
出品人:Towhee 技术团队
随着 ChatGPT 引起一波又一波的“GPT热潮”,自然语言领域又一次成为了人工智能的讨论焦点。大家不由得思考,计算机视觉领域里是否会出现这样一个堪称划时代的模型?在这种万众瞩目的时候,一直处在行业前沿的 MetaAI 推出了一个新模型 Segment Anything Model (SAM),号称“了解物体是什么的一般概念”,能够“一键从任意图像中剪切出任何物体”。除了模型之外,它还针对图像分割提出了一种新型任务模式和大规模数据集。

|segment-anything.com: some potential systems integrated with SAM
首先让我们了解一下什么是“图像分割”:简单地说就是将图像分成若干个区域(通常按物体划分),帮助理解物体之间的关系与目标物体在图中的上下文。该任务是目标识别相关应用的重要基石,能够助力人脸检测、自动驾驶、卫星图像分析等。可以说,图像分割对计算机视觉的发展至关重要。SAM 支持自动分割图像中的所有物体,也允许用点击或框出物体实现精准分割,甚至能够根据指示展现多种分割结果。这些功能可以让用户轻松地将 SAM 集成到各种系统或应用中,比如在 AR/VR 中根据目光注视或语音指令选择操作对象、据输入框中的文本描述识别物体等。另外,SAM 的输出也可当作其他 AI 应用的输入。例如,SAM 可以帮助系统在视频中跟踪对象并进行遮蔽、在图像编辑中支持类似抠图或替换等功能、用于搭建 3D 场景、或进行物体拼贴等创意任务。
|SAM Overview
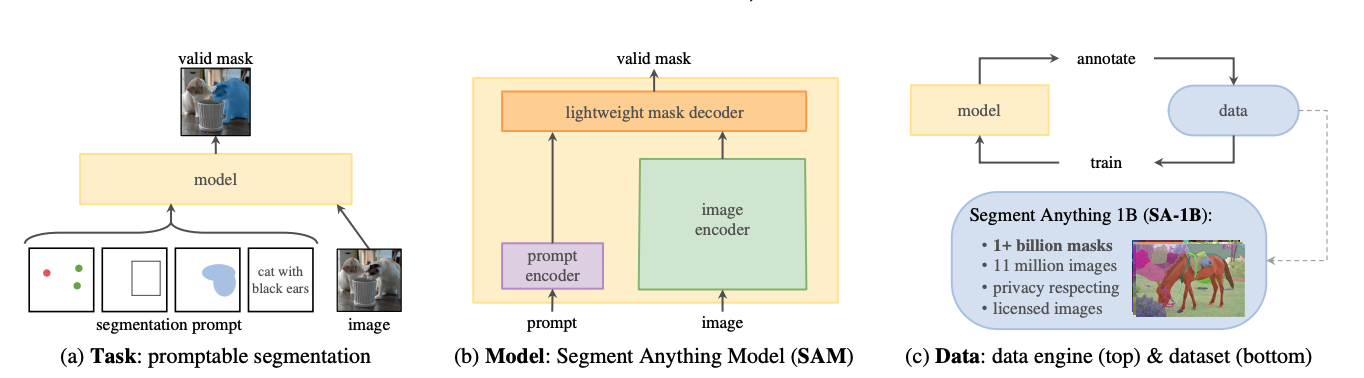
SAM 旨在创建一个用于图像分割的通用基础模型,为此将研究分为了任务、模型、数据三个相互关联的部分。它回答了三个问题:
- 什么样的任务能够实现零样本迁移?将提示(prompt)引入视觉分割,SAM 定义了“可提示”分割任务。提示在模型的零样本迁移能力中起到了关键作用。它可以指定图像中要分割的内容,从而在没有额外训练的情况下实现更广泛的分割任务。
- 通用模型需要什么架构?SAM 模型架构支持数据注释,并能通过提示工程实现对各种任务的零样本迁移。它以Tranformers 系列的视觉模型为基础,重新权衡和选择了组件,最终包括了一个强大的图像编码器、一个灵活的提示编码器、和一个轻量的掩码编码器。
- 怎样的数据才能满足该任务和模型的训练?SAM 数据引擎构建了一个目前最大的图像分割数据集 SA-1B,拥有超过 10 亿个掩码,专门用于图像分割任务的训练和测试。数据收集的过程包括了三个阶段:(手动阶段)在模型辅助下进行人工标注、(半自动阶段)结合人工标注和来自模型的掩码、(全自动)完全由模型生成掩码。
SAM 的本质是一个视觉大模型,其能力的亮点与 GPT-4 一样在于优秀的零样本迁移能力,即一个适用于不同任务的通用模型。论文中的实验结果表示 SAM 的模型效果令人惊喜,在多种任务中都展现出优秀的零样本迁移能力,其性能更是经常媲美或超越全监督模型。
相关资料:
本文由mdnice多平台发布

