
嵌入模型是大型语言模型检索增强生成(RAG)的关键组成部分。它们对知识库和用户编写的查询进行编码。
使用与LLM相同领域的训练或微调的嵌入模型可以显著改进RAG系统。然而,寻找或训练这样的嵌入模型往往是一项困难的任务,因为领域内的数据通常是稀缺的。
但是这篇论文LLM2Vec,可以将任何的LLM转换为文本嵌入模型,这样我们就可以直接使用现有的大语言模型的信息进行RAG了。

嵌入模型和生成模型
嵌入模型主要用于将文本数据转换为数值形式的向量表示,这些向量能够捕捉单词、短语或整个文档的语义信息。这些向量表示也被称为嵌入(embeddings),可以用于各种下游任务,如文本分类、搜索、相似度计算等。
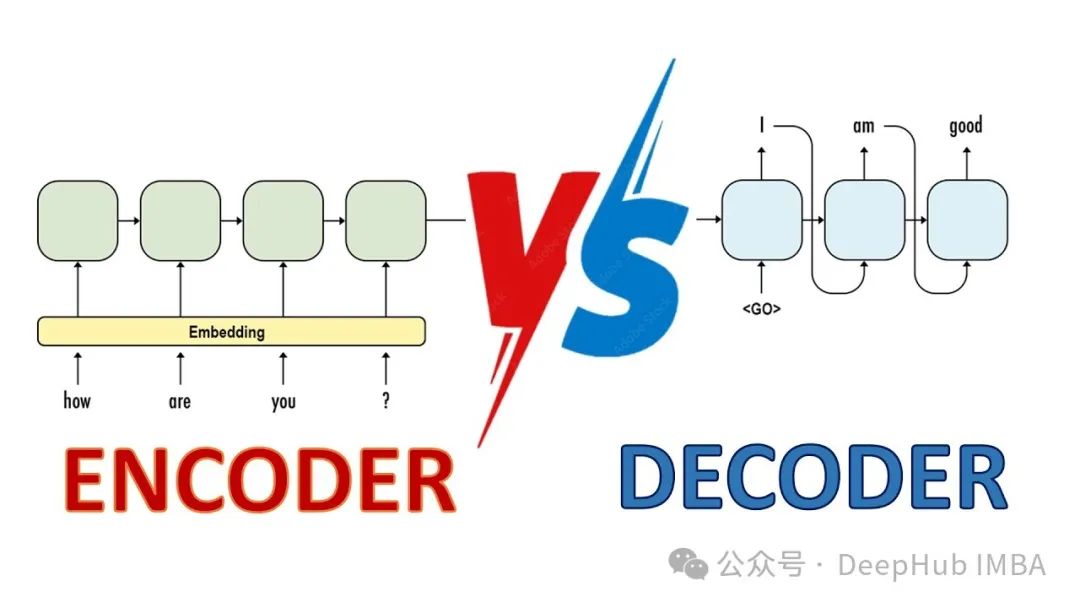
最有名的嵌入模型就是BERT是一个典型的encoder-only模型
生成模型则设计用来基于训练数据生成新的数据实例。在NLP中,这通常意味着生成文本。这类模型能够学习到数据的分布,并能创造出符合这一分布的新实例,如新的句子或文档。
如GPT系列,通常是decoder-only模型。
这两种架构在设计和应用上有所不同:
- BERT (Encoder-only):BERT利用双向Transformer编码器,这意味着它在处理文本时可以同时考虑前面和后面的上下文。这种双向上下文理解使得BERT非常适合用于各种理解任务,如问答、自然语言推理和实体识别等。
- LLM (Decoder-only):如GPT系列模型,通常采用单向Transformer解码器。这意味着在生成文本时,每个新词只能基于前面的词生成。这种结构适合于文本生成任务,如文本续写、自动编写程序代码等。
在论文中对encoder-only和decoder-only模型的特点进行了讨论,特别是在解释为什么将decoder-only的大型语言模型(LLM)转换为有效的文本编码器时。论文指出了几个关键点:
- Decoder-only模型的局限性:这些模型,如GPT系列,使用因果(单向)注意力机制。这意味着在生成文本时,每个标记只能看到它之前的标记。这种结构虽然适合文本生成,但在需要丰富的上下文信息(如文本嵌入任务)时可能不够理想。
- 克服Decoder-only模型的限制:论文中提出的LLM2Vec方法特别通过几个步骤来克服这些限制,包括启用双向注意力,这使得模型能够在处理文本时同时考虑前后文本,从而生成更丰富的上下文表示。
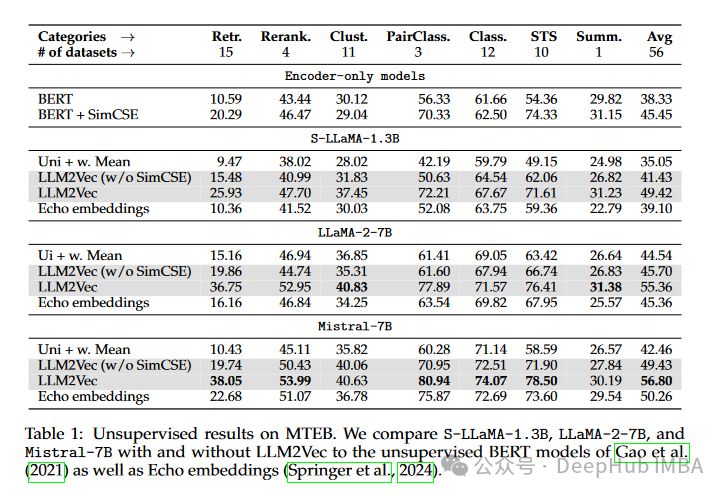
- 与Encoder-only模型的对比:论文比较了使用LLM2Vec转换的decoder-only模型与传统的encoder-only模型(如BERT)。结果显示,通过适当的转换和训练,原本设计为decoder-only的模型在多个文本嵌入任务上能够达到甚至超过传统encoder-only模型的性能。
这表明,尽管decoder-only和encoder-only模型在设计和功能上有本质的不同,但通过创新的方法可以扩展或改变这些模型的能力,使它们适应更广泛的应用场景。
其实我们可以将这篇论文的重点简单的理解为,如何将一个decoder-only的模型快速并且无损的转换成一个encoder-only模型。
LLM2Vec
在论文中提出了一种名为LLM2Vec的方法,用于将仅解码器的大型语言模型(LLM)转换为强大的文本编码器。这种方法包括三个简单的步骤:1)启用双向注意力;2)蒙版下一个标记预测;3)无监督对比学习。这种转换不需要标记数据,且在数据和参数上都非常高效。

具体来说,研究中首先解决了LLM在文本嵌入任务中由于其因果关注机制而受限的问题,该机制仅允许标记与其前面的标记交互。通过启用双向注意力,每个标记能够访问序列中的所有其他标记,从而转换为双向LLM。然后,通过蒙版下一个标记预测(MNTP),调整模型以利用其双向注意力。最后,应用无监督对比学习以改进序列表示。
