
在基于transformer的自回归语言模型(LMs)中,生成令牌的成本很高,这是因为自注意力机制需要关注所有之前的令牌,通常通过在自回归解码过程中缓存所有令牌的键值(KV)状态来解决这个问题。但是,加载所有先前令牌的KV状态以计算自注意力分数则占据了LMs的推理的大部分成本。
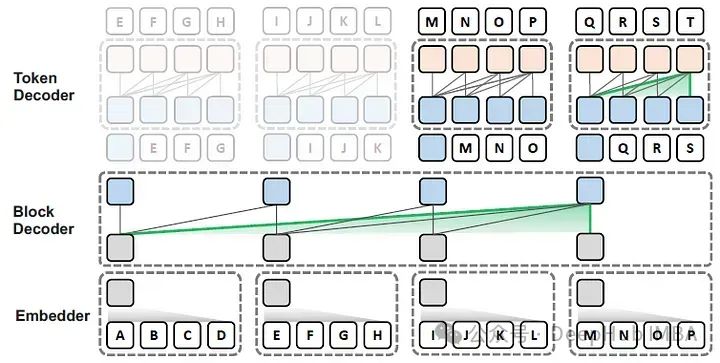
在这篇论文中,作者提出了Block Transformer架构,该架构通过在较低层次之间的粗糙块(每个块代表多个令牌)的自注意力来模拟全局依赖性,并在较高层次的每个局部块内解码细粒度的令牌,如下图所示。
论文的主要贡献包括:
- 发现了在自回归变换器中,全局和局部建模在推理时的核心作用和好处,特别是局部模块的重要性。
- 利用这些见解可以优化架构中的推理吞吐量,与普通transformers相比,显著提高了性能与吞吐量
Block Transformer
Block Transformer包括三个组成部分:
- 嵌入器:嵌入器将每个LB令牌的块聚合成一个输入块嵌入。
- 块解码器:块解码器对整个块序列应用自注意力以模拟全局依赖关系。
- 令牌解码器:令牌解码器在每个块内应用自注意力以处理细粒度的局部依赖性并解码个别令牌。
为什么Block Transformer高效?
- 全局到局部的方法可以通过将全局建模的昂贵瓶颈隔离到较低层并在上层的独立块内进行局部建模,这样可以减轻检索先前KV缓存的延迟和内存开销。
- 粗粒度的全局建模(块级解码)通过块长度因子缓解了KV缓存的瓶颈,同时保持了考虑完整上下文的能力。局部解码几乎没有预填充的成本,并且几乎消除了KV缓存开销,因此在推理硬件上的利用率中受益。
- 令牌解码器可以用更多的FLOPs进行细粒度的语言建模,对推理吞吐量的影响最小。
- 虽然block transformer需要比普通transformer更多的参数以保持可比的性能,但实际的吞吐量瓶颈是KV缓存开销,并且仍然可以实现更高的速度提升。
嵌入器 Embedder
嵌入器优先考虑简单性,主要处理小块长度(2-8),使用查找表Eemb∈RV×Demb来检索和连接可训练的令牌嵌入,其中令牌嵌入维度Demb设置为D/LB,D是整个网络中使用的块表示维度。
块解码器 Block decoder
块解码器的目标是通过关注前面的块来使块表示具有上下文性,利用嵌入器的输出作为输入。这种自回归transformer在块级别操作,产生输出块嵌入(也称为上下文嵌入),使得令牌解码器能够自回归地解码后续块的令牌内容。从嵌入器得到的输入块嵌入,源自输入令牌x0:(i×LB−1),块解码器输出一个上下文嵌入,包含预测x(i×LB):((i+1)×LB−1)所需的信息。这种方法通过使用粗粒度块输入而不是单个令牌,减轻了自注意力的二次成本,从而减少了给定序列的上下文长度,同时保持了全局建模能力和硬件加速密集注意力的便利性。
令牌解码器 Token decoder
令牌解码器使用来自上下文块嵌入的全局上下文信息局部解码下一个块的个别令牌。令牌解码器也是一个标准的自回归transformer,具有自己的嵌入表Etok∈RV×Dtok和分类器。令牌解码器消除了预填充(仅在块解码器中必需),因为上下文信息由输出块嵌入提供,因此称之为上下文嵌入。KV缓存IO,批量解码期间的一个主要瓶颈,几乎被消除。与普通transformer相比,因为与完整上下文长度的成本是线性的,而普通注意力的KV缓存IO与完整上下文长度是二次的,因此计算单元的利用率更高。
实验结果
