
科学发现是一个复杂过程,涉及到几个相互关联的阶段,包括形成假设、实验设计、数据收集及分析。近年来,AI 与基础科研的融合日益加深,借助 AI,科学家得以加速科研进度、促进科研成果的落地。
权威期刊「Nature」刊登了一篇论文,来自斯坦福大学计算机科学与基因技术学院的博士后 Hanchen Wang,与佐治亚理工学院计算科学与工程专业的 Tianfan Fu,以及康奈尔大学计算机系的 Yuanqi Du 等 30 人,回顾了过去十年间,基础科研领域中的 AI 角色,并提出了仍然存在的挑战和不足。
本文对该论文进行了整理汇总。
阅读完整论文:https://www.nature.com/articles/s41586-023-06221-2
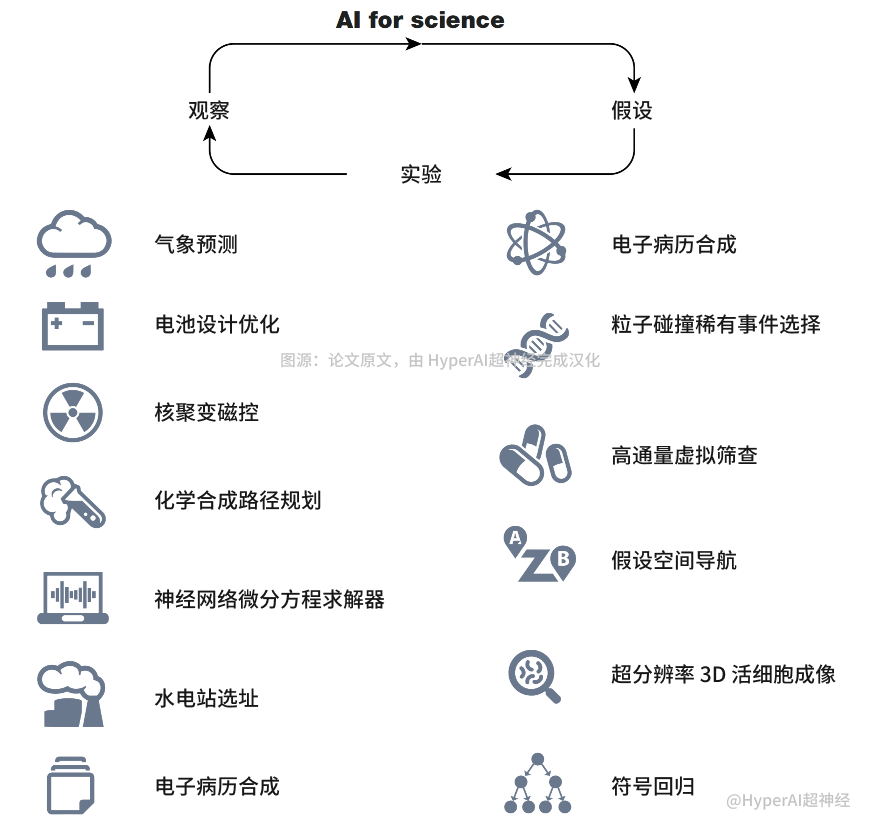
AI 与基础科研的结合案例 图源:论文原文,由 HyperAI超神经完成汉化
01 AI 辅助科研数据收集及整理
随着实验平台收集的数据规模及复杂性不断增加,要想选择性地存储和分析高速生成的数据,必须依赖实时处理及高性能计算 (HPC)。
数据选择
以粒子碰撞实验为例,每秒会产生超过 100 TB 的数据,这对于现有的数据传输和存储技术造成了极大的挑战。在这些物理实验中,超过 99.99% 的元数据必须进行实时检测并舍弃无关数据。深度学习、自动关编码器等技术,可以帮助识别类似科学研究中的异常事件,极大降低数据传输和处理的压力。
目前这些技术并已广泛应用于物理、神经科学、地球科学、海洋学及天文学等领域。
数据标注
伪标签 (Pseudo-labelling) 和标签传播算法 (label propagation) 对于替代繁琐的数据标注具有重要意义,可以使得模型在仅有少量准确标注的数据的前提下,自动对海量数据进行标注。
数据生成
