
来源:内容由半导体行业观察 编译自anandtech,谢谢。
在全球范围内,如果智能手机和移动设备市场有一个普遍不变的常数,那就是 Arm。无论是移动芯片制造商将他们的 SoC 基于 Arm 的完全合成 CPU 内核,还是仅仅依靠 Arm ISA 并设计他们自己的芯片,归根结底,Arm 几乎是所有这一切的基础。这种市场饱和度和相关性证明了 Arm 在过去几十年中为达到这一点所做的所有艰苦工作,但这也是一项重大责任——对于大多数移动 SoC 而言,它们的性能只会以最快的速度向前发展Arm 自己的 CPU 内核设计和相关 IP 可以。
因此,我们已经看到 Arm 为他们的客户 IP 设定了年度节奏,今年也不例外。为了配合今年在台湾举行的 Computex 贸易展,Arm 展示了一套新的 Cortex-A 和 Cortex-X 系列 CPU 内核——以及新一代 GPU 设计——我们将看到它们为Arm 从今年晚些时候开始,一直持续到 2024 年。其中包括旗舰 Cortex-X4 内核,以及 Arm 的中核 Cortex-A720。以及新的小核 Cortex-A520。
Arm 的最新 CPU 内核建立在 Armv9 及其整体计算解决方案 (TSC21/22) 生态系统的基础上。对于他们的 2023 IP,Arm 正在通过其 Cortex 内核系列推出一波次要的微架构改进,这些细微的变化旨在提高效率和性能,同时完全转向 AArch64 64 位指令集。Arm 的最新 CPU 设计也旨在与全行业不断提高安全性的努力保持一致,虽然这些功能并非严格面向最终用户,但它确实强调了 Arm 的世代改进不仅仅是性能和功率效率。
除了改进其 CPU 内核外,Arm 还使用 DSU-120 对其 DynamIQ Shared Unit 内核复合块进行了全面升级。尽管引入的修改很细微,但它们在提高将 Arm CPU 内核保持在一起的结构效率方面具有重要意义,同时在性能可扩展性方面进一步扩展 Arm 的范围,支持单个块中多达 14 个 CPU 内核– 此举旨在使 Cortex-A/X 更适合笔记本电脑。
有了三个新的 CPU 核心和一个新的核心复合体,有很多东西可以涵盖。所以让我们开始吧。
高水平的 Arm TCS23:提高效率并走向纯 64 位
扩展去年在 Armv9.1 架构中引入的增强功能,Arm 正在使用最新的 Armv9.2 架构完成其预定的开发周期。此周期的主要目标是消除对 32 位应用程序的支持并过渡到全面的 64 位平台。支持这一转变的是 Arm 的战略框架“整体计算解决方案”(TCS),它围绕三个核心原则:计算性能、安全性和开发人员访问。这种方法构成了 Arm 方法论的基础,并指导其努力提供最佳性能、强大的安全措施和简化的开发人员能力。
Arm 多年来一直致力于逐步淘汰 32 位指令集。对于他们最新的 TCS23,他们终于创建了一个完全 64 位的集群,以利用完整的 64 位移动生态系统的优势,完全取消 AArch32(32 位指令)支持。所以无论是大型、中型还是小核,Arm最新一代IP只有AArch64。
开发适用于从尖端旗舰智能手机到入门级型号的各种移动设备的动态片上系统 (SoC),需要采取细致一致的方法来在快速扩张的市场中保持竞争力. 例如,在旗舰设备领域,Qualcomm 的 Snapdragon 8 Gen2 SoC 脱颖而出,它利用了 Arm 的 Cortex-X3、Cortex A715/710 和 Cortex-A510 内核集群。Qualcomm 的 Snapdragon 8 Gen3 和其他 SoC 制造商即将迭代,准备利用 Arm 的 TSC23 核心集群和知识产权的力量,进一步提升下一代旗舰移动设备的性能。
