
毫无疑问,经过近二十年的信息化和数字化的建设,大部分企业已经从“没有数据”发展到了“数据太多”的阶段。今天,各行各业正在由过去“粗放式”的增长向着数据支撑的“精细化”运营转型,但随之而来的是 ETL 任务的激剧膨胀,企业的整个数据仓库可能充斥着数百万张表,而无数个 ETL 任务不仅会让重复操作变得过多,操作过程复杂,同时还严重耗费时间,可以说这让企业的数据集成工作面临着十分严峻的挑战。
所谓“ETL”,指的是将业务系统的数据经过提取(Extract)、转换清洗(Transform)和加载(Load)到数据仓库、大数据平台的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。也正因此,ETL对任何一家企业来说历来都是“老大难”的问题。数据显示,在企业的BI(商业智能)项目中,构建 ETL 会花掉整个项目至少1/3的时间;而自传统数据仓库理论形成,ETL 构建与维护甚至会占据数据工程师超过70%的工作量。

在此背景下,在刚刚举办的2022亚马逊云科技 re:Invent 全球大会上,亚马逊云科技发布了一系列的全新技术,希望最大化帮助企业减少数据集成带来的痛苦和挑战,而这些新技术、新功能的上线,不仅能够帮助企业的数据工程师实现“减负”,更赋予了数据“无感知”、“更自由”的流动能力,而这也标志着亚马逊云科技向“Zero ETL”——即创造一个没有ETL理想世界的愿景再次迈出重要一步,其价值无疑重要而深远。
天下“苦ETL”久矣的背后
早在1991年,有着“数据仓库之父”称号的比尔·恩门(Bill Inmon)出版了他的第一本关于数据仓库的著作《Building the Data Warehouse》,标志着数据仓库概念的正式确立,而历经三十多年的发展,数据仓库大概经历了三个阶段的发展。
从早期诸如 Teradata、Greenplum 为代表传统数仓时代,到后来离线存储计算平台(Hadoop、Hive、Spark、Flink)和实时数仓技术(Druid、Clickhouse、Doris)与平台同时涌现的湖仓并存时代,技术在发展的浪潮下快速迭代,以云原生数仓为中心的现代数据栈时代已然到来。
但是,无论是何种时代下的数据仓库,都是把业务系统的数据从各个地方汇集过来,通过一系列标准化、规范化的操作,再存起来放在同一个地方,这个过程就是我们通常所说的“ETL”,而要完成这一工作,企业所面临的挑战是巨大的,我们可以从几个维度来做观察:
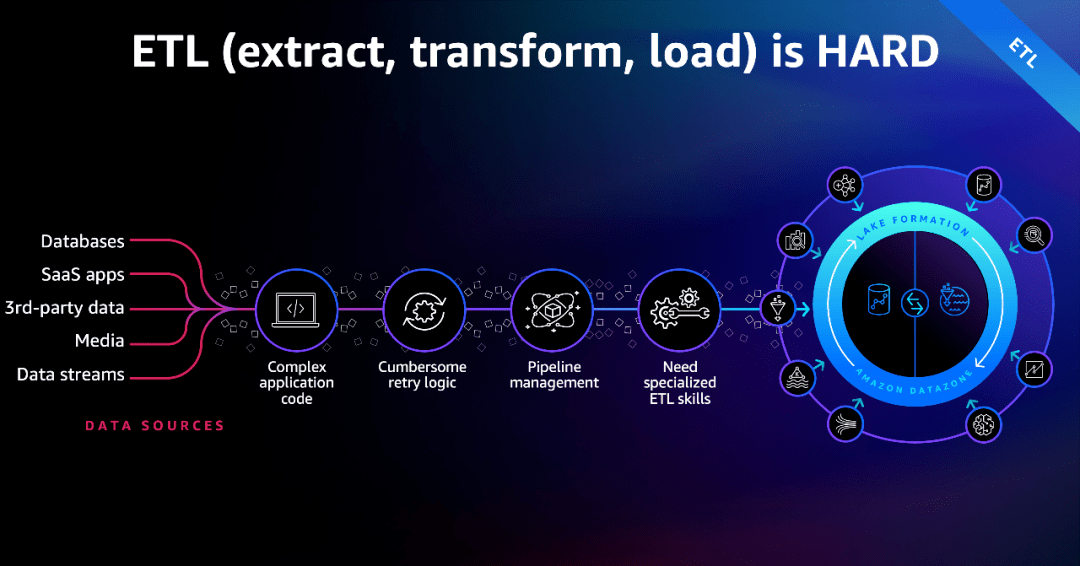
一是,数据量激增的问题,目前虽然可以通过数据上云、湖仓一体的技术解决数据企业数据存储的问题,让企业的数据管理实现更统一,数据接口更标准,分析更自助。但与此同时,随着数据量的爆炸,比如说一家中大型企业的BI项目可能会有几百到几千张的报表,每张报表可能有超过十个以上的指标,这就意味着有几万甚至几十万的业务指标,那么这些口径是不是统一?这些数据是不是在被人使用?以及如何确定这些报表背后的数据价值呢?