通过自动数据增强及深度生成模型,可以生成额外的合成数据点 (additional synthetic data points),进而扩充训练数据。实验证明,生成对抗网络 (Generative adversarial networks,简称 GAN) 在诸多领域都能合成逼真图像,范围涵盖粒子碰撞事件、病理切片、胸部 X 光、磁共振对比、三维 (3D) 材料微结构、蛋白质功能到基因序列等。
数据优化
AI 可以显著提高图像分辨率、减少噪声,并消除测量 roundness 时的报错,从而在各个 site 都保持高精度一致性。其应用案例包括可视化时空区域如黑洞、捕获物理粒子碰撞、提升活体细胞图像分辨率以及更好地检测不同生物环境下的细胞类型。
02 学习科学数据有意义的表征
深度学习可以在各种抽象级别上提取科学数据有意义的表征并对其进行优化。高质量的表征应该尽可能地保留数据相关信息,同时保持简洁和易于访问。这里介绍 3 种满足这些要求的新型策略:几何先验 (geometric priors)、自监督学习 (self-supervised learning) 及语言建模 (language modelling)。
几何先验 (geometric priors)
几何和结构对科学研究至关重要,对称性是几何学中的重要概念,重要的结构属性在空间方向上是稳定的,不会发生变化。在科学图像分析中,将几何先验整合到学习表征中已被证明是有效的。
几何深度学习
图神经网络已成为在具有基础几何和关系结构的数据集上,进行深度学习的主要方法。根据科学问题的不同,科研人员开发了各种图表征 (graph representations) 来捕获复杂系统。
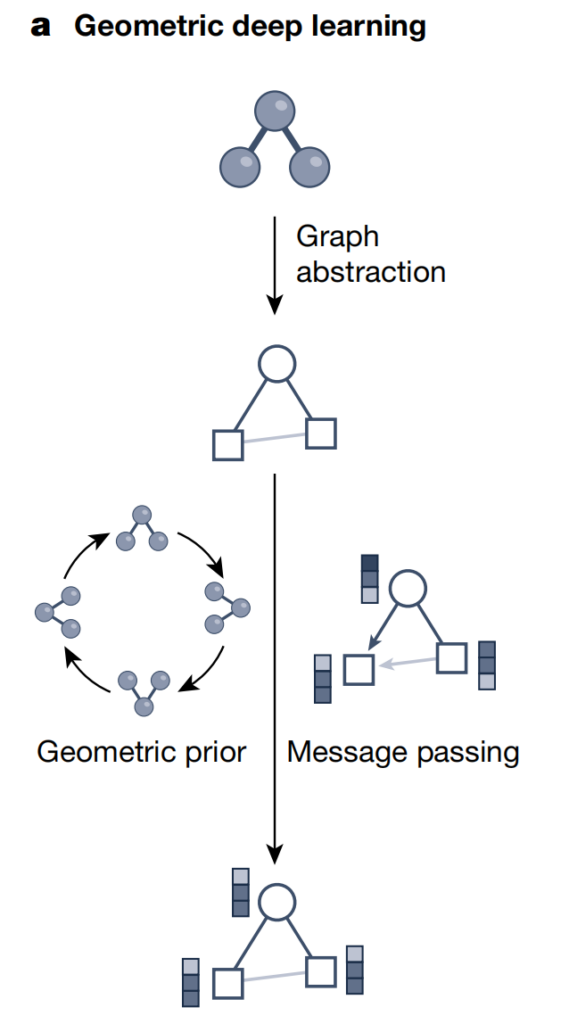
如上图所示,几何深度学习利用图结构及神经信息传递策略,整合了分子/材料等科学数据的几何、结构和对称性信息。这种方法沿图结构中的 edge 交换神经信息,来生成潜在表征(嵌入向量),同时考虑其他几何先验(如不变性和等差数列约束)。因此,几何深度学习可以将复杂的结构信息,纳入深度学习模型,从而更好地理解和处理底层几何数据集。