Arm 最新的 DynamIQ 共享单元 DSU-120 支持集群中多达 14 个 CPU 内核,这为大量不同的 CPU 内核组合打开了大门。我们将在今年晚些时候看到 SoC 供应商选择了什么,但一种可能的配置是 1+5+2 (X4+720+520),这很可能是高端智能手机的配置。与上一代 1+3+4 集群 (X3+715+510) 相比,Arm 声称在 GeekBench 6 MT 中的计算性能提升了 27%,在 Speedometer 中提升了 33% 到 64% 之间。2.1 基准取决于实施的软件优化。
去年,Arm 更加关注 64 位迁移的方法,宣布了他们的第一个 AArch64-only CPU 内核 Cortex-A715。因此,去年发布了第一批仅支持 64 位的产品,例如联发科的 Dimensity 9200 SoC,以及谷歌的 Pixel 7——64 位仅作为平台选择而非架构限制。
也就是说,在更大的软件生态系统中实际采用/使用 AArch64 的速度比预期的要慢,这主要是由于中国市场从 32 位到 64 位的转换速度很慢。早在 2019 年,谷歌就要求其开发人员提交 64 位应用程序,同时还允许在没有原生 64 位支持的设备上使用 32 位应用程序,实际上谷歌一直是其应用程序存储 (Google Play) 的关键。其他市场并没有那么快这样做,但 Arm 声称它正在“推动”OPPO、Vivo和小米等公司更快地采用 AArch64,相信这会产生预期的效果。
在最初的 Armv9 架构中,Arm 通过使用其内存标记扩展 (MTE) (Armv8.5) 改进了安全性,这是一种基于硬件的实现,使用指针身份验证 (PA) 扩展来帮助防止内存漏洞。多年来,基于内存的漏洞一直是对基于硬件的安全性的威胁,而 Arm 在其 IP 中不断开发这种漏洞,以帮助减轻此类攻击。作为参考,谷歌的 Chromium 项目声称大约 70% 的高严重性错误来自内存。
最新的 Armv9.2 架构的相关安全功能之一是引入了新的 QARMA3 指针验证码 (PAC) 算法。Arm 声称更新的算法将 PAC 的 CPU 开销降低到不到 1%,即使在他们的小内核上也是如此,这让开发人员和手机供应商更没有理由不启用该安全功能。这些改进大多围绕硬件完整性和安全性,通过 64 位指令和架构结合了 MTE 和本机优势,所有这些旨在使设备在 2023 年及以后更加安全。这符合 Arm 鼓励在 64 位和 32 位混合市场上完全切换到 64 位的精神。
后,在性能方面,Arm 声称他们最新一代的 CPU 和核心复杂架构在能效方面取得了可观的进步。在 iso-performance 方面,Cortex-X4 的功耗比 Cortex-X3 低 40% 以上,而 Cortex-A720 和 A520 比其各自的前身低 20-22%。在 DSU-120 集线器本身,Arm 声称能效提高了 18%。
当然,这些省电中的大部分将用于提高性能。但它表明,如果 SoC 和手机供应商只关注电源效率和电池寿命,那么他们在这一代的目标是什么。
Arm Cortex-X4:有史以来最快的 Arm 内核
进一步深入研究 Arm 的新 CPU 核心微架构,我们将从 Cortex-X4 开始,它作为最实质性的进步脱颖而出。从最初的 Cortex X1 内核开始,然后发展到 Cortex X2,并继续使用去年推出的 Cortex-X3 IP,Arm 在每次迭代中始终在每周期指令 (IPC) 方面取得两位数的显着改进,他们'我也会在 2023 年为 Cortex-X4 再次这样做。Cortex-X4 专门设计用于使用基于 Arm IP 的强大片上系统 (SoC) 的尖端旗舰 Android 智能手机和领先的移动设备。Cortex-X4 代表了对其前身的微妙而有影响力的增强,进一步完善了 Cortex-X3 内核的功能。
