
论文标题:MoViNets: Mobile Video Networks for Efficient Video Recognition
论文地址:
2103.11511v2.pdf (arxiv.org)arxiv.org/pdf/2103.11511v2.pdf
Google研究院在2021年的工作,意在提出一种像MobileNetV3那样的轻量网络结构,应用于视频理解领域。
由于我也是第一次接触视频理解领域的工作,有很多的技术都很陌生,所以花了不少时间去查资料和理解,如果有不足之处欢迎指正和交流~
0. 简介
3D卷积网络在视频理解领域已经取得了不错的精度,但对于计算量和内存的需求十分巨大,因此暂时不太适用于在线实时推理的场景,更不用说在移动设备上使用了。但动作行为的识别,很多是单张图片分类无法完成的,于是本文针对这一需求,最终提出的网络结构被命名为MoViNets,从三个途径优化了3D卷积网络的计算效率:
- 利用NAS搜索更计算高效的网络结构
- 提出Stream Buffer技术来将视频片段长度与内存占用量解耦
- 利用模型集成来弥补结构优化带来的精度损失
1. 内容
对于视频理解任务而言,很多的情况都跟单帧的图片识别有所不同,其中最大的差异在于时序信息的利用。最早深度学习技术被证明在视频理解任务上有效,就是使用了光流信息的双流网络的提出,随后3D网络在该领域屡创新高,都离不开时序信息的利用。
深度学习技术在视频理解领域的开山之作,双流网络的视频解读可以看这里:
[双流网络论文逐段精读【论文精读】_哔哩哔哩_bilibiliwww.bilibili.com/video/BV1mq4y1x7RU
可以帮助对该领域尚不了解的小伙伴快速入门。
Multi-Clip Evaluation
对于视频而言,随着帧数的增加,内存的使用也越来越大,这很大程度上限制了深度学习技术的应用场景。过去降低内存使用的一个方法是multi-clip evaluation,简单来说,就是通过将一段视频拆分成n个彼此有部分重叠片段的短视频,让网络对每段短视频进行预测后取平均,得到最终的预测结果,这样做可以让计算复杂度从视频长度相关,降低到与短片段长度有关。

然而这样做也存在很明显的不足:
- 拆分以后,网络只会对短片段内的信息进行学习,因此缺少了时间维度上的长距离信息依赖的学习,这对于精度是有影响的。
- 在重叠片段上的计算是重复的,每相邻两个片段都会有一段重叠片段被计算两次,增加了计算冗余。
Stream Buffer
为了解决以上问题,本文提出了用Stream Buffer来缓存特征片段,具体来说,按照以下的流程来进行:
- 初始化一个Buffer片段B,设置为全0的tensor