自监督学习
自监督学习使得模型能够在不依赖明确标签 (explicit label) 的情况下,了解数据集的通用特征 (general features),它可以作为一个关键的预处理步骤,在微调模型执行下游任务前,从大规模未标注数据中学习可转移特征 (transferable features)。这样预先训练好的具有广泛科研领域理解力的模型是通用目标预测器,可以适应多种任务,从而提高效率并超越了单纯的有监督方法。
![]()
如上图所示,有效表示卫星图像等不同样本,需要同时捕捉它们的相似性和差异性。自监督学习策略(如对比学习)可通过生成增强的对等数据、对齐正向数据并分离负向数据对来实现这一目标。这种迭代过程会增强嵌入,从而产生信息丰富的潜在表征,并在下游预测任务中取得更好的性能。
语言建模
遮罩语言建模 (Masked-language modelling) 是自监督学习自然语言和生物序列的流行方法(见下图)。
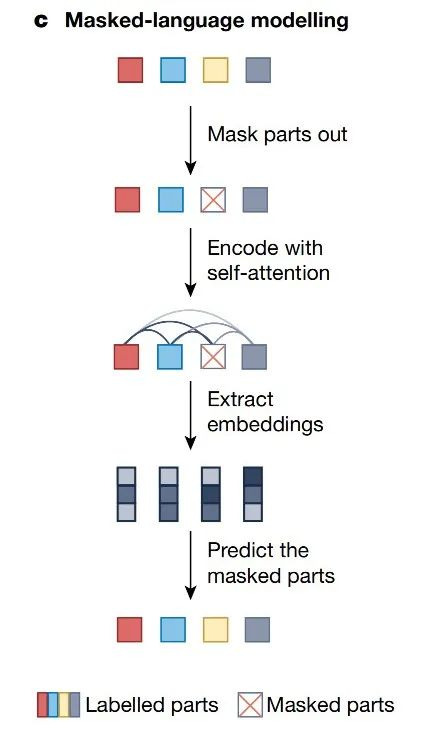
自然语言处理与生物序列处理彼此影响。训练过程中,目标是预测序列中的下一个 token,而在基于遮罩的训练中,自监督任务是使用双向序列上下文,恢复序列中被遮罩的 token。蛋白质语言模型可以编码氨基酸序列,捕获结构性和功能性属性,并评估病毒变种的进化适应度。处理生化序列时,化学语言模型可以有效探索广阔的化学空间。
如上图所示,遮罩语言建模可以有效捕捉序列数据的语义,如自然语言和生物序列。这种方法是将输入中的遮罩元素输入 Transformer 模块,其中包括位置编码等预处理步骤。灰色线条表示 self-attention 机制,颜色深浅反映了 attention 权重的大小,它结合非遮罩输入的表征,对遮罩输入进行准确预测。该方法通过在输入的诸多元素中重复这一自动完成过程,产生高质量的序列表征。