Cortex-X4 旨在为移动片上系统 (SoC) 提供顶级计算性能,特别适合处理要求苛刻的工作负载,例如 AAA 游戏和突发操作。Cortex-X4 是 Arm 迄今为止性能最高的内核,具有预期的 3.4 GHz 内核时钟速度和每个内核增加的 L2 缓存,与去年的 1 MB Cortex-X3 相比,其容量翻了一番,达到 2 MB。尽管有这些改进,Arm 仍设法保持核心物理尺寸的最小增加,更复杂的 X4 CPU 核心的裸片尺寸增加不到 10%(不包括额外的 L2 缓存)。
至于电源效率,Arm 声称与前几代产品相比,节电效果显着提高了约 40%。不要指望看到太多 CPU 供应商利用这一点,因为 X 系列的主要工作是快速运行,但它会显示 X4 与最新的晶圆厂节点相结合可以完成什么。
在架构方面,Cortex-X4 与其前身 Cortex-X3 有相似之处,主要侧重于改进现有架构并优化各种核心组件的效率。
现在,虽然从 Cortex-X4 到 Cortex-X3 在架构上没有太大变化,但 Cortex-X4 前端已经重新洗牌并调整了指令获取块。Arm 的目标是保持低延迟,同时在其 Cortex-X4 内核和整个 TSC23 内核集群中提供峰值带宽。
关于 Cortex-X4 的前端,这里的重大架构变化体现在其调度宽度上。Cortex-X4 现在具有更集中的 10 宽调度宽度,达到 X3 的 6/8 宽调度。也就是说,尽管前端变宽了,但有效流水线长度实际上却略微缩短了;分支预测错误的惩罚从 11 个周期减少到 10 个。
前端的另一个重点是指令获取过程本身。与 Cortex-X3 相比,Arm 基本上重新设计了整个指令获取传送系统,以确保整个流水线的效率更高。
最新的架构还对 Arm 的分支预测单元进行了另一次改进,进一步提高了它们的预测准确性。Arm 并没有多说他们是如何做到这一点的,尽管我们知道他们特别关注条件分支的准确性。但是,这一切都不是免费的。Arm 很快注意到改进后的预测器的实施成本更高。尽管如此,Arm 认为,可以这么说,为了让这头野兽 (Cortex-X4) 吃饱,这是值得的。
转移到 CPU 内核的后端,Arm 将重点放在了执行带宽上。在其他变化中,Arm 将 ALU 的数量从 6 个增加到 8 个。其中6 个是用于处理单周期 uOPS 的简单 ALU。同时,有两个复杂的 ALU 用于处理双周期和多周期指令, Arm 还挤进了另一个分支单元,使 Cortex-X4 从 2 个增加到 3 个,并增加了一个额外的 Integer MAC。同时在浮点方面,Cortex-X4 还升级了流水线浮点分频器。
因此,在某种程度上,X4 的性能改进来自于整个芯片的强力增加,芯片能够在单个时钟内调度和退出更多指令。Cortex-X4 的目标是在基准测试和实际工作负载上提供最佳性能,并增加通过管道的任何指令集的提取带宽。这些好处来自延迟减少和指令融合优势,适用于更大的指令占用空间工作负载。
增加多通道队列 (MCQ) 容量——从而增加指令重新排序窗口的大小——是 Arm 的 Cortex-X4 工具箱的另一项改进。与之前 Arm 的重新排序缓冲区的增加一样,更大的队列提供了更多机会来寻找指令重新排序、隐藏内存停顿以及以其他方式为其余 CPU 后端提取更多机会来完成一些工作。随着 CPU 性能继续超过内存带宽,对更大缓冲区的需求只会随着每一代的增长而增长。
最后,在 X4 CPU 核心的后端,Arm 添加了第四个地址生成单元。有趣的是,这个只适用于存储;Arm 已有一个仅加载单元,但选择了一个仅存储单元,而不是将其转换为完全混合的 LS 单元。
Cortex-X4 的 L1 缓存子系统也得到了大量的工作。L1 的翻译后备缓冲区 (TLB:translation lookaside buffer) 已翻倍至 96 个条目,并且有一个新的 L1 时间数据预取器。最后,Arm 已采取措施减少 X4 上 L1 数据库冲突的数量。
还进行了一些更改,以更好地支持我们之前讨论的 Cortex-X4 的更大 L2 缓存大小。出于性能原因,L2 在物理上更靠近 CPU 核心,并且 Arm 已经能够扩展 L2 大小而不会导致延迟增加。因此,与增加高速缓存大小的情况相比,这里的权衡更少。