二是,ETL“膨胀”的问题,数据的集成工作还会让ETL任务和过程变得“膨胀”。这背后不仅仅只是存储的问题,它带来更大的挑战在于,这一过程中有着无数的ETL的任务,其实在不断地做着重复性的工作,不断地消耗整个数据集群的资源,而每一张报表背后每运行一次,都可能涉及到几百甚至几千的费用,因此对企业而言,如何简化流程,控制成本也是必须要进行认真考量的问题。
三是,选型和维护的问题,主要体现在对于企业的数据工程师而言,当前市面上的ETL工具多,这也代表这选择多和学习成本高,ETL的工具选型就是个难题。除此之外,由ETL“膨胀”难题带来的挑战还体现在,当下越复杂的项目调度任务越多,动辄数千个 ETL 任务的项目已“屡见不鲜”,因此数据工程师要实现任务调度与排查,背后的复杂与维护也是一个巨大的难题。
由此可见,企业的数据集成或者说完成ETL的过程,就是重复操作多,操作流程很繁琐,耗费时间巨多,成本居高不下的过程,因此整个业界也就有了天下“苦ETL”久矣的说法。
“Zero ETL”迈出关键一步
也正是洞察到这种全新的挑战,作为全球云计算、云数据库领域的领导者,亚马逊云科技一直致力于实现“Zero ETL”的愿景,同时也一直在投入开发基于“Zero ETL”理念的技术功能。
此前,亚马逊云科技就实现了Amazon Athena的Federated Query联邦查询功能,可以对存储在关系数据源、非关系数据源、对象数据源和外部自定义数据源中的数据运行 SQL 查询,而无需移动数据。还有流式服务(如Amazon Kinesis 和 Amazon MSK)向数据存储服务(如 Amazon S3)无缝注入数据,从而帮助企业客户及时分析数据。

而在 re:Invent 2022 全球大会上,亚马逊云科技的“Zero ETL”目标又再次迈出“关键一步”——首当其冲的是,就是最新发布的Amazon Aurora zero-ETL与Amazon Redshift集成功能,它可以帮助客户近乎实时地分析 PB 级交易数据。
据了解,借助Amazon Redshift集成的Amazon Aurora zero-ETL功能,企业的交易数据在写入Amazon Aurora后的几秒钟内可以自动连续复制,使其在Amazon Redshift中“即时可用”。而一旦数据在Amazon Redshift中可用,企业客户可立即可以开始分析数据,并且应用数据共享和Amazon Redshift ML等高级功能获得全面的预测性洞察。
更关键的是,企业客户还可以将数据从多个Amazon Aurora数据库集群复制到同一个Amazon Redshift实例,跨多个应用程序获得洞察。这样一来,客户可以使用Amazon Aurora支持交易数据库需求,使用 Amazon Redshift进行分析,而无需构建或维护复杂的数据管道。
那么,Amazon Aurora Zero-ETL to Amazon Redshift最大的好处或者说优势是什么呢?简而言之,这意味着亚马逊云科技打通了Aurora数据库和Redshift 数据仓库,让企业客户不用执行ETL就能进行同步,且不会相互影响各自的正常运行。
换句话说,在过去企业如果需要跑一个ETL的业务,通常的流程是在白天执行ETL业务,把数据库中的数据导入到数据仓库中,在晚上再进行分析;而现在,有了这项集成功能的“加持”之后,企业就可以完全“跳过”ETL的环节,直接在数仓中就能够进行分析,同时不用在中间去构建很多复杂的基础设施,它也能自动保证任务完成。
