
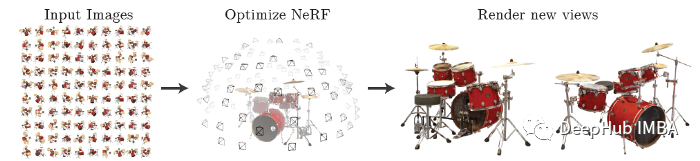
提起三维重建技术,NeRF是一个绝对绕不过去的名字。这项逆天的技术,一经提出就被众多研究者所重视,对该技术进行深入研究并提出改进已经成为一个热点。不到两年的时间,NeRF及其变种已经成为重建领域的主流。本文通过100行的Pytorch代码实现最初的 NeRF 论文。
NeRF全称为Neural Radiance Fields(神经辐射场),是一项利用多目图像重建三维场景的技术。该项目的作者来自于加州大学伯克利分校,Google研究院,以及加州大学圣地亚哥分校。NeRF使用一组多目图作为输入,通过优化一个潜在连续的体素场景方程来得到一个完整的三维场景。该方法使用一个全连接深度网络来表示场景,使用的输入是一个单连通的5D坐标(空间位置x,y,z以及观察视角θ,),输出为一个体素场景,可以以任意视角查看,并通过体素渲染技术,生成需要视角的照片。该方法同样支持视频合成。
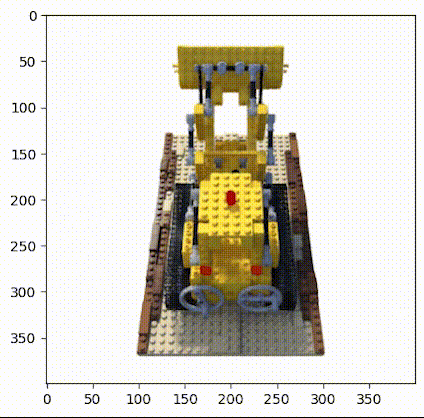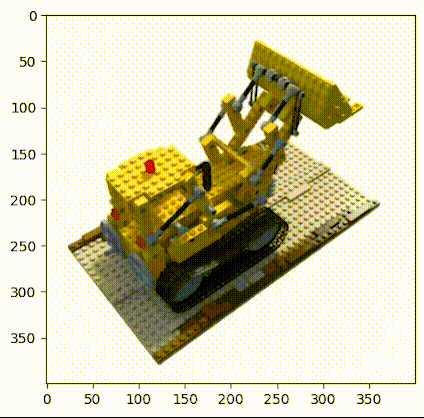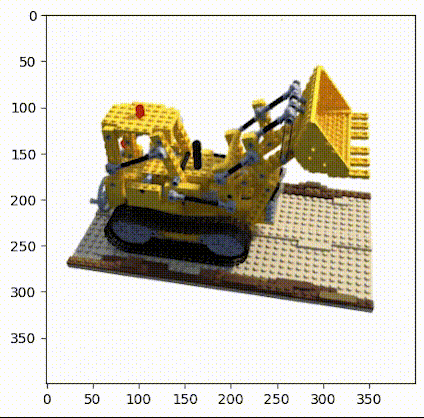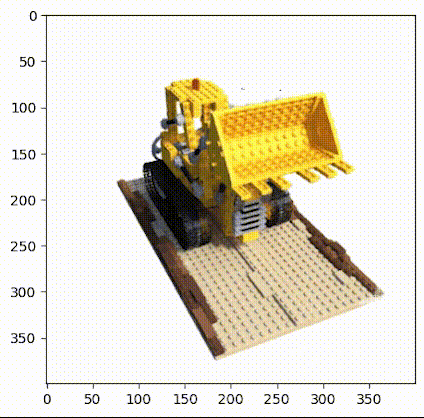
该方法是一个基于体素重建的方法,通过在多幅图片中的五维坐标建立一个由粗到细的对应,进而恢复出原始的三维体素场景。
NeRF 和神经渲染的基本概念
Rendering
渲染是从 3D 模型创建图像的过程。该模型将包含纹理、阴影、阴影、照明和视点等特征,渲染引擎的作用是处理这些特征以创建逼真的图像。
三种常见的渲染算法类型是光栅化,它根据模型中的信息以几何方式投影对象,没有光学效果;光线投射,使用基本的光学反射定律从特定角度计算图像;和光线追踪,它使用蒙特卡罗技术在更短的时间内获得逼真的图像。光线追踪用于提高 NVIDIA GPU 中的渲染性能。
Volume Rendering
立体渲染使能够创建 3D 离散采样数据集的 2D 投影。
对于给定的相机位置,立体渲染算法为空间中的每个体素获取 RGBα(红色、绿色、蓝色和 Alpha 通道),相机光线通过这些体素投射。RGBα 颜色转换为 RGB 颜色并记录在 2D 图像的相应像素中。对每个像素重复该过程,直到呈现整个 2D 图像。
View Synthesis
视图合成与立体渲染相反——它涉从一系列 2D 图像创建 3D 视图。这可以使用一系列从多个角度显示对象的照片来完成,创建对象的半球平面图,并将每个图像放置在对象周围的适当位置。视图合成函数尝试在给定一系列描述对象不同视角的图像的情况下预测深度。
NeRF是如何工作的
NeRF使用一组稀疏的输入视图来优化连续的立体场景函数。这种优化的结果是能够生成复杂场景的新视图。
NeRF使用一组多目图作为输入:
输入为一个单连通的5D坐标(空间位置x,y,z以及观察视角(θ; Φ)
输出为一个体素场景 c = (r; g; b) 和体积密度 (α)。
下面是如何从一个特定的视点生成一个NeRF:
- 通过移动摄像机光线穿过场景生成一组采样的3D点
- 将采样点及其相应的2D观察方向输入神经网络,生成密度和颜色的输出集
- 通过使用经典的立体渲染技术,将密度和颜色累积到2D图像中
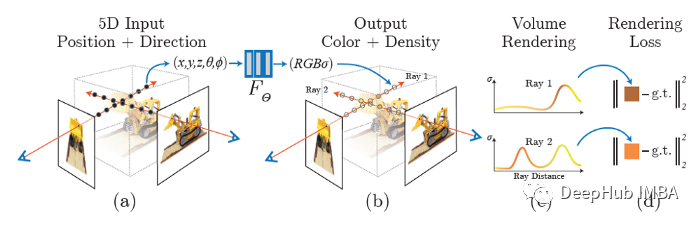
上述过程深度的全连接、多层感知器(MLP)进行优化,并且不需要使用卷积层。它使用梯度下降来最小化每个观察到的图像和从表示中呈现的所有相应视图之间的误差。
Pytorch代码实现
渲染
神经辐射场的一个关键组件,是一个可微分渲染,它将由NeRF模型表示的3D表示映射到2D图像。该问题可以表述为一个简单的重构问题
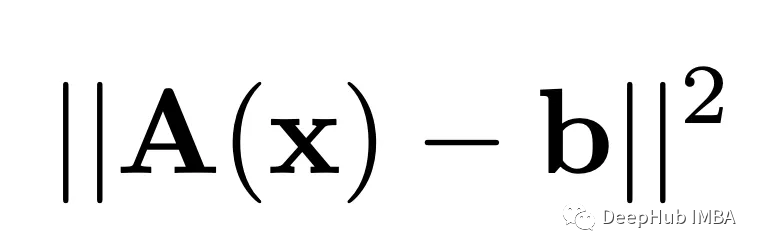
这里的A是可微渲染,x是NeRF模型,b是目标2D图像。
代码如下:
defrender_rays(nerf_model, ray_origins, ray_directions, hn=0, hf=0.5, nb_bins=192):
device=ray_origins.device
t=torch.linspace(hn, hf, nb_bins, device=device).expand(ray_origins.shape[0], nb_bins)
# Perturb sampling along each ray.
mid= (t[:, :-1] +t[:, 1:]) /2.
lower=torch.cat((t[:, :1], mid), -1)
upper=torch.cat((mid, t[:, -1:]), -1)
u=torch.rand(t.shape, device=device)
t=lower+ (upper-lower) *u # [batch_size, nb_bins]
delta=torch.cat((t[:, 1:] -t[:, :-1], torch.tensor([1e10], device=device).expand(ray_origins.shape[0], 1)), -1)
x=ray_origins.unsqueeze(1) +t.unsqueeze(2) *ray_directions.unsqueeze(1) # [batch_size, nb_bins, 3]
