
出品人:Towhee 技术团队
作者:顾梦佳
近日,谷歌推出了一个能够理解并生成语音理解的大型语言模型——AudioPaLM。这一模型融合了分别基于文本和语音两种语言模型——PaLM-2 和 AudioLM,形成了一个统一的多模态架构。该模型不仅能对文本进行处理,还能处理音频,实现多模态处理。另外,AudioPaLM 还同时继承了AudioLM 和PaLM-2的能力,比如保留语音信息(如说话人身份和语调)以及文本大语言模型所独有的语言知识。
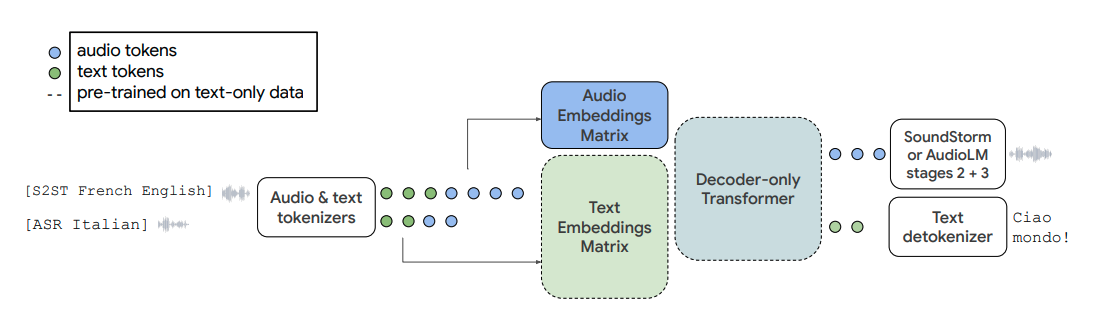
|Speech-to-Speech Translation & Automatic Speech Recognition by AudioPaLM
AudioPaLM 能够模拟由文本和音频 token 组成的序列。模型采用仅用解码器的Transformer结构来处理输入,将文本和音频作为任意整数序列,输入前进行分词,输出后再进行反分词。AudioPaLM 在处理音频数据时,首先从现有语音表征模型中提取向量,然后将这些向量离散化为一组有限的音频token,用于表示语音。结合该音频词汇表和一个用于表示文本的SentencePiece,模型构建了一个多模态词汇表。
由于 AudioPaLM 是基于 Transformer 模型的大语言模型,它可以使用基础的文本预训练模型来初始化权重,从而受益于 PaLM 或 PaLM 2 等模型的语言和常识知识。由于统一的多模态架构,AudioPaLM 能够使用直接映射或组合任务的方式来解决语音识别、语音合成和语音翻译等问题。单一任务包括自动语音识别(ASR)、自动语音翻译(AST)、语音到语音翻译(S2ST)、文本到语音(TTS)和文本到文本机器翻译(MT)等。为了指定模型在给定输入上执行的任务,可以在输入前加上标签,指定任务和输入语言的英文名称,输出语言也可以选择加上。例如,[ASR French]表示执行法语的自动语音识别任务,[TTS English]表示执行英语的文本到语音任务,[S2ST English French]表示执行从英语到法语的语音到语音翻译任务,而组合任务的标签[ASR AST S2ST English French]表示依次进行从英语到法语的自动语音识别、自动语音翻译、语音到语音翻译。微调使用的数据集包含音频、音频的转录、音频的翻译、音频的翻译文本等。一个数据集可以用于多个任务,将同一数据集中的多个任务结合起来可以提高性能。
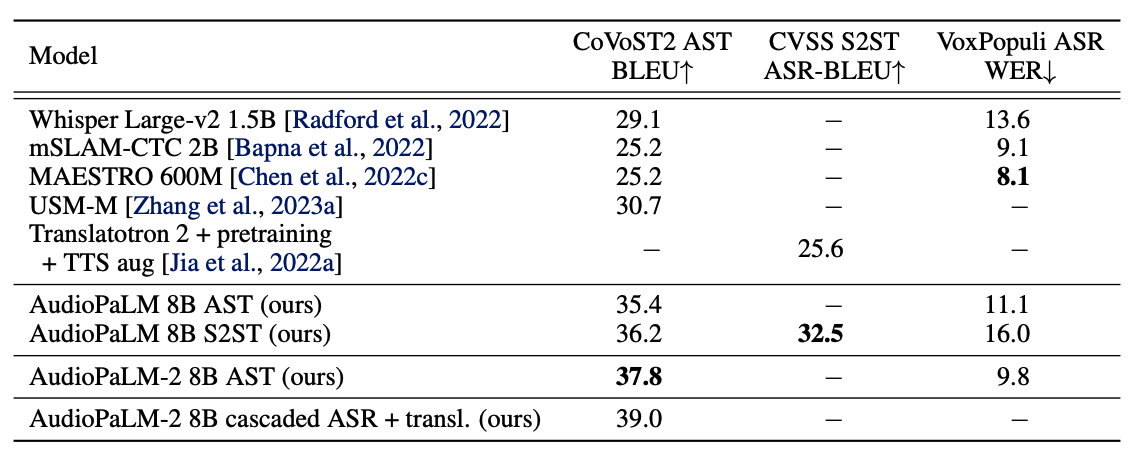
|Top level experiment results of AudioPaLM
AudioPaLM 在语音翻译基准测试中展示了最先进的结果,并在语音识别任务上表现出竞争性能。利用 AudioLM 的语音提示,该模型还可以对未见过的讲话者进行 S2ST,超越现有方法,以客观和主观评估的方式衡量语音质量和声音保持。另外,该模型展示了零样本迁移的能力,可以使用训练中未曾出现过的语音输入/目标语言组合进行 AST。
总的来说,AudioPaLM 是一款非常强大的语音理解与生成的大型语言模型,能够处理和生成语音和文本,并且可以被应用于语音识别和语音翻译等领域。它为语音技术领域的发展带来了新的思路和突破,将有助于大大提高语音理解和生成的准确性和效率,为人们的生活带来更多便利。另外,这一新技术的出现也让机器更加“聪明”、更加接近人类。
相关资料:
- 论文链接:https://arxiv.org/abs/2306.12925
- 官方演示:https://google-research.github.io/seanet/audiopalm/examples/
🌟全托管 Milvus SaaS/PaaS 即将上线,由 Zilliz 原厂打造!覆盖阿里云、百度智能云、腾讯云、金山云。目前已支持申请试用,企业用户 PoC 申请或其他商务合作请联系 business@zilliz.com。
- 如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。
- 欢迎关注微信公众号“Zilliz”,了解最新资讯。

本文由mdnice多平台发布

