT虚拟机:主要是期望在Python解释执行的基础上增加JIT编译加速的能力,典型的如PyPy;不过由于前期CPython暴露了太多内部接口,导致Python JIT虚拟机兼容的困难。
- 修饰符方式的Python JIT方案:典型的如Numba,Python JIT虚拟机的一种妥协实现方式,通过修饰符,进行部分Python语句加速。

AI框架静态化的方案普遍采用修饰符这套方案,这套方案细分下来也有两种不同的方法:
- Tracing Based
- AST Transform
AI编译器在Python静态化方面的挑战:
- 类型推导:从Python动态类型到编译器IR的静态类型
- 灵活的语法和数据类型转换:slice、dict等
- 控制流的处理
- JIT的编译性能
- .....
挑战2:AI编译器如何使能多样性算力,特别是如何充分发挥DSA芯片的算力
前面提到AI的训练和推理都是对性能非常敏感的,所以在AI的场景中大量用到加速器,包括CPU的SIMD单元、GPU的SIMT架构、NPU这样的专用架构等;AI编译器逐步成为发挥这些多样性算力的关键,特别是近期类Dataflow+SIMD这样的DSA芯片占比逐步提升的情况下:
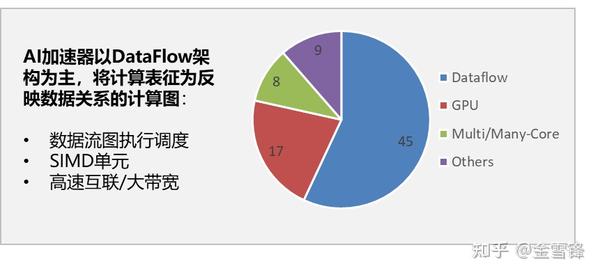
统计数据表明,最近出现的AI芯片中,Dataflow架构占比大于50%,这类架构的特点:
- 数据流图的执行调度更加能发挥芯片的性能,即芯片进行整图或者子图的调度,而不是像GPU那样,主流是 kernel by kernel的调度
- 较强大的Cube处理单元(类SIMD),较为复杂的内存管理机制
同时我们也看到最新NV GPU的H100架构的DSA特征也逐步明显。
AI编译器在性能优化的难度和复杂度挑战变大:
- 性能优化更加依赖图算融合优化,图层和算子层独立优化无法充分发挥芯片性能,需要图算融合优化;子图切分、子图内垂直融合优化和水平并行优化;
- 优化的复杂度提升,标量+向量+张量+加速指令、多级的存储结构,导致Schedule、Tilling、Vectorization/Tensorization复杂。
当前的AI编译器在这一块还没有一个完善的方案:
首先我们看一下AI编译器的普遍需求:
- 打开图和算子的边界,进行重新组合优化
- 多种优化手段:垂直融合优化(buffer fusion等)和水平并行(msa rammer等)优化
- 重新组合优化后的子图的代码自动生成(scheduling、tilling、vectorizing)
其次,我们看一下业界已有的方案:

- XLA:基本上的思路是把图层下发的子图中的算子全部打开成小算子,然后基于这张小算子组成的子图进行编译优化,整体设计主要通过HLO/LLO/LLVM层层lowering实现,算子打开/子图融合优化/融合算子生成的规则都是手工提前指定。
- TVM:分为Relay和TVM两层,Relay关注图层,TVM关注算子层,总体思路与XLA是类似的,Relay做子图的优化、TVM实现融合算子的生成,区别在于TVM是开放的架构,提供了compute和schedule分离的方案,方便定制算子生成的优化。
