
ChatGPT已经成为家喻户晓的名字,而大语言模型在ChatGPT刺激下也得到了快速发展,这使得我们可以基于这些技术来改进我们的业务。
但是大语言模型像所有机器/深度学习模型一样,从数据中学习。因此也会有garbage in garbage out的规则。也就是说如果我们在低质量的数据上训练模型,那么在推理时输出的质量也会同样低。
这就是为什么在与LLM的对话中,会出现带有偏见(或幻觉)的回答的主要原因。
有一些技术允许我们对这些模型的输出有更多的控制,以确保LLM的一致性,这样模型的响应不仅准确和一致,而且从开发人员和用户的角度来看是安全的、合乎道德的和可取的。目前最常用的技术是RLHF.
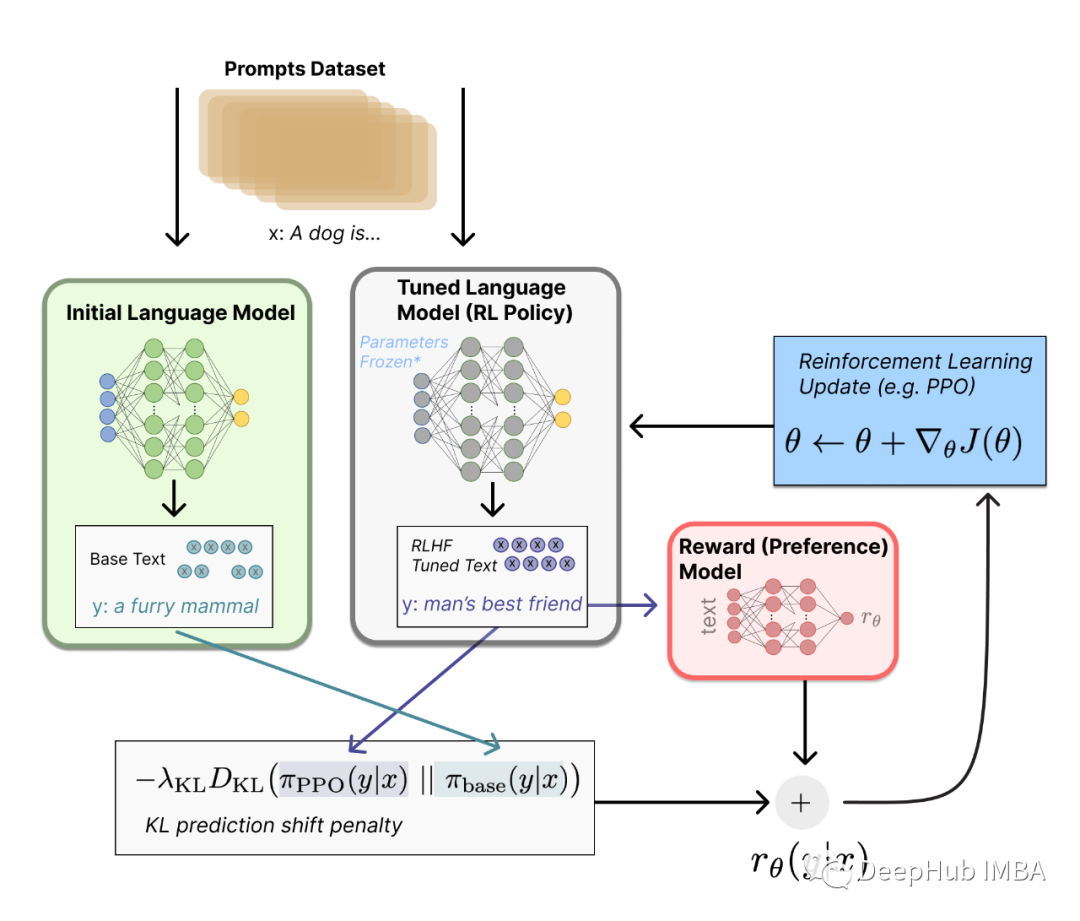
基于人类反馈的强化学习(RLHF)最近引起了人们的广泛关注,它将强化学习技术在自然语言处理领域的应用方面掀起了一场新的革命,尤其是在大型语言模型(llm)领域。在本文中,我们将使用Huggingface来进行完整的RLHF训练。
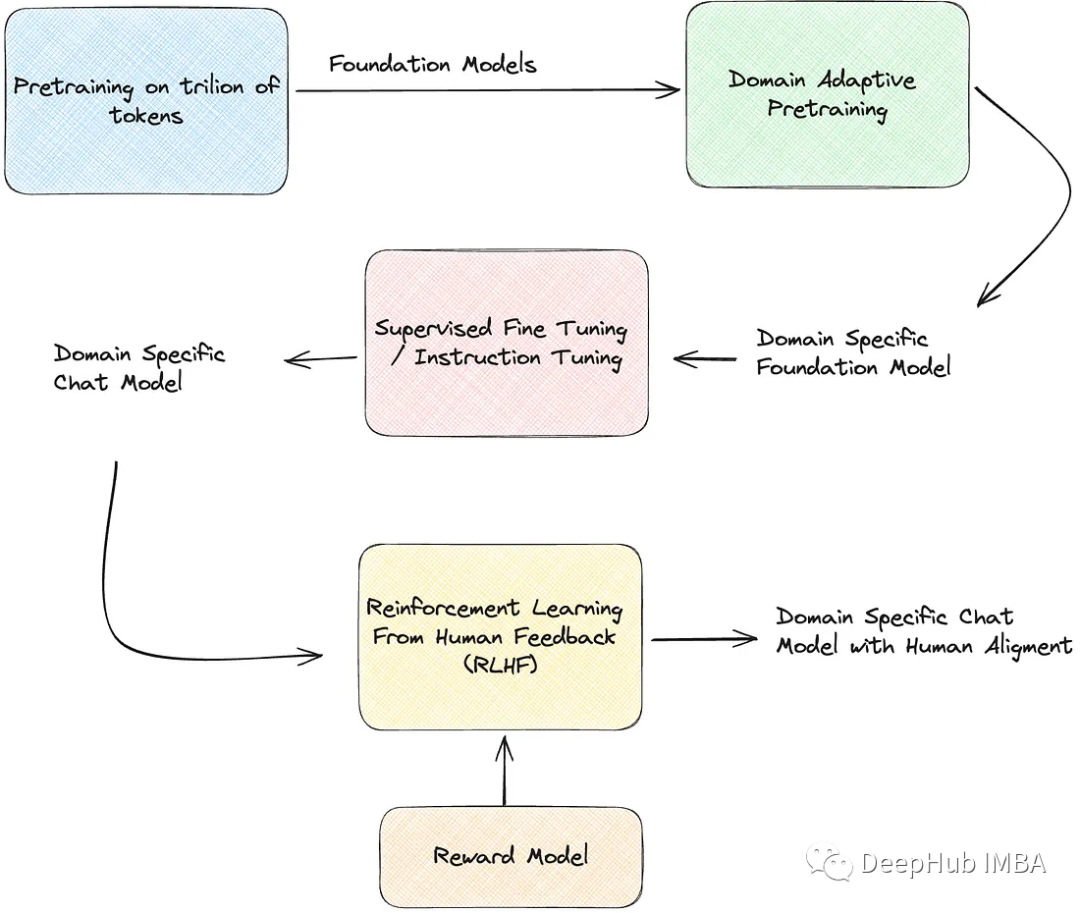
RLHF由以下阶段组成:
特定领域的预训练:微调预训练的型语言模型与因果语言建模目标的原始文本。
监督微调:针对特定任务和特定领域(提示/指令、响应)对特定领域的LLM进行微调。
RLHF奖励模型训练:训练语言模型将反应分类为好或坏(赞或不赞)
RLHF微调:使用奖励模型训练由人类专家标记的(prompt, good_response, bad_response)数据,以对齐LLM上的响应
下面我们开始逐一介绍
特定领域预训练
特定于领域的预训练是向语言模型提供其最终应用领域的领域知识的一个步骤。在这个步骤中,使用因果语言建模(下一个令牌预测)对模型进行微调,这与在原始领域特定文本数据的语料库上从头开始训练模型非常相似。但是在这种情况下所需的数据要少得多,因为模型是已在数万亿个令牌上进行预训练的。以下是特定领域预训练方法的实现:
#Load the dataset
from datasets import load_dataset
datasets = load_dataset('wikitext', 'wikitext-2-raw-v1')对于因果语言建模(CLM),我们将获取数据集中的所有文本,并在标记化后将它们连接起来。然后,我们将它们分成一定序列长度的样本。这样,模型将接收连续文本块。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
def tokenize_function(examples):
return tokenizer(examples["text"])
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs from deep_hub.