其次,亚马逊云科技在Amazon Redshift 中的一系列全新实践和创新,同样也是其践行“Zero ETL”理念的最新印证,具体来看:亚马逊云科技宣布Amazon Redshift与Apache Spark实现集成,能够让企业客户可以更加轻松地通过Apache Spark访问Amazon Redshift上的实时数据。

我们知道,亚马逊云科技支持在Amazon EMR、Amazon Glue和Amazon SageMaker上运行Apache Spark,而企业客户通常希望直接从这些服务中分析Amazon Redshift中的数据。但是,这一过程并不轻松,企业需要经历复杂、耗时的过程查找、测试和认证第三方连接器,以在他们的环境和Amazon Redshift之间读取和写入数据,这些流程无疑都显著增加了整个操作的复杂性,使企业客户难以充分利用Apache Spark的价值。
而Amazon Redshift与Apache Spark实现集成,就可以帮助客户在使用亚马逊云科技的分析和机器学习服务时可以更快更轻松地通过 Apache Spark 应用程序访问到 Redshift 上的数据,这样开发人员就可以快速而敏捷地实现分析与机器学习。

在此基础上,亚马逊云科技的Amazon Redshift也支持 Amazon S3 自动复制(预览版),借助这项新功能,Amazon Redshift 会将企业指定到达的 Amazon S3 的文件自动加载到企业的数据仓库中,例如 CSV、JSON、Parquet 和 Avro,无需手动或重复运行复制过程,而Amazon Redshift 可自动提取文件并负责幕后数据的加载步骤;同时,亚马逊云科技最新的Amazon Redshift streaming ingestion 流式数据接入功能也成功上线,该功能可以直接让流式数据接入数据仓库,能够为企业打造云原生实时数仓奠定关键基础,帮助企业可以轻松地探索实时分析场景,同时基于历史数据的实时预测、反欺诈等场景。
最后,为了更大的帮助企业完成数据集成的工作,亚马逊云科技数据服务目前已可以连接超过100种外部数据源,像 Adobe、Salesforce 等各类 SaaS 应用,也包括各类 on-premise 数据源类型,因此企业可借助亚马逊云科技提供的技术和工具,全面释放数据的更多的价值。
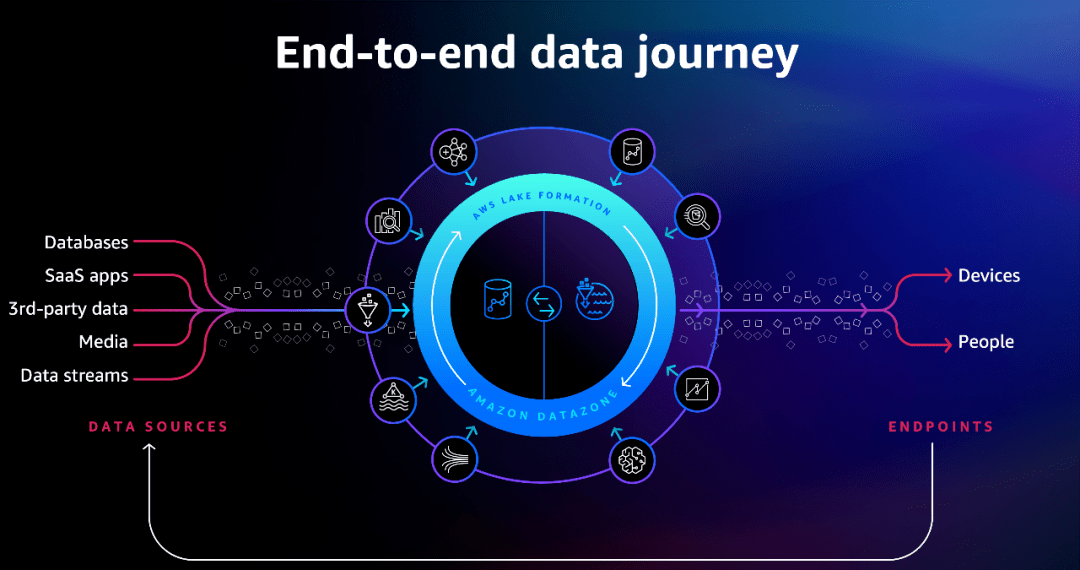
事实上,最新发布的Amazon Aurora zero-ETL与Amazon Redshift集成功能也好,还是Amazon Redshift与Apache Spark实现集成也好,背后都体现了亚马逊云科技为了实现数据一体化的融合,正在将其数据库、数据服务底层打通,把各种各样的数据都连接到执行分析所需要的地方去,由此实现数据平滑“无感”的流动,这既是“Zero ETL”的未来,更标志着企业未来在云上通过数据一体化融合,实现端到端数据之旅也正从梦想变成现实。
让数据分析变得“触手可及”