另外,不得不提MLIR,不过他的定位还是聚焦提供MetaIR,作为构建AI编译器的基础,如果从功能完善性的角度看,目前看还有比较大的差距。
最后总结是:AI编译器目前还没有一个完善的解决方案,仍在持续演进
挑战3:面向NN领域的特定优化—自动并行+自动微分
个人认为自动并行和自动微分这两个最为关键
- 自动并行依然是大模型训练的一个难题:
当前大模型训练碰到碰到的内存墙、性能墙依赖复杂的切分策略来解决,包括:
- Scale out:多维混合并行能力,含:数据并行、算子级模型并行、流水线并行、优化器并行等
- Scale up:重计算、Host/Devcie并行等
这种方式最大的挑战就是效率墙:如果依赖手工去配置切分策略,对算法工程师来说,门槛高,效率低;当前类似半自动并行的方式可以解决一部分效率的问题,但是真正要解放工程师还是依赖编译+寻优结合,自动化的找到并行策略。
- 面向未来AI+科学计算场景,自动微分的要求更高,是另外一个挑战
这里有两个大的难题:
控制流:传统的自动微分都是通过控制流展开方式来解决问题,动态图通过正向在Python侧执行进行控制流展开,一旦循环次数多的话,性能劣化;静态图的控制流自动微分目前还没有太完善的方案。
高级微分的性能:前向微分+后向微分;Jacobian matrix(雅克比);高阶微分:Hessian matrix(海森矩阵)
3、MindSpore的创新和实践
昇思-MindSpore的AI编译器全景图

昇思-MindSpore的AI编译器总共有五个特点:
- 完整的AI编译器解决方案
- 完善的Python静态化方案
- 为AI领域优化的编译器IR-MindIR(函数式图形IR)
- 充分发挥硬件算力的图算融合+算子自动生成方案
- 针对大规模并行的完整编译优化方案
下面基于这几个特点,展开进行描述。
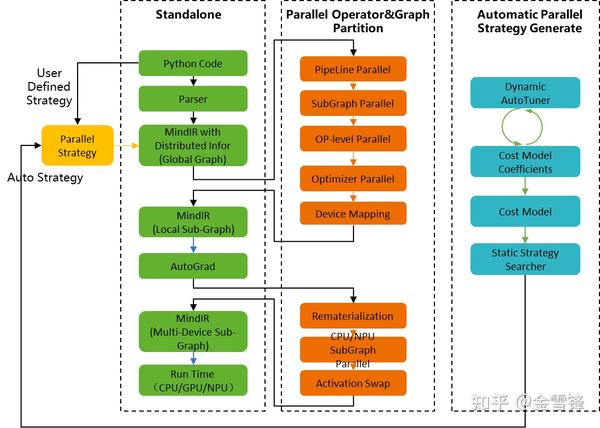
特点1:完整的AI编译器解决方案
完整主要体现在两个维度:
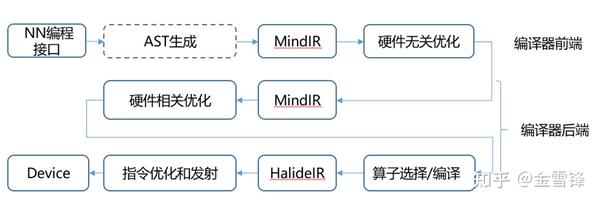
- 纵向提供图编译器(前端/中端/后端)以及算子编译器:
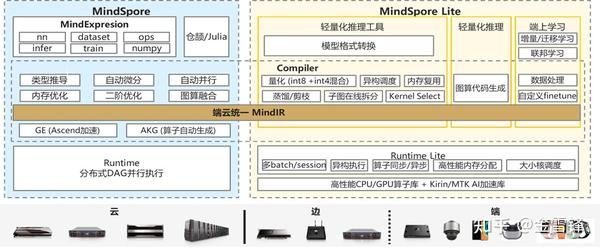
- 横向提供端云统一的编译架构:统一的IR(MindIR)、公共Pass共享
特点2:完善的Python静态化方案
前面提到AI编译器的起点就是把Python表达的AI网络和模型转化为编译器IR,但是这本身是一个非常有挑战性的工作,原因在于:
- Python是动态类型,无法通过AST解析直接确定类型
- Python的语法非常灵活,全量转换工作量大
当前Python静态化的主流方案有两种,如前面介绍的,一种是Tracing based,另外一种是AST transform,可参考:
聊一聊AI框架前端
考虑到Tracing based的方案虽然简单直接,但是由于很难解决控制流的问题以及图算统一表达的问题,所以MindSpore最终采用了AST Transform的方案。