- 将视频拆分成互不重叠的n个片段
- 将片段B与当前计算的片段x拼接起来,送入网络计算特征图
- 将上一步拼接的结果,截取末尾的b帧,作为新的B
如此一来,每个片段x计算时,都能复用上一个片段的Stream Buffer,且这个Buffer的长度是一个常数,因此计算复杂只与片段长度有关,同时避免了计算冗余。
Causal Operations
要将3D卷积网络应用于实时的视频,其中一个阻碍在于,实时的视频流无法获取很长的时间跨度的片段,除非你愿意等待,而等待又会导致延迟。所以在实时的视频中使用Causal Operations是非常合理的。这里的Causal Operations我也是第一次接触,先暂且将其翻译为因果运算吧。
因果运算具有的一个特性在于,计算是单向的,只允许历史帧参与计算,不允许使用未来帧。
因果卷积
这里我找了一个因果卷积的例子:

通过上图可以清楚地看到,因果卷积的计算是单向的,输入和输出具有时序信息时,未来信息不会参与到对历史的计算。(上图中左边为历史,右边为未来)
在实现上,因果卷积相当于在标准卷积运算的基础上增加了掩码,屏蔽掉了未来信息对历史计算的影响。
另一方面,卷积操作会导致序列长度的缩短,因此需要加入padding操作来维持输出尺寸与输入一致。我们知道,在标准卷积运算中,padding的做法是对称地在两边填充0,但对于时序数据而言,这个操作就有点问题了。
秉承着”我们不能知道未来的数据“的宗旨,在未来的数据后面补0这个操作显然就有点不合理了。
一般的资料里,关于padding的解释就到此为止了,但关于对称padding的不合理之处,这个地方我疑惑了很久,因为我觉得0应该是没有引入新信息的,如果每一个片段都固定地引入0的话,好像跟图片补0一样不会有什么问题,为此查了很多资料。
对称padding不合理之处
我发现几乎所有用到了因果卷积的工作里,都会专门交代一下padding操作是如何处理的,如何将对称padding变为只在历史信息前面补0,这更让我觉得,这么做一定是有原因的,无奈大家都是一句话带过,只说不能知道未来信息。
直到后来我想到了这样一种理解:对于时序数据而言,0其实是有信息的,这跟图片补0操作有所不同。图片padding相当于在周围填充了黑边,由于没有时序信息,这样的一条稳定出现的黑边并不会对结果产生影响。但时序信息不同,时序信息不光是视频片段,还可能是音频、股票、决策等等,对于这些数据而言,0都是有含义的,在这样的未来数据后面加入一个0,显然改变了序列的信息。
padding与Stream Buffer的结合