下表显示了普通transformer和块transformer模型之间的性能比较。
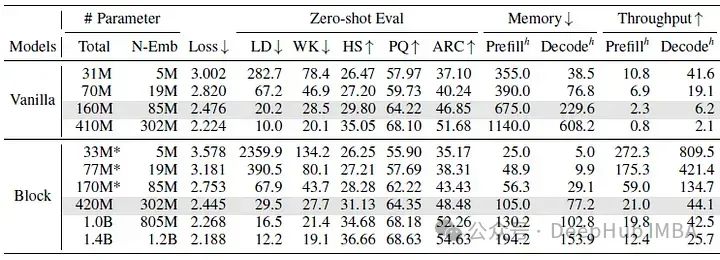
当块transformer模型的参数是普通模型的两到三倍时,在五个零样本评估任务上实现了可比的困惑度和准确度。而下图显示了吞吐量到语言建模性能的前沿。吞吐量表示每秒生成的令牌数量,每个点旁边的数字代表非嵌入参数的数量。
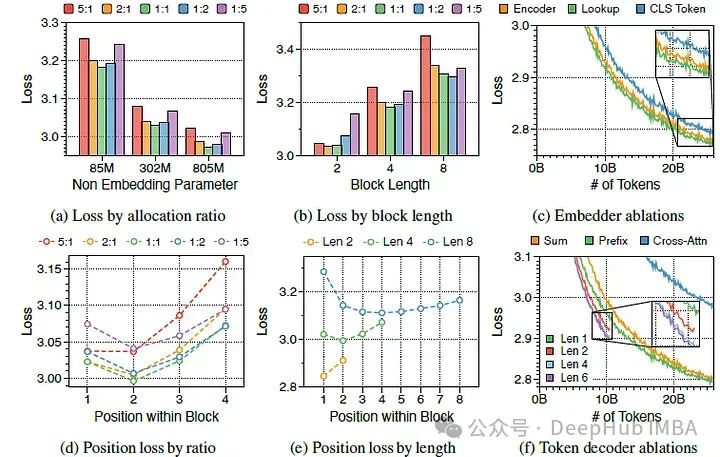
(左:(a),(d))参数分配比例之间的平均损失和位置损失。该比例表示为块解码器到令牌解码器的比例
(中:(b),(e))与块长度LB相关的平均损失和位置损失。
(右:(c),(f))嵌入器和令牌解码器变体的训练损失曲线 可以观察到,当块transformer的提示长度为8K时,其吞吐量超过了普通模型提示长度为2K的吞吐量。
所以这就是论文说的,虽然参数多了,但是吞吐量却提高了,下面我们详细分析参数分配比例和块长度:
a) 困惑度在不同分配比例中呈现U型模式
在上图(a)中展示了三种模型大小的五个不同比例的训练损失,并发现对于LB=4的模型,一对一的比例在所有模型大小中始终是最优的。如果任一侧太小,性能会明显下降,这证明了块解码器和令牌解码器在语言建模中的协同效应和同等重要性。
b) 更大的块解码器和令牌解码器分别在初始位置和后期位置降低困惑度
在上图(d)中测量了块内每个位置的平均损失。位置损失通常呈现U型模式,与以前的多尺度语言模型和块并行解码方法的发现一致。较大的块解码器由于仅基于上下文嵌入进行预测,显著降低了初始位置的损失。相比之下,较大的令牌解码器通过更好地利用局部上下文,提高了后期令牌的预测准确性。
c) 较短的块长度有利于较大的块解码器,而较长的块长度则更适合令牌解码器
上图(b)显示,训练损失仍然在不同分配比例中呈现U型模式,无论块长度如何。最佳比例随块长度变化:较短的块受益于较大的块解码器,而较长的块在令牌解码器中拥有更多参数时表现更好,这是由块解码器的FLOPs与块长度成反比关系导致的。
d) 较大的令牌解码器和较长的块长度有助于实现高吞吐量
从吞吐量的角度评估分配比例和块长度。配备较大令牌解码器的模型通过在轻微性能妥协下实现更高的吞吐量达到最优。增加块长度改善了吞吐量,因为块解码器中的KV缓存长度按比例减少。
全局到局部的语言建模分析:
1、全局到局部的语言建模有效优化了相对于性能的吞吐量
下图显示了不同块长度的训练损失曲线。括号中的数字代表最大吞吐量,以每秒1K令牌计算,分别用于预填充和解码的设置。
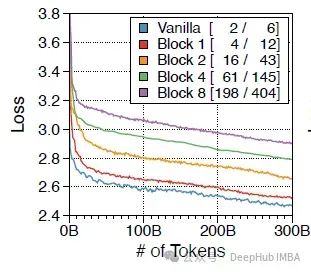
随着块长度的增加,训练损失以对数线性变化,吞吐量呈指数增长,清楚地展示了全局到局部建模的效率。
2、块transformer可以有效利用完整上下文
下图显示了PG19测试集上不同令牌位置的损失。平均每128个序列进行平滑。
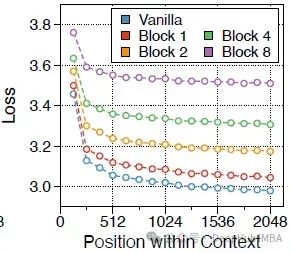
后期令牌的预测概率始终较高,表明论文的架构,区分了块级和令牌级解码器,有效地利用了至少2K令牌的上下文。
总结
Block Transformer架构突出了自回归变换器中全局到局部建模的推理时优势,实证发现表明全局和局部组件都扮演了至关重要的角色,对于全局和局部的理解不仅可以加速推理,可能还会对以后的架构改进产生新的方向。
论文地址:
https://avoid.overfit.cn/post/6867c4c1e9f24d3fb5fef2cd2ecfd989
作者:SACHIN KUMAR