这些步骤的组合不仅在单词级任务上提升了模型的性能,还在大规模文本嵌入基准(MTEB)上达到了新的无监督性能水平。此外,当将LLM2Vec与监督对比学习相结合时,还在仅使用公开可用数据的模型中实现了最先进的性能。这表明,通过这种简单且有效的方法,原本仅用于生成任务的解码器模型也能被转化为通用的文本编码器,从而在多种NLP任务中表现出色。
方法详解
论文中描述的LLM2Vec方法在代码层面主要涉及以下几个关键的修改,以将decoder-only模型转换为能够生成丰富文本编码的模型:
- 启用双向注意力:通常,decoder-only模型使用的是单向(因果)注意力机制,这限制了模型只能看到当前标记之前的信息。为了转换这一点,论文中提到通过替换因果注意力掩码(causal attention mask)为全1矩阵,使得每个标记都能看到序列中的所有其他标记,从而实现双向注意力。
- 蒙版下一个标记预测(MNTP):这是一个训练目标,结合了下一个标记预测和蒙版语言模型的元素。具体来说,首先在输入序列中随机蒙版一些标记,然后训练模型预测这些蒙版的标记,同时考虑前后文。这种训练方式帮助模型适应其新的双向注意力能力。
- 无监督对比学习:使用SimCSE(Simple Contrastive Learning of Sentence Embeddings)方法,这种方法通过对同一句子生成两个不同的嵌入表示,并训练模型最大化这两个表示之间的相似度,同时最小化与批次中其他不相关句子表示的相似度。这一步骤不需要配对数据,可以使用任何文本集合。
这些代码修改主要集中在模型的预训练和微调阶段,旨在不仅使模型能够处理更丰富的上下文信息,还提高了模型在不同NLP任务中的通用性和有效性,也就是说我们最终还是需要进行微调训练的,所以下面我们就要展示一些代码来看看如何进行这部分的微调训练。
利用LLM2Vec将Llama 3转化为文本嵌入模型
首先我们安装依赖
pip install llm2vec
pip install flash-attn --no-build-isolation我们这里演示使用单卡的4090,对于现有模型,我们直接加载现有的模型:
import torch
from llm2vec import LLM2Vec
l2v = LLM2Vec.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
device_map="cuda" if torch.cuda.is_available() else "cpu",
torch_dtype=torch.bfloat16,
)
l2v.save("Llama-3-8B-Emb")“torch_dtype=torch.bfloat16”是能够在24 GB GPU上运行转换所必需的配置。如果不设置它,模型将是float32参数的原始大小,内存是不够的。
这时,其实这个模型已经可以使用了。但是如果其插入到RAG中。它的性能是不如标准嵌入模型,因为他的运行方式还是因果推断,而不是我们的嵌入。
所以下一步,就需要用MNTP的目标来训练羊驼他。论文的作者还提供了一个脚本:
experiments/run_mntp.py
它目前支持Llama和Mistral架构的模型,所以我们直接可以拿来使用
git clone https://github.com/McGill-NLP/llm2vec.git这个脚本需要一个参数,它是JSON格式的配置文件。他们在这里提出了几个例子:
train_configs / mntp
对于Llama 3 8b,配置可以是这样的:
JSON_CONFIG='''
{
"model_name_or_path": "meta-llama/Meta-Llama-3-8B",
"dataset_name": "wikitext",
"dataset_config_name": "wikitext-103-raw-v1",
"per_device_train_batch_size": 1,
"per_device_eval_batch_size": 1,
"gradient_accumulation_steps": 16,
"do_train": true,
"do_eval": true,
"max_seq_length": 512,
"mask_token_type": "blank",
"data_collator_type": "all_mask",
"mlm_probability": 0.8,
"overwrite_output_dir": true,
"output_dir": "Llama-3-8B-llm2vec-MNTP-Emb",
"evaluation_strategy": "steps",
"eval_steps": 100,
"save_steps": 200,
"stop_after_n_steps": 1000,
"lora_r": 16,
"gradient_checkpointing": true,
"torch_dtype": "bfloat16",
"attn_implementation": "flash_attention_2"
}
'''
with open("mntp_config.json", 'w') as f:
f.write(JSON_CONFIG)该脚本使用bfloat16参数加载模型。将每个设备的批处理大小设置为1,这样可以适合24 GB的GPU。
然后可以开始MNTP训练:
python llm2vec/experiments/run_mntp.py mntp_config.json使用24gb的4090,或者Google Colab的L4,这需要4天的时间。但是经过MNTP训练后,模型应该会产生更好的结果,特别是对于检索任务。
论文中提到的最后一步是SimCSE,但是作者还没有发布他们的代码,但提到他们会发布的。所以我们直接可以那这个模型来进行测试
使用Llama 3文本嵌入模型
对于训练完成的模型,我们可以直接使用SentenceTransformer加载
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Llama-3-8B-llm2vec-Emb")使用LlamaIndex的话可以直接设置
Settings.embed_model = HuggingFaceEmbedding(model_name="Llama-3-8B-llm2vec-Emb", device='cpu')这里设置device= ' cpu '使用cpu加载,这会使RAG系统变慢。可以删除此参数以在GPU上运行它。但是模型是以全精度加载的,所以我们将其加载到CPU上进行测试。因为llm2vec是刚刚发布的,所以还没有任何的量化教程,希望后续会有发布,这样就可以在我们的GPU上完全的使用了。
总结
通过LLM2Vec,我们可以使用LLM作为文本嵌入模型。但是简单地从llm中提取的嵌入模型往往表现不如常规嵌入模型。LLM2Vec的作者提出了新的训练目标MNTP和SimCSE来训练从llm中提取的嵌入模型。这种训练成本很高,但根据作者的说法,可以产生更好的嵌入模型。
论文地址:
https://avoid.overfit.cn/post/67a62b9532b247cc9db87663ce547ff2