MindSpore静态化方案主要有三个关键点:
- 第1步—语法解析:从AST翻译到MindIR
MindSpore定义了一套相对完整的语法解析规则来进行AST到MindIR的转换:

- 第2步—基于抽象释义的静态分析:完成类型推导和特化
完成了AST到MindIR的转换后,下一步的难点就是如何从Python这种解释性语言中推导出静态类型,并进行常量传播和特化,MindSpore的做法比较类似Julia的JIT方式,从顶层函数图入口开始解释执行,将函数图中所有节点进行拓扑排序,根据节点的语义递归推导各节点的抽象值。当遇到函数子图时,递归进入函数子图进行解释执行,最后返回顶层函数输出节点的抽象值。

- 第3步—JIT Fallback:难以解析的Python语法返回Python解释器去处理
Python是解释性语言,语法比较灵活,想全量从Python转到静态IR上工作量大,难度非常高,有许多语法很难通过AST转换进行全量转换,JIT Fallback机制允许编译期遇到原生不支持语法时,通过Fallback到Python解释器去支持此语法。
AI框架动静态图统一的思考
特点3:为AI领域优化的编译器IR-MindIR(函数式图形IR)
业界编译器的IR按照不同的分类方法,有多种类型
- 分类方法1-按照组织结构:
- 线性IR:三地址代码
- 图IR:V8/JVM,常用于虚拟机
- 混合IR:LLVM
- 分类方法2-按照编程语言的角度:
- 命令式风格:SSA
- 函数式风格:CPS/ANF
AI领域IR有其特殊的需求,包括:
- 自动微分:能够处理控制流、递归、高阶微分等复杂场景
- 隐式并行:程序能根据数据流依赖自动分析可以并行部分
- JIT能力:编译时间要短
MindSpore的解决方案-MindIR(函数式图形IR):
- Functional(函数式)-更自然的自动微分实现方式和更方便的隐式并行分析能力:
- 函数作为一等公民,支持高阶函数,控制流也是特殊的函数,以统一的形式来实现微分,容易处理控制流、递归、高阶微分等复杂场景。
- 函数以无副作用的方式实现,与命令式语言相比,可基于数据依赖的偏序分析,方便的分析出程序的可并行部分,实现隐式并行的能力。
- Graph based(图形IR)-更适合JIT的快速优化能力:
- 采用类似Sea of Nodes IR的只有一层的表示方式,控制流和数据流合一,直接表达used-def,适合JIT优化。
详细的AI框架的IR的介绍以及MindIR的设计,可参见:
AI框架中图层IR的分析
特点4:充分发挥硬件算力的图算融合+算子自动生成方案
AI芯片对AI编译器来说,主要带来两大挑战,性能和开发效率:
- AI芯片的发展对AI框架的关键性能挑战:
- 由于并行度及工艺的快速提升,AI芯片计算能力相比带宽能力提升更快。需要软件通过平衡带宽的能力不足(Buffer融合 – 减少带宽);
