
MTCNN(Multi-task Cascaded Convolutional Networks,多任务级联卷积神经网络)
该模型利用多级联的结构,从粗到细预测人脸以及相应特征坐标位置,能够适用于各种自然条件下复杂的人脸场景检测,可以实现人脸检测和5个特征点的标定。主要包括三个网络子结构:P-Net(proposal networks)、R-Net(refine networks)、O-Net(output networks)。
模型流程
该算法模型流程包括四部分(图像金字塔、P-Net、R-Net、O-Net)
- 图像金字塔
为了检测到不同size的人脸,在进入P-Net之前,我们应该对图像进行金字塔操作。首先,根据设定的min_face_size尺寸,将img按照一定的尺寸缩小,每次将img缩小到前级img面积的一半,形成scales列表,直至边长小于min_face_size,此时得到不同尺寸的输入图像。
- P-Net(proposal network)
根据上述步骤得到的不同尺寸的图像,输入到P-Net网络中。如图所示为P-Net网络结构:
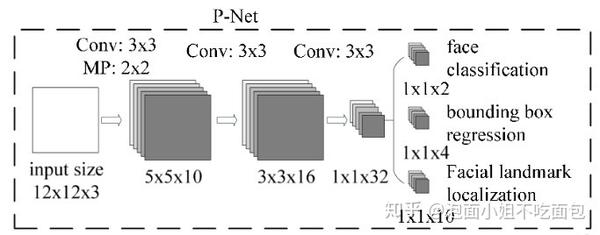
图1 P-Net网络结构示意图
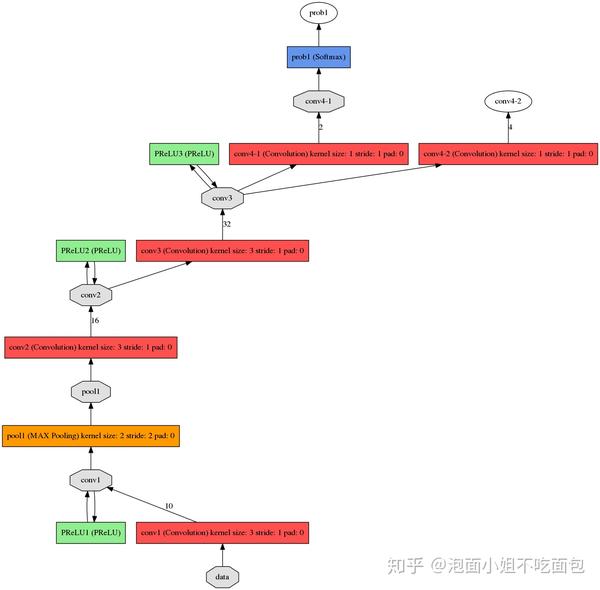
图2 P-Net网络结构详细示意图
由图1可知,该层网络anchor大小为12 12(可更改),代表12 12区域,经过P-Net全卷积层后,变成1(输入不同,则输出也不同。假设输出为w h,则输出的每个点都对应原img中一个12 12的区域)
a. 将不同尺寸的金字塔图像输入到p-net中,最终得到prob1与conv4-2。prob1中包含box位置信息及其置信度,conv4-2中包含box的回归系数信息。
b. 利用a中的prob1与conv4-2生成box,设置阈值为0.6(初筛,阈值应偏小),得到一系列点,影射回原img,以此点为左上角,向右向下各扩展12pixel,得到12 * 12的矩形框。
c. 接下来对一帧图像上检测到的所有12 * 12矩形框进行nms运算。
d. 最后得到的所有box会放置在一个number 9的数组里,number表示box的数量,9代表box的坐标信息、score、坐标回归信息[x1、y1、x2、y2、score、reg_x1_、_reg_y1、reg_x2、reg_y2],利用reg 系列(对应坐标的线性回归参数)可对box进行坐标修正,修正过程可表示为:
new_x1 = x1 + reg_x1 * width_of_box
new_y1 = y1 + reg_y1 * height_of_box
new_x2 = x2 + reg_x2 * width_of_box
new_y2 = y2 +e.目标框修正之后,先rec2square、再pad。rec2square是将修正后不规则的框调整为正方形,pad的目标是将超出原img范围的部分填充为0,大小比例不变。
注:上述过程可看成 12 * 12的anchor在不同尺寸的图像上按照stride=1滑动,根据face classification结果判定是否为人脸,小于-->Drop,大于留下,利用回归系数信息进行精修;-->nms-->rec2square-->pad,生成一系列候选框。
- R-Net(refine network)


将P-Net最后输出的所有box,resize到24 * 24后输入R-Net。经过R-Net后,输出与P-Net类似,prob1:box坐标信息与置信度与conv5-2的回归系数信息。根据所得的置信度信息与该层阈值对比,小于阈值的直接drop掉,大于阈值的留下,经过nms、再利用回归系数信息进行精修、rec2square、pad。
- O-Net(output network)


将R-Net最后输出的所有box,resize到48 * 48后输入O-Net。经过O-Net后,输出prob1:box坐标信息与置信度、conv6-2的回归系数信息、以及conv6-3的关键点坐标信息。
conv6-3是number * 10的二维数组,number代表box的数量,10则包含了5个关键点信息的x、y坐标信息:[Rx1,Rx2, Rx3, Rx4, Rx5, Ry1, Ry2, Ry3, Ry4, Ry5],此时的坐标为目标框内部的比例,最后影射回原img得到真实的坐标。
根据prob1置信度信息与该层阈值对比,小于阈值的直接drop掉,大于阈值的留下,再利用回归系数信息进行精修,最后再进行一次nms。
最后,输出一副包含人脸框与人脸关键点的检测图像。
Loss
训练中需要最小化的损失函数来自3方面:
face/non-face classification + bounding box regression + facial landmark localization,综合在一起,表示如下:

边训练边选择出hard sample,只有hard samples才进反向传播,其他样本不进行反向传播。具体做法:对每个小批量里所有样本计算loss,对loss进行降序,前70%samples 做为hard samples进行反向传播。
训练数据预处理
数据类型有下面四种,通过从WIDER FACE数据集随机crop生成 Negtives(IOU小于0.3)、Positives(IOU大于0.65)、Part faces(IOU大于0.4小于0.65),从CelebA 获得landmark数据。
IOU(Intersection-Over-Union)的计算流程如下:

蓝色的框为生成的滑动窗口,红色的框为Guarant Box,其中(x, y)表示回归框的顶点坐标。IOU为两个框相交的面积除以两个框的总面积,如果IOU越大表示生成的滑动窗口和真实的窗口越接近。这样IOU的计算公式可以表示为:
IOU=((x2-gx1) (y2-gy1))/((x2-x1) (y2-y1)+(gx2-gx1) * (gy2-gy1))
- P-Net
通过从WIDER FACE数据集随机crop生成 Negtives、Positives、Part faces。从CelebA 获得landmark数据。
- R-Net
通过P-Net从WIDER FACE检测人脸生成 Negtives、Positives、Part faces。从CelebA 获得landmark数据。
- O-Net
通过O-Net、P-Net从WIDER FACE检测人脸生成 Negtives、Positives、Part faces。从CelebA 获得landmark数据。
作者:泡面小姐不吃面包
文章来源:知乎
推荐阅读
更多芯擎AI开发板干货请关注芯擎AI开发板专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