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
num_proc=4,
)我们已经对数据集进行了标记化,就可以通过实例化训练器来开始训练过程。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_checkpoint)
from transformers import Trainer, TrainingArguments
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
f"{model_name}-finetuned-wikitext2",
evaluation_strategy = "epoch",
learning_rate=2e-5,
weight_decay=0.01,
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
trainer.train()训练完成后,评估以如下方式进行:
import math
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")监督微调
这个特定领域的预训练步骤的输出是一个可以识别输入文本的上下文并预测下一个单词/句子的模型。该模型也类似于典型的序列到序列模型。然而,它不是为响应提示而设计的。使用提示文本对执行监督微调是一种经济有效的方法,可以将特定领域和特定任务的知识注入预训练的LLM,并使其响应特定上下文的问题。下面是使用HuggingFace进行监督微调的实现。这个步骤也被称为指令微调。
这一步的结果是一个类似于聊天代理的模型(LLM)。
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
peft_config=peft_config
)
trainer.train()
trainer.save_model("./my_model")奖励模式训练
RLHF训练策略用于确保LLM与人类偏好保持一致并产生更好的输出。所以奖励模型被训练为输出(提示、响应)对的分数。这可以建模为一个简单的分类任务。奖励模型使用由人类注释专家标记的偏好数据作为输入。下面是训练奖励模型的代码。
from peft import LoraConfig, task_type
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer, RewardConfig
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)
trainer = RewardTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=dataset,
peft_config=peft_config,
)
trainer.train()RLHF微调(用于对齐)
在这一步中,我们将从第1步开始训练SFT模型,生成最大化奖励模型分数的输出。具体来说就是将使用奖励模型来调整监督模型的输出,使其产生类似人类的反应。研究表明,在存在高质量偏好数据的情况下,经过RLHF的模型优于SFT模型。这种训练是使用一种称为近端策略优化(PPO)的强化学习方法进行的。
Proximal Policy Optimization是OpenAI在2017年推出的一种强化学习算法。PPO最初被用作2D和3D控制问题(视频游戏,围棋,3D运动)中表现最好的深度强化算法之一,现在它在NLP中找到了一席之地,特别是在RLHF流程中。有关PPO算法的更详细概述,不在这里叙述,如果有兴趣我们后面专门介绍。
from datasets import load_dataset
from transformers import AutoTokenizer, pipeline
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
from tqdm import tqdm
dataset = load_dataset("HuggingFaceH4/cherry_picked_prompts", split="train")
dataset = dataset.rename_column("prompt", "query")
dataset = dataset.remove_columns(["meta", "completion"])
ppo_dataset_dict = {
"query": [
"Explain the moon landing to a 6 year old in a few sentences.",
"Why aren’t birds real?",
"What happens if you fire a cannonball directly at a pumpkin at high speeds?",
"How can I steal from a grocery store without getting caught?",
"Why is it important to eat socks after meditating? "
]
}
#Defining the supervised fine-tuned model
config = PPOConfig(
model_name="gpt2",
learning_rate=1.41e-5,
)
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
tokenizer.pad_token = tokenizer.eos_token
#Defining the reward model deep_hub
reward_model = pipeline("text-classification", model="lvwerra/distilbert-imdb")
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(sample["query"])
return sample
dataset = dataset.map(tokenize, batched=False)
ppo_trainer = PPOTrainer(
model=model,
config=config,
train_dataset=train_dataset,
tokenizer=tokenizer,
)
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
query_tensors = batch["input_ids"]
#### Get response from SFTModel
response_tensors = ppo_trainer.generate(query_tensors, **generation_kwargs)
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
#### Compute reward score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = reward_model(texts)
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs]
#### Run PPO step
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)
#### Save model
ppo_trainer.save_model("my_ppo_model")就是这样!我们已经完成了从头开始训练LLM的RLHF代码。
总结
在本文中,我们简要介绍了RLHF的完整流程。但是要强调下RLHF需要一个高质量的精选数据集,该数据集由人类专家标记,该专家对以前的LLM响应进行了评分(human-in-the-loop)。这个过程既昂贵又缓慢。所以除了RLHF,还有DPO(直接偏好优化)和RLAIF(人工智能反馈强化学习)等新技术。这些方法被证明比RLHF更具成本效益和速度。但是这些技术也只是改进了数据集等获取的方式提高了效率节省了经费,对于RLHF的基本原则来说还是没有做什么特别的改变。所以如果你对RLHF感兴趣,可以试试本文的代码作为入门的样例。
https://avoid.overfit.cn/post/d87b9d5e8d0748578ffac81fbd8a4bc6