Arm 的 v9.2 架构转变的主要好处之一是它提供了更高的可扩展性。TSC23 内核集群现在支持多达 14 个内核,这增加了 SoC 供应商在其最新设计中实施的灵活性。也许最大的变化之一是在 TSC23 核心集群中支持高达 32 MB 的共享 L3 缓存。实现的 L3 缓存级别当然取决于 SoC 制造商,但可以提供的最大级别为 32 MB,这允许在适用的情况下增加对平板电脑和笔记本电脑等高端移动设备的支持。
整个 TSC23 核心集群的最大核心数量总计达到 14 个,混合了大核心和小核心,SoC 供应商可以探索多种途径来利用性能提升和效率等优势。所有这些灵活性都赋予了 SoC 供应商根据设备级别设计自己的变体。因此,旗舰移动设备将根据成本、功率预算和预期性能水平等多种因素利用 Cortex-X4、Cortex-A720 和 Cortex-A520 的不同组合。
更大的核心和现有流程的优化通常会带来性能优势。Arm 声称,根据其硅前仿真数据,与去年旗舰 Android SoC 中使用的 Cortex-X3 相比,Cortex-X4 将在等频和等带宽下提供 15% 的 IPC 提升。这里有许多因素在提供总体性能改进方面发挥了作用,包括前端优化和改进,以及更大的每核 2 MB 二级缓存和更大的 L1D-TLB,这是为最近设计的缓存访问的页面转换。
Cortex-A720:中核,高效率
重点是Arm最新的中核,Cortex-A720与去年的Cortex A715设计相比并没有太大变化,也是Arm首款纯AArch64的中核。Arm 对其 A700 系列有一套理念,主要是通过优化提高性能,在设定的热限制内提供最高水平的电源效率,并针对实际用例优化工作负载,而不是极快的基准性能。Arm 的主要目标是提高性能指标,同时将电源效率、面积和所有这些都保持在可接受的热范围内。成本也很重要,市场上已有许多入门级移动设备将 Cortex A700 系列用作其主要内核。
与 Cortex-X4 类似,Cortex-A720 是围绕 Armv9.2 ISA 构建的,Arm 优化了其设计,使 A720 能够在相同的功率预算内提供比 Cortex A715 更高的性能。Arm 700 系列通常涵盖范围更广的应用并迎合各种市场,包括但不限于数字电视 (DTV)、智能手机和笔记本电脑。在更多样化的空间中拥有更全面的灵活性有其优势,而 Arm 希望通过 Cortex-A720 充当 TSC23 核心集群的“主力”来利用这一优势。
入门级智能手机等设备通常希望降低成本,同时最大限度地提高性能和效率,而这正是 Cortex-A720 等内核发挥作用的地方;Cortex-X4 主要分配给具有旗舰地位的设备或需要最高爆发和持续性能的设备,例如顶级智能手机、平板电脑和笔记本电脑。对于 Cortex-A720,Arm 声称这可以在实施时进行配置,以匹配与 Arm Cortex A78 内核相同的面积占用,但整体性能提升 10%。
Arm 的重点是扩大入门级市场的范围并扩展其 Cortex-A720 内核的可能用例,以便它可以在更广泛的入门级移动设备和低端市场中实施。
与之前的 A715 相比,Cortex-A720 的一些关键改进是 Arm 选择了更快的分支预测错误恢复。分支预测将指令分解为谓词,分支预测器将只执行它断言为真的语句。选择更快的分支预测错误恢复有很多好处,因为它不仅可以减少指令执行中的延迟,还可以提高整体性能。另一个因素是流水线效率,因为分支预测错误会扰乱流水线中的指令流,而更快地执行此操作的能力不仅会提高性能,还会提高整体能效。
Arm 已将 A720 上的整体分支预测错误惩罚减少到 11 个周期,低于 Cortex A715 上的 12 个周期。他们还改进了 2-taken 分支预测技术,该技术可以预测指令的结果,并再次提高流水线的效率并减少错误预测的惩罚。