- 随着芯片并行度的增加,如何增加融合算子计算并行度,以提升芯片资源利用率。也成为一个重要的性能优化方向(并行融合 – 提高并行度)。
•AI模型的规模和复杂度发展对算子融合的挑战:
- 由于复杂度和规模增加,完全依赖手工算子融合并实现融合算子变得不再可能;
- 业界传统采用图层和算子层严格分层独立的实现方法,为算子融合技术演进带来一定的障碍。
MindSpore的解决方案:
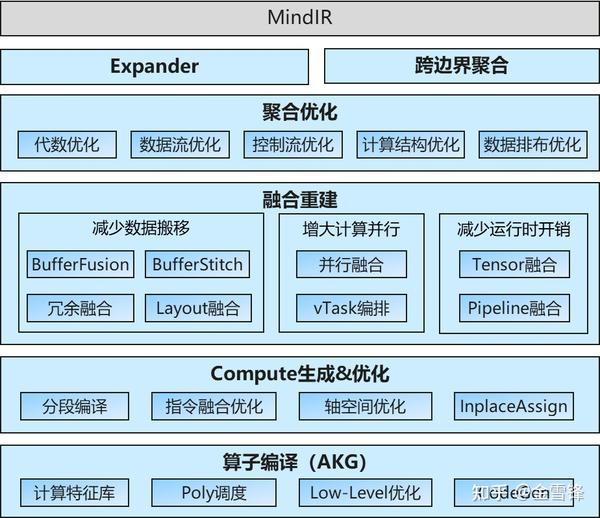
主要是两个关键点:基于多层规约的图算融合引擎、自动算子生成。
整体的流程:基于MindSpore的统一IR MindIR,通过expander的复合算子白盒化,实现对不同网络的无侵入使能和优化;在完成跨边界聚合优化后,实现多层次多维的算子融合重建;包括buffer融合,并行融合,buffer stitch等等;最后,交给算子编译器AKG,完成子图的codegen。
整个方案的构建,实际上花了比较长的时间,三年三篇顶会,从侧面上反映了这个过程。
【MLSys 2022】论文介绍:图算融合Apollo:-基于多层规约的自动算子融合优化框架
PLDI 2021论文分析(一):AKG-NPU上算子自动生成技术探索
53年来国内唯三,MindSpore加速昇腾芯片论文获国际顶会MICRO最佳论文提名
与业界已有的AI编译器的对比:

- 基于多层规约的图算融合引擎:
MindSpore的图算融合引擎充分吸收了当前多类算子融合的技术,并有效的把它们整合在一起。
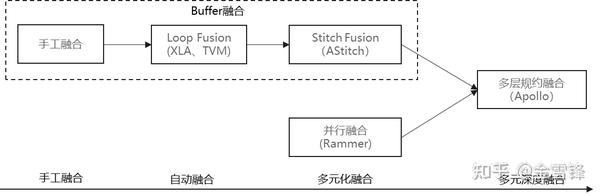
整体的架构如下:
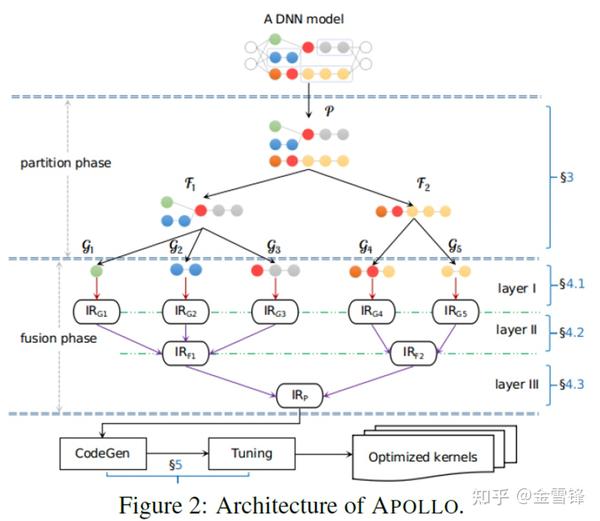
流程主要分为partition和fusion两个阶段。对于输入的DNN模型,在partition阶段,会先完成黑盒白化以及白盒聚合,也就是把复合算子通过扩展器扩展为基本算子的白盒子图,打开原子图边界后,完成跨边界的聚合优化以及计算逻辑优化,包括代数化简常量折叠等等。最后,按照预定的pattern以及costmodel,对计算图拆分为适合codegen的子图;
在fusion阶段,我们提供了多层级的融合方案。在layer1层,主要是完成buffer融合,将子图拆分后的融合子图交给算子编译器AKG,从loop粒度,完成循环变化、调度优化等编译优化。接着,对于AKG生成的子图kernel,通过bufferStitch按照依赖关系对其做buffer拼接,进一步减少访存次数(这部分工作其实跟阿里的Astitch理念上比较类似,实现上不同);最后,对不存在依赖关系的子图kernel,寻求并行融合机会。
- 算子自动生成(AKG)
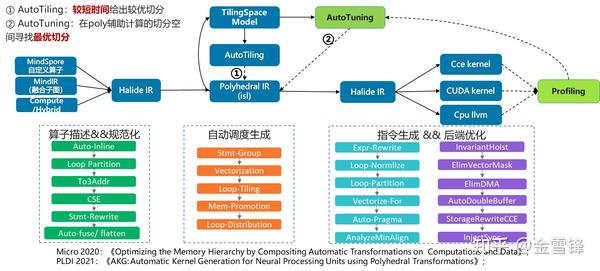