ray_directions=ray_directions.expand(nb_bins, ray_directions.shape[0], 3).transpose(0, 1)
colors, sigma=nerf_model(x.reshape(-1, 3), ray_directions.reshape(-1, 3))
colors=colors.reshape(x.shape)
sigma=sigma.reshape(x.shape[:-1])
alpha=1-torch.exp(-sigma*delta) # [batch_size, nb_bins]
weights=compute_accumulated_transmittance(1-alpha).unsqueeze(2) *alpha.unsqueeze(2)
c= (weights*colors).sum(dim=1) # Pixel values
weight_sum=weights.sum(-1).sum(-1) # Regularization for white background
returnc+1-weight_sum.unsqueeze(-1)渲染将NeRF模型和来自相机的一些光线作为输入,并使用立体渲染返回与每个光线相关的颜色。
代码的初始部分使用分层采样沿射线选择3D点。然后在这些点上查询神经辐射场模型(连同射线方向)以获得密度和颜色信息。模型的输出可以用蒙特卡罗积分计算每条射线的线积分。
累积透射率(论文中Ti)用下面的专用函数中单独计算。
defcompute_accumulated_transmittance(alphas):
accumulated_transmittance=torch.cumprod(alphas, 1)
returntorch.cat((torch.ones((accumulated_transmittance.shape[0], 1), device=alphas.device),
accumulated_transmittance[:, :-1]), dim=-1)NeRF
我们已经有了一个可以从3D模型生成2D图像的可微分模拟器,下面就是实现NeRF模型。
根据上面的介绍,NeRF非常的复杂,但实际上NeRF模型只是多层感知器(MLPs)。但是具有ReLU激活函数的mlp倾向于学习低频信号。当试图用高频特征建模物体和场景时,这就出现了一个问题。为了抵消这种偏差并允许模型学习高频信号,使用位置编码将神经网络的输入映射到高维空间。
classNerfModel(nn.Module):
def__init__(self, embedding_dim_pos=10, embedding_dim_direction=4, hidden_dim=128):
super(NerfModel, self).__init__()
self.block1=nn.Sequential(nn.Linear(embedding_dim_pos*6+3, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), )
self.block2=nn.Sequential(nn.Linear(embedding_dim_pos*6+hidden_dim+3, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim+1), )
self.block3=nn.Sequential(nn.Linear(embedding_dim_direction*6+hidden_dim+3, hidden_dim//2), nn.ReLU(), )
self.block4=nn.Sequential(nn.Linear(hidden_dim//2, 3), nn.Sigmoid(), )
self.embedding_dim_pos=embedding_dim_pos
self.embedding_dim_direction=embedding_dim_direction
self.relu=nn.ReLU()
@staticmethod
defpositional_encoding(x, L):
out= [x]
forjinrange(L):
out.append(torch.sin(2**j*x))
out.append(torch.cos(2**j*x))
returntorch.cat(out, dim=1)
defforward(self, o, d):
emb_x=self.positional_encoding(o, self.embedding_dim_pos)
emb_d=self.positional_encoding(d, self.embedding_dim_direction)
h=self.block1(emb_x)
tmp=self.block2(torch.cat((h, emb_x), dim=1))
h, sigma=tmp[:, :-1], self.relu(tmp[:, -1])
h=self.block3(torch.cat((h, emb_d), dim=1))
c=self.block4(h)
returnc, sigma训练