Transformer 架构
Transformer 统一了图神经网络和语言模型,主导自然语言处理,并已成功应用于地震信号检测、DNA 和蛋白质序列建模、对生物功能影响的序列变异效果建模以及符号回归等领域。
神经算子
通过学习函数空间之间的映射,神经算子离散化不变,可以在任何 input 离散化上工作,并在网格细化时收敛到一个限制值。一旦训练了神经算子,就可以在任何分辨率下对其进行评估,无需重新训练。
03 生成基于 AI 的科学假设 (hypotheses)
AI 可以通过识别噪声观察结果中的候选符号表达来生成假设。它们可以帮助设计对象、学习假设贝叶斯后验概率,并用其产生与科学数据和知识兼容的假设。
科学假设的黑箱预测器
弱监督学习可用来训练嘈杂、有限或不精确监督被用作训练信号 (signal) 的模型。
AI 方法经过高仿真模拟训练,已被用来有效筛选大规模分子库;基因组学中,训练 Transformer 架构用 DNA 序列预测基因表达值,进而识别基因变异;蛋白质折叠中,AlphaFold2 可以从氨基酸序列预测蛋白质 3D 原子坐标;粒子物理学中,识别质子内固有的魅力夸克,会涉及到筛选所有可能的结构,并对所有潜在结构进行实验数据拟合。
除了正向问题外, AI 也越来越多地被用于解决逆向问题。
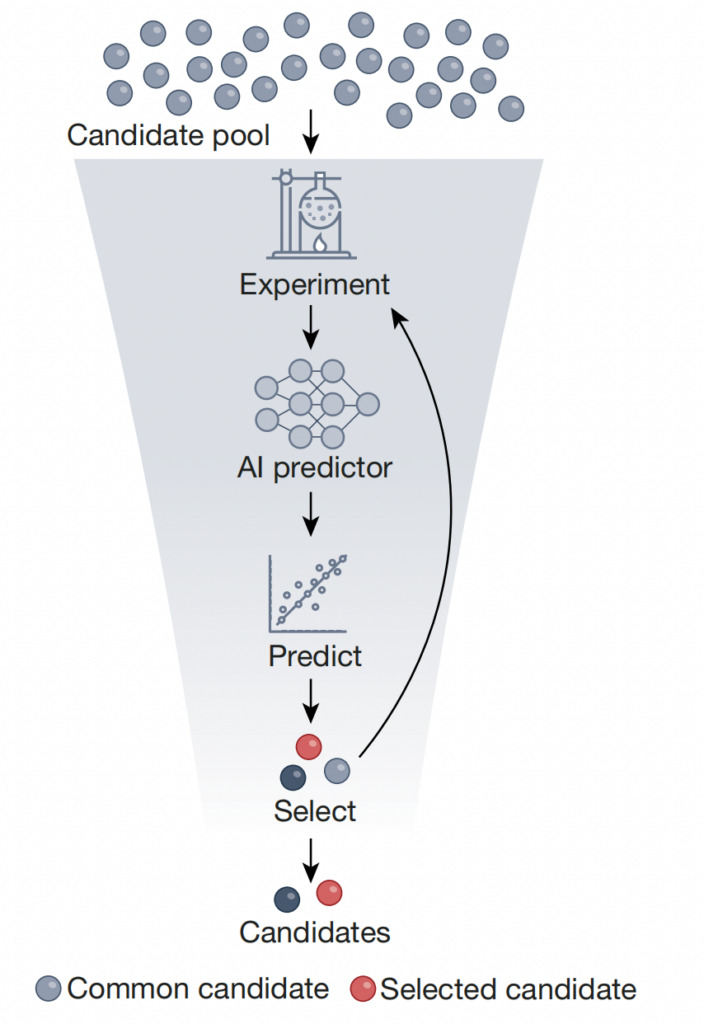
如上图所示,高通量筛查是指利用在实验生成的数据集上训练的 AI 预测器,筛选出少量具有理想特性的目标对象,从而将候选对象库的总规模减少几个数量级。这种方法可以利用自监督学习,在大量未筛选对象上对预测器进行预训练,然后在标注好 readouts 筛选对象数据集上,微调预测器。实验室评估和不确定性量化可以完善这种方法,从而简化筛选过程,提高成本效益和时间效率,最终加快候选化合物、材料和生物分子的鉴定。