AKG基于TVM开发,但与TVM不同的是,我们是通过polyhedral实现调度自动优化。AKG的输入除了tvm中提供的dsl算子外,还支持图算融合后的子图以及MindSpore提供的python自定义算子。在通过一系列规范化的pass后,将halideIR转为poly模块中的schedule tree,并对schedule tree完成自动调度优化,自动切分,内存搬移等操作,随即转回HalideIR完成后端指令生成及后端优化。在切分策略上,提供了两种模式。对于训练场景,使用autotiling在较短时间给出相对较优的切分,对于性能极致优化场景,我们提供了tuning能力,在poly辅助计算的切分空间中,利用进化算法,costmodel等寻求最优切分。
整套方案同其他编译器相比,主要有两个优势:由于调度是自动完成的,极大降低了开发门槛;对于异构硬件、以及融合算子都能够有较好的支持。
整体的性能提升:
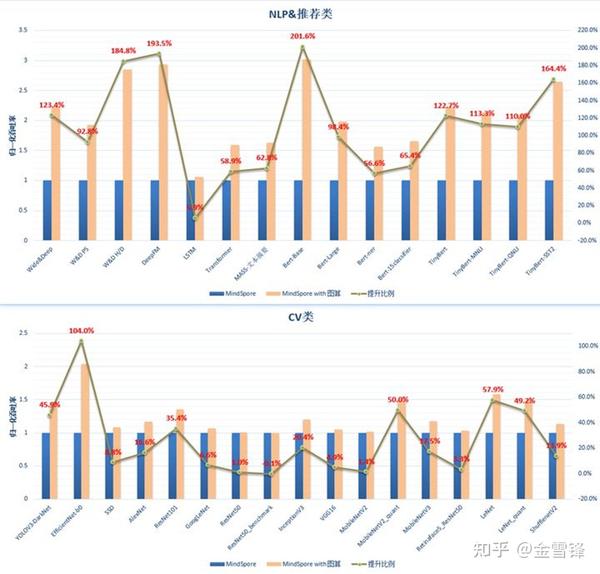
•GPU平台:已经基本实现泛化支持
- NLP、推荐类网络收益明显:NLP类96.4%;推荐类136.6%;
- CV类由于以卷积为主,平均30.7%。
•CPU平台:已打通CPU后端支持
- 强化学习网络提升15~20%,典型NN网络提升17%~33%
特点5:针对大规模并行的完整编译优化方案
MindSpore另一个创新是把AI编译器从单芯片支持拓展到集群支持,在编译中实现通用分布式并行及内存优化。
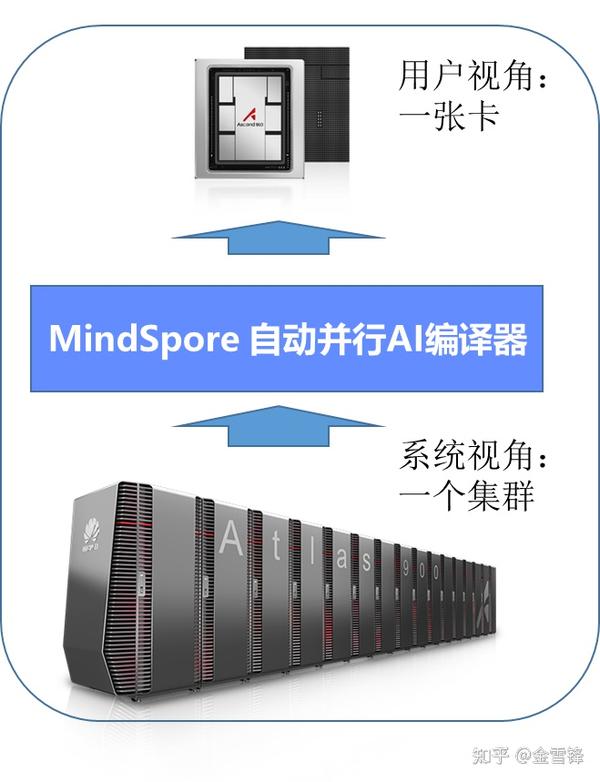
整体的编译流程:
4、未来一些开放性的问题
问题1:AI的图层优化最终是一个什么问题?
整体而言,AI图层的优化当前有三种思路:
- 编译器的优化思路,基于Pattern Match,从搜索算法的本质讲是一种贪心的算法,是局部寻优的思路
- 全局规划的思路,无论是动态规划、还是类似ILP的线性规划也好,都是采用全局寻优的思路,这里的关键是需要一个较好的cost model。
- Tuning的思路,还是全局寻优的思路,但是弱化cost model。
未来图层的优化哪一种方式是主流,或者哪几种方式组合最优。
问题2:图算能否统一表达,统一编译优化,成为一个通用编译器
当前的AI框架下,图层和算子层是分开表达和优化的,算法工程师主要是接触图层的表达,AI框架或者芯片使能的工程师主要是接触算子的表达,但是未来在AI+科学计算的场景下,图层和算子层不再清晰,能否放在一起表达,统一优化?
问题3:完全的自动并行是否可行
在完全的自动并行方面,MindSpore以及学术界都做了有益的探索,但是目前看泛化性还有一些差距,未来能否真正做到自动并行?
大家想了解MindSpore在编译方面的细节,可加入MindSpore社区:
MindSpore官网
原文:知乎
作者:金雪峰
推荐阅读
- SIoU 实现50.3 AP+7.6ms检测速度精度、速度完美超越YoloV5、YoloX
- Sparse RCNN再升级 | ResNet50在不需要NMS和二分匹配的情况下达到48.1AP
- 字节用4大准则教你设计一个拥有CNN的速度,Transformer精度的模型!
更多嵌入式AI相关技术干货请关注嵌入式AI专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