另一个改进是 Pipelined FDIV/FSQRT(除法 + 平方根),它使用管道对浮点数执行操作。允许同时执行 FDI 和 FSQRT 可以提高指令量,Arm 声称已经在不影响整体面积的情况下实现了显着的速度提升。从浮点到浮点的传输速度也更快,包括 NEON 和 SVE2 整数,这是 Arm 为 Armv9 引入的。这还包括对问题队列和执行单元的整体改进,这简化了向 AGU 转发数据的过程。
在 Cortex-A720 的内存系统中,将 L2 缓存延迟减少到 9 个周期,并且 Arm 声称 L2 缓存中的 memset(0) 带宽高达 2 倍。在没有详细介绍他们的方法的情况下,Arm 还声称在预取器的准确性和覆盖范围方面有了一代又一代的改进。但是,它有一个新的 L2 空间预取引擎,这是以前开创性的 Cortex-X 核心系统设计功能。
将改进和改进转化为性能,Arm 估计等频性能提升约 15%,具体取决于工作负载。在其他基准测试中,与上一代相比,SPECint2017 有明显的进步,并且在 SPECint2006 的内部测试中有所改进。例如,在 SPECint2007\_403.gcc 中使用 SPECint2007 作为其性能指标,Cortex-A720 比 Cortex A715 提高了约 5%,功率效率提高了约 6%。
提供的其他性能指标包括 DRAM 读取,Arm 将大量注意力集中在提高效率上,总体上显示出较小的收益;SPEC2007int\_483.xalacbmk 显示 DRAM 读取性能大幅提升高达 41%。虽然一切都与任务的工作负载相关且主观,但 Arm 凭借其最新的 Cortex-A720 CPU 核心微架构取得了一些明显的进步。
Cortex-A520:大改进的小内核
Armv9.2 内核中的第三个是 Cortex-A520,它的设计很少,但 Arm 承诺比前几代有很大改进,尤其是在能效方面。
立即解决最大的问题:不,Cortex-A520 不是乱序内核设计。忠于 Arm 的小核心设计理念,它仍然是有序核心——事实上,Arm 甚至在此过程中移除了 ALU。
Arm 这一代的最小内核实际上是一个新内核,但它更多的是对 Cortex-A510 的改进,而不是全新的设计。在已发布的所有三个 Cortex Armv9.2 内核中,它的功率面积比最低。最显著的差异来自功率优化,Arm 声称 Cortex-A520 在等进程和等频率下的能效比之前的 Cortex-A510 内核高 22%。Arm 的 TCS23 目录中的小内核主要是为执行低强度和后台操作任务而设计的,它可以减轻 Cortex-A720/Cortex-X4 等较大内核的负载,从而提高集群内的整体能效。

Arm 的许多效率提升来自于微小的微架构级别变化,主要围绕它如何实现数据预取和分支预测。总的来说,小核改动不大,但是小改动都是为了提高效率。
非架构方面的改进之一是引入了新的 QARMA3 指针身份验证代码 (PAC) 算法,Arm 声称该算法可将 PAC 的开销降低到 1% 以下。QARMA3 是一种基于密码的技术,旨在确保指针的完整性是正确和准确的。它还提供了一种安全有效的方法来避免篡改必要的底层代码,以便在删除指针后进行的任何授权修改或篡改都会增加一层硬件级安全性。Arm 不仅利用 QARMA3 PAC 来提高安全性和完整性,而且与使用具有旧算法的 PAC 相比,它还允许他们挤出更高级别的效率。

就像 Arm 在 2021 年宣布其 armv9 架构时一样,小型 Cortex-A520 内核可以成对合并以共享管道并提高效率。采用一对较小的 Cortex-A520 内核可以通过 SVE、NEON 和 FP 等相关流水线将它们组合起来,从而提高效率。在 SVE2 的情况下更是如此,它确实需要比其他执行更大的面积占用,并且将两个较小的内核配对比单独使用一个更有意义。然而,如果 SoC 供应商愿意,他们完全有可能在他们的设计中使用单核选项实现。