探索组合假设空间 (combinatorial hypothesis spaces)
相比于依赖手动设计规则的传统方法,AI 策略可以用来评估每次搜索的奖励 (reward),并识别价值更高的搜索方向。
对于优化问题,可以使用进化算法来解决符号回归任务。组合优化也适用于发现具有理想药物属性的分子等任务,其中每一步在分子设计中都是一个离散决策过程。此外强化学习方法已成功应用于各种优化问题,如最大限度提高蛋白质表达、规划亚马逊平原水电,以及探索粒子加速器参数空间。
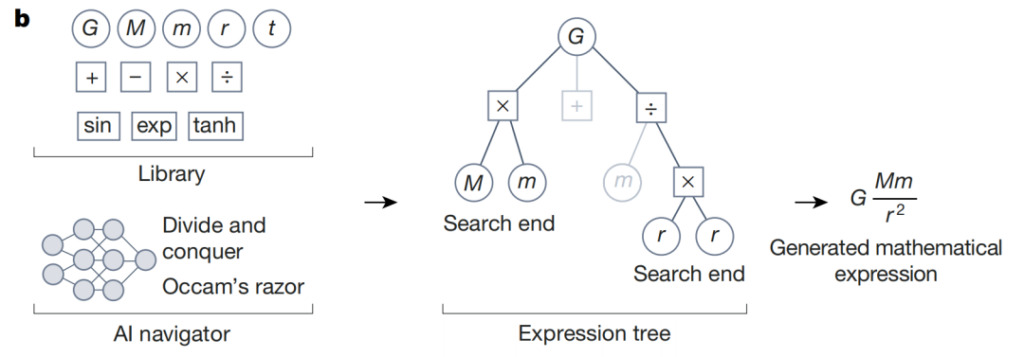
如上图所示,在符号回归过程中,AI navigator 利用强化学习 agent 和设计标准(如奥卡姆剃刀)预测的 reward,将重点放在候选假设中最有希望的元素上。后面的示例说明了牛顿万有引力定律数学表达式的推理过程。低分搜索路径在符号表达式树中显示为灰色分支。在与最高预测 reward 相关的行动的引导下,这一迭代过程会趋近于与数据一致并符合其他设计标准的数学表达式。
优化可微假设空间 (differentiable hypothesis spaces)
可微空间适合基于梯度的方法,可以有效地找到局部最优解。为了启用基于梯度的优化,通常使用两种方法:
* 使用类似 VAEs 这样的模型,将离散候选假设映射到一个潜在可微空间中;
* 将离散假设放宽成可在可微空间内进行优化的可微对象(这种放宽可以采取不同形式,例如用连续变量替换离散变量,或使用原始约束条件的 soft version)。
在天体物理学中, VAEs 已被用于根据预训练黑洞波形模型,评估引力波探测器参数。这种方法比传统方法快了 6 个数量级。材料科学中,热力学规则与自编码器相结合,设计了一个可解释潜在空间以识别晶体结构映射图。