从亚马逊云科技在“Zero ETL”的实践和探索中,其实不难发现,作为诞生于2012年的全球首个云数据仓库,Amazon Redshift今天也正通过“与时俱进”的创新,为企业用户提供更多功能,以便更轻松、更快速、更安全地存储、处理和分析其所有数据,相信也会为千行百业的数字化转型提供更强大的驱动力。
客观地说,数据仓库历经多年的发展,帮助企业解决了很多数据方面的难题,但也要看到,随着企业实时数据分析的需求变得越来越迫切,特别是金融、电信等行业,由于日常需要处理大量人工智能、机器学习以及海量的结构化或者非结构化的数据实时分析等业务,因此也对数仓提出了新的挑战,主要表现在:
复杂性高,主要表现在很多的数据仓库使用上复杂性高,软件维护以及业务系统的维护的复杂性也很高;灵活性差,过去的数据仓库技术并不能很好地满足今天越来越多样化的分析数据类型与分析工作负载,对半结构化和非结构化的数据也无法提供原生的高效支持,此外也没有针对数据科学,机器学习等深度分析场景的优化;性价比低,随着新硬件特别是闪存技术的发展,以及数据仓库部署模式的多样化,也意味着存算分离,弹性使用正在变成企业的刚需,这也让过去数据仓库的付费模式变得性价比越来越低。

为此,Amazon Redshift也进行了大胆的技术创新,特别是其在无服务器(Serverless)化领域的探索,就为未来云原生实时数据仓库的发展“打了个样”。
第一,基于Serverless架构设计,Amazon Redshift能够帮助企业自动扩展资源,无需用户管理数据仓库集群,使得用户体验得以简化;同时智能动态计算能够自动调配和扩展数据仓库容量,提供一致快速的用户体验;此外,Amazon Redshift红海提供与用户的数据湖和其他数据源的无缝集成,性能出色,速度比任何其他云数据仓库快三倍,且具有自动维护功能,存储和计算分离,能够将成本最高降低75%。
第二,源于“Zero ETL”理念创新,Amazon Redshift对不同数据来源的普适性较好,可以针对操作性数据库完成实时数据查询;与第三方数据的数据市场进行良好的数据共享;可以连接商业智能类的数据应用,实现对大数据的实时分析和可视化;同时可以同Amazon S3数据湖进行功能整合,完成数据湖的导出,并基于开放标准数据格式进行分析等。
第三,专为实时数据应用场景而生,亚马逊云科技围绕Amazon Redshift构建了多种类型实时数据仓库架构,如为支持APP埋点数据实时采集与分析类应用所构建的实时数据仓库架构,就特别针对实时数据摄入、高并发实时查询等典型功能进行针对性优化设计,将易于使用和结构灵活的特点释放得“淋漓尽致”。
此外,基于kafka+flink架构并进行适配性改进,支撑实时报表的应用需求。可以实时按照不同维度进行汇总计算,依照指定形式归类数据,同时能够以每5分钟向Amazon Redshift实时表导入800万条数据,且可以秒级完成实时报表的历史数据定期删除或定期重建,这就相当于预制了多类型常用的“菜单”、“模板”,能够相当广泛的对接企业客户的主流实时数据分析需求,做到了让即时大数据分析的体验“触手可及”。
总的来看,无论是“Zero ETL”的探索实践,还是基于Serverless架构的大胆创新,背后都体现出了亚马逊云科技正以其强大的技术创新能力,减少企业在数据集成中面临的痛苦,让企业在新时代下的云原生实时数仓应用更简单方便,可以说真正为企业的实时数据分析乃至数字化转型提供了更好的选择,其价值也可谓:“不至于现在,更关乎未来。”

