
目录
翻译自《Arm Mali GPU Best Practices Developer Guide Version 2.2》 虽然英文原文的比较准确,但是中文更方便我自己查阅。如有不准,请看原文。 https://developer.arm.com/documentation/101897/v2-2/Optimizing-application-logic?lang=en
优化应用逻辑以减少图形驱动层的负载是非常重要的。CPU是用来处理应用逻辑,驱动图形堆栈(Graph Stack),运行图形驱动的。图形驱动是你需要注意的第一个潜在的性能瓶颈。
绘制调用合批最佳实践
提交绘制调用到命令流是图形驱动中比较费的操作。OpenGL ES上的绘制调用的运行时开销比Vulkan要大。
预备知识
- 绘制调用(Draw Call)
- 实例化(Instancing)
批量绘制(batch rendering)和命令缓冲(command buffer)来减少绘制调用
含有少量顶点和片段的绘制调用在GPU上可以被快速处理,但在CPU上指派这个任务是比较慢的。因此,这样的应用的性能是被CPU限制的,因为CPU不能让GPU一直繁忙。
我们鼓励用绘制调用合批来处理这个问题。绘制调用合批把多个使用相同渲染状态的物体的渲染合并到一个绘制调用上。这样减少了一帧中总的绘制调用数量,降低了CPU计算开销和能耗。
如何优化绘制调用合批
尝试以下的优化技术:
- 批处理物体减少绘制调用数量
- 即使不是CPU瓶颈也可以使用合批来减少能耗
- 使用实例化绘制调用来绘制mesh的多个副本。实例化允许应用测试裁切独立的实例,比如裁切视锥(View Frustum)之外的实例。
- OpenGL ES上,以每帧少于500次绘制调用为目标
- Vulkan上,以每帧少于1000次绘制调用为目标
Note
由于芯片组之间的CPU性能差距很大,这些绘制调用的次数建议基于当前Mali GPU硬件的近似建议。
绘制合批要避免的行为
Arm建议你:
- 合批不要合得太大,不然视锥剔除和绘制排序就需要做出妥协变得低效。
- 不要请求太多非合批的小型绘制调用,比如画一个点或者方块。
未优化的绘制合批的负面影响
- CPU负载较高,因为绘制调用数量多。
- 整体性能下降,如果应用本身是CPU限制的。
调试绘制合批
尝试以下的调试建议:
- 分析应用的CPU负载
- 统计每帧的绘制调用数量
绘制调用剔除最佳实践
在绘制调用到达图形API层之前就把它们丢弃掉是最快速的。
预备知识
你必须理解以下概念:
- 剔除(culling)
- 图元(primitives)
- 顶点着色(vertex shading)
最小化绘制调用
与 GPU 中的每个基元剔除相比,剔除整个网格使用的绘制调用更少,因为它可以利用场景知识。GPU 剔除只能在图元裁剪空间坐标已知后执行。因此,即使图元最终被剔除,也必须执行顶点着色。
如何优化绘制调用剔除
尝试以下的优化技术:
- CPU上剔除超出视锥的对象。例如,通过使用包围盒平截头体检查(bounding box frustum checks)。
- CPU上剔除已知会被遮挡的对象。例如,通过使用portal剔除。
- 尝试在合批大小和剔除效率之间找到平衡点
绘制调用剔除时要避免的结果
不要将每个对象都发送到图形 API。
对 CPU 和 GPU 的负面影响
未优化的绘制调用剔除会导致以下问题:
- 由于不必要的绘制调用,应用程序 CPU 负载较高。
- 由于冗余顶点着色,GPU 顶点着色负载和带宽较高。
调试绘制调用剔除问题
尝试以下调试建议:
- 分析应用的CPU负载
- 使用 GPU 性能计数器来确认平铺图元剔除率。预计大约 50% 的三角形会被剔除,因为它们的背面在视锥内。较高的剔除率可能表明应用程序需要改进绘制调用剔除方法。
优化绘制调用绘制顺序
绘制时,GPU可以使用前期深度测试(early ZS test)来有效拒绝被遮挡的片段。高效的绘制调用顺序可以最大化利用early ZS test来移除尽可能多的遮挡片段。
