
RAG:AI大模型联合向量数据库和 Llama-index,助力检索增强生成技术
在大模型爆发的时代,快速准确地从大量数据中检索出有价值的信息变得至关重要。检索增强生成(RAG)技术,结合了传统的信息检索和最新的大语言模型(LLM),不仅能够回答复杂的查询,还能在此基础上生成信息丰富的内容。
RAG 技术的核心在于其能够将大型语言模型的生成能力与特定数据源的检索相结合。这意味着,当模型面对用户提出的问题时,它不仅依赖于自身训练时的知识,还可以实时地从外部数据源中检索相关信息,以此增强回答的准确性和丰富性。这种方法对于处理最新信息特别有效,能够有效弥补传统模型在时效性方面的不足。
这里我们将基于大模型、Milvus 向量数据库、LlamaIndex 大模型应用框架,与大家一起完成 RAG 系统的搭建。本文将以 Yuan2.0 最新发布的 Februa 模型为例进行测试验证,用更小规模的模型达到更好的效果。
1.RAG 系统架构
RAG(检索增强生成) 就是通过检索获取相关的知识并将其融入 Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将 RAG 的核心理解为 “检索 + 生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和 Prompt 工程,将召回的知识合理利用,生成目标答案。
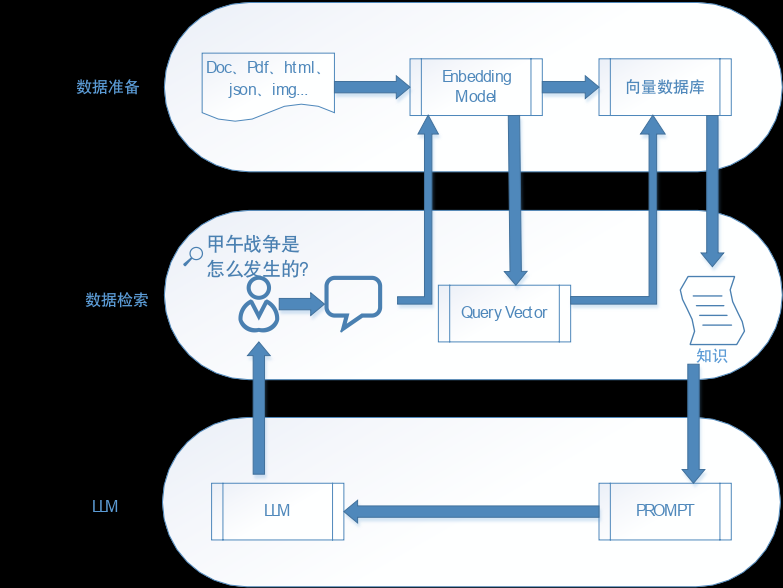
从 RAG 系统的运行流程我们可以看到,整个 RAG 系统可以分解为三个核心部件:
向量数据库:用来存放向量化之后的知识库,并提供向量检索能力,为 RAG 系统实现对知识的初步检索。这里我们采用 Milvus 向量数据库来实现知识的存储和初筛。它通常被用来存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。作为一个专门设计用于处理输入向量查询的数据库,Milvus 能够处理万亿级别的向量索引。与现有的关系型数据库主要处理遵循预定义模式的结构化数据不同,Milvus 从底层设计用于处理从非结构化数据转换而来的嵌入向量。
语言大模型(LLM):用来实现基于检索到的知识的推理和答案生成。这里我们将采用浪潮最新发布的 Yuan2.0 大模型来实现答案生成。从官方公布的资料来看,Yuan2.0 是在 Yuan1.0 的基础上,利用更多样的高质量预训练数据和指令微调数据集,令模型在语义、数学、推理、代码、知识等不同方面具备更强的理解能力。Yuan2.0 包含了 2B、51B、102B 不同参数量的系列模型。根据官方公布的资料显示,今年 3 月最新发布的 Yuan2-2B-Februa 在数学推理、代码生成等任务上的精度均取得了明显提升。为了部署方便,我们将采用 Yuan2-2B-Februa 来构建 RAG 系统的 LLM 模块。关于 Yuan2.0 模型的详细介绍请参考:Yuan2.0 Github问答推理框架:问答推理框架主要用来实现 RAG 系统的问答逻辑。它接收用户的提问输入,并根据输入向向量数据库发起索引请求,将得到的索引结果与问题结合,形成新的提示词(prompt),并将提示词提交给 LLM,最后将 LLM 生成的结果返回给用户。这里我们将采用 LlamaIndex 工具来实现这个框架。其主要由 3 部分组成:- 数据连接。首先将数据能读取进来,这样才能挖掘。
- 索引构建。要查询外部数据,就必须先构建可以查询的索引,LlamdaIndex 将数据存储在 Node 中,并基于 Node 构建索引。索引类型包括向量索引、列表索引、树形索引等;
- 查询接口。通过这些接口用户可以先基于索引进行检索,再将检索结果和之前的输入 Prompt 进行组合形成新的扩充 Prompt,对话大模型并拿到结果进行解析。
2.部署教程
2.1 流程图
以 Yuan2-2B-Februa 大模型为例,RAG 实践流程图如下所示:
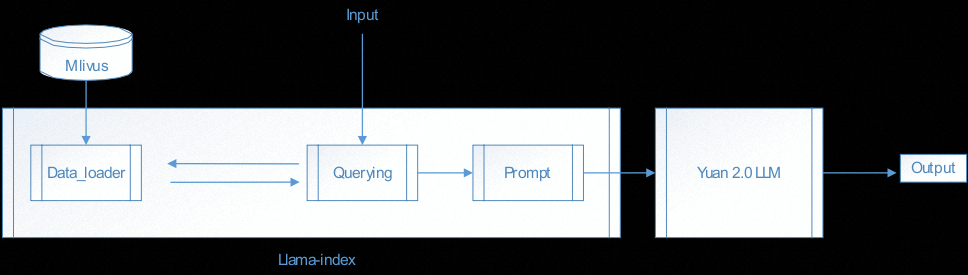
Yuan2.0-2B 大模型 RAG 实践包括以下步骤:
- Step 1: 向量数据库的安装,以及知识的填充;详细安装过程参见后续章节;