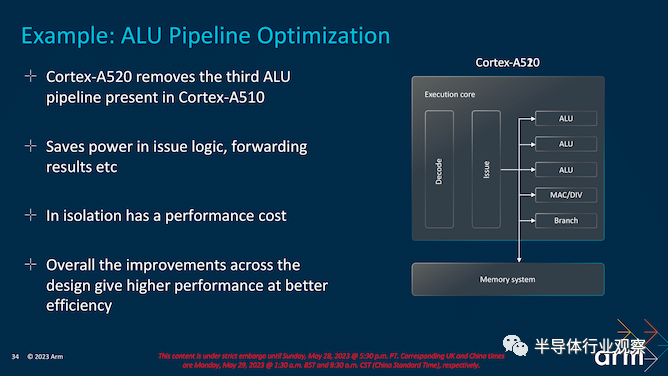
有时少即是多,就 Cortex-A520 而言,Arm 移除了第三个 ALU 流水线,它最初使用 Cortex-A510 添加到 Cortex-A5x DNA 中。Arm 在这背后的理念是它可以节省问题逻辑的能力,并在管道的整体复杂性内改善转发结果。在实践中,Arm 已经找到了如何通过其他改进来恢复足够的性能损失,他们选择吃掉移除 ALU 的损失,以最小化核心尺寸并最大化效率。
最终,Arm 也在寻求全局性的权衡。降低 Cortex-A520 的功耗可以释放可分配给其他内核的能量,例如 Cortex-A720,甚至适用的 Cortex-X4。这使得 Armv9.2 IP 具有通用性和可扩展性,可以在需要的地方和需要的时候在其他领域节省少量资金。
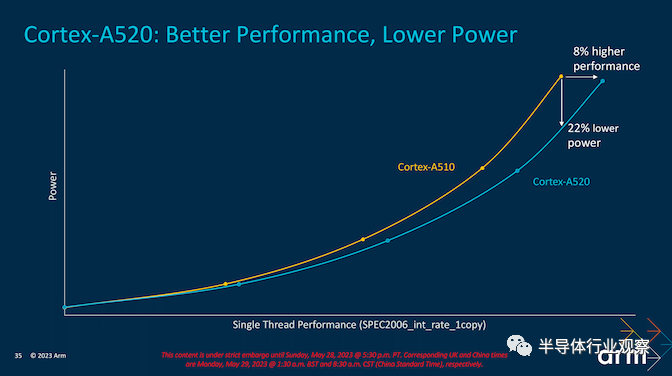
Arm 使用 SPEC2006\_int\_rate\_1copy 作为其性能指标来判断性能和效率,一代又一代(以及在等进程和等频率下),Arm 声称 Cortex-A520 的性能比 Cortex-A510 高出 8%,功耗水平相似. 或者,在 iso-performance 下,Cortex-A520 可以显着节省 22% 的功率。
虽然看起来很小,但它可以在宏伟的计划中加起来,尤其是在 Cortex-A520 内核的四核复合体中。虽然在性能方面增加核心数量的回报水平总是递减,但拥有低功耗和更高效的核心通常会为其他领域创造更多的动力,例如大型 Cortex-X4 核心,这需要更多的咕噜声来提升那些密集和突发依赖的工作负载。
新 DSU-120:更多 L3 缓存,效率翻倍
为了推出其 Armv9.2 架构,Arm 决定在其当前 DSU-110 模块的基础上为其 TCS23 CPU 内核选择一种新的核心复杂设计。DSU-110 最初于 2017 年与 Cortex A75 和 A55 内核一起推出,代表了重大的重新设计和代际转变,以集成更大的共享 L3 缓存池、带宽和可扩展性。除了 Arm 对其新的 Cortex-X4、Cortex-A720 和 A520 内核进行的效率调整外,新的 DynamIQ Shared Unit-120 (DSU-120) 在这些进步中也发挥了重要作用。

Arm 构建了一个更精致的 DSU,而不是另一种全新的设计,通过其 DSU-120 在提高整体可扩展性、效率和性能方面取得了很大进展。一些最显著的改进包括在单个集群中支持多达 14 个 CPU 内核,这允许 SoC 供应商挑选和选择他们的核心集群配置以适应即将上市的设备。Arm 还通过实施新的省电模式(包括 RAM 和切片断电)改进了其功率和性能区域 (PPA),这些模式根据工作负载类型和强度分阶段工作,以减少集群的整体功率占用.

也许 DSU-120 从 DSU-110 到 DSU-120 最显着的变化是 Arm 有效地将集群可以实现的共享 L3 缓存总量翻了一番。DSU-110 最初支持高达 16 MB,而 DS-120 现在可以在整个综合体中容纳高达 32 MB 的共享 L3 缓存,还提供其他选项,包括 24 MB。虽然这不是 IP 中的直接实现,但实现的 L3 缓存数量的决定完全取决于 SoC 供应商根据设备的性能和效率平衡来决定 L3 缓存的正确级别。重点是如果供应商希望实施更多的 L3 缓存,DSU-120 和新的 TCS23 集群有能力支持这一点。
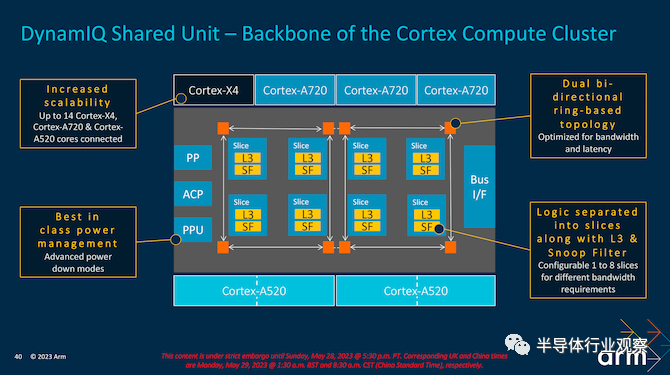