预备知识
你必须理解以下概念:
- 命令缓冲(command buffers)
- 绘制调用(draw calls)
- 前期和后期zs测试(Early and late ZS testing)
使用前期zs测试和前向像素消除(Forward Pixel Kill)来增加剔除率
为了从前期ZS测试中获得最高的片段剔除率,首要是从前到后的绘制顺序绘制所有不透明网格。为确保混合正常工作,请在不透明几何体的绘制之后,用后到前的绘制顺序绘制所有透明网格。
自 Mali-T620 GPU 以来的所有 Mali GPU 都包含前向像素消除 (FPK) 优化。 FPK 提供自动隐藏表面去除被遮挡的片段,而前期zs测试不会消除这些片段。
由于对不透明几何体使用了从后到前的绘制顺序,因此会移除被遮挡的片段。但是,不要单独依赖 FPK 优化。前期 ZS 测试总是更节能、更一致,并且适用于不包括隐藏表面去除的旧 Mali GPU
尽管最好使用前期ZS测试而不是 FPK,但了解阻止 FPK 工作的原因可能很有用。 FPK失败的情况通常包括使用透明效果、小三角形或帧缓冲区共享。
译者注:FPK其实就是把通过earlyz的片段先缓存在一个队列中,后进队列的片段会把先进的顶掉,因为后通过深度测试的片段一定会把先进的挡住,最后把留在队列中的拿去着色。当然队列也是有容量的,队列满了,也会取出片段进入着色阶段。
如何优化绘制调用顺序
尝试使用以下优化技术:
- 按从前到后的顺序绘制不透明对象
- 在禁用混合的情况下绘制不透明对象。
优化绘制调用顺序时要避免的行为
Arm 建议您:
- 不要在片段着色器中使用丢弃(discard),因为它会强制进行后期 ZS 测试。
- 不要使用 alpha-to-coverage,因为它会强制进行后期 ZS 测试。
- 不要在片段着色器中写入片段深度,因为它会强制进行后期 ZS 测试。
未优化的绘制调用顺序的负面影响
使用次优的绘制调用顺序和后期 ZS 测试会导致更高的片段着色负载。这是因为存在一些被遮挡的片段在着色之前没被消除。
调试绘制调用顺序问题
尝试以下调试技术:
- 绘制没有透明元素的场景。使用 GPU 性能计数器检查每个输出像素绘制的片段数。如果片段数大于 1,则表示存在过度绘制,而这些绘制可以被早期 ZS 测试移除。
- 使用 GPU 性能计数器检查需要后期 ZS 测试的片段数量。还要检查后期 ZS 测试消除的片段数量。
避免使用深度预通道(depth prepasses)
深度预通道是 PC 和主机游戏开发中的常用技术。它用于可能存在许多过度绘制和昂贵的片段着色器的场景。它也用于无法可靠地从前到后排序不透明几何体的情况。
预备知识
你必须理解以下概念:
- 前期深度测试
- 绘制通道(render passes)
降低性能的优化
深度预通道目的是快速设置所有几何体的深度,而不产生片段着色成本。预通道之后的着色通道(color shading pass)仅对深度完全匹配的片段进行着色。每个像素只理想地调用一个片段着色器。Mali GPU 包括隐藏表面去除,不需要严格的从前到后的顺序。因此,对于大多数情况而言,由于需要对每个网格进行两次渲染,深度预通道会降低性能。
在深度预通道算法期间,不透明几何图形被绘制两次。首先仅做深度更新,然后使用 EQUALS 深度测试的做颜色绘制。
因为完整的着色仅对可见片段执行,所以它最大限度地减少了发生的冗余片段处理量。但是,深度预通道的绘制调用次数和处理的顶点数是原来的两倍。
Mali GPU 已经包含优化,例如前向像素消除 (FPK),以自动减少冗余片段处理。因此,额外的绘制调用、顶点着色和内存带宽的性能成本通常超过收益。
要避免的行为
不要使用深度预通道算法来消除任何片段过度绘制。
使用深度预通道的负面影响
使用深度预通道时对性能的影响是:
- 由于重复的绘制调用,CPU 会产生更高的负载。
- 由于重复的几何图形,顶点着色和内存带宽成本更高。
OpenGL ES GPU 管道
OpenGL ES 在API层暴露了一个同步渲染模型,尽管GPU上异步执行的。而 Vulkan 直接在 API 中公开了这种异步特性。
