
本文为墨天轮社区作者 张sir 原创作品,记录了日常运维Oracle数据库过程中遇到的一个慢SQL问题的解决、优化过程,文章内容全面具体、分析到位,且含有经验总结,分享给各位。

问题现象
这次出问题的数据库比较特殊,承接的系统交易要求很高,SQL基本都是短平快,响应时间基本不能超过50ms,某天凌晨的01:12-01:14在进行压力测试的时候,突然出现短暂的交易延迟变长的情况,有部分交易超时。应用定位到是数据库返回慢了,要求我们排查问题。
问题分析:
步骤一:come on v$ASH
分析这种问题,我是特别喜欢用v$active\_session\_history视图的,虽然oracle也提供了ASH报告的功能,但是总感觉报告提供的内容太多,没法抓住重点。直接查视图,想看什么信息都可以。首先先看看问题时段整体的数据库sql的执行情况,SQL执行时间最长已经到40s左右了,这个时间肯定是无法接受的,而且基本上都是两条SQL:cuw23huyg926x和84m7xzxz0181g。
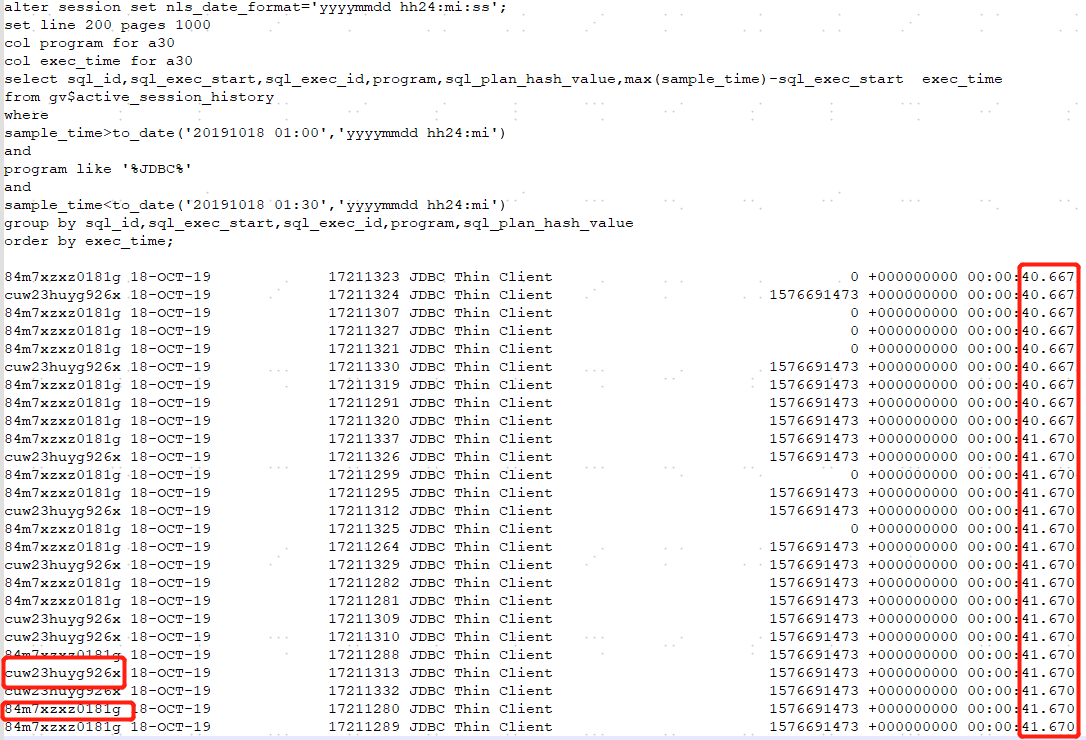
既然找到了慢SQL,那就看看他们的主要的等待事件吧, 通过下面的查询可以看出84m7xzxz0181g主要等待事件是enq: US - contention和row cache lock,cuw23huyg926x的主要等待事件是enq: US - contention。
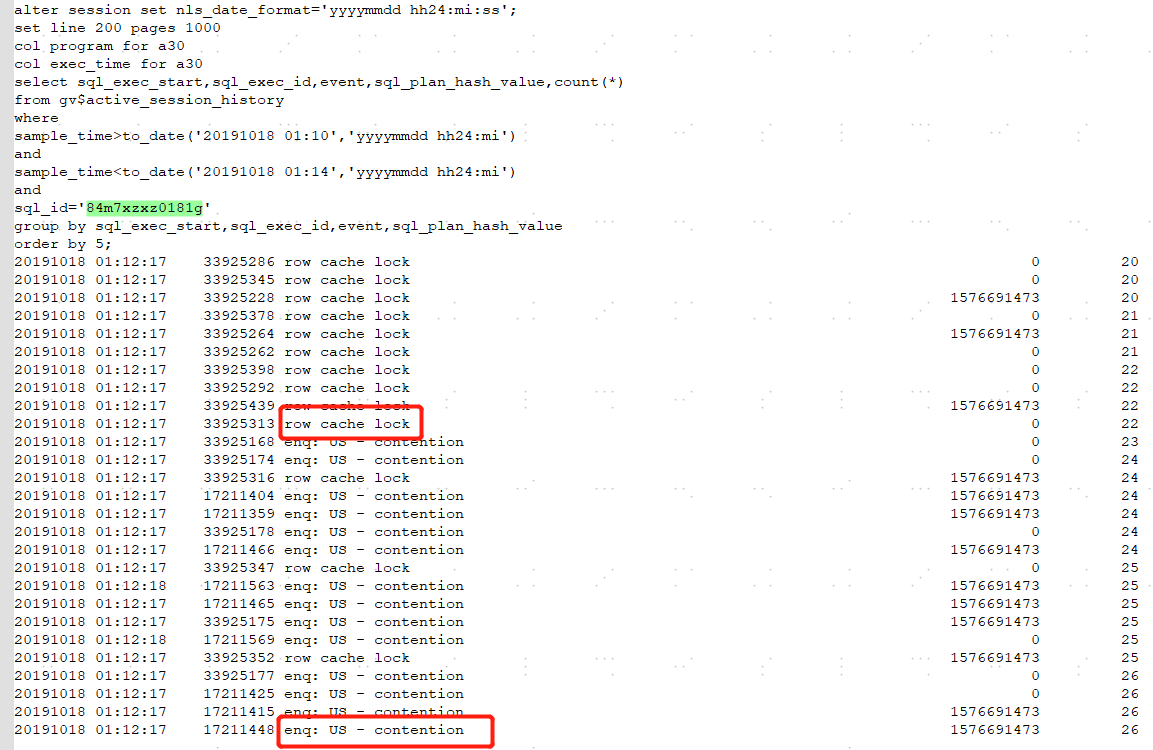
84m7xzxz0181g:
步骤二:等待事件分析