与当前/之前的 DSU-110 互连一样,新的 DSU-120 也使用双双向基于环的拓扑结构,允许在集群内双向传输数据并减少整体延迟。DynamIQ Shared Unit 的整体设计是为了优化延迟和增加带宽,这正是 Arm 通过切片其逻辑 L3 和监听过滤器所做的事情。因此,它可以根据特定的客户带宽要求进行配置。如前所述,DSU-120 允许将多达 14 个 Cortex-X/A 内核实施到一个集群中,与之前的迭代相比,选择最新的 Armv9.2 代具有很多好处。
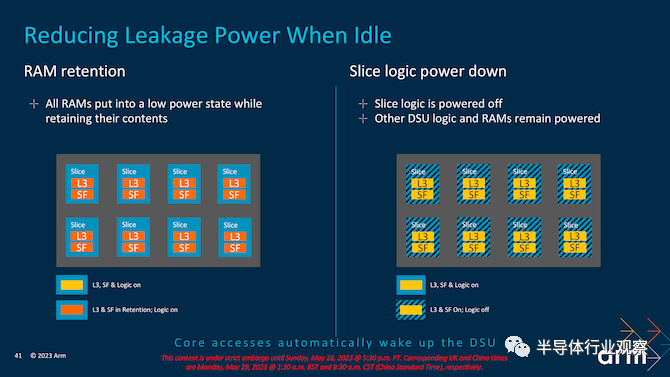
专注于 TCS23 和 DSU-120 复合体的新电源改进,Arm 确定了可以节省电源以最大限度提高效率的特定领域。其中之一是通过 RAM 并减少与之相关的任何不必要的电力泄漏。为了解决这个问题,Arm 选择了一种机制,允许 RAM 在未被积极使用时置于低功耗状态,但仍具有足够的功率来确保其内容的完整性。逻辑被分成带有 L3 高速缓存和旨在提高多核复合体中的高速缓存一致性的探听过滤器的片。
选择带有侦听过滤器的切片方法可以实现几件事情。首先,正如我们所提到的,它改进并增强了缓存一致性。这意味着内核会得到一致且最新的指令,并且探听过滤器本身旨在过滤掉被认为不必要的请求,这确实带来了一些效率优势。其次,切片允许 Arm 的 IP 提高可扩展性,随着内核的增加,意味着增加具有专用缓存切片的切片,从而更好地分配数据并降低数据争用率。带有 DSU-120 的 Armv9.2 IP 允许使用 1 到 8 个片,旨在使 SoC 供应商能够在其带宽要求范围内灵活地工作。

Arm 声称,当所有容量未被使用时,在复合体上的一半 L3 RAM 上启用 RAM 断电适用于大型 L3 缓存。通过允许 RAM 断电,所有未使用的 RAM 都进入低功耗状态,但足以在内存子结构中保留内容并保持其完整性。即使在 RAM 和 Slice 断电的情况下,内核仍然可以处于活动状态并处理相关指令和数据。一个切片将有效地保持活动状态,这非常适合单核上的较小和轻型工作负载,但当涉及到关闭 DSU-120 互连上的功能时,访问内核将唤醒 DSU-120。
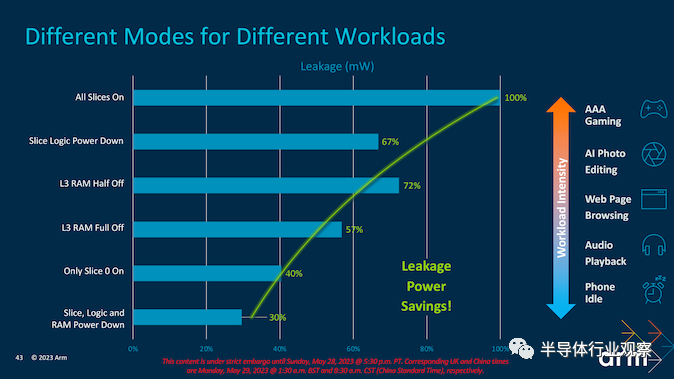
查看这种效率如何转化为数据,Arm 提供了一张方便的幻灯片,其中包含其自己测试的估计值。正如我们所见,通过不同级别的 RAM 和 Slice Logic 断电,我们可以获得不同的潜在节能效果,然后可以将其预算回内核本身以获得更高的性能级别。不同的工作负载和任务需要不同级别的核心功率、一致性、强度和 L3 分配,因此不同的断电会导致不同级别的泄漏和电源效率节省。Arm 的数据估计在其他断电状态下减少 30% 到 72%,在启用所有切片的情况下减少 100% 的泄漏。
结束语:TCS23 承诺提高性能和能效
自 Arm 最新的客户端技术日,我的印象是,在这一代中,Arm 的主要重点甚至比以往任何时候都更加注重提高其电源效率。大多数对最新内核的关注,包括大的 Cortex-X4、中间的 Cortex-A720 和小的 Cortex-A520,并不是要重新发明轮子,而是要对其进行润滑以挤出与之前的 Armv9 相比的改进基于微架构。一直以来,Arm 在确保 SoC 供应商和更广泛的市场为从当前的混合 64/32 位移动市场到完整的 AArch64 世界的完整和动态切换做好准备方面也走了九步。

将 TCS22 与具有相同核心复杂配置 1+3+4 的 TCS23 进行比较,Arm 声称使用速度计基准在同频下获得了高达 33% 的显着增益。在其他地方,当 Arm 将其最新的 TCS23 集群与 1+5+2 配置与 TCS22 与 1+3+4 配置进行比较时,情况会略有偏差。尽管如此,Arm 仍声称 GeekBench 6 的多线程基准测试全面提升了 27%,其中选择两个较大的中间内核并失去两个较小的内核对该数字产生了重大影响。
Arm 的 Armv9.2 公告的关键要点是他们的 IP 将完全绑定到一个完整且完整的 64 位生态系统,并且他们希望利用更统一的市场带来的所有好处。