预备知识
你必须理解以下概念:
- 同步和异步执行的不同
- pipeline draining
保持GPU繁忙,栅栏(fence)和查询(queries)
无论执行是同步的还是异步的,应用程序都必须让 GPU 保持忙碌。因此,除非已达到预期的目标帧率,否则应避免使用会饿死GPU的操作。让 GPU 保持忙碌意味着您可以从平台获得最佳渲染性能。
如何在 Mali GPU 上优化 OpenGL ES GPU 管道
尝试使用以下优化技术:
- 避免以导致 GPU 空闲的方式使用 API,除非已达到目标性能。
- 任何栅栏和查询对象的使用都不要过早等待查询结果。
- 为了防止 n 个冲突的绘制调用阻塞缓冲,使用
GL_MAP_UNSYNCHRONIZED以启用glMapBufferRange()。 - 使用异步的
glReadPixels()调用将数据读入像素缓冲区。
在 Mali GPU 上优化 OpenGL ES GPU 流水线时要避免的行为
您可以看到的不同类型的影响:
- 如果管道耗尽(pipeline draining),GPU 在产生气泡期间会有部分空闲,从而导致性能损失。
- 还可能存在一些性能不稳定,来自于和系统动态电压和频率缩放的电源管理逻辑的交互。
调试 Mali GPU 的 OpenGL ES 问题
可以使用系统分析器监控 CPU 和 GPU 活动。例如,Arm Streamline 性能分析器。Pipeline drains are visible as periods of busy time oscillating between the CPU and GPU, without the CPU or the GPU being fully utilized.(不知道怎么翻译)
OpenGL ES 分离着色器对象
OpenGL ES 允许使用分离的着色器对象 (SSO)。仅在需要时使用它们。
预备知识
您必须了解着色器对象的概念。
仅在必要时使用 SSO
使用 SSO 会阻止些优化,让着色器会更慢。SSO 有用的地方,例如避免显着增加着色器的数量,也请非常小心地使用SSO。因此, 请优化管道以消除冗余计算并仅传递所需的值。开发人员承担了编译器和驱动程序无法完成的额外优化责任。
要避免的行为
除非必要,否则 Arm 建议您不要使用 SSO。
如何优化 SSO
如果需要 SSO,请删除冗余计算并仅传递必要的值。
SSO 的负面影响
如果您使用 SSO,则程序就不知道管道的其他阶段是什么样的。一些优化,包括链接和缓冲区优化,都不可用了。
Vulkan GPU 管道
Mali GPU 可以在另一个渲染通道的片段着色器运行时执行计算着色器或顶点着色器的工作。为确保高性能,应用程序不要在此管道中不必要地创建气泡。
预备知识
您必须了解以下概念:
- 使用命令缓冲区。
- 不同的着色器阶段。
管道气泡
对于 Mali GPU,将一个渲染通道中的顶点或计算工作与更早的渲染通道中的片段工作重叠非常重要。
在使用 Vulkan 时,以下原因可能会导致应用程序中出现管道气泡:
- 没有提交足够的命令缓冲区:没提交足够的命令缓冲区会减少 GPU 处理队列中的工作量。限制可能的调度机会。
- 数据依赖:例如,考虑两个渲染通道 N 和 M。渲染通道 M 发生在管道的稍后阶段。当N在管道早期需要消费M的结果的时候,数据依赖就会出现。数据依赖性会导致延迟,在此期间必须完成足够的工作来隐藏延迟。
在下图(取自我们的 Streamline 分析器)中,您可以看到我们没有达到目标 60FPS。但是,CPU 以及 GPU 中的顶点和片段活动都有空闲时间。
这种工作和空闲时间在处理器之间波动的模式很好地表明了,有API调用的问题,或者存在限制了 GPU 调度的数据依赖。
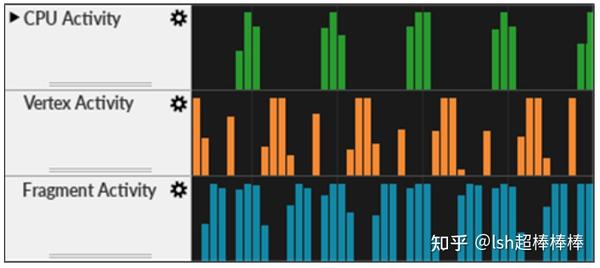
如何防止管道气泡
为防止管道气泡的发生:
- 频繁提交命令缓冲区,例如,对于帧中的每个主要渲染通道.
