
如果你是一个Mac用户和一个深度学习爱好者,你可能希望在某些时候Mac可以处理一些重型模型。苹果刚刚发布了MLX,一个在苹果芯片上高效运行机器学习模型的框架。
最近在PyTorch 1.12中引入MPS后端已经是一个大胆的步骤,但随着MLX的宣布,苹果还想在开源深度学习方面有更大的发展。

在本文中,我们将对这些新方法进行测试,在三种不同的Apple Silicon芯片和两个支持cuda的gpu上和传统CPU后端进行基准测试。
这里把基准测试集中在图卷积网络(GCN)模型上。这个模型主要由线性层组成,所以对于其他的模型也应该得到类似的结果。
创造环境
要为MLX构建环境,我们必须指定是使用i386还是arm架构。使用conda,可以使用:
CONDA_SUBDIR=osx-arm64 conda create -n mlx python=3.10 numpy pytorch scipy requests -c conda-forge
conda activate mlx如果检查你的env是否实际使用了arm,下面命令的输出应该是arm,而不是i386(因为我们用的Apple Silicon):
python -c "import platform; print(platform.processor())"然后就是使用pip安装MLX:
pip install mlxGCN模型
GCN模型是图神经网络(GNN)的一种,它使用邻接矩阵(表示图结构)和节点特征。它通过收集邻近节点的信息来计算节点嵌入。每个节点获得其邻居特征的平均值。这种平均是通过将节点特征与标准化邻接矩阵相乘来完成的,并根据节点度进行调整。为了学习这个过程,特征首先通过线性层投射到嵌入空间中。
我们将使用MLX实现一个GCN层和一个GCN模型:
import mlx.nn as nn
class GCNLayer(nn.Module):
def __init__(self, in_features, out_features, bias=True):
super(GCNLayer, self).__init__()
self.linear = nn.Linear(in_features, out_features, bias)
def __call__(self, x, adj):
x = self.linear(x)
return adj @ x
class GCN(nn.Module):
def __init__(self, x_dim, h_dim, out_dim, nb_layers=2, dropout=0.5, bias=True):
super(GCN, self).__init__()
layer_sizes = [x_dim] + [h_dim] * nb_layers + [out_dim]
self.gcn_layers = [
GCNLayer(in_dim, out_dim, bias)
for in_dim, out_dim in zip(layer_sizes[:-1], layer_sizes[1:])
]
self.dropout = nn.Dropout(p=dropout)
def __call__(self, x, adj):
for layer in self.gcn_layers[:-1]:
x = nn.relu(layer(x, adj))
x = self.dropout(x)
x = self.gcn_layers[-1](x, adj)
return x可以看到,mlx的模型开发方式与tf2基本一样,都是调用
__call__进行前向传播,其实torch也一样,只不过它自定义了一个forward函数。
下面就是训练
gcn = GCN(
x_dim=x.shape[-1],
h_dim=args.hidden_dim,
out_dim=args.nb_classes,
nb_layers=args.nb_layers,
dropout=args.dropout,
bias=args.bias,
)
mx.eval(gcn.parameters())
optimizer = optim.Adam(learning_rate=args.lr)
loss_and_grad_fn = nn.value_and_grad(gcn, forward_fn)
# Training loop
for epoch in range(args.epochs):
# Loss
(loss, y_hat), grads = loss_and_grad_fn(
gcn, x, adj, y, train_mask, args.weight_decay
)
optimizer.update(gcn, grads)
mx.eval(gcn.parameters(), optimizer.state)
# Validation
val_loss = loss_fn(y_hat[val_mask], y[val_mask])
val_acc = eval_fn(y_hat[val_mask], y[val_mask])在MLX中,计算是惰性的,这意味着eval()通常用于在更新后实际计算新的模型参数。而另一个关键函数是nn.value_and_grad(),它生成一个计算参数损失的函数。第一个参数是保存当前参数的模型,第二个参数是用于前向传递和损失计算的可调用函数。它返回的函数接受与forward函数相同的参数(在本例中为forward_fn)。我们可以这样定义这个函数:
def forward_fn(gcn, x, adj, y, train_mask, weight_decay):
y_hat = gcn(x, adj)
loss = loss_fn(y_hat[train_mask], y[train_mask], weight_decay, gcn.parameters())
return loss, y_hat它仅仅包括计算前向传递和计算损失。Loss_fn()和eval_fn()定义如下:
def loss_fn(y_hat, y, weight_decay=0.0, parameters=None):
l = mx.mean(nn.losses.cross_entropy(y_hat, y))
if weight_decay != 0.0:
assert parameters != None, "Model parameters missing for L2 reg."
l2_reg = sum(mx.sum(p[1] ** 2) for p in tree_flatten(parameters)).sqrt()
return l + weight_decay * l2_reg
return l
def eval_fn(x, y):
return mx.mean(mx.argmax(x, axis=1) == y)损失函数是计算预测和标签之间的交叉熵,并包括L2正则化。由于L2正则化还不是内置特性,需要手动实现。
本文的完整代码:https://github.com/TristanBil...