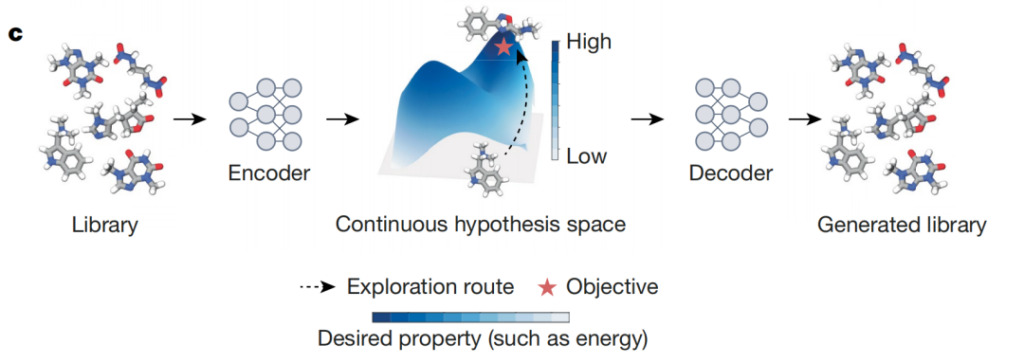
如上图所示,AI 微分器 (AI differentiators) 是一种自编码器模型,可将离散对象(如化合物)映射到可微分的连续潜在空间中的 Point。这个空间允许对目标对象进行优化,例如从庞大的化学库中,选择能最大限度提高特定生化终点的化合物。理想蓝图描述了学到的潜在空间,较深的颜色表示预测分数较高的对象集中的区域。利用这一潜在空间,AI differentiator 可以高效识别出能最大化红星标注的预期属性的对象。
04 AI 驱动的实验及模拟
计算机模拟可以替代成本高昂的实验室实验,提供更高效灵活的试验可能性。深度学习可以识别并优化假设,从而进行有效测试,并使计算机模拟能够将观察结果与假设联系起来。
高效评估科学假设
AI 系统提供了实验设计和优化工具,这些工具可以增强传统的科学方法,减少所需的实验数量并节省资源。
具体来说,AI 系统可以协助进行实验测试的两个关键步骤:规划和引导。AI 规划为设计实验、优化效率以及探索未知领域提供了一种系统性的方法。同时,AI 引导将实验过程指向高产出假设,允许系统从先前的观察中学习并调整实验进程。这些 AI 方法可以基于模型(使用模拟和先验知识),也可以是仅基于机器学习算法的无模型方法。
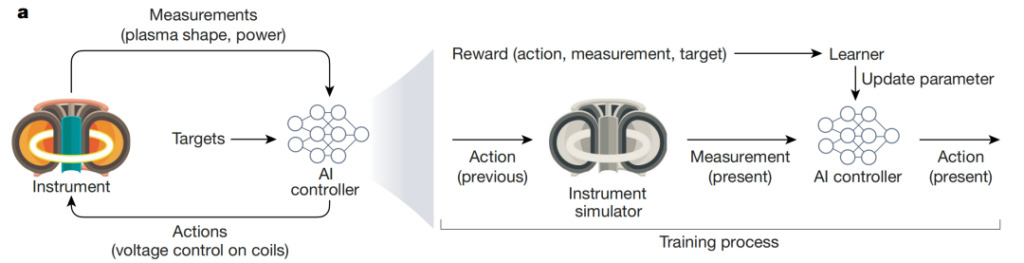
上图展示的是利用 AI 控制复杂、动态的核聚变过程:Degrave 等人开发了一种 AI controller,可以通过托卡马克反应堆中的磁场调节核聚变。AI agent 接收对电气电压水平和等离子体配置的实时测量结果,并采取行动控制磁场,实现实验目标(如维持正常的电力供应)。Controller 通过模拟进行训练,并利用 reward 函数更新模型参数。
借助模拟从假设中推导可观察量 (observables)