- 如果您有产生气泡的情况,请尝试使用气泡填充技术。例如,通过在两个渲染通道之间插入独立的工作负载。
- 在需要消费数据的阶段的早期阶段生成数据。例如,计算阶段适合为顶点着色阶段生成输入数据。片段阶段不太适合为顶点着色器生成数据,因为它发生在管道中的顶点着色阶段之后。
- 考虑在管道后期处理有依赖的数据。例如,使用来自其他片段着色阶段的输出的片段着色器比使用片段着色阶段输出的计算着色器效果更好。
- 使用栅栏将数据异步读回 CPU。不要使用同步阻塞的方式导致管道耗尽。
优化 GPU 管道时要避免的操作
Arm 建议您:
- 不要在管道中的任何地方不必要地等待 GPU 数据。
- 不要等到帧结束才提交所有渲染通道。
- 请不要在管道中创建任何后向数据依赖,如果没有足够的工作负载来隐藏延迟的话。
- 不要使用 vkQueueWaitIdle() 或 vkDeviceWaitIdle()
调试您的应用程序
Arm Streamline 系统分析器可视化两个 GPU 队列上的 Arm CPU 和 GPU 活动。该系统分析器可以快速显示出由于以下两种方式出现的调度气泡:
- GPU自身队列。这种类型的气泡表型存在GPU阶段依赖问题。
- 全局的跨 CPU 和 GPU的气泡。这种类型的气泡表示正在使用带阻塞 的CPU 调用。
Vulkan管道同步
Mali GPU 公开了两个硬件处理器插槽(slot)。每个插槽实现渲染管道阶段(rendering pipeline stages)的子集,并与另一个插槽并行运行。
预备知识
你必须理解以下概念:
- 命令同步障碍(Command synchronization barriers)
- 着色阶段(shader stages)
使用 Vulkan 进行并行处理
GPU 允许跨两个硬件插槽进行最大数量的并行处理。
Mali 等 Tile-based 的 GPU 与intermediate-mode的桌面GPU不同,基于 Tile 的 GPU 具有两个独立调度的硬件插槽,用于不同类型的工作负载。从桌面 GPU 移植内容时,需要调整您的管道以在tile-based GPU 上正常工作。
以下列表显示了 Vulkan stage到 Mali GPU 处理槽的映射:
顶点或计算硬件插槽
- VK\_PIPELINE\_STAGE\_DRAW\_INDIRECT\_BIT
- VK\_PIPELINE\_STAGE\_VERTEX\_\_BIT*
- VK\_PIPELINE\_STAGE\_TESSELLATION\_\_BIT*
- VK\_PIPELINE\_STAGE\_GEOMETRY\_SHADER\_BIT
- VK\_PIPELINE\_STAGE\_COMPUTE\_SHADER\_BIT
- VK\_PIPELINE\_STAGE\_TRANSFER\_BIT
片段硬件插槽
- VK\_PIPELINE\_STAGE\_EARLY\_FRAGMENT\_TESTS\_BIT
- VK\_PIPELINE\_STAGE\_FRAGMENT\_SHADER\_BIT
- VK\_PIPELINE\_STAGE\_LATE\_FRAGMENT\_TESTS\_BIT
- VK\_PIPELINE\_STAGE\_COLOR\_ATTACHMENT\_OUTPUT\_BIT
- VK\_PIPELINE\_STAGE\_TRANSFER\_BIT
Vulkan 让应用程序控制命令之间的依赖关系。应用程序必须确保一个命令在流水线阶段已经产生了结果,之后的命令才能使用结果。
API 包括多个可用于命令同步的原语,例如:
- 子通道依赖(Subpass dependencies), 管道屏障(pipeline barriers), 事件(events),用于在单个队列中做细粒度同步。
- 信号量,用于队列之间粗粒度的依赖性。