1) 先简单看下这两个等待事件哈:
row cache lock等待事件是一个共享池相关的等待事件,是由于对字典缓冲的访问造成的。每一个行缓冲队列锁都对应一个特定的数据字典对象,这被叫做队列锁类型,并可以在V$ROWCACHE视图中找到。在AWR中需要查看Dictionary Cache Stats部分用以确定问题。常见的原因有如下几点:
① 序列没有设置CACHE属性,导致序列争用。
② 表空间不足引起 表空间的扩展速度跟不上表空间的使用速度会发生该等待事件。
③ Shared Pool不足,需要增加共享池。
④ 用户密码错误或给出了空密码并且频繁登录。
enq: US - contention:这个event说明事务在队列中等待UNDO Segment,通常是由于UNDO空间不足导致的。
在对此事件说明之前,需要理解在使用AUM(atuomatic undo management)时,回滚段在何时联机或脱机。AUM与RBU(rollback segment management)不同,回滚段的管理是Oracle自动完成的。使用AUM时,回滚段的联机或脱机的时刻如下:
1)在执行alter database open的时候将回滚段联机
2)通过alter system set undo_tablespace=xxx 修改撤销表空间时,将原来的回滚段脱机后,再将新的回滚段联机。
3)通过SMON,自动脱机或者联机回滚段,如果一段时间内,事务量增加,联机状态的回滚段也会增加,一段时间内若是没有实物或事务减少,回滚段就会被smon进程脱机。
为了同步将回滚段联机或脱机的过程,执行该工作的服务器进程或后台进程应获得US锁,每个回滚段非配一个US锁,ID1=Undo segment#。若在获得US锁的过程中发生争用,则等待enq:US-contention事件。服务器进程应该在开始事务时分配到回滚段,但如果不存在可用的回滚段时,应该创建新的回滚段或将脱机状态的回滚段联机。在实现此项工作期间,服务器进程为了获得US锁而等待,等待占有可用回滚段。
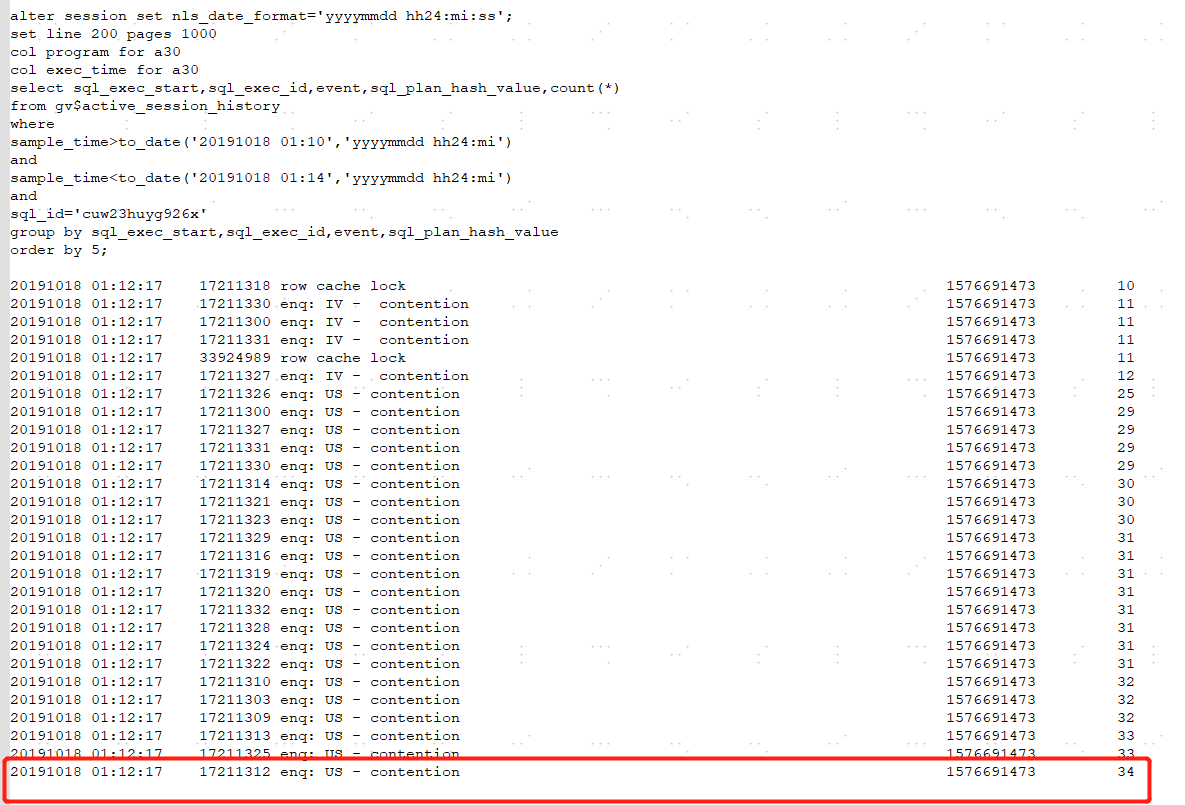
2)第一个等待事件是跟共享池相关的等待事件,我们可以通过v$ash看看具体等待的字典缓冲类型
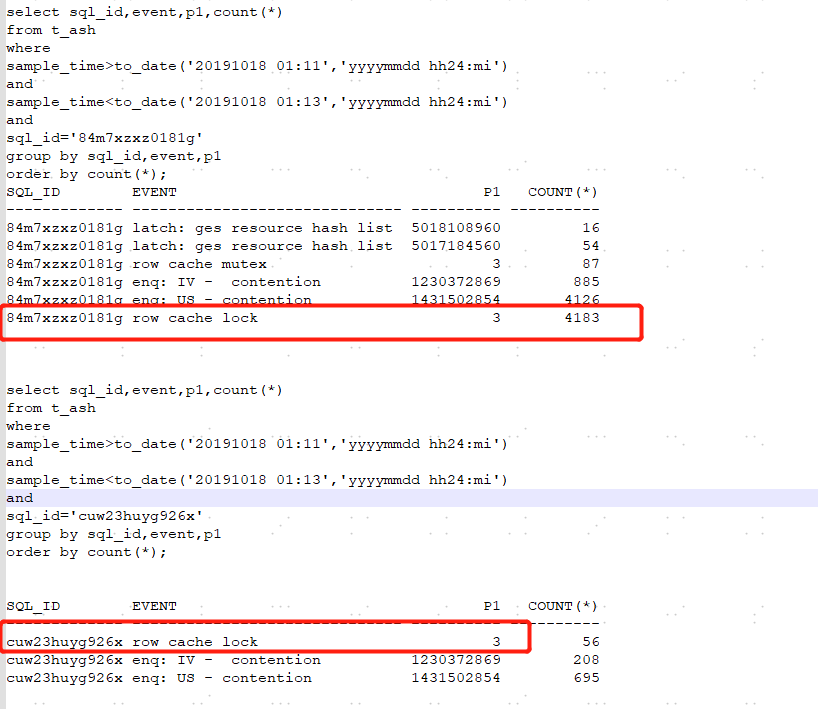
3)看一下等待事件row cahce lock等待的对象是什么,row cache lock 等待事件的P1参数为cache id,根据cache id找到dc,可以看到大部分是等待获取dc\_rollback\_segments,这个等待时间也是在等待获取undo信息。

4)第一个等待事件是字典缓冲的争用,争用的对象是rollback segments,第二个等待事件enq: US - contention也是关于undo segment的等待。根据以上情况可以看出,row cache lock和enq:U - contention是有相关性的,都是由于获取undo的时候产生的争用。但是这个系统其实是采用的分库分表的架构,有多个对等角色的数据库,每套数据库交易量基本一致,那为什么这套库有问题,而别的库没问题呢?