在本文的实现中,巧妙地将padding与Stream Buffer进行了结合,你卷积为了维持输入输出尺寸不变,不是要通过补0来padding吗?现在也不用补0了,直接把Stream Buffer补在历史数据前面呗,这样不仅不用引入新数据,还利用上了更多的历史信息。
CausalSE & CGAP
CGAP这个操作主要是对GAP的扩展,将GAP应用于特征图的空间维度。说白了这一套操作是想在3D网络上也实现一个SE模块,对于时间维度上进行注意力学习。由于SE中使用的全连接层是顺序无关的,从实验结果上表现不好,作者模仿Transformer的操作,为每一帧增加了sine位置编码。
Temporal Ensembles
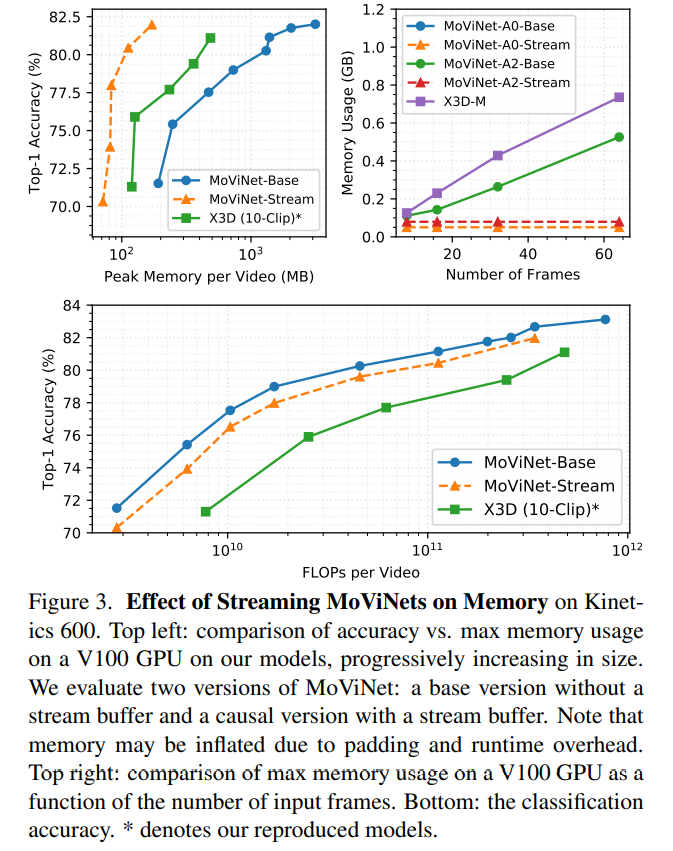
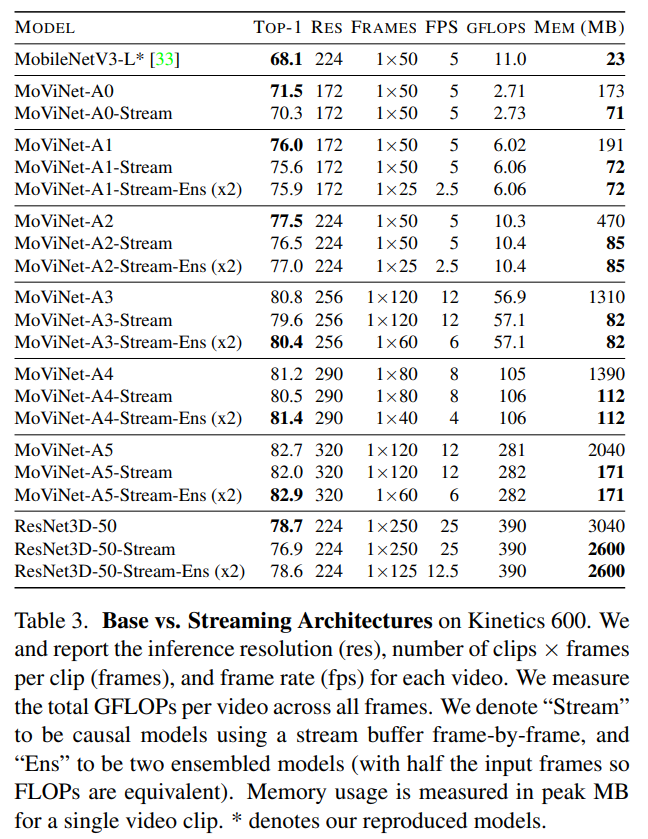
尽管Stream Buffer有效降低了内存开销,但也对模型精度造成了1%左右的损失,于是本文作者想通过模型集成的方式把损失的精度补回来。
提到模型集成大家肯定不陌生,但同时也会想到,模型集成是有代价的,最大的问题在于同样的数据需要推理两遍,增加了延迟,而本文提出的集成方法却可以不增加额外的推理时间。
这个方法其实很简单,由于推理变成了两段,那么就将每一段视频的帧数减半即可,如此一来在总计算量上就保持不变了。
通过实验作者发现,这样的集成方法可以稳定地增加模型精度,尽管并不一定都能追平开Stream Buffer前的精度,但在不增加时间开销的情况下,能补回一些精度总是很好的。尤其是随着模型的增大,二者之间的差距也越来越小。
2. 总结
其实MoViNets优化的第一点就是以MobileNetV3为基础,针对视频数据集进行了NAS,寻找最优的模型结构,但这方面的工作我认为相对来说比较缺乏亮点,因此只放在这里简单提一嘴了。
总而言之,MoViNets系列模型通过NAS、Stream Buffer、Ensemble三个途径,得到了计算量、内存开销、精度上的有效平衡,让实时的视频理解成为现实。
本文进行了大量的实验对比,来验证该系列模型的高效性和广泛适用性。更多的细节,感兴趣的小伙伴可以自行查阅原文~
感谢阅读,如果觉得有所收获的话可以点赞鼓励一下我~
文章来源:知乎
作者: 镜子
推荐阅读
- CAL:低分辨率姿态估计
- DID-M3D:用于单目3D物体检测的解耦实例深度
- ECCV 2022 | SmoothNet:用神经网络代替平滑滤波器,不用重新训练才配叫“即插即用”
- ECCV 2022 | SmoothNet:用神经网络代替平滑滤波器,不用重新训练才配叫“即插即用”
更多嵌入式AI相关技术干货请关注嵌入式AI专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