- Step 2:Llama_index 的安装;详细安装过程参见后续章节;
- Step 3:Llama_index 中设置 data_loader 模块,可以直接从向量数据库中查询;
- Step 4:根据用户输入进行向量检索,将检索结果与 Input 合并,形成新的 prompt;
- Step 5:加载 Yuan2.0-2B 大模型;合并后的 prompt 作为输入,传递给大模型,大模型将结果输出返回;
2.2 向量数据库安装以及知识填充
向量数据库安装步骤如下:
#Create Milvus file
mkdir -p /home/$USER/milvus/conf
cd /home/$USER/milvus/conf
wget https://raw.githubusercontent.com/milvus-io/milvus/v0.8.0/core/conf/demo/server_config.yaml
wget https://raw.githubusercontent.com/milvus-io/milvus/v0.8.0/core/conf/demo/log_config.conf
#Start Milvus
docker run -d --name milvus_cpu \
-p 19530:19530 \
-p 19121:19121 \
-p 9091:9091 \
-v /home/$USER/milvus/db:/var/lib/milvus/db \
-v /home/$USER/milvus/conf:/var/lib/milvus/conf \
-v /home/$USER/milvus/logs:/var/lib/milvus/logs \
-v /home/$USER/milvus/wal:/var/lib/milvus/wal \
milvusdb/milvus:0.8.0-cpu-d041520-464400- 这里我们以 txt 文本为例,演示如何将知识库导入到数据库中。在任意目录下新建一个 python 脚本 milvus.py,输入以下代码:
from pymilvus import (
connections,
utility,
FieldSchema, CollectionSchema, DataType,
Collection,
)
from llama_index.embeddings import HuggingFaceEmbedding
fmt = "\n=== {:30} ===\n"
#1. connect to Milvus
print(fmt.format("start connecting to Milvus"))
connections.connect("default", host="localhost", port="19530")
#2. define collection
fields = [
FieldSchema("pk", DataType.INT64, is_primary=True, auto_id=True),
FieldSchema("vector", DataType.FLOAT_VECTOR, dim=768),]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")
print(fmt.format("Create collection `hello_milvus`"))
hello_milvus = Collection("hello_milvus", schema, consistency_level="Strong")
#3. insert data
chunk_list = []
print("Creat embedding model...")
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5",trust_remote_code=True)
with open('knowledge.txt', 'r') as file:
line = file.readline()
while line:
# Generate embeddings using encoder from HuggingFace.
embeddings = embed_model.get_text_embedding(line)
chunk_list.append(embeddings)
line = file.readline()
insert_result = hello_milvus.insert(chunk_list)
hello_milvus.flush()
#create index
index = {
"index_type": "AUTOINDEX",
"metric_type": "COSINE",
}
hello_milvus.create_index("vector", index)
上述代码首先导入 python 连接 milvus 所需的库,然后通过 connections.connect("default", host="localhost", port="19530") 指定使用本地的 19530 端口建立数据库连接。其中 knowledge.txt 就是我们的知识库内容,这个文件放在与 milvus.py 脚本相同的目录下。如果用户的知识库在其他路径存放,修改 with open('knowledge.txt', 'r') 中的路径即可。
knowledge.txt 的初始样例中每行代表一条知识。其中一条数据样例如下,稍后将基于这条知识进行实验验证。
广州大学(Guangzhou University),简称广大(GU),是由广东省广州市人民政府举办的全日制普通高等学校,实行省市共建、以市为主的办学体制,是国家“111计划”建设高校、广东省和广州市高水平大学重点建设高校。广州大学的办学历史可以追溯到1927年创办的私立广州大学;1951年并入华南联合大学;1983年筹备复办,1984年定名为广州大学;2000年7月,经教育部批准,与广州教育学院(1953年创办)、广州师范学院(1958年创办)、华南建设学院西院(1984年创办)、广州高等师范专科学校(1985年创办)合并组建成立新的广州大学。
2.3 Llama_index 安装以及设置安装 Llama-index1
##在线安装
pip install llama-index设置 data_loader 加载,从 Milvus 中获取知识, 具体源码可参考 yuan.py 文件。
from llama_index import download_loader
import os
MilvusReader = download_loader("MilvusReader")
reader = MilvusReader(
host="localhost", port=19530, user="<user>", password="<password>", use_secure=False
)
#the query_vector is an embedding representation of your query_vector
#Example query vector:
#query_vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]
query_vector=[n1, n2, n3, ...]
documents = reader.load_data(
query_vector=query_vector,
collection_name="demo",
limit=5
)2.4 Prompt 合并
text_qa_template=PromptTemplate(
("背景:{context_str}"
"问题: {query_str}\n")
)说明:
- context_str 是知识库中查询到的结果;
- query_str 为用户输入的问题;
具体情况如下:1
在本实例中,
query_str具体内容是:介绍一下广州大学
context_str具体内容是:file_path: data\***.txt
广州大学(Guangzhou University),简称广大(GU),是由广东省广州市人民政府举办的全日制普通高等学校,实行省市共建、以市为主的办学体制,是国家“111计划”建设高校、广东省和广州市高水平大学重点建设高校。广州大学的办学历史可以追溯到1927年创办的私立广州大学;1951年并入华南联合大学;1983年筹备复办,1984年定名为广州大学;2000年7月,经教育部批准,与广州教育学院(1953年创办)、广州师范学院(1958年创办)、华南建设学院西院(1984年创办)、广州高等师范专科学校(1985年创办)合并组建成立新的广州大学。
3.5 Yuan 大模型下载以及推理试用安装
Yuan2.0 模型是浪潮信息发布的新一代基础语言大模型。我们开源了全部的 3 个模型:Yuan2.0-102B、Yuan2.0-51B、Yuan2.0-2B。提供预训练、微调、推理服务的相关脚本,以供研发人员做进一步开发。Yuan2.0 是在 Yuan1.0 的基础上,利用更多样的高质量预训练数据和指令微调数据集,令模型在语义、数学、推理、代码、知识等不同方面具备更强的理解能力。
提供了 Yuan2.0 的模型文件,可以通过以下链接进行下载:
Yuan2.0-102B-hf | 序列长度:4K
- ModelScope:https://modelscope.cn/models/YuanLLM/Yuan2.0-102B-hf/summary
- HuggingFace:https://huggingface.co/IEITYuan/Yuan2-102B-hf
- OpenXlab:https://openxlab.org.cn/models/detail/YuanLLM/Yuan2-102B-hf
- 百度网盘:https://pan.baidu.com/s/1O4GkPSTPu5nwHk4v9byt7A?pwd=pq74
- WiseModel:https://www.wisemodel.cn/models/IEIT-Yuan/Yuan2-102B-hf
Yuan 2.0-51B-hf | 序列长度:4K
- ModelScopehttps://modelscope.cn/models/YuanLLM/Yuan2.0-51B-hf/summary* HuggingFacehttps://huggingface.co/IEITYuan/Yuan2.0-51B-hf
- OpenXlabhttps://openxlab.org.cn/models/detail/YuanLLM/Yuan2-51B-hf
- 百度网盘https://pan.baidu.com/s/1-qw30ZuyrMfraFtkLgDg0A?pwd=v2nd
- WiseModelhttps://www.wisemodel.cn/models/IEIT-Yuan/Yuan2-51B-hf
更多内容见:https://modelscope.cn/headlin...