所有处理细粒度依赖的工具都允许应用程序为其同步指定一个约束范围。srcStage 掩码指示哪些管道阶段必须被等待。dstStage 掩码指示哪些管道阶段必须在处理开始之前等待同步。
要在两个 Mali 硬件处理槽中获得最佳并行处理,首先要最小化同步范围。在管道中尽可能早地设置 srcStage,尽可能晚地设置 dstStage。
信号量允许使用 pWaitDstStages 对依赖的命令进行控制。但是,信号量假定 srcStage 是最坏的情况 VK\_PIPELINE\_STAGE\_BOTTOM\_OF\_PIPE\_BIT。因此,只有在没有细粒度替代方案可用时才使用信号量。
底层的同步原语
在底层需要两种同步:
- 在单个硬件处理槽中同步
- 跨两个硬件处理插槽同步
由于在 Mali 渲染管道中,片段着色总是在顶点或计算之后进行,因此从在顶点或计算处理槽中运行的 srcStage 到在片段处理槽中运行的 dstStage 的同步成本较低。
从片段硬件插槽中的 srcStage 到顶点或计算硬件插槽中的 dstStage 的同步是昂贵的。除非考虑到 srcStage 结果生成的额外延迟,否则同步会创建管道气泡。例如,有足够的无依赖工作来填充气泡。
TRANSFER 阶段是 Vulkan 管道中的一个重载项。驱动程序可以在任一硬件处理槽中实现传输操作。这意味着在管道中的传输操作,无论是有前向依赖还是后向依赖,都不会有明显差别。
从缓冲区到缓冲区的传输在顶点或计算处理槽中实现。其他传输可以在任一处理槽中实现,并且确定使用哪个硬件处理槽取决于当时正在写入的数据资源的状态。
被占用的处理槽会实质性的影响到应用程序管道的渲染工作负载。因此,请始终检查传输操作的性能。
如何优化 Vulkan 管道同步
尝试使用以下优化技术:
- 在管道中尽早设置 srcStageMask。
- 在管道中尽可能晚地设置 dstStageMask。
- 检查依赖项是前向的,源是顶点或计算,目标是片段,还是后向的,源是片段,目标是顶点或计算。尽量减少使用后向依赖项。
- 如果需要向后依赖,则在资源的生成和消耗之间添加足够的延迟,以隐藏气泡。
- 使用 srcStageMask = ALL\_GRAPHICS\_BIT 和 dstStageMask = FRAGMENT\_SHADER\_BIT 做渲染通道之间的同步。
- 零拷贝算法是最有效的,因此尽量减少使用 TRANSFER 拷贝操作。始终查看 TRANSFER 拷贝如何影响硬件流水线。
- 仅在需要时使用队列内屏障,并在屏障之间放置尽可能多的工作。
使用 Vulkan 管道要避免的
Arm 建议您:
- 不要饿死硬件
- 不要忘记在片段处理的同时进行顶点或计算处理。
- 不要使用以下 srcStageMask 到 dstStageMask 同步配对,因为它们完全耗尽了管道:
- BOTTOM\_OF\_PIPE\_BIT to TOP\_OF\_PIPE\_BIT
- ALL\_GRAPHICS\_BIT to ALL\_GRAPHICS\_BIT
- ALL\_COMMANDS\_BIT to ALL\_COMMANDS\_BIT
- 如果合并管道屏障,请注意不要引入错误的依赖关系。确保不要破坏顶点/片段的重叠运行并创建不必要的气泡。
- 不要立即使用 VkEvent 发出信号并等待该事件。请改用 vkCmdPipelineBarrier()。
- 不要在单个队列中使用 VkSemaphore 进行依赖管理
低效 Vulkan 管道的负面影响
错误的管道屏障可能会因过多的同步而使 GPU 无法工作,或者会在同步过少的情况下导致渲染错误。
调试 Vulkan 管道以识别气泡
Arm Streamline 系统分析器工具可快速显示在 GPU 或跨 CPU 和 GPU 的全局调度中的气泡。GPU 本地气泡表明存在stage依赖性问题。全局气泡表明正在使用阻塞的CPU 调用。