步骤三、继续AWR+v$ASH
以上问题也是我自己的疑问,多套配置相同的数据库,交易量一致,如果说是由于undo引发的,那为啥其他库没问题,单单这套库有问题? 感觉问题的根源还不在这里。继续仔细查看
awr报告,发现问题库的rac节点2的等待事件中有log file sync等待,按理说这是一个正常等待,但是其等待时间超过了2ms,而其他几套库的该等待事件时间都是几百us。

再看下log file parallel write事件,平均等待时间是1.09ms,其他对等数据库的等待时间只有几百us。

去V$ASH里查看这个等待事件的时间分布情况,发现在01:12:16s的时候,log file parallel write执行超过了1s。
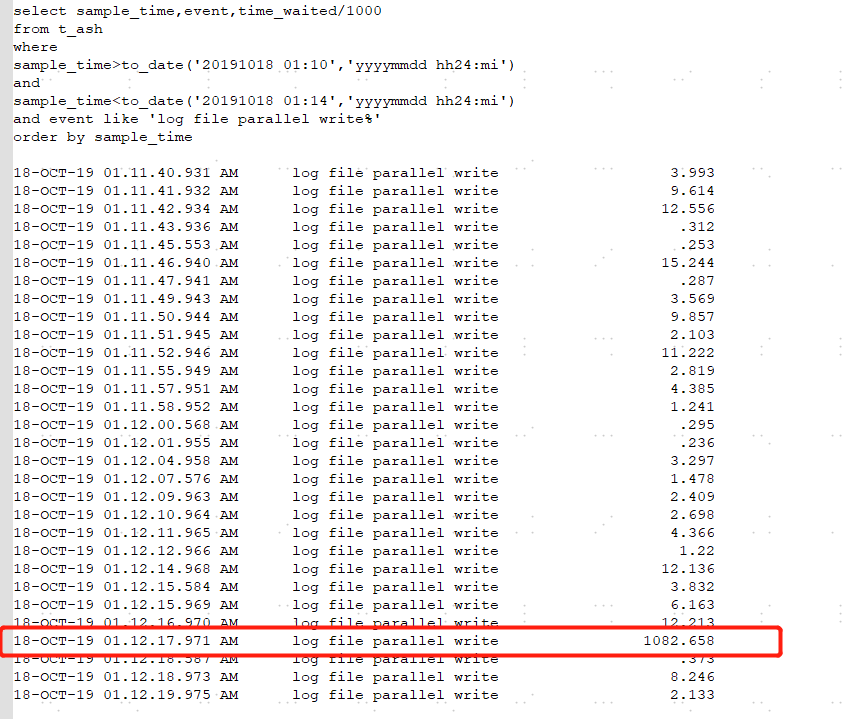
到这里,基本上可以把证据链梳理下了:
压力测试期间,交易量突然上升-----》online的undo segment不足-----》数据库online undo segment-----》发生US锁争用
而IO突然的堵塞,事务无法正常提交,加剧了undo的争用。针对这个问题,我们设置了\_rollback\_segment_count 参数,表示有多少rollback segment要处于online的状态;可以将该数值设置为数据库最繁忙的时候的回滚段数目。
总结:
1、 如果这个系统只有一套数据库,分析到第二步可能就结案了,有同样分库发表的兄弟库做对比,别人都没问题,就你有问题,那说明还有更深层次的原因。
2、 这种IO瞬时的延迟,基本上无解,尤其对于高并发系统,一个IO抖动就可能导致数据库堵塞。整个存储链路也不可能百分之百的一直处于高质量的状态。
3、 对于从v$ash中查到log file parallel write有1s的延迟,这个值的准确性我持怀疑态度,从底层的os、虚拟化、光纤交换机、存储都没看到这么高的延迟。有对这个有研究的老铁,可以讨论下。
阅读原文:https://www.modb.pro/db/486407
本文为【墨力原创作者计划】征文活动投稿作品,活动收录了数百篇Oracle、MySQL、PostgreSQL以及国产数据库相关的文章,包含数据库安装配置、性能调优、故障处理、高可用搭建等主题,此外也有K8s、Java、VUE等优质稿件。大家点击此处可查看有所技术文章。更多数据库故障处理文章可以点击此处查看。
【墨力原创作者计划】活动长期进行中,首次参与活动即有机会获得定制护腰靠枕;参与月更挑战,还可以获得定制U盘、罗技鼠标、华为手环、100-300元现金奖励等奖品,期待您的参与!
具体活动规则可以查看:https://www.modb.pro/db/513210

