Pandas是我们最常用的数据处理Python库之一。尽管您可能已经与它共事多年,但可能还有许多您尚未探索的实用方法。我将向您展示一些可能未曾听说但在数据整理方面非常实用的方法。
LoRA是人工智能中有效扩展预训练语言模型(llm)上下文大小的一种方法。LongLoRA通过在训练期间利用稀疏的局部注意力和在推理期间利用密集的全局注意力,允许进行经济有效的微调并保持性能。LongLoRA在各种任务上展示了令人印象深刻的结果,并在llm中支持多达10万个令牌的上下文扩展。
我们都知道Transformers相对于CNN的架构效率并不高,这导致在一些边缘设备进行推理时延迟会很高,所以这次介绍的论文EfficientFormer号称在准确率不降低的同时可以达到MobileNet的推理速度。
数据清理是数据分析过程中的关键步骤,它涉及识别缺失值、重复行、异常值和不正确的数据类型。获得干净可靠的数据对于准确的分析和建模非常重要。
levi - unet[2]是一种新的医学图像分割架构,它使用transformer 作为编码器,这使得它能够更有效地学习远程依赖关系。levi - unet[2]比传统的U-Nets更快,同时仍然实现了最先进的分割性能。
最近两个最流行的AI图像生成器,Midjourney和Stable Diffusion,都发布了重大更新。Midjourney v5.2引入了许多新功能,包括“缩小”功能、“/缩短”命令、改进的图像质量等。
这时一篇2015年的论文,但是他却是最早提出在语义分割中使用弱监督和半监督的方法,SAM的火爆证明了弱监督和半监督的学习方法也可以用在分割上。
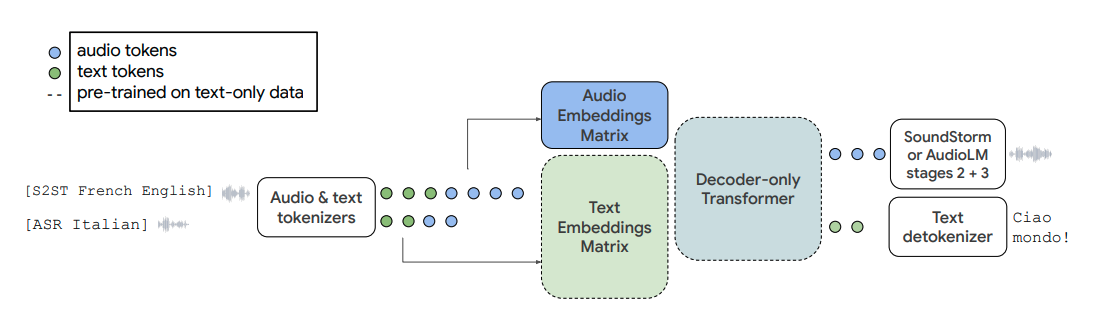
近日,谷歌推出了一个能够理解并生成语音理解的大型语言模型——AudioPaLM。这一模型融合了分别基于文本和语音两种语言模型——PaLM-2 和 AudioLM,形成了一个统一的多模态架构。该模型不仅能对文本进行处理,还能处理音频,实现多模态处理。另外,AudioPaLM 还同时继承了AudioLM 和PaLM-2的能力,比如保留语音信息(如说话...
在数字时代,视频已经成为一种主要的内容形式。但是理解和解释视频内容是一项复杂的任务,不仅需要视觉和听觉信号的整合,还需要处理上下文的时间序列的能力。本文将重点介绍称为video - llama的多模态框架。Video-LLaMA旨在使LLM能够理解视频中的视觉和听觉内容。论文设计了两个分支,即视觉语言分支和音频语言分支,分...
在统计建模领域,理解总体趋势的同时解释群体差异的一个强大方法是分层(或多层)建模。这种方法允许参数随组而变化,并捕获组内和组间的变化。在时间序列数据中,这些特定于组的参数可以表示不同组随时间的不同模式。
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。
Optuna是一个开源的超参数优化框架,Optuna与框架无关,可以在任何机器学习或深度学习框架中使用它。本文将以表格数据为例,使用Optuna对PyTorch模型进行超参数调优。
大多数大型语言模型(LLM)都无法在消费者硬件上进行微调。例如,650亿个参数模型需要超过780 Gb的GPU内存。这相当于10个A100 80gb的gpu。就算我们使用云服务器,花费的开销也不是所有人都能够承担的。
假设我们想要在音频记录中检测一个特定的人的声音,并获得每个声音片段的时间边界。例如,给定一小时的流,管道预测前10分钟是前景(我们感兴趣的人说话),然后接下来的20分钟是背景(其他人或没有人说话),然后接下来的20分钟是前景段,最后10分钟属于背景段。
偏度(skewness)是用来衡量概率分布或数据集中不对称程度的统计量。它描述了数据分布的尾部(tail)在平均值的哪一侧更重或更长。偏度可以帮助我们了解数据的偏斜性质,即数据相对于平均值的分布情况。
Jupyter 笔记本是数据科学家和分析师用于交互式计算、数据可视化和协作的工具。Jupyter 笔记本的基本功能大家都已经很熟悉了,但还有一些鲜为人知的技巧可以大大提高生产力和效率。在这篇文章中,我将介绍10个可以提升体验的高级技巧。
GMAC 代表“Giga Multiply-Add Operations per Second”(每秒千兆乘法累加运算),是用于衡量深度学习模型计算效率的指标。它表示每秒在模型中执行的乘法累加运算的数量,以每秒十亿 (giga) 表示。
对于大型模型来说,重新训练所有模型参数的全微调变得不可行。比如GPT-3 175B,模型包含175B个参数吗,无论是微调训练和模型部署,都是不可能的事。所以Microsoft 提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预先训练好的模型权重,并将可训练的秩的分解矩阵注入到Transformer体系结构的每一层,从而大大减...
赫尔移动平均线(Hull Moving Average,简称HMA)是一种技术指标,于2005年由Alan Hull开发。它是一种移动平均线,利用加权计算来减少滞后并提高准确性。
数据汇总是一个将原始数据简化为其主要成分或特征的过程,使其更容易理解、可视化和分析。本文介绍总结数据的七种重要方法,有助于理解数据实质的内容。