即使从技术的角度来看,为了提高效率而改进现有的 TCS22 IP 也不是前卫的。它更多地是关于改进当前的 IP 以适应更广泛的市场对效率的关注。从我们所看到的情况来看,大部分收益都来自于通过诸如 RAM 断电和 Slice 断电等实施来减少特定的电源结构,以尽可能节省能源,并允许将节省的电力用于其他领域;或者根本不节省设备电池寿命。
Arm 进一步提高了其所有三个新内核的能效,Cortex-X4 是 Arm 创造的最快的内核,一直到中间的 Cortex-A720 和小的 Cortex-A520 内核。在每个内核中找到功率和性能提升,可以对整体效率产生更显着的影响,这正是 Arm 多年来一直在做的事情。即使是最新的 DynamIQ Shared Unit (DSU-120) 也通过使用动态功耗和各种空闲电源模式来实现活动,从性能的角度来看,这使得事情变得更加高效,尤其是在工作负载不密集并且可以分配给正确的内核,特定的逻辑片可以断电以最大限度地提高效率。
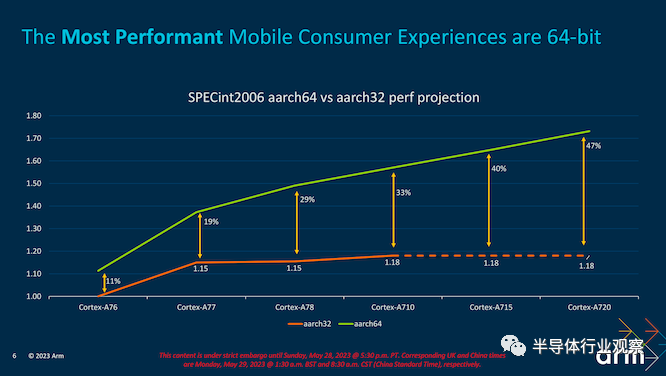
同时,向纯粹的、仅 64 位的 AArch64 ISA 的转变在不同领域产生了许多改进。对于 Arm 的 IP 团队,它允许 Arm 在我们推进时将其工作直接集中在一个特定的 ISA 上。尽管如此,它还在其软件中实现了对等,其中 Arm 的软件工程人员占其整个工程团队的 45%。这是一大笔人力致力于在软件、硬件和 IP 之间的差距中进行改进,并推动 64 位 ISA 生态系统进一步走向完全统一的市场空间。性能优势和基于安全的优势在 32 位和 64 位之间的转换中普遍存在,它只是采用统一的系统,而 Arm 无疑正在鼓励市场从以前的产品转向,包括新发布的 Armv9.2 架构。

虽然 OPPO 等中国公司在向 64 位迁移方面进展缓慢是出了名的,但中国市场 64 位应用程序的增长在去年呈指数级增长。64 位和 32 位之间的应用程序周期主要由谷歌及其 Play Store 驱动,其开发人员多年来需要编译 64 位版本。这一要求确保软件开发商,尤其是那些与 Arm 合作为最新的 Arm IP 优化其软件的开发商,对较慢的采用者和市场产生积极影响,促使他们最终转向 64 位。
64 位的下一步是挤出比 32 位更多的优势;一方面,安全在推动事情向前发展方面发挥着更重要的作用。AArch64 不仅性能优于 AArch32,而且 64 位 ISA 提供了更多安全选项。在简化从 IP 到硬件、到软件、到设备、再到市场的整个过程中找到效率,应该有望通过从公司计划中完全放弃 32 位来降低成本。即使对于像下一波数字电视 (DTV) 这样不断增长的市场的设备,这些供应商无疑也可以将提高的性能和安全完整性的优势应用到他们的产品中。
所有这些都与事物的制造方面密切相关。尽管 Arm 在 IP 级别改进了其设计,并在 iso-process 的基础上提供了收益,但节点缩小仍然是提高芯片性能的最有效方法,尤其是在能效方面。Arm 的 TSC23 IP 是第一个在台积电 N3E 工艺上流片的 IP 绝非侥幸,它标志着 Arm PPA 设计理念的最终组成部分。
总的来说,虽然 Arm 的 2023 CPU 和系统 IP 没有在任何层面带来任何根本的微架构变化,但总的来说它是一系列新的 IP 产品。在去年将球转向带有 Cortex-A715 的纯 64 位 CPU 内核之后,今年的最终全面转变仍需要一些时间来适应,但总体而言应该是一个相当平稳的过渡。通过这样做的同时关注他们的 SoC 客户真正关心的 PPA 的那些方面——小的裸片尺寸可以降耗——Arm 为他们的合作伙伴提供了两个很好的理由来继续推进其他方面公司。Arm 的合作伙伴最终制造出什么样的芯片还有待观察,但我们期待在今年晚些时候看到事情的进展。