管道资源更新
当在 GPU 上执行绘制调用时,OpenGL ES 必须确保资源处于正确的状态。正确的操作可以防止正在运行的资源被修改造成冲突。
预备知识
您必须了解以下概念:
- 资源重影(Resource ghosting)
- N-buffering
引用资源
取决于驱动程序处理冲突的方式,尝试修改仍被引用的资源可能会导致管道气泡或 CPU 负载增加。
OpenGL ES 向应用程序开发人员提供了一个同步渲染模型,即使底层执行是异步的。渲染必须知道进行绘制调用时数据资源的状态。如果应用程序修改了资源,而挂起的绘制调用仍在引用它,则驱动程序必须采取规避措施以确保正确性。
Mali 驱动程序不通过阻塞并等待资源引用计数达到零来处理,因为这样做会耗尽管道并导致性能下降。Mali GPU 创建了新版本的资源。资源的旧版本或幽灵版本将一直保留,直到挂起的绘制调用完成并且其引用计数降至零。
这个过程很昂贵,并且需要为新资源分配内存并在完成时清理幽灵资源。如果更新不是完全替换,则还需要从旧资源缓冲区复制到新资源缓冲区。
如何优化管道资源
尝试使用以下优化技术:
- 为防止修改队列中的绘制调用所引用的资源,请使用 N 缓冲资源,并管道化你的动态资源更新。
- GL\_MAP\_UNSYNCHRONIZED 允许使用 glMapBufferRange() 来修补仍在进行中的绘制调用引用的缓冲区的未引用区域。
未优化的流水线资源更新的负面影响
次优管道资源更新可能会导致以下负面影响:
- 由于内存分配开销和需要副本来构建新版本的资源,资源重影会增加 CPU 负载。
- 不断分配和释放重影会导致内存占用不稳定。
调试资源更新
Arm Streamline 系统分析器可视化 Arm CPU 和 GPU 活动。未能管道化更新资源通常显示为 CPU 负载升高。
查询(query)
OpenGL ES 和 Vulkan 都有用于测试遮挡等的查询对象。正确使用它们可以提高性能。
预备知识
您必须了解以下概念:
- 查询对象。
如何优化查询
尝试使用以下优化技术:
- 管道化查询使用,只在需要时获取返回结果,不要等待它,因为这是低效的。
- 对于遮挡,仅在必要时使用精确计数选项。对 OpenGL ES 使用 GL\_ANY\_SAMPLES\_PASSED,或者对 Vulkan 使用 VK\_QUERY\_CONTROL\_PRECISE\_BIT = false,除非你必须知道遮挡的数量。
Query practices to avoid
Arm recommends that you:
- Do not modify resources that in-flight draw calls are still referencing.
- Do not use glMapBufferRange() with either GL_MAP_INVALIDATE_RANGE or GL_MAP_INVALIDATE_BUFFER on some older Mali driver versions, as these flags trigger the creation of an unnecessary resource ghost.
感觉这段不应该在这一节。。
低效查询对 Mali GPU 的负面影响
- 如果过早等待查询结果,GPU 会不必要地空闲,从而浪费周期。
- 如果不必要地使用精确计数遮挡查询,GPU 会做不必要的工作,这也会浪费功率和周期。
作者:lsh超棒棒棒
文章来源:知乎
推荐阅读
计算机体系结构学习资料汇总
深入GPU硬件架构及运行机制
Mali-G710开发者概览(二、着色器核心改进)
更多Arm Mali GPU相关技术干货请关注Arm Mali GPU技术专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