运行以下代码可以进行简单的推理效果试用:
import torch, transformers
import sys, os
sys.path.append(
os.path.abspath(os.path.join(os.path.dirname(__file__), os.path.pardir)))
from transformers import AutoModelForCausalLM,AutoTokenizer,LlamaTokenizer
print("Creat tokenizer...")
tokenizer = LlamaTokenizer.from_pretrained('IEITYuan/Yuan2-2B-Februa-hf', add_eos_token=False, add_bos_token=False, eos_token='<eod>')
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Creat model...")
model = AutoModelForCausalLM.from_pretrained('IEITYuan/Yuan2-2B-Februa-hf', device_map='auto', torch_dtype=torch.bfloat16, trust_remote_code=True)
inputs = tokenizer("请问目前最先进的机器学习算法有哪些?", return_tensors="pt")["input_ids"].to("cuda:0")
outputs = model.generate(inputs,do_sample=False,max_length=100)
print(tokenizer.decode(outputs[0]))3.案例测试
利用 Yuan2.0 大模型,联合向量数据和 Llama_index,对比用户同一个问题的输出结果,验证方案的可行性。
用户输入问题:"介绍一下广州大学",使用检索增强生成技术之前的模型回答效果,该结果可以直接使用 Yuan2-2B-Februa 模型进行推理复现:
广州大学是一所位于中国广东省广州市的本科高校,创建于1980年。学校以“南国情怀、卓越创新”为校训,是一所以工科为主,工学、理学、管理学、法学、文学、教育学等学科门类齐全的综合性大学。目前设有14个学院和26个研究院所,拥有全日制本科生近3.5万名,硕士、博士研究生超过7万人。校园环境优美,设施完善,是全国文明单位和国家绿化先进集体。
使用检索增强生成技术之后的模型回答效果,运行完整代码,可以复现该结果:
广州大学是一所位于中国广东省广州市的综合性大学,是广东省重点建设高校之一,也是国家“111计划”建设的高校之一。它于1927年由原国立广东法商学院在广州创立,是中国第一所独立设立的现代高等教育机构之一。学校的前身是成立于1927年的广州大学公学,发展至今已成为一所具有悠久历史的研究型大学。学校占地约1880亩,拥有现代化的教学楼、实验楼和图书馆等设施,同时注重学生的全面发展和社会实践能力培养。
对比发现:添加知识库之后,大模型的回答学到了 “国家“111 计划” 建设的高校“的新知识。
4.总结
利用 Yuan 大模型、向量数据库和 LlamaIndex 助力大模型检索增强生成技术,为 NLP 领域开辟了一个可能性领域。这个管道不仅可以理解和生成文本,而且还利用庞大的信息数据库来增强其响应,使其在聊天机器人、推荐系统等各种应用程序中具有难以置信的强大功能。
然而,旅程并没有就此结束。NLP 的世界正在迅速发展,保持最新趋势和技术的更新至关重要。这里讨论的实现是进入更广泛、更复杂的语言理解和生成世界的垫脚石。不断试验,不断学习,最重要的是不断创新。
5. 附完整代码
完整代码文件 yuan.py 内容如下:
from llama_index import download_loader
import logging
import sys
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from llama_index.embeddings import HuggingFaceEmbedding
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms import HuggingFaceLLM
from llama_index.prompts import PromptTemplate
query = "介绍一下广州大学"
yuan_path = "/workspace/yuan_2/Yuan2-2B-Februa-hf"
print("Yuan2-2B-Februa Creat tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(yuan_path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Yuan2-2B-Februa Creat model...")
model = AutoModelForCausalLM.from_pretrained(yuan_path, torch_dtype=torch.bfloat16, trust_remote_code=True)
device_map = torch.cuda.current_device() if torch.cuda.is_available() else torch.device('cpu')
model = model.to(device_map)
# model = model.to("cpu")
llm = HuggingFaceLLM(
# context_window=2048,
max_new_tokens=1024,
generate_kwargs={"temperature": 0.25, "do_sample": False, "repetition_penalty": 1.2, "max_length": 2048},
# query_wrapper_prompt=query_wrapper_prompt,
tokenizer=tokenizer,
model=model,
# tokenizer_name=yuan_path,
# model_name=yuan_path,
device_map="auto",
# tokenizer_kwargs={"max_length": 2048},
# uncomment this if using CUDA to reduce memory usage
model_kwargs={"torch_dtype": torch.float16, "trust_remote_code":True}
)
print("Creat embedding model...")
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5",trust_remote_code=True)
# load documents
MilvusReader = download_loader("MilvusReader")
reader = MilvusReader(
host="localhost", port=19530, user="<user>", password="<password>", use_secure=False
)
# Example query vector:
documents = reader.load_data(
query_vector=embed_model.get_text_embedding(query),
collection_name="demo",
limit=5
)
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
# define prompts that are used in llama-index, {query_str} is user's question,{context_str} is content queried by milvus
query_engine = index.as_query_engine(**{"text_qa_template":PromptTemplate(
("背景:{context_str}"
"问题: {query_str}\n")
)})
response = query_engine.query(query)
print(response)更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