可以看到除了一些细节函数调用的差别,基本的训练流程与pytorch和tf都很类似,但是这里的一个很好的事情是消除了显式地将对象分配给特定设备的需要,就像我们在PyTorch中经常使用.cuda()和.to(device)那样。这是因为苹果硅芯片的统一内存架构,所有变量共存于同一空间,也就是说消除了CPU和GPU之间缓慢的数据传输,这样也可以保证不会再出现与设备不匹配相关的烦人的运行时错误。
基准测试
我们将使用MLX与MPS, CPU和GPU设备进行比较。我们的测试平台是一个2层GCN模型,应用于Cora数据集,其中包括2708个节点和5429条边。
对于MLX, MPS和CPU测试,我们对M1 Pro, M2 Ultra和M3 Max进行基准测试。在两款NVIDIA V100 PCIe和V100 NVLINK上进行测试
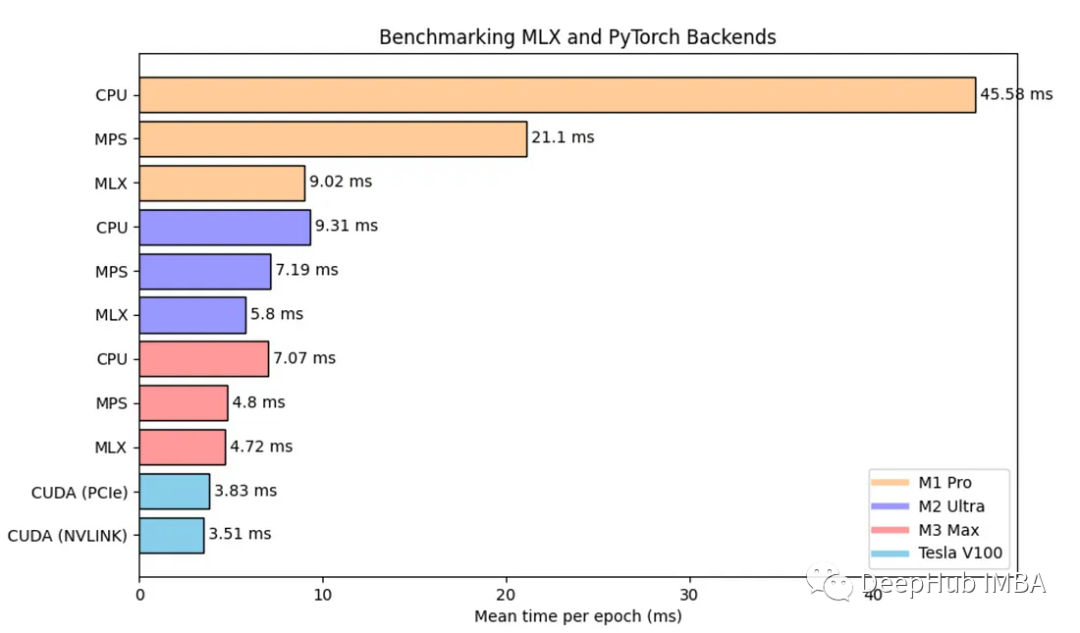
MPS:比M1 Pro的CPU快2倍以上,在其他两个芯片上,与CPU相比有30-50%的改进。
MLX:比M1 Pro上的MPS快2.34倍。与MPS相比,M2 Ultra的性能提高了24%。在M3 Pro上MPS和MLX之间没有真正的改进。
CUDA V100 PCIe & NVLINK:只有23%和34%的速度比M3 Max与MLX,这里的原因可能是因为我们的模型比较小,所以发挥不出V100和NVLINK的优势(NVLINK主要GPU之间的数据传输大的情况下会有提高)。这也说明了苹果的统一内存架构的确可以消除CPU和GPU之间缓慢的数据传输。
总结
与CPU和MPS相比,MLX可以说是非常大的进步,在小数据量的情况下它甚至接近特斯拉V100的性能。也就是说我们可以使用MLX跑一些不是那么大的模型,比如一些表格数据。
从上面的基准测试也可以看到,现在可以利用苹果芯片的全部力量在本地运行深度学习模型(我一直认为MPS还没发挥苹果的优势,这回MPS已经证明了这一点)。
MLX刚刚发布就已经取得了惊人的影响力,并展示了巨大的潜力。相信未来几年开源社区的进一步增强,可以期待在不久的将来更强大的苹果芯片,将MLX的性能提升到一个全新的水平。
另外也说明了MPS(虽然也发布不久)还是有巨大的发展空间的,毕竟切换框架是一件很麻烦的事情,如果MPS能达到MLX 80%或者90%的速度,我想不会有人去换框架的。
最后说到框架,现在已经有了Pytorch,TF,JAX,现在又多了一个MLX。各种设备、各种后端包括:TPU(pytorch使用的XLA),CUDA,ROCM,现在又多了一个MPS。
https://avoid.overfit.cn/post/eb87d12f29eb4665adb43ad59fd3d64f