训练循环也很简单,因为它也是监督学习。我们可以直接最小化预测颜色和实际颜色之间的L2损失。
deftrain(nerf_model, optimizer, scheduler, data_loader, device='cpu', hn=0, hf=1, nb_epochs=int(1e5),
nb_bins=192, H=400, W=400):
training_loss= []
for_intqdm(range(nb_epochs)):
forbatchindata_loader:
ray_origins=batch[:, :3].to(device)
ray_directions=batch[:, 3:6].to(device)
ground_truth_px_values=batch[:, 6:].to(device)
regenerated_px_values=render_rays(nerf_model, ray_origins, ray_directions, hn=hn, hf=hf, nb_bins=nb_bins)
loss= ((ground_truth_px_values-regenerated_px_values) **2).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
training_loss.append(loss.item())
scheduler.step()
forimg_indexinrange(200):
test(hn, hf, testing_dataset, img_index=img_index, nb_bins=nb_bins, H=H, W=W)
returntraining_loss测试
训练过程完成,NeRF模型就可以用于从任何角度生成图像。测试函数通过使用来自测试图像的射线数据集进行操作,然后使用渲染函数和优化的NeRF模型为这些射线生成图像。
@torch.no_grad()
deftest(hn, hf, dataset, chunk_size=10, img_index=0, nb_bins=192, H=400, W=400):
ray_origins=dataset[img_index*H*W: (img_index+1) *H*W, :3]
ray_directions=dataset[img_index*H*W: (img_index+1) *H*W, 3:6]
data= []
foriinrange(int(np.ceil(H/chunk_size))):
ray_origins_=ray_origins[i*W*chunk_size: (i+1) *W*chunk_size].to(device)
ray_directions_=ray_directions[i*W*chunk_size: (i+1) *W*chunk_size].to(device)
regenerated_px_values=render_rays(model, ray_origins_, ray_directions_, hn=hn, hf=hf, nb_bins=nb_bins)
data.append(regenerated_px_values)
img=torch.cat(data).data.cpu().numpy().reshape(H, W, 3)
plt.figure()
plt.imshow(img)
plt.savefig(f'novel_views/img_{img_index}.png', bbox_inches='tight')
plt.close()所有的部分都可以很容易地组合起来。
if__name__=='main':
device='cuda'
training_dataset=torch.from_numpy(np.load('training_data.pkl', allow_pickle=True))
testing_dataset=torch.from_numpy(np.load('testing_data.pkl', allow_pickle=True))
model=NerfModel(hidden_dim=256).to(device)
model_optimizer=torch.optim.Adam(model.parameters(), lr=5e-4)
scheduler=torch.optim.lr_scheduler.MultiStepLR(model_optimizer, milestones=[2, 4, 8], gamma=0.5)
data_loader=DataLoader(training_dataset, batch_size=1024, shuffle=True)
train(model, model_optimizer, scheduler, data_loader, nb_epochs=16, device=device, hn=2, hf=6, nb_bins=192, H=400,
W=400)这样一个简单的NeRF就完成了,看看效果:

希望本文对你有所帮助,如果你对NeRF感兴趣可以看看这个项目:
https://avoid.overfit.cn/post/3d89b7ed625b437993e3fde57f36c70a