现有的计算机模拟技术,严重依赖人类对系统底层机制的理解和认知,AI 系统可以更准确高效地适应复杂系统关键参数,解决可以控制复杂系统的微分方程,并对复杂系统状态进行建模,以此来增强计算机模拟。
以分子力场 (molecular force fields) 为例,它们虽然具备可解释性,但在各种功能的表示上受限,而且生成过程中需要极强地归纳偏见,以及丰富的科学知识。为了提高分子模拟的精度 (accuracy),开发出了基于 AI 的、适应昂贵且精确量子力学数据的神经电位 (neural potential),来取代传统力场。
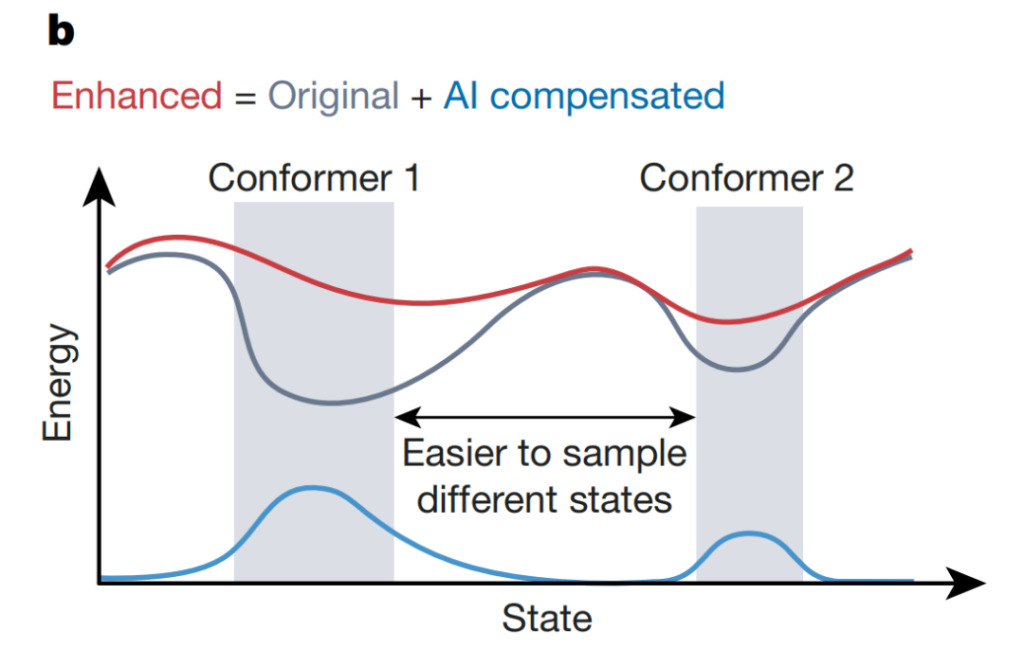
在复杂系统的计算模拟中,AI 系统可以加速异常事件的检测,例如蛋白质构象结构之间的转换。上图所示,Wang 等人利用基于神经网络的不确定性评估器,引导增加补偿原始势能 (potential) 的势能,使系统摆脱局部极小值(灰色),更快地探索配置空间。这种方法可以提高模拟的效率和准确性,从而加深对复杂生物现象的理解。
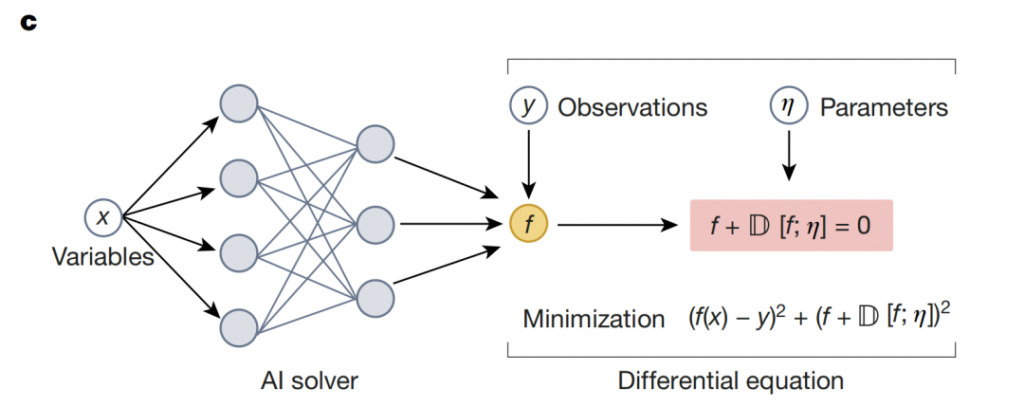
神经求解器将物理与深度学习的灵活性相结合:在领域知识的基础上构建神经网络
05 AI for Science 任重道远
AI 系统有助于科学理解,事实证明,AI 能够对难以可视化或探测的过程和物体进行研究,并通过从数据中建立模型、将数据与模拟和可扩展计算相结合,系统性地提出新想法。但是,要保证 AI 使用过程中的安全性和隐私性问题,这一过程仍然离不开成熟的技术部署。
要在科学研究中负责任地使用 AI,科研人员需要衡量 AI 系统的不确定性、误差和效用水平。随着 AI 系统的不断发展,AI 有望开启以往遥不可及的科学发现之门,但理论、方法、软件和硬件基础设施等配套,仍有很多路要走。
参考文献:

