
无缝融入,即刻智能[二]:Dify-LLM平台(聊天智能助手、AI工作流)快速使用指南,42K+星标见证专属智能方案
1.快速创建应用
你可以通过 3 种方式在 Dify 的工作室内创建应用:
- 基于应用模板创建(新手推荐)
- 创建一个空白应用
- 通过 DSL 文件(本地 / 在线)创建应用
- 从模板创建应用
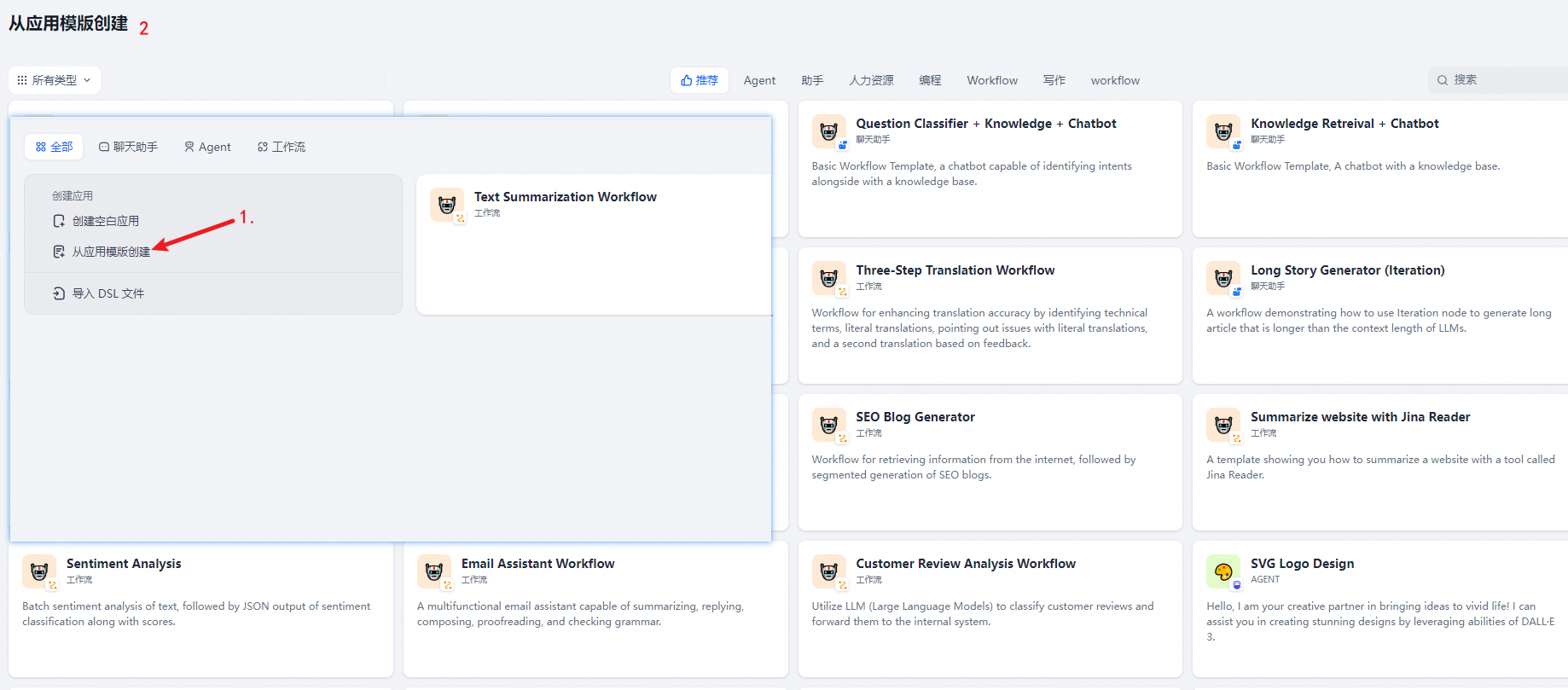
初次使用 Dify 时,你可能对于应用创建比较陌生。为了帮助新手用户快速了解在 Dify 上能够构建哪些类型的应用,Dify 团队内的提示词工程师已经创建好了多场景、高质量的应用模板。
你可以从导航选择 「工作室 」,在应用列表内选择 「从模版创建」。任意选择某个模板,并将其添加至工作区。
- 创建一个新应用
如果你需要在 Dify 上创建一个空白应用,你可以从导航选择 「工作室」 ,在应用列表内选择 「从空白创建 」。
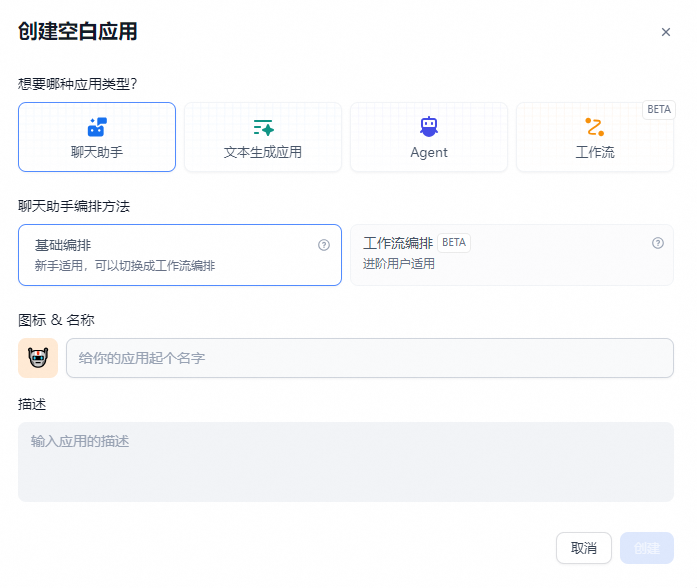
初次创建应用时,你可能需要先理解 Dify 上 4 种不同应用类型的,分别是聊天助手、文本生成应用、Agent 和工作流。
- 聊天助手:基于 LLM 构建对话式交互的助手
- 文本生成:构建面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等
- Agent:能够分解任务、推理思考、调用工具的对话式智能助手
- 工作流:基于流程编排的方式定义更加灵活的 LLM 工作流
文本生成与聊天助手的区别见下表:
| 文本生成 | 聊天助手 | |
|---|---|---|
| WebApp 界面 | 表单 + 结果式 | 聊天式 |
| WebAPI 端点 | completion-messages | chat-messages |
| 交互方式 | 一问一答 | 多轮对话 |
| 流式结果返回 | 支持 | 支持 |
| 上下文保存 | 当次 | 持续 |
| 用户输入表单 | 支持 | 支持 |
| 数据集与插件 | 支持 | 支持 |
| AI 开场白 | 不支持 | 支持 |
| 情景举例 | 翻译、判断、索引 | 聊天 |
通过 DSL 文件创建应用
Dify DSL 是由 Dify.AI 所定义的 AI 应用工程文件标准,文件格式为 YML。该标准涵盖应用在 Dify 内的基本描述、模型参数、编排配置等信息。
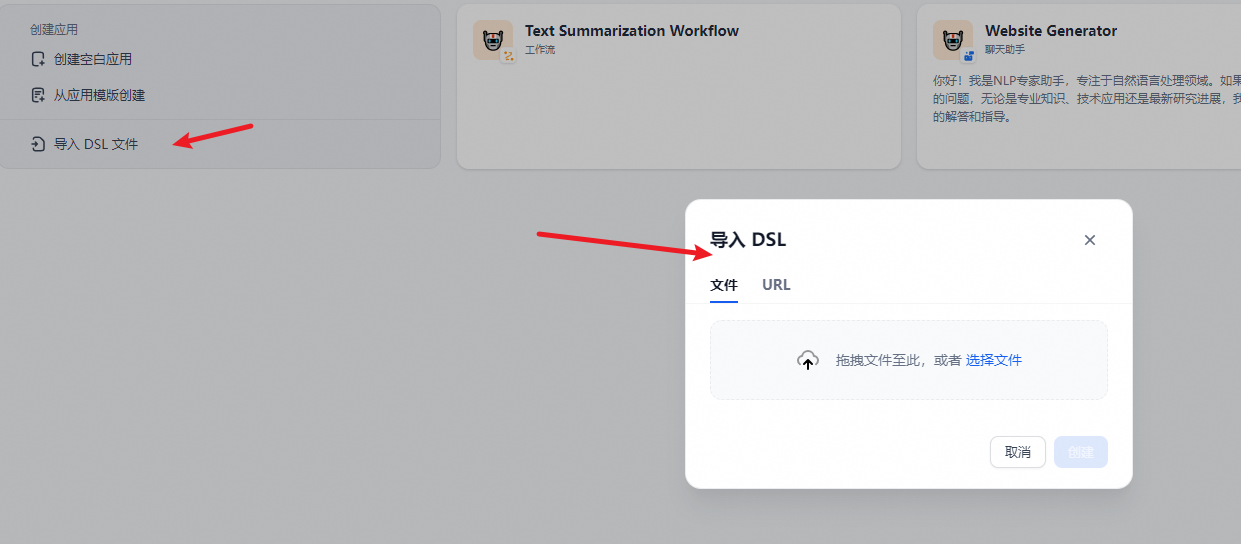
* 本地导入
如果你从社区或其它人那里获得了一个应用模版(DSL 文件),可以从工作室选择 「 导入 DSL 文件 」。DSL 文件导入后将直接加载原应用的所有配置信息。
* URL 导入
你也可以通过 URL 导入 DSL 文件,参考的链接格式:
```
https://example.com/your_dsl.yml
```
2.应用介绍
2.1 聊天助手
对话型应用采用一问一答模式与用户持续对话。对话型应用的编排支持:对话前提示词,变量,上下文,开场白和下一步问题建议。
创建应用:在首页点击 “创建应用” 按钮创建应用。填上应用名称,应用类型选择聊天助手。
编排应用:创建应用后会自动跳转到应用概览页。点击左侧菜单 编排 来编排应用。
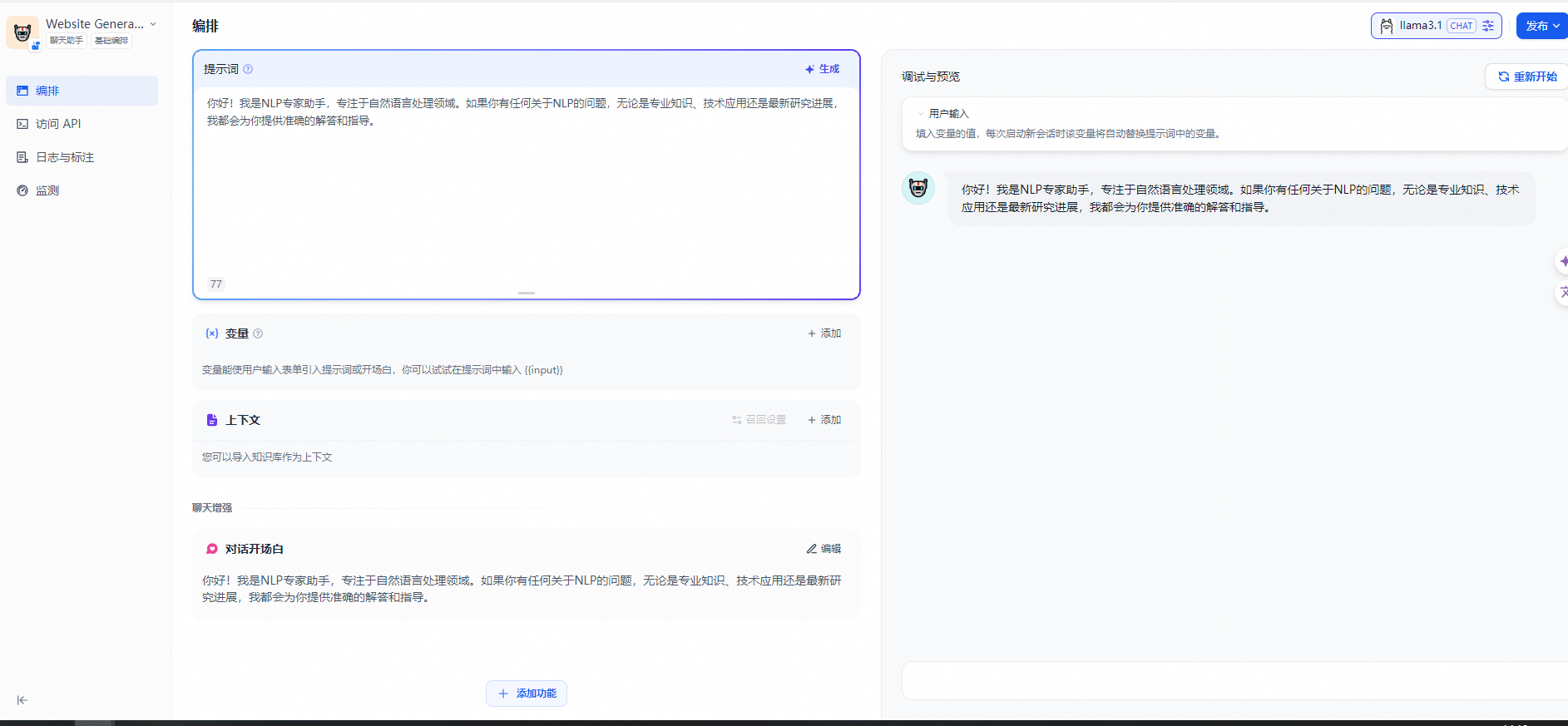
填写提示词:提示词用于约束 AI 给出专业的回复,让回应更加精确。你可以借助内置的提示生成器,编写合适的提示词。提示词内支持插入表单变量,例如{{input}}。提示词中的变量的值会替换成用户填写的值。
示例:
- 输入提示指令,要求给出一段场景的提示词。
- 右侧内容框将自动生成提示词。
- 你可以在提示词内插入自定义变量。
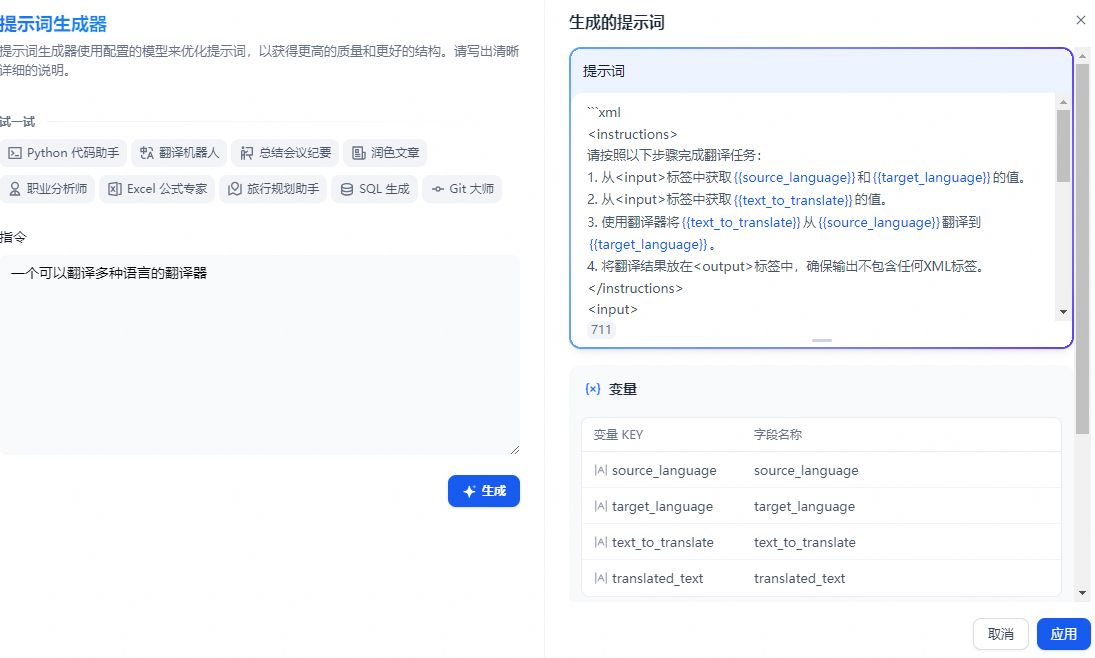
为了更好的用户体验,可以加上对话开场白:。点击页面底部的 “添加功能” 按钮,打开 “对话开场白” 的功能:
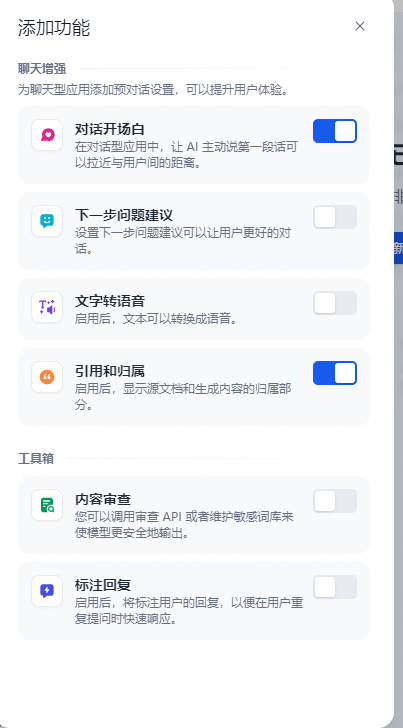
编辑开场白时,还可以添加数个开场问题:
- 添加上下文
如果想要让 AI 的对话范围局限在知识库内,例如企业数据,可以在 “上下文” 内引用知识库。
- 调试:在右侧填写用户输入项,输入内容进行调试。
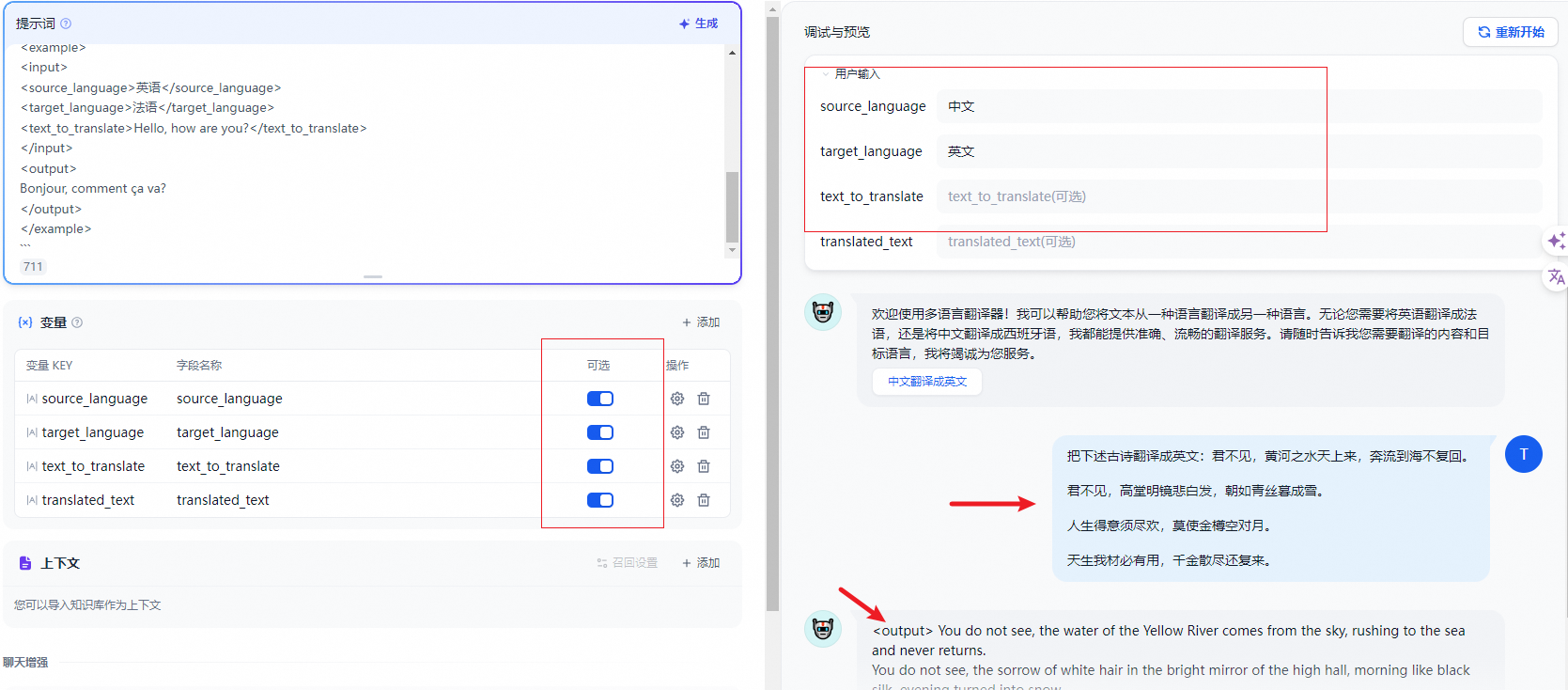
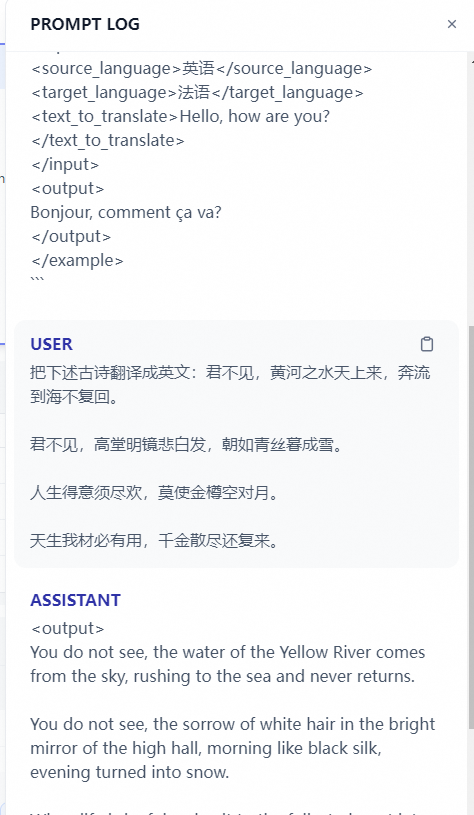
如果回答结果不理想,可以调整提示词和底层模型。你也可以使用多个模型同步进行调试,搭配出合适的配置。
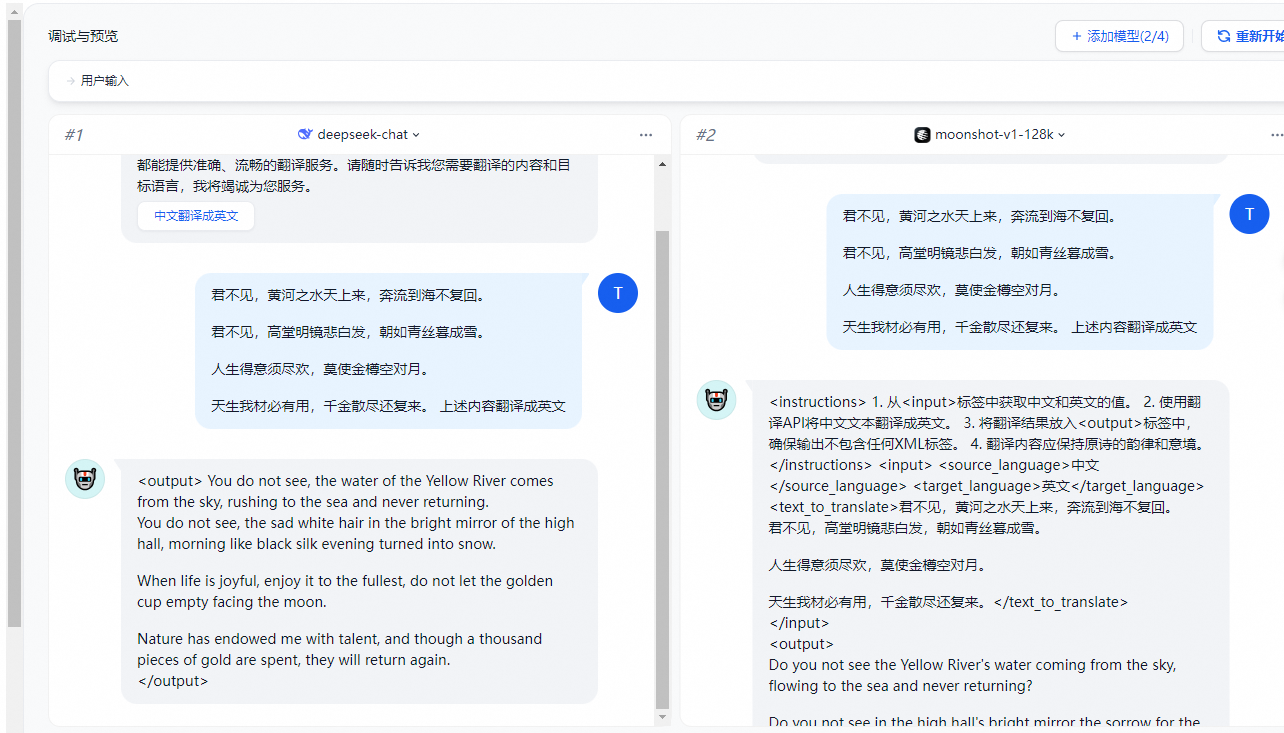
多个模型进行调试:
如果使用单一模型调试时感到效率低下,你也可以使用 “多个模型进行调试” 功能,批量检视模型的回答效果。最多支持同时添加 4 个大模型。
- 发布应用
调试好应用后,点击右上角的 “发布” 按钮生成独立的 AI 应用。除了通过公开 URL 体验该应用,你也进行基于 APIs 的二次开发、嵌入至网站内等操作。
2.2 智能助手(Agent Assistant)
智能助手(Agent Assistant),利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。
- 选择智能助手的推理模型,智能助手的任务完成能力取决于模型推理能力,建议在使用智能助手时选择推理能力更强的模型系列如 gpt-4 以获得更稳定的任务完成效果。
- 你可以在 “提示词” 中编写智能助手的指令,为了能够达到更优的预期效果,你可以在指令中明确它的任务目标、工作流程、资源和限制等。
#角色
你是一个AI新闻助手
#目标
帮我搜索AI新闻,主题请询问我
#要求
1.请用中文帮我总结
2.给我5篇新闻
#工作流
1. 先通过搜索技能搜索新闻【调用工具:travily】
2. 检查返回的内容,甄别是最近的新闻
3. 总结内容,再输出给我
#输出格式
标题:
摘要:
链接:- 添加助手需要的工具
在 “上下文” 中,你可以添加智能助手可以用于查询的知识库工具,这将帮助它获取外部背景知识。
在 “工具” 中,你可以添加需要使用的工具。工具可以扩展 LLM 的能力,比如联网搜索、科学计算或绘制图片,赋予并增强了 LLM 连接外部世界的能力。Dify 提供了两种工具类型:第一方工具和自定义工具。
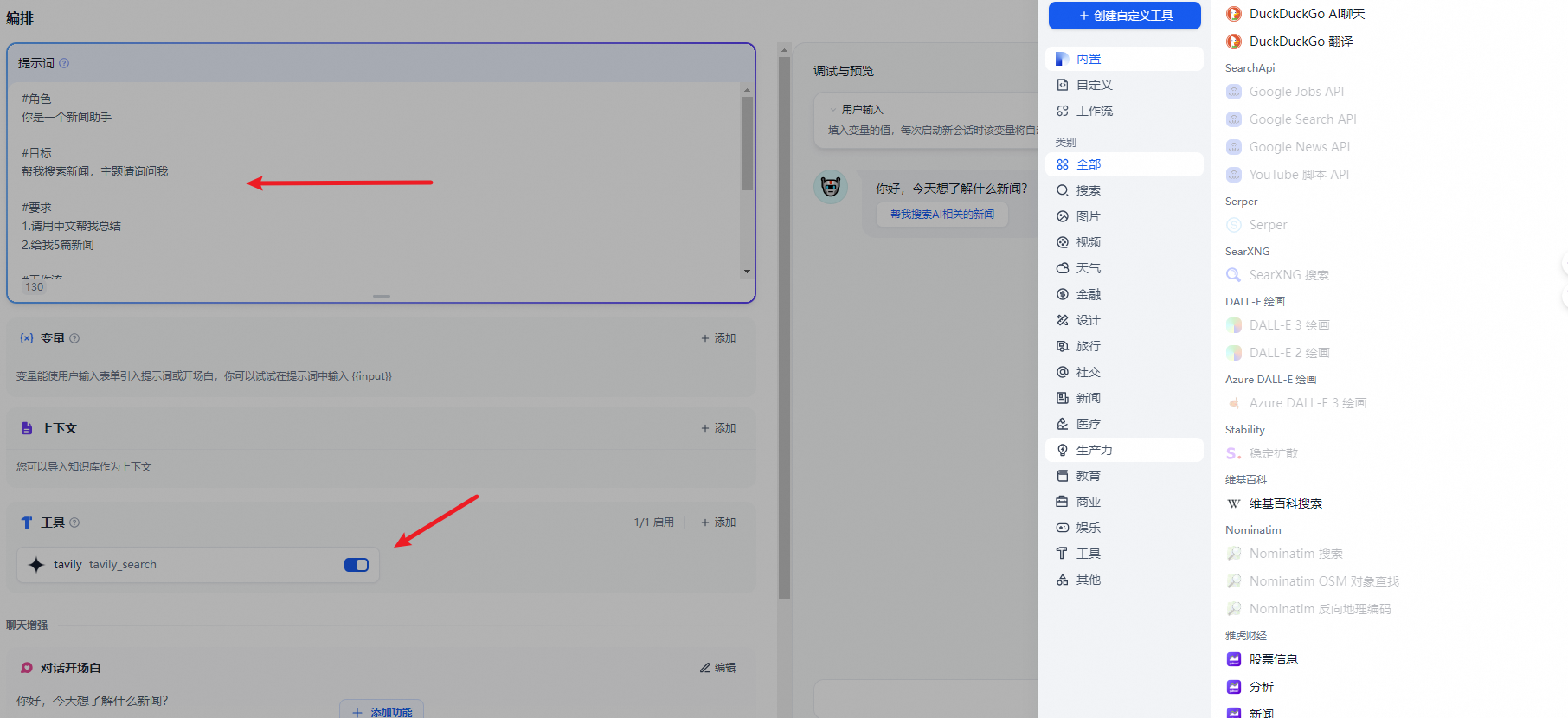
Tavily Search API is a search engine optimized for LLMs and RAG, aimed at efficient, quick, and persistent search results
工具使用户可以在 Dify 上创建更强大的 AI 应用,如你可以为智能助理型应用(Agent)编排合适的工具,它可以通过任务推理、步骤拆解、调用工具完成复杂任务。另外工具也可以方便将你的应用与其他系统或服务连接,与外部环境交互,如代码执行、对专属信息源的访问等。
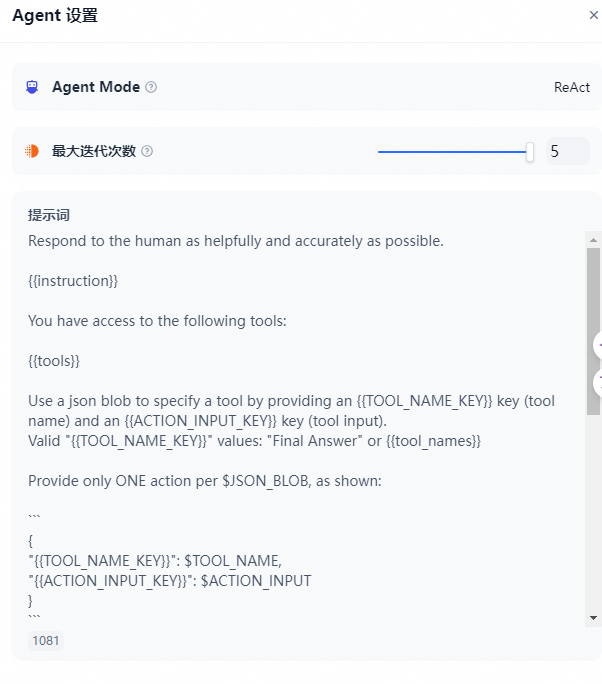
- 配置 Agent
在 Dify 上为智能助手提供了 Function calling(函数调用)和 ReAct 两种推理模式。已支持 Function Call 的模型系列如 gpt-3.5/gpt-4 拥有效果更佳、更稳定的表现,尚未支持 Function calling 的模型系列,支持了 ReAct 推理框架实现类似的效果。
在 Agent 配置中,你可以修改助手的迭代次数限制。
- 配置对话开场白
可以为智能助手配置一套会话开场白和开场问题,配置的对话开场白将在每次用户初次对话中展示助手可以完成什么样的任务,以及可以提出的问题示例。
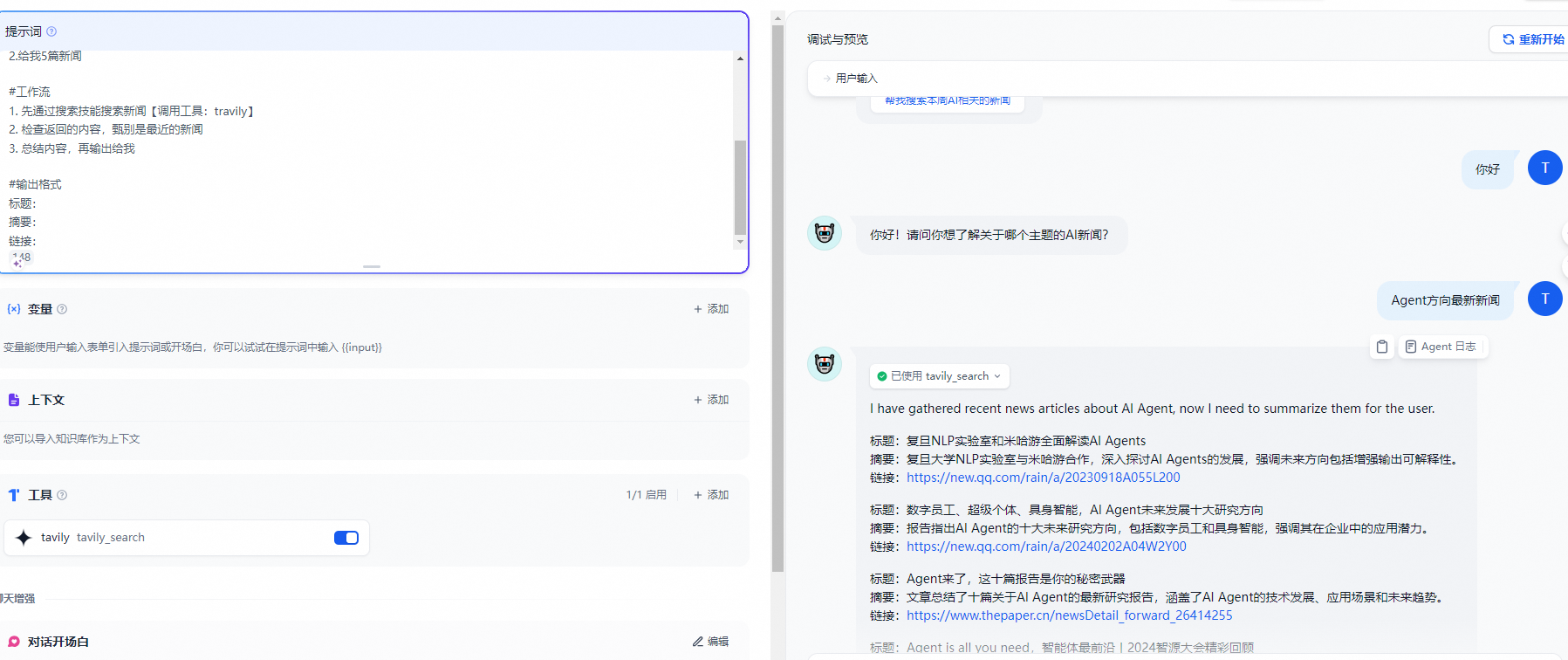
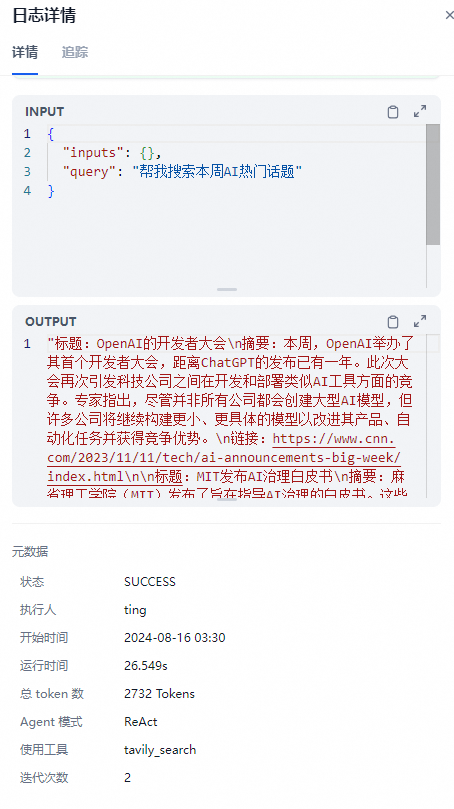
- 调试与预览
编排完智能助手之后,你可以在发布成应用之前进行调试与预览,查看助手的任务完成效果。
2.3 开应用工具箱
应用工具箱为 Dify 的应用提供了不同的附加功能:
对话开场白:在对话类应用中,AI 会主动说第一句话或者提出问题,你可以编辑开场白的内容包括开场问题。使用对话开场白可以引导用户提问,交代应用背景,降低对话提问的使用门槛。
下一步问题建议:设置下一步问题建议可以在每次对话交互后,让 AI 根据之前的对话内容继续生成 3 个提问,引导下一轮对话。
文字转语音:开启后可以将 AI 回复的内容转换成自然的语音播放。
语音转文字:开启后可以在应用内录音并将语音自动转换成文本。
2.3.1 引用与归属
开启功能后,当大语言模型回复问题时引用来自知识库的内容时,可以在回复内容下面查看到具体的引用段落信息,包括原始分段文本、分段序号、匹配度等。
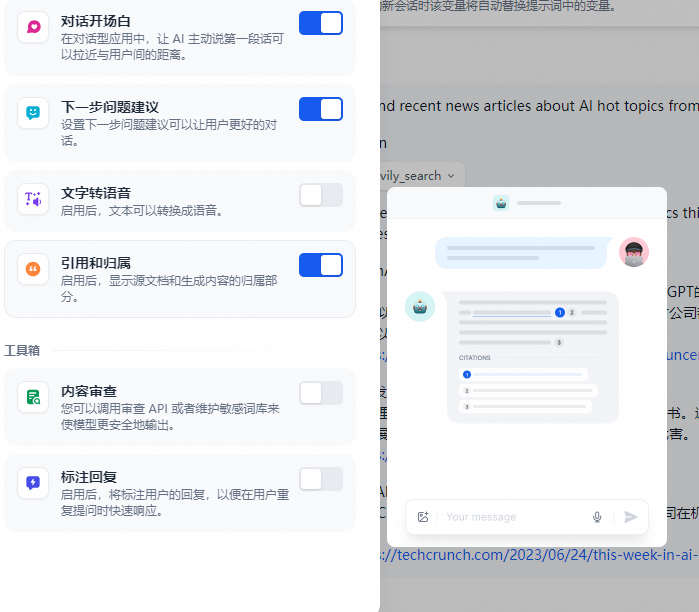
开启功能后,当大语言模型回复问题时引用来自知识库的内容时,可以在回复内容下面查看到具体的引用段落信息,包括原始分段文本、分段序号、匹配度等。点击引用分段上方的 跳转至知识库 ,可以快捷访问该分段所在的知识库分段列表,方便开发者进行调试编辑。
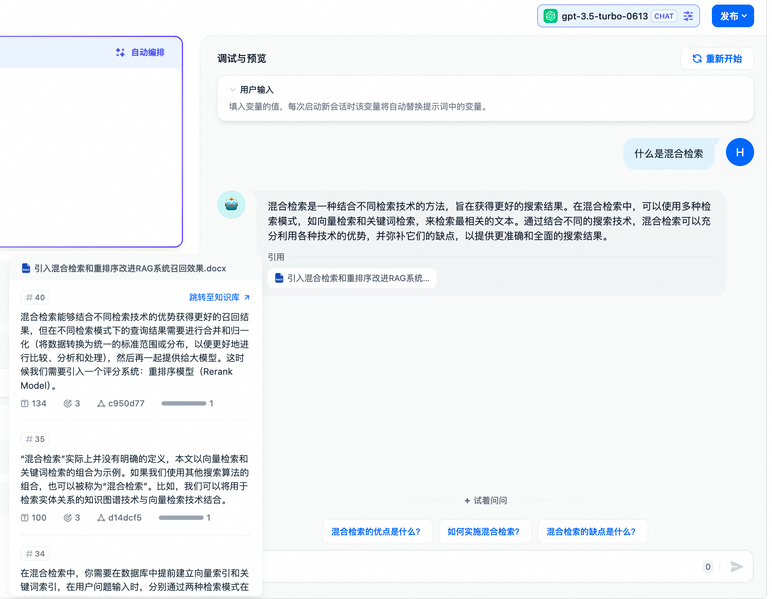
2.3.2 内容审查
在与 AI 应用交互的过程中,往往在内容安全性,用户体验,法律法规等方面有较为苛刻的要求,此时我们需要 “敏感内容审查” 功能,来为终端用户创造一个更好的交互环境。
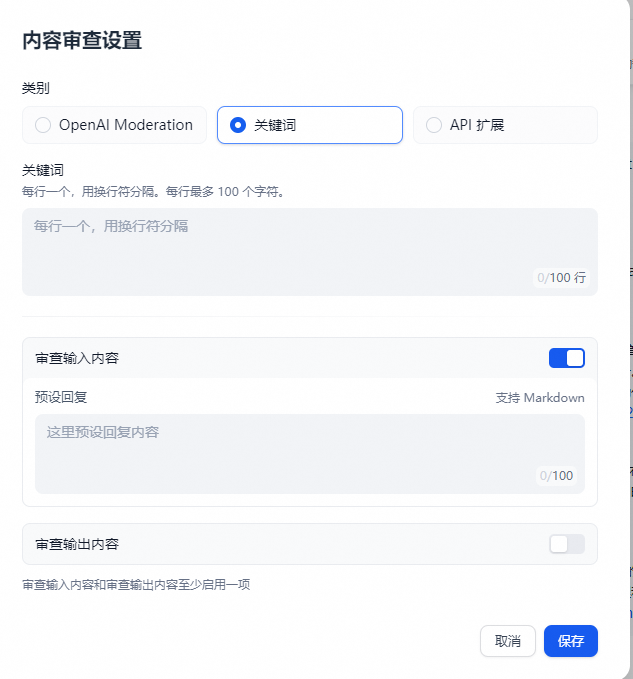
- 功能一:调用 OpenAI Moderation API
OpenAI 和大多数 LLM 公司提供的模型,都带有内容审查功能,确保不会输出包含有争议的内容,比如暴力,性和非法行为,并且 OpenAI 还开放了这种内容审查能力,具体可以参考 platform.openai.com 。现在你也可以直接在 Dify 上调用 OpenAI Moderation API,你可以审核输入内容或输出内容,只要输入对应的“预设回复”即可。 - 功能二:自定义关键词
开发者可以自定义需要审查的敏感词,比如把“kill”作为关键词,在用户输入的时候作审核动作,要求预设回复内容为“The content is violating usage policies.”可以预见的结果是当用户在终端输入包含“kill”的语料片段,就会触发敏感词审查工具,返回预设回复内容。 - 功能三: 敏感词审查 Moderation 扩展
不同的企业内部往往有着不同的敏感词审查机制,企业在开发自己的 AI 应用如企业内部知识库 ChatBot,需要对员工输入的查询内容作敏感词审查。为此,开发者可以根据自己企业内部的敏感词审查机制写一个 API 扩展,具体可参考 敏感内容审查,从而在 Dify 上调用,实现敏感词审查的高度自定义和隐私保护。
参考链接:https://docs.dify.ai/v/zh-han...
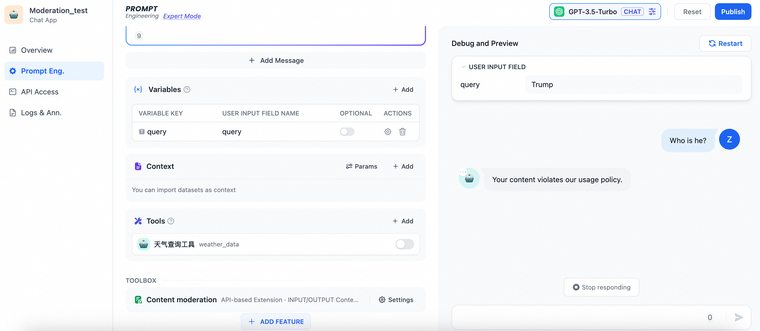
比如本地服务中自定义敏感词审查规则:不能查询有关美国总统的名字的问题。当用户在query变量输入"Trump",则在对话时会返回 "Your content violates our usage policy." 测试效果如下:
2.3.3 标注回复
标注回复功能通过人工编辑标注为应用提供了可定制的高质量问答回复能力。
适用情景:
- 特定领域的定制化回答: 在企业、政府等客服或知识库问答情景时,对于某些特定问题,服务提供方希望确保系统以明确的结果来回答问题,因此需要对在特定问题上定制化输出结果。比如定制某些问题的“标准答案”或某些问题“不可回答”。
- POC 或 DEMO 产品快速调优: 在快速搭建原型产品,通过标注回复实现的定制化回答可以高效提升问答结果的生成预期,提升客户满意度。
标注回复功能相当于提供了另一套检索增强系统,可以跳过 LLM 的生成环节,规避 RAG 的生成幻觉问题。
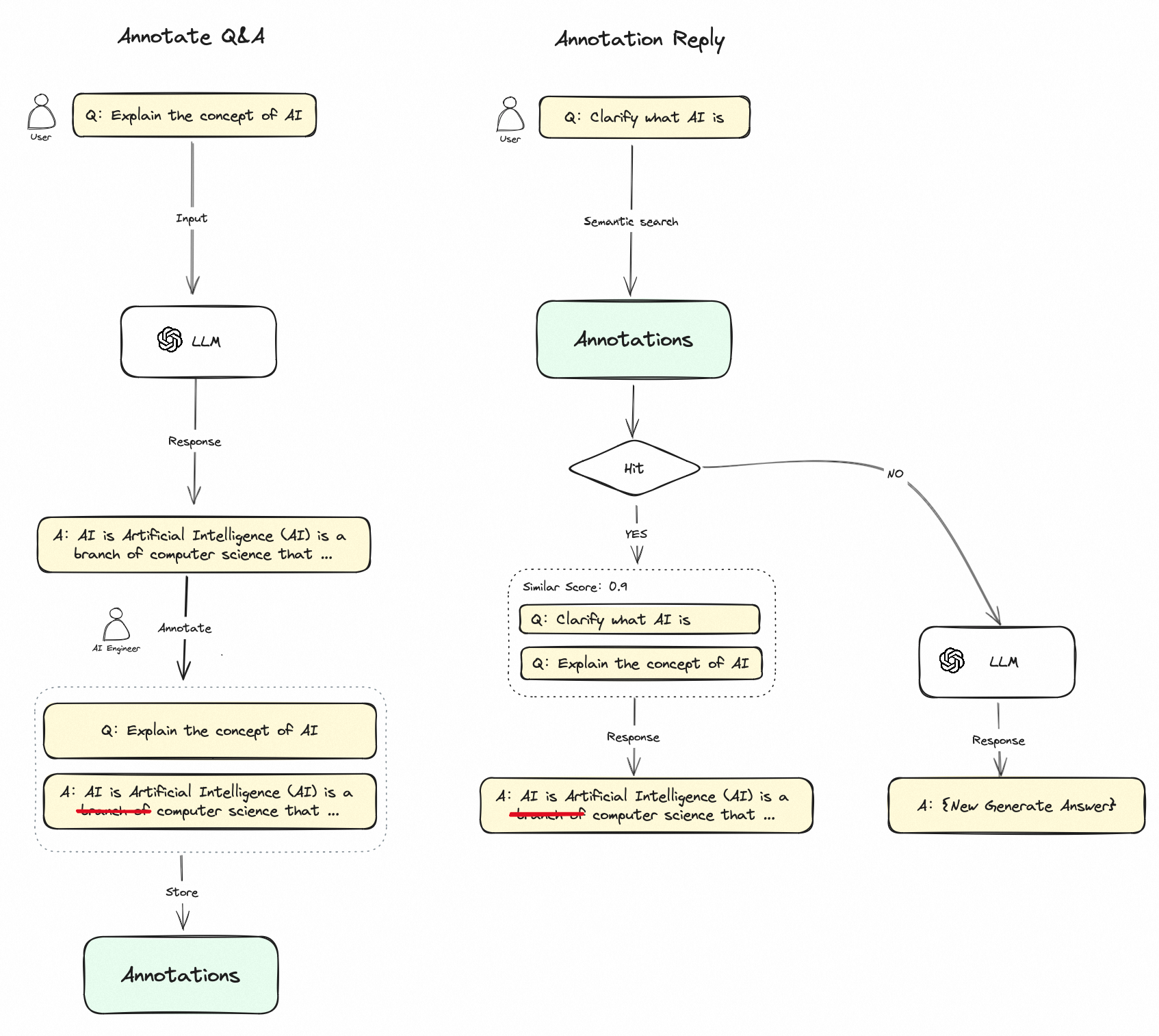
使用流程
- 在开启标注回复功能之后,你可以对 LLM 对话回复内容进行标注,你可以将 LLM 回复的高质量答案直接添加为一条标注,也可以根据自己的需求编辑一条高质量答案,这些编辑的标注内容会被持久化保存;
- 当用户再次提问相似的问题时,会将问题向量化并查询中与之相似的标注问题;
- 如果找到匹配项,则直接返回标注中与问题相对应的答案,不再传递至 LLM 或 RAG 过程进行回复;
- 如果没有找到匹配项,则问题继续常规流程(传递至 LLM 或 RAG);
- 关闭标注回复功能后,系统将一直不再继续从标注内匹配回复。
- 提示词编排中开启标注回复
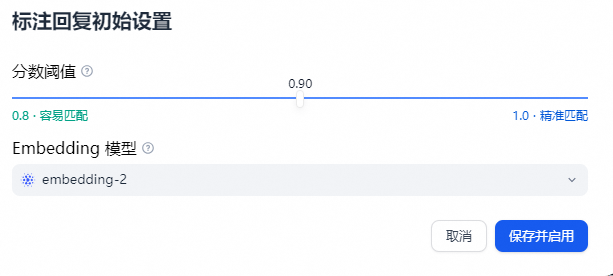
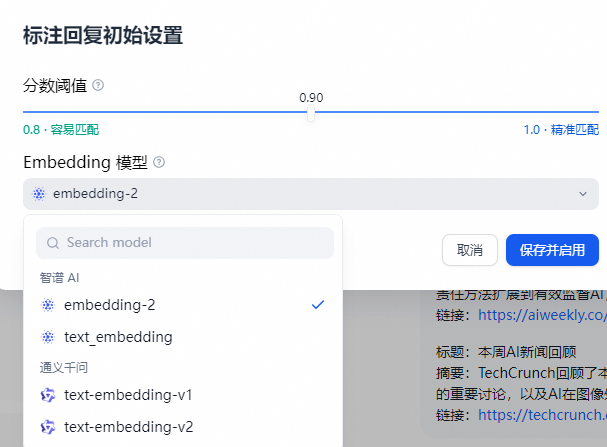
进入“应用构建->添加功能”开启标注回复开关:开启时需要先设置标注回复的参数,可设置参数包括:Score 阈值 和 Embedding 模型
- Score 阈值:用于设置标注回复的匹配相似度阈值,只有高于阈值分数的标注会被召回。
- Embedding 模型:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
点击保存并启用时,该设置会立即生效,系统将对所有已保存的标注利用 Embedding 模型生成嵌入保存。
- 在会话调试页添加标注
可以在调试与预览页面直接在模型回复信息上添加或编辑标注。
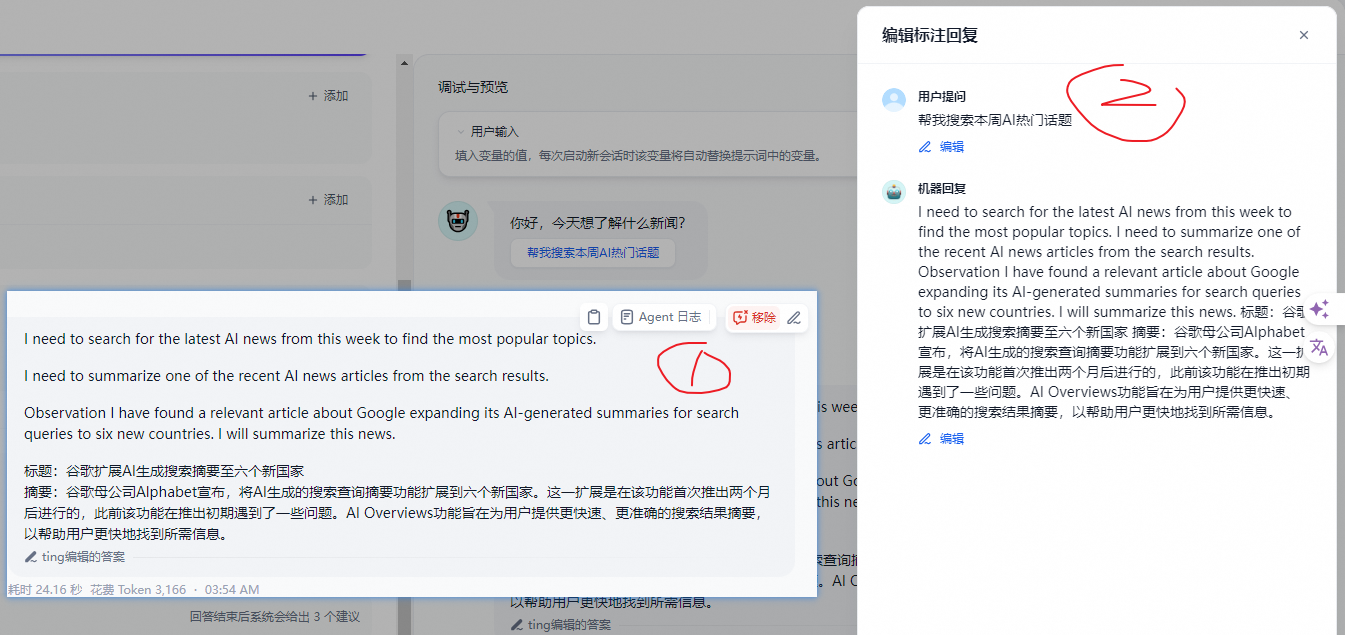
编辑成你需要的高质量回复并保存。再次输入同样的用户问题,系统将使用已保存的标注直接回复用户问题。
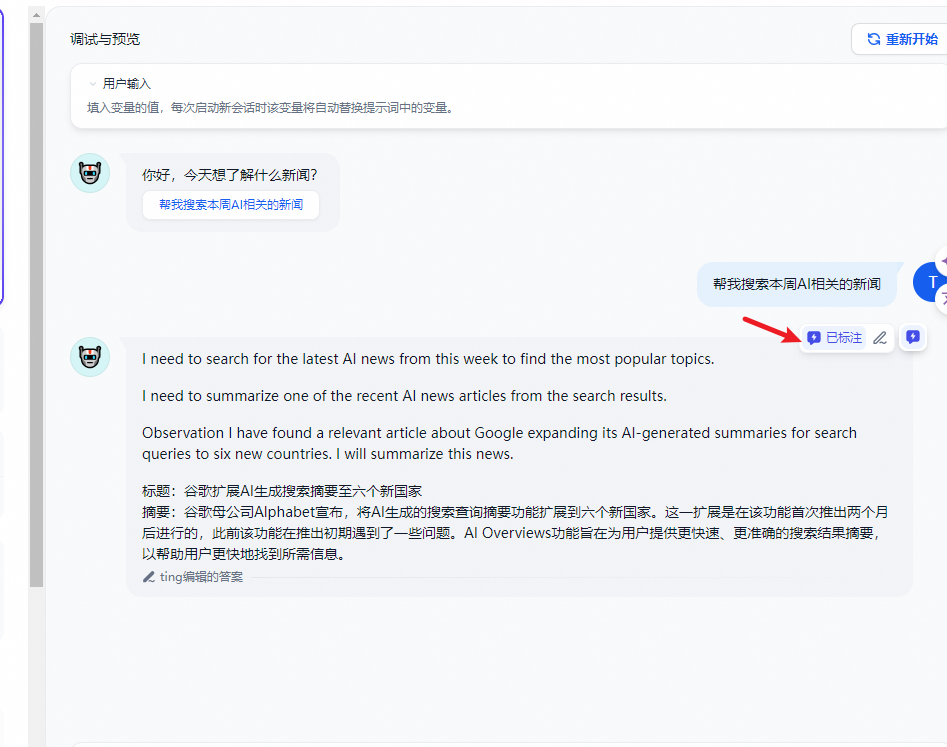
- 日志与标注中开启标注回复
进入“应用构建->日志与标注->标注”开启标注回复开关:

- 标注回复可设置的参数包括:Score 阈值 和 Embedding 模型
Score 阈值:用于设置标注回复的匹配相似度阈值,只有高于阈值分数的标注会被召回。
Embedding 模型:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
- 批量导入标注问答对:在批量导入功能内,你可以下载标注导入模板,按模版格式编辑标注问答对,编辑好后在此批量导入。
- 批量导出标注问答对:通过标注批量导出功能,你可以一次性导出系统内已保存的所有标注问答对。
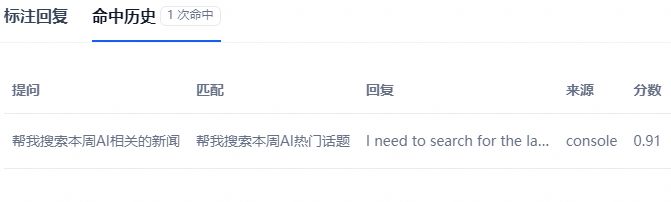
- 查看标注回复命中历史:可以查看所有命中该条标注的编辑历史、命中的用户问题、回复答案、命中来源、匹配相似分数、命中时间等信息,你可以根据这些系统信息持续改进你的标注内容。
3.工作流
3.1 节点概览
节点是工作流的关键构成,通过连接不同功能的节点,执行工作流的一系列操作。
变量
变量用于串联工作流内前后节点的输入与输出,实现流程中的复杂处理逻辑。
- 工作流需要定义启动执行变量,如聊天机器人需要定义一个输入变量
sys.query; - 节点一般需要定义输入变量,如定义问题分类器的输入变量为
sys.query; - 引用变量时只可引用流程上游节点的变量;
- 为避免变量名重复,节点命名不可重复;
- 节点的输出变量一般为系统固定变量,不可编辑。
环境变量
环境变量用于保护工作流内所涉及的敏感信息,例如运行工作流时所涉及的 API 密钥、数据库密码等。它们被存储在工作流程中,而不是代码中,以便在不同环境中共享。
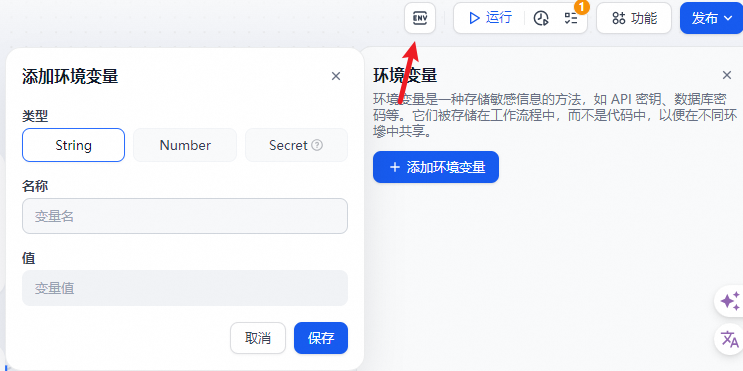
支持以下三种数据类型:
- String 字符串
- Number 数字
- Secret 密钥
环境变量拥有以下特性:
- 环境变量可在大部分节点内全局引用;
- 环境变量命名不可重复;
- 环境变量为只读变量,不可写入;
- 会话变量
会话变量仅适用于 Chatflow 类型(聊天助手 → 工作流编排)应用。
会话变量允许应用开发者在同一个 Chatflow 会话内,指定需要被临时存储的特定信息,并确保在当前工作流内的多轮对话内都能够引用该信息,如上下文、上传至对话框的文件(即将上线)、 用户在对话过程中所输入的偏好信息等。好比为 LLM 提供一个可以被随时查看的“备忘录”,避免因 LLM 记忆出错而导致的信息偏差。
例如你可以将用户在首轮对话时输入的语言偏好存储至会话变量中,LLM 在回答时将参考会话变量中的信息,并在后续的对话中使用指定的语言回复用户。
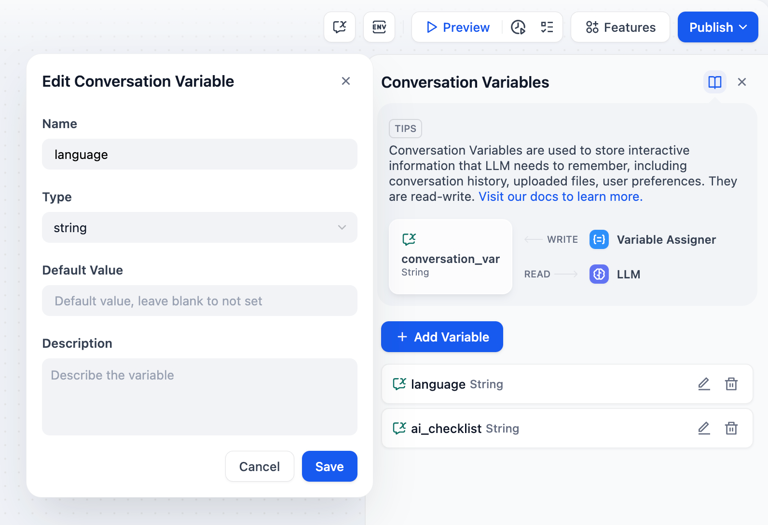
会话变量支持以下六种数据类型:
- String 字符串
- Number 数值
- Object 对象
- Array[string] 字符串数组
- Array[number] 数值数组
- Array[object] 对象数组
会话变量具有以下特性:
- 会话变量可在大部分节点内全局引用;
- 会话变量的写入需要使用[变量赋值]节点;
- 会话变量为可读写变量;
Chatflow 和 Workflow
应用场景
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
使用入口
可用节点差异
- End 节点属于 Workflow 的结束节点,仅可在流程结束时选择。
- Answer 节点属于 Chatflow ,用于流式输出文本内容,并支持在流程中间步骤输出。
- Chatflow 内置聊天记忆(Memory),用于存储和传递多轮对话的历史消息,可在 LLM 、问题分类等节点内开启,Workflow 无 Memory 相关配置,无法开启。
- Chatflow 的开始节点内置变量包括:
sys.query,sys.files,sys.conversation_id,sys.user_id。Workflow 的开始节点内置变量包括:sys.files,sys.user_id
3.2 节点说明
1.开始节点
在开始节点中,您可以自定义启动工作流的输入变量。每个工作流都需要一个开始节点。
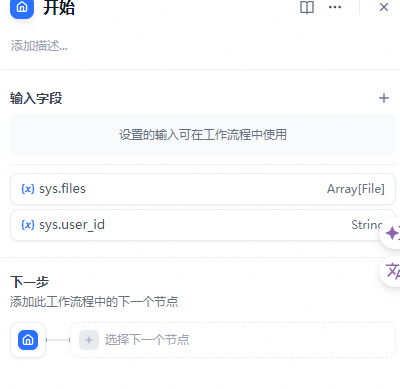
开始节点支持定义四种类型输入变量:
- 文本
- 段落
- 下拉选项
- 数字
- 文件
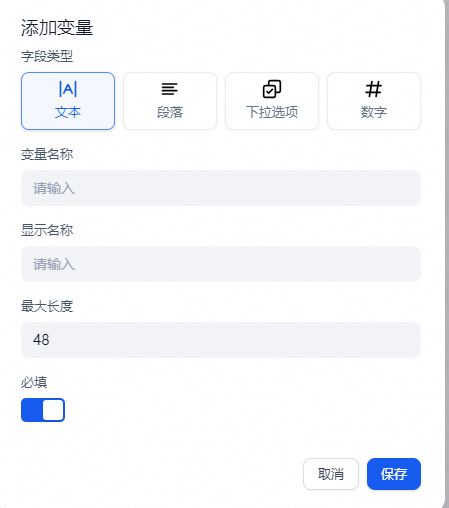
配置完成后,工作流在执行时将提示您提供开始节点中定义的变量值。
Tip: 在Chatflow中,开始节点提供了内置系统变量:sys.query 和 sys.files。
sys.query 用于对话应用中的用户输入问题。
sys.files 用于对话中的文件上传,如上传图片,这需要与图片理解模型配合使用。
2.结束节点
定义一个工作流程结束的最终输出内容。每一个工作流在完整执行后都需要至少一个结束节点,用于输出完整执行的最终结果。
结束节点为流程终止节点,后面无法再添加其他节点,工作流应用中只有运行到结束节点才会输出执行结果。若流程中出现条件分叉,则需要定义多个结束节点。
结束节点需要声明一个或多个输出变量,声明时可以引用任意上游节点的输出变量。
3.直接回复
定义一个 Chatflow 流程中的回复内容。可以在文本编辑器中自由定义回复格式,包括自定义一段固定的文本内容、使用前置步骤中的输出变量作为回复内容、或者将自定义文本与变量组合后回复。
可随时加入节点将内容流式输出至对话回复,支持所见即所得配置模式并支持图文混排,如:
- 输出 LLM 节点回复内容
- 输出生成图片
- 输出纯文本
示例 1:输出纯文本
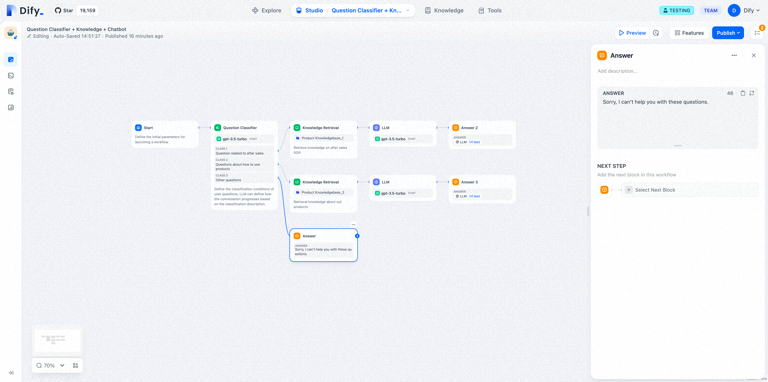
示例 2:输出图片 + LLM 回复

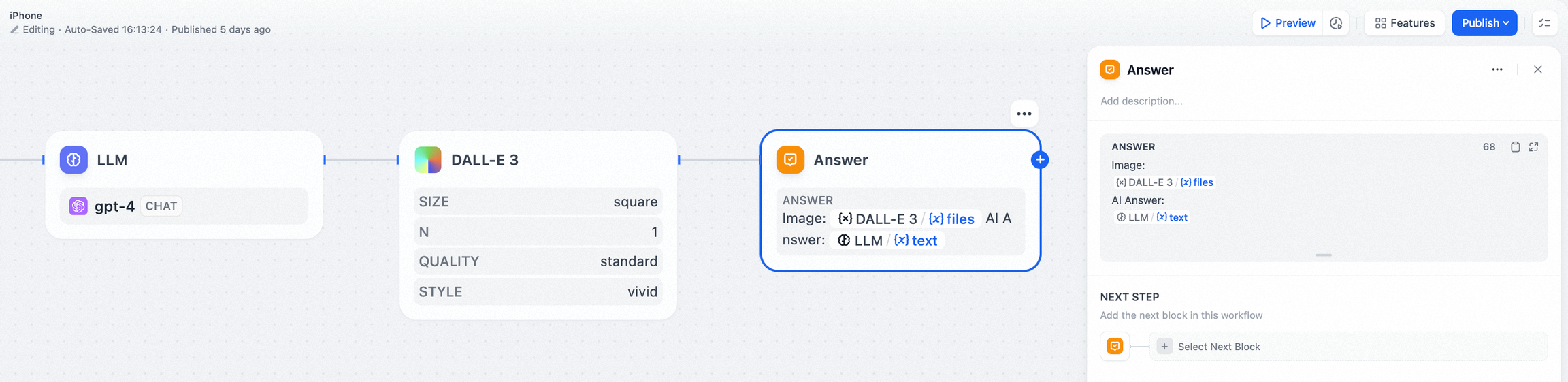
直接回复节点可以不作为最终的输出节点,作为流程过程节点时,可以在中间步骤流式输出结果。
4.LLM
场景:LLM 是 Chatflow/Workflow 的核心节点,利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
- 意图识别,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
- 文本生成,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
- 内容分类,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
- 文本转换,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
- 代码生成,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
- RAG,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
- 图片理解,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
选择合适的模型,编写提示词,你可以在 Chatflow/Workflow 中构建出强大、可靠的解决方案。
LLM配置步骤:
- 选择一个模型取决于其推理能力、成本、响应速度、上下文窗口等因素,你需要根据场景需求和任务类型选择合适的模型。
- 配置模型参数,模型参数用于控制模型的生成结果,例如温度、TopP,最大标记、回复格式等,为了方便选择系统同时提供了 3 套预设参数:创意,平衡和精确。
- 编写提示词,LLM 节点提供了一个易用的提示词编排页面,选择聊天模型或补全模型,会显示不同的提示词编排结构。
- 高级设置,可以开关记忆,设置记忆窗口,使用 Jinja-2 模版语言来进行更复杂的提示词等。
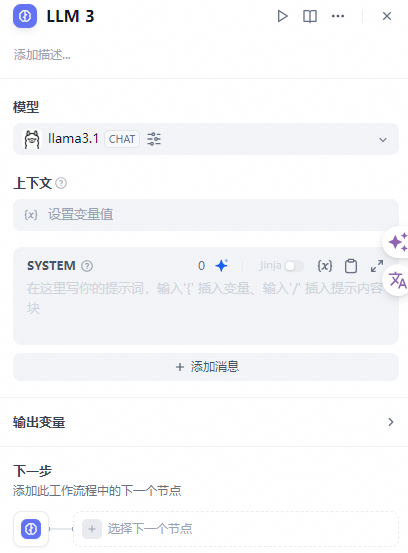
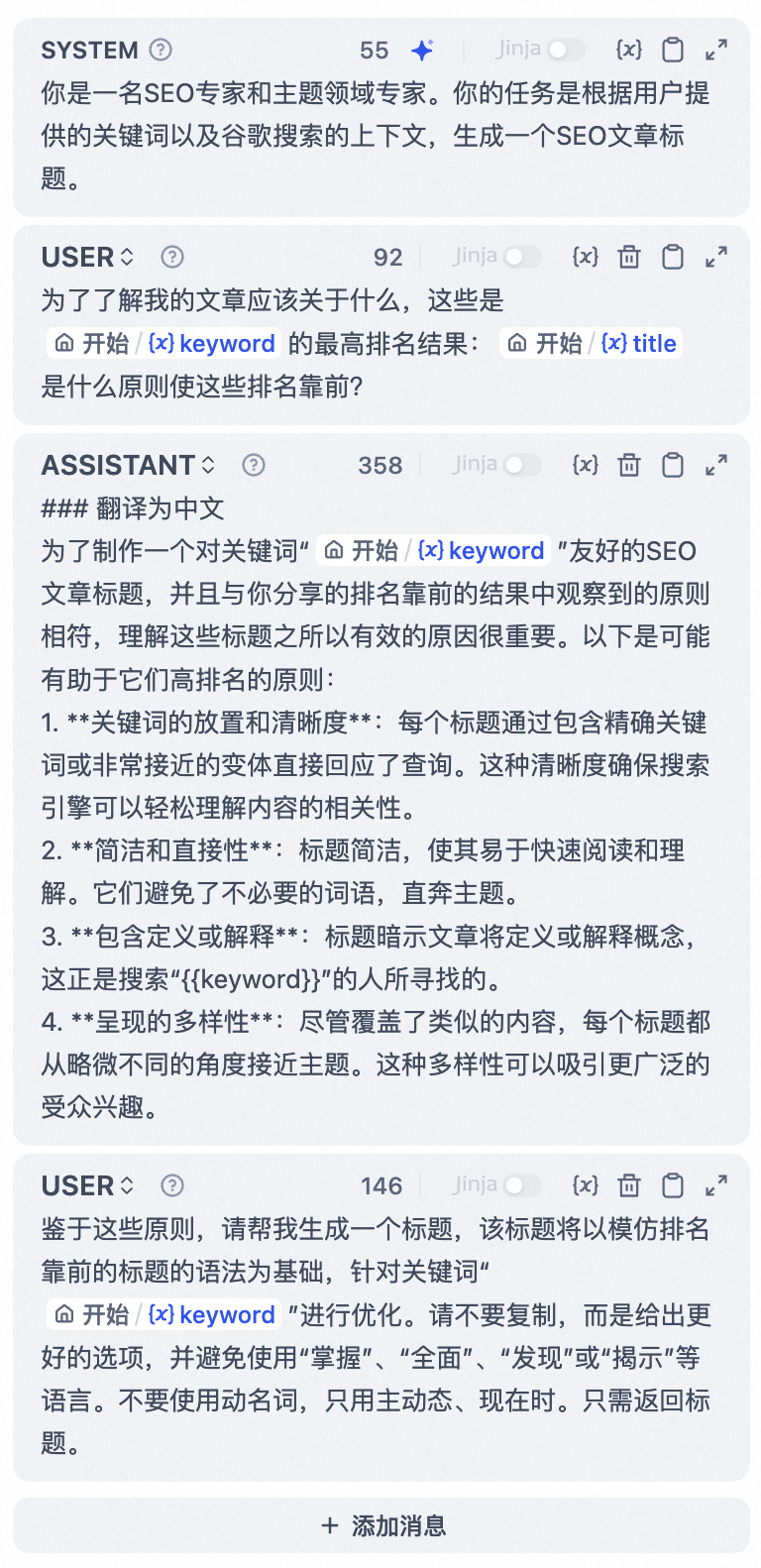
- 编写提示词
在 LLM 节点内,你可以自定义模型输入提示词。如果选择聊天模型(Chat model),你可以自定义系统提示词(SYSTEM)/用户(USER)/助手(ASSISTANT)三部分内容。
- 提示生成器
如果在编写系统提示词(SYSTEM)时没有好的头绪,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
在提示词编辑器中,你可以通过输入 “/” 或者 “{” 呼出 变量插入菜单,将 特殊变量块 或者 上游节点变量 插入到提示词中作为上下文内容。
- 特殊变量说明
- 上下文变量是 LLM 节点内定义的特殊变量类型,用于在提示词内插入外部检索的文本内容。
在常见的知识库问答应用中,知识库检索的下游节点一般为 LLM 节点,知识检索的 输出变量 result 需要配置在 LLM 节点中的 上下文变量 内关联赋值。关联后在提示词的合适位置插入 上下文变量 ,可以将外部检索到的知识插入到提示词中。
该变量除了可以作为 LLM 回复问题时的提示词上下文作为外部知识引入,由于其数据结构中包含了分段引用信息,同时可以支持应用端的 引用与归属 功能。
若上下文变量关联赋值的是上游节点的普通变量,例如开始节点的字符串类型变量,则上下文的变量同样可以作为外部知识引入,但 引用与归属 功能将会失效。
高级功能
记忆: 开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。记忆窗口: 记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。对话角色名设置: 由于模型在训练阶段的差异,不同模型对于角色名的指令遵循程度不同,如 Human/Assistant,Human/AI,人类/助手等等。为适配多模型的提示响应效果,系统提供了对话角色名的设置,修改对话角色名将会修改会话历史的角色前缀。Jinja-2 模板: LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,
5.知识检索
常见情景:构建基于外部数据/知识的 AI 问答系统(RAG)。
下图为一个最基础的知识库问答应用示例,该流程的执行逻辑为:知识库检索作为 LLM 节点的前置步骤,在用户问题传递至 LLM 节点之前,先在知识检索节点内将匹配用户问题最相关的文本内容并召回,随后在 LLM 节点内将用户问题与检索到的上下文一同作为输入,让 LLM 根据检索内容来回复问题。
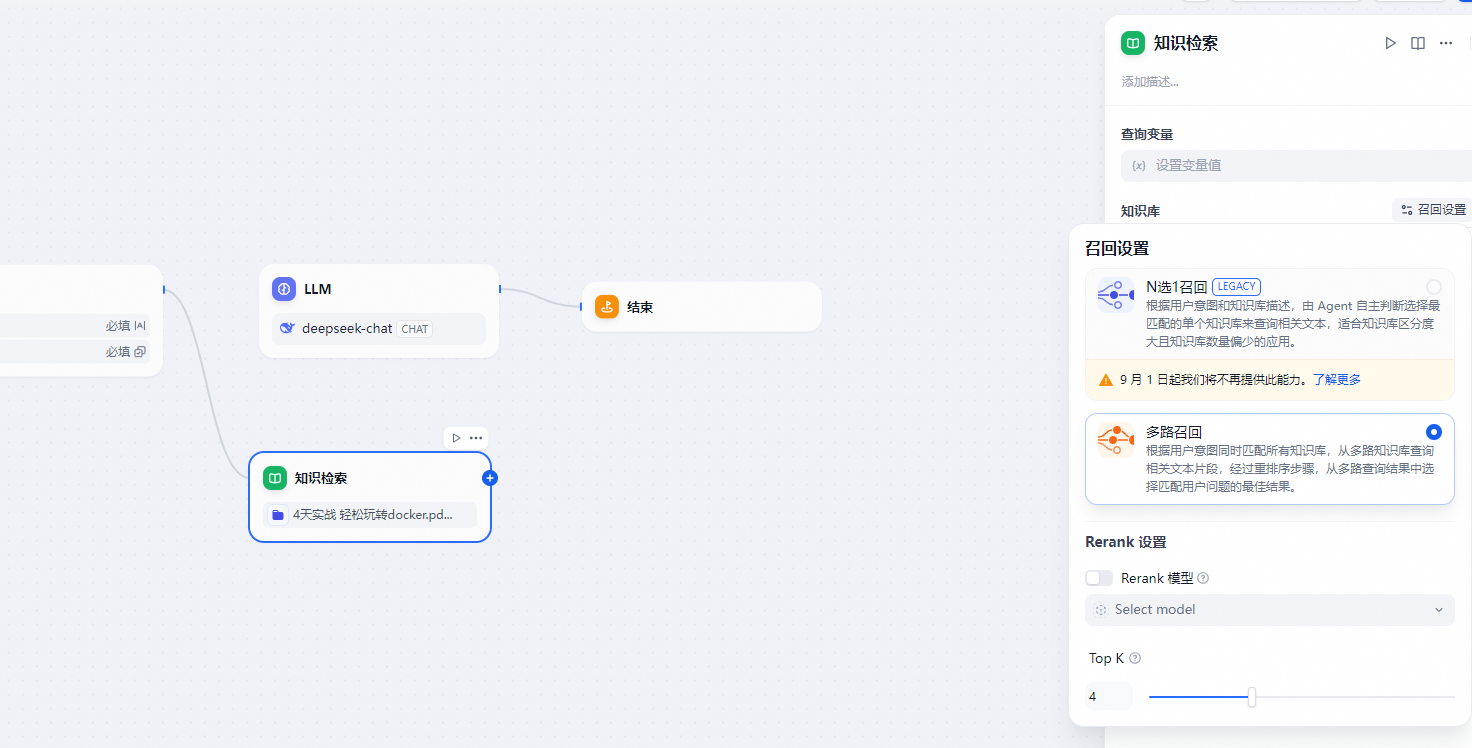
配置流程:
- 选择查询变量,用于作为输入来检索知识库中的相关文本分段,在常见的对话类应用中一般将开始节点的 sys.query 作为查询变量;
- 选择需要查询的知识库,可选知识库需要在 Dify 知识库内预先创建;
- 指定召回模式。自 9 月 1 日后,知识库的召回模式将自动切换为多路召回,不再建议使用 N 选 1 召回模式;
- 连接并配置下游节点,一般为 LLM 节点;
- 输出变量
知识检索的输出变量 result 为从知识库中检索到的相关文本分段。其变量数据结构中包含了分段内容、标题、链接、图标、元数据信息。

- 配置下游节点
在常见的对话类应用中,知识库检索的下游节点一般为 LLM 节点,知识检索的输出变量 result 需要配置在 LLM 节点中的 上下文变量 内关联赋值。关联后你可以在提示词的合适位置插入 上下文变量。
当用户提问时,若在知识检索中召回了相关文本,文本内容会作为上下文变量中的值填入提示词,提供 LLM 回复问题;若未在知识库检索中召回相关的文本,上下文变量值为空,LLM 则会直接回复用户问题。
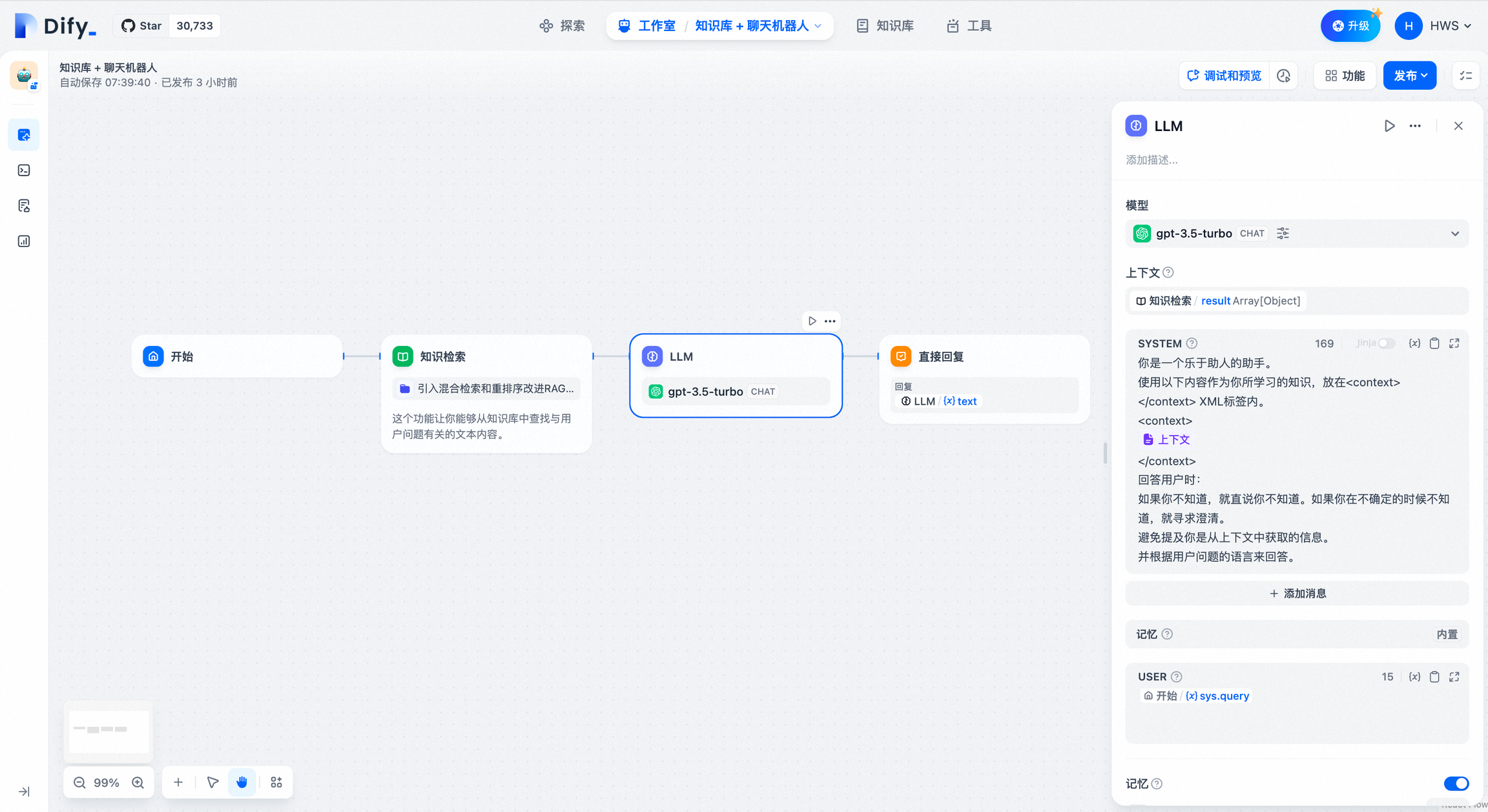
该变量除了可以作为 LLM 回复问题时的提示词上下文作为外部知识参考引用,另外由于其数据结构中包含了分段引用信息,同时可以支持应用端的 引用与归属 功能。
6.问题分类
通过定义分类描述,问题分类器能够根据用户输入推理与之相匹配的分类并输出分类结果。
2 场景
常见的使用情景包括对话意图分类、产品评价分类、邮件批量分类等。
在一个典型的产品客服问答场景中,问题分类器可以作为知识库检索的前置步骤,对用户输入问题意图进行分类处理,分类后导向下游不同的知识库查询相关的内容,以精确回复用户的问题。
在该场景中我们设置了 3 个分类标签/描述:
- 分类 1 :与售后相关的问题
- 分类 2:与产品操作使用相关的问题
- 分类 3 :其他问题
当用户输入不同的问题时,问题分类器会根据已设置的分类标签/描述自动完成分类:
- “iPhone 14 如何设置通讯录联系人?” —> “与产品操作使用相关的问题”
- “保修期限是多久?” —> “与售后相关的问题”
- “今天天气怎么样?” —> “其他问题”
- 如何配置
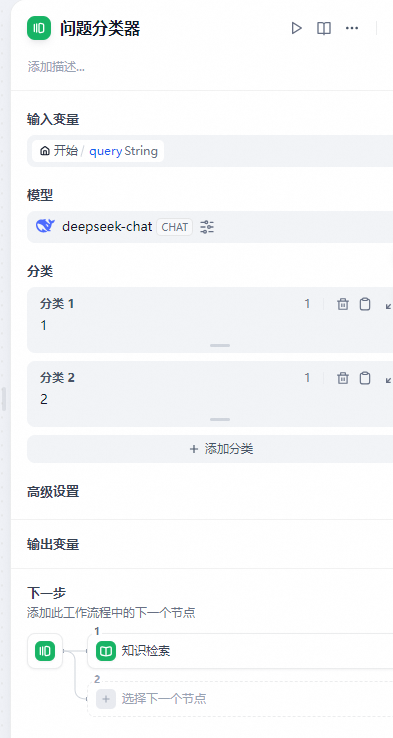
配置步骤:
- 选择输入变量,指用于分类的输入内容,客服问答场景下一般为用户输入的问题
sys.query; - 选择推理模型,问题分类器基于大语言模型的自然语言分类和推理能力,选择合适的模型将有助于提升分类效果;
- 编写分类标签/描述,你可以手动添加多个分类,通过编写分类的关键词或者描述语句,让大语言模型更好的理解分类依据。
- 选择分类对应的下游节点,问题分类节点完成分类之后,可以根据分类与下游节点的关系选择后续的流程路径。
- 选择输入变量,指用于分类的输入内容,客服问答场景下一般为用户输入的问题
高级设置:
- 指令:你可以在 高级设置-指令 里补充附加指令,比如更丰富的分类依据,以增强问题分类器的分类能力。
- 记忆:开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
- 记忆窗口:记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
- 输出变量::
class_name
即分类之后输出的分类名。你可以在下游节点需要时使用分类结果变量。
7.条件分支
根据 if/else/elif 条件将 workflow 拆分成多个分支。条件分支节点有六个部分:
- IF 条件:选择变量,设置条件和满足条件的值;
- IF 条件判断为
True,执行 IF 路径; - IF 条件判断为
False,执行 ELSE 路径; - ELIF 条件判断为
True,执行 ELIF 路径; - ELIF 条件判断为
False,继续判断下一个 ELIF 路径或执行最后的 ELSE 路径;
条件类型
- 包含(Contains)
- 不包含(Not contains)
- 开始是(Start with)
- 结束是(End with)
- 是(Is)
- 不是(Is not)
- 为空(Is empty)
- 不为空(Is not empty)
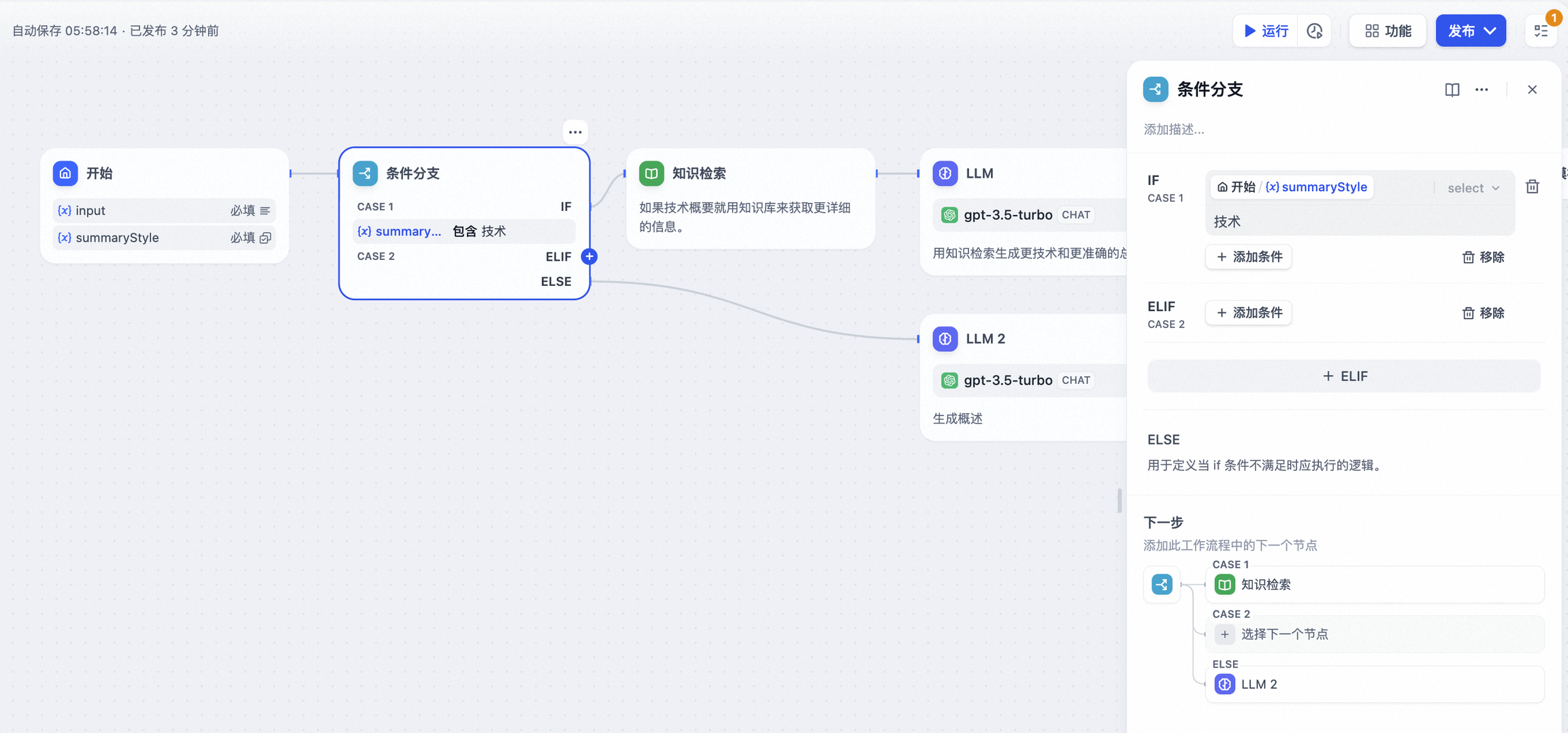
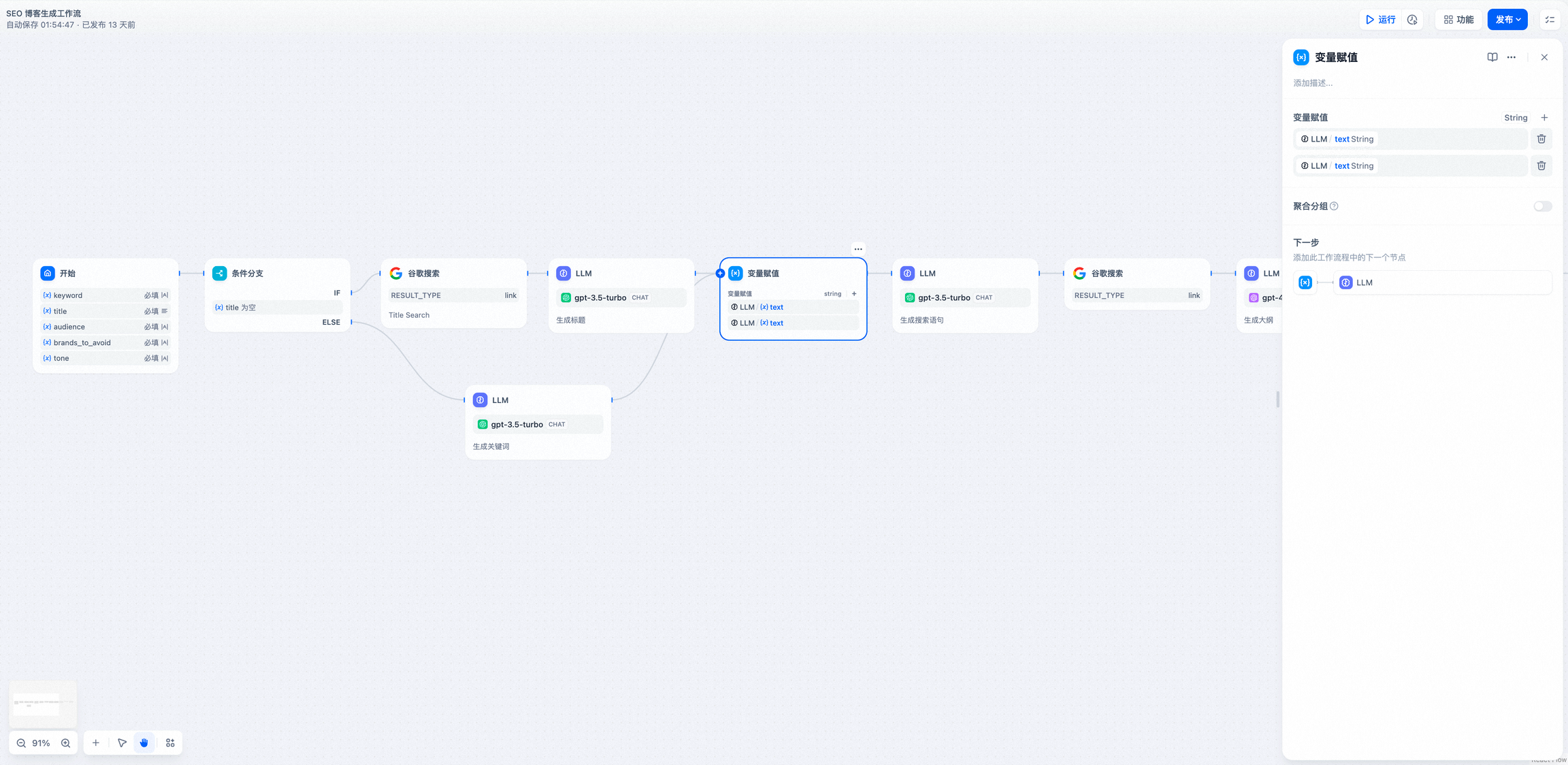
以文本总结工作流作为示例说明各个条件:
- IF 条件: 选择开始节点中的
summarystyle变量,条件为包含技术; - IF 条件判断为
True,执行 IF 路径,通过知识检索节点查询技术相关知识再到 LLM 节点回复(图中上半部分); - IF 条件判断为
False,但添加了ELIF条件,即summarystyle变量输入不包含技术,但ELIF条件内包含科技,会检查ELIF内的条件是否为True,然后执行路径内定义的步骤; ELIF内的条件为False,即输入变量既不不包含技术,也不包含科技,继续判断下一个 ELIF 路径或执行最后的 ELSE 路径;- IF 条件判断为
False,即summarystyle变量输入不包含技术,执行 ELSE 路径,通过 LLM2 节点进行回复(图中下半部分);
多重条件判断
涉及复杂的条件判断时,可以设置多重条件判断,在条件之间设置 AND 或者 OR,即在条件之间取交集或者并集。

8.代码执行
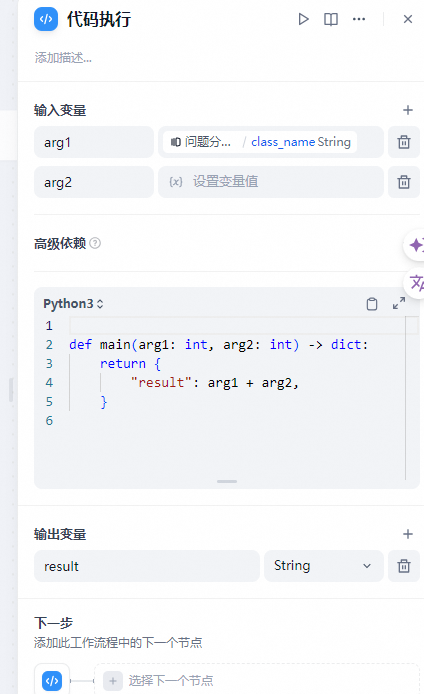
代码节点支持运行 Python / NodeJS 代码以在工作流程中执行数据转换。它可以简化您的工作流程,适用于 Arithmetic、JSON transform、文本处理等情景。
该节点极大地增强了开发人员的灵活性,使他们能够在工作流程中嵌入自定义的 Python 或 Javascript 脚本,并以预设节点无法达到的方式操作变量。通过配置选项,你可以指明所需的输入和输出变量,并撰写相应的执行代码:
- 结构化数据处理
在工作流中,经常要面对非结构化的数据处理,如 JSON 字符串的解析、提取、转换等。最典型的例子就是 HTTP 节点的数据处理,在常见的 API 返回结构中,数据可能会被嵌套在多层 JSON 对象中,而我们需要提取其中的某些字段。代码节点可以帮助您完成这些操作,下面是一个简单的例子,它从 HTTP 节点返回的 JSON 字符串中提取了data.name字段:
复制
def main(http_response: str) -> str:
import json
data = json.loads(http_response)
return {
#注意在输出变量中声明result
'result': data['data']['name']
}
- 数学计算
当工作流中需要进行一些复杂的数学计算时,也可以使用代码节点。例如,计算一个复杂的数学公式,或者对数据进行一些统计分析。下面是一个简单的例子,它计算了一个数组的平方差:
def main(x: list) -> float:
return {
#注意在输出变量中声明result
'result' : sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
}
- 拼接数据
有时,也许您需要拼接多个数据源,如多个知识检索、数据搜索、API 调用等,代码节点可以帮助您将这些数据源整合在一起。下面是一个简单的例子,它将两个知识库的数据合并在一起:
复制
def main(knowledge1: list, knowledge2: list) -> list:
return {
#注意在输出变量中声明result
'result': knowledge1 + knowledge2
}
如果是本地部署的用户,需要启动一个沙盒服务,它会确保恶意代码不会被执行,同时,启动该服务需要使用 Docker 服务,可以在这里找到 Sandbox 服务的具体信息,您也可以直接通过docker-compose启动服务:
docker-compose -f docker-compose.middleware.yaml up -d
如果您的系统安装了 Docker Compose V2 而不是 V1,请使用
docker compose而不是docker-compose。通过$ docker compose version检查这是否为情况。无论是 Python 还是 Javascript,它们的执行环境都被严格隔离(沙箱化),以确保安全性。这意味着开发者不能使用那些消耗大量系统资源或可能引发安全问题的功能,如直接访问文件系统、进行网络请求或执行操作系统级别的命令。这些限制保证了代码的安全执行,同时避免了对系统资源的过度消耗。
9. Jinja2模板转换
允许借助 Jinja2 的 Python 模板语言灵活地进行数据转换、文本处理等。
Jinja 是一个快速、表达力强、可扩展的模板引擎。
—— https://jinja.palletsprojects.com/en/3.1.x/
模板节点允许你借助 Jinja2 这一强大的 Python 模板语言,在工作流内实现轻量、灵活的数据转换,适用于文本处理、JSON 转换等情景。例如灵活地格式化并合并来自前面步骤的变量,创建出单一的文本输出。这非常适合于将多个数据源的信息汇总成一个特定格式,满足后续步骤的需求。
示例 1:将多个输入(文章标题、介绍、内容)拼接为完整文本
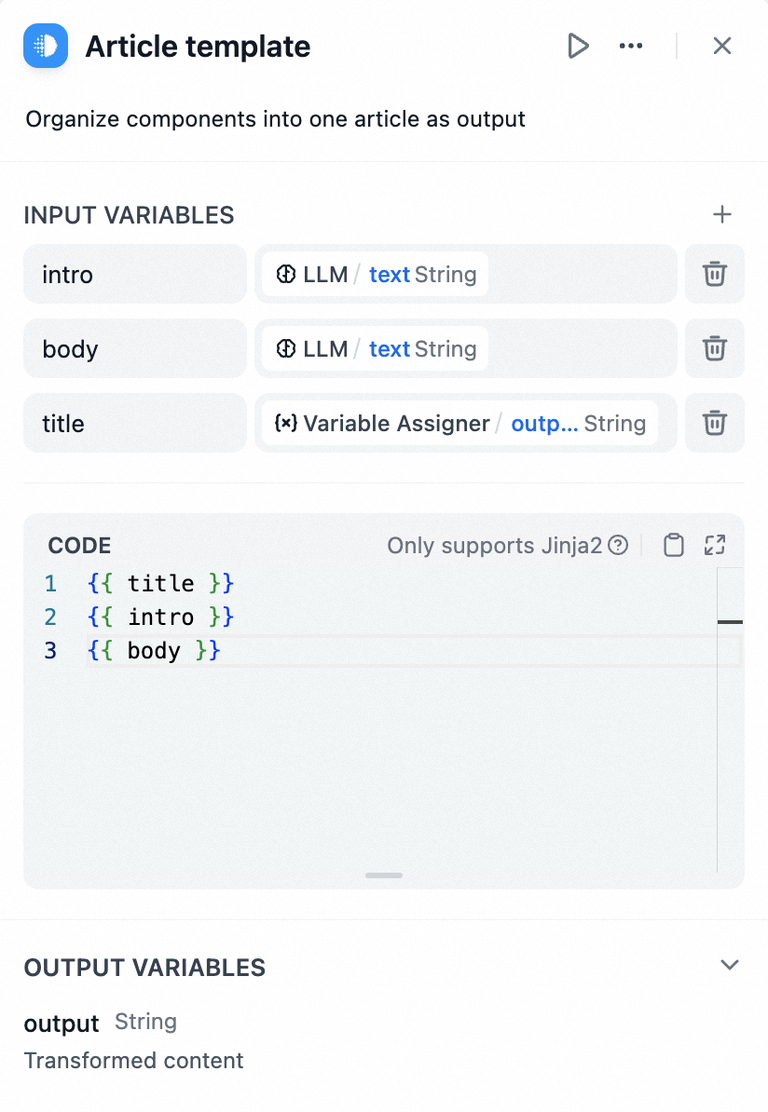
示例 2:将知识检索节点获取的信息及其相关的元数据,整理成一个结构化的 Markdown 格式
{% for item in chunks %}
###Chunk {{ loop.index }}.
###Similarity: {{ item.metadata.score | default('N/A') }}
####{ item.title }}
#####Content
{{ item.content | replace('\n', '\n\n') }}
---
{% endfor %}
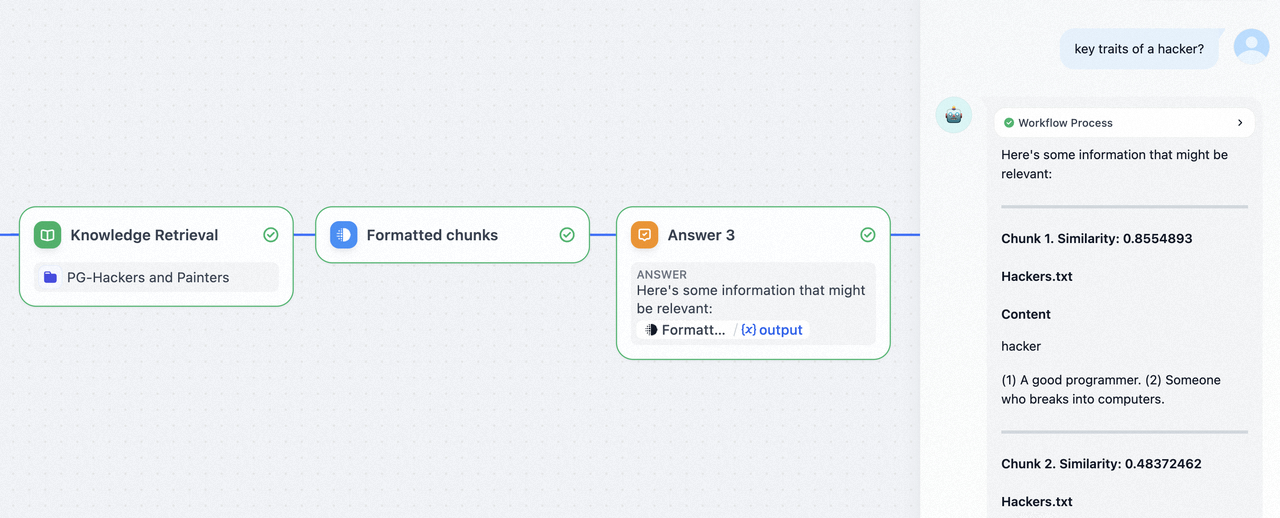
知识检索节点输出转换为 Markdown,可以参考 Jinja 的官方文档,创建更为复杂的模板来执行各种任务。
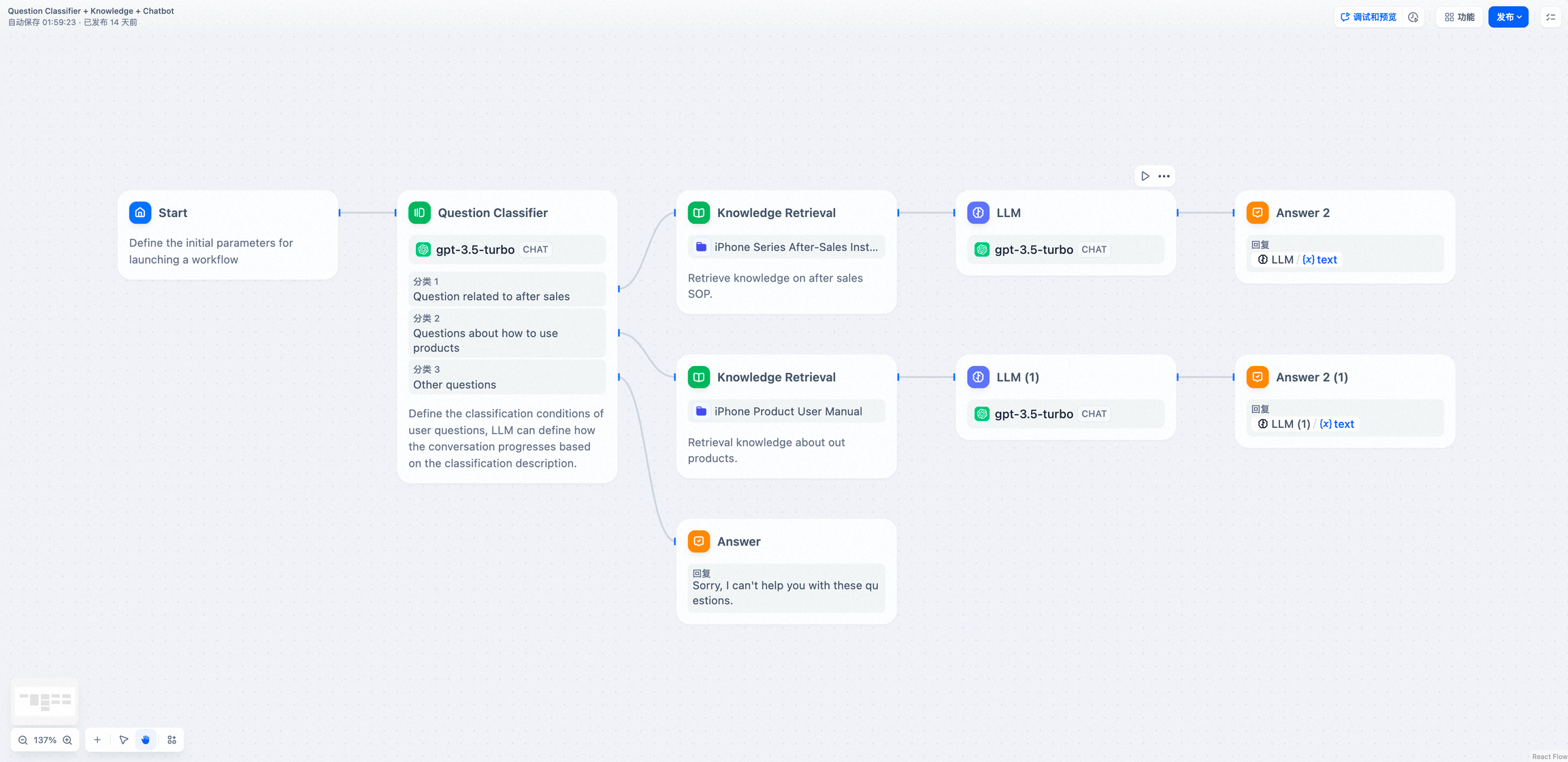
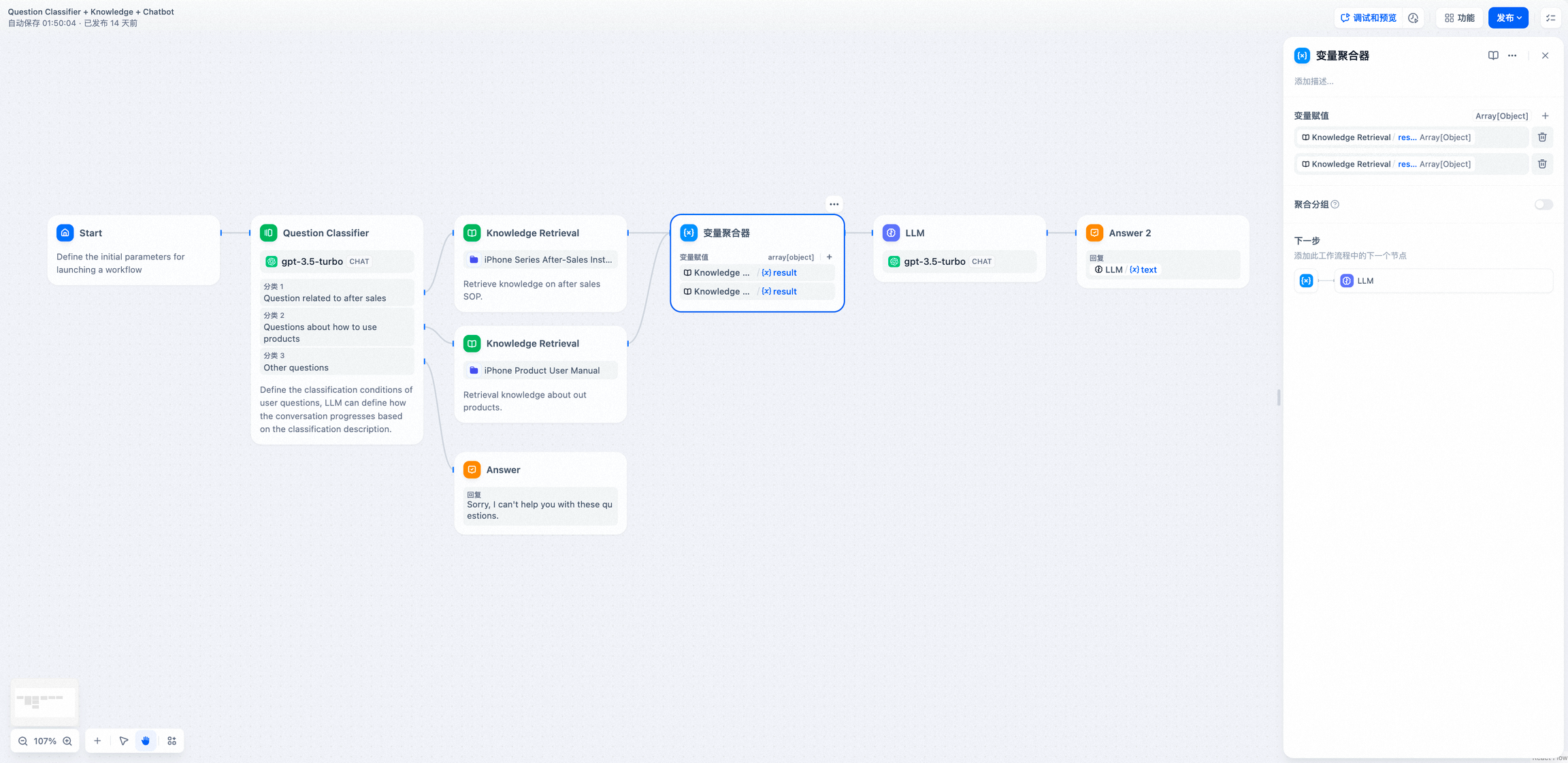
10.变量聚合
将多路分支的变量聚合为一个变量,以实现下游节点统一配置。变量聚合节点(原变量赋值节点)是工作流程中的一个关键节点,它负责整合不同分支的输出结果,确保无论哪个分支被执行,其结果都能通过一个统一的变量来引用和访问。这在多分支的情况下非常有用,可将不同分支下相同作用的变量映射为一个输出变量,避免下游节点重复定义。
通过变量聚合,可以将诸如问题分类或条件分支等多路输出聚合为单路,供流程下游的节点使用和操作,简化了数据流的管理。
问题分类后的多路聚合
- 未添加变量聚合,分类 1 和 分类 2 分支经不同的知识库检索后需要重复定义下游的 LLM 和直接回复节点。
- 添加变量聚合,可以将两个知识检索节点的输出聚合为一个变量。
- IF/ELSE 条件分支后的多路聚合
- 格式要求
变量聚合器支持聚合多种数据类型,包括字符串(String)、数字(Number)、对象(Object)以及数组(Array)。
变量聚合器只能聚合同一种数据类型的变量。若第一个添加至变量聚合节点内的变量数据格式为 String,后续连线时会自动过滤可添加变量为 String 类型。
聚合分组
v0.6.10 版本之后已支持聚合分组。开启聚合分组后,变量聚合器可以聚合多组变量,各组内聚合时要求同一种数据类型。
11.变量赋值
变量赋值节点用于向可写入变量进行变量赋值,已支持以下可写入变量:
用法:通过变量赋值节点,你可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。
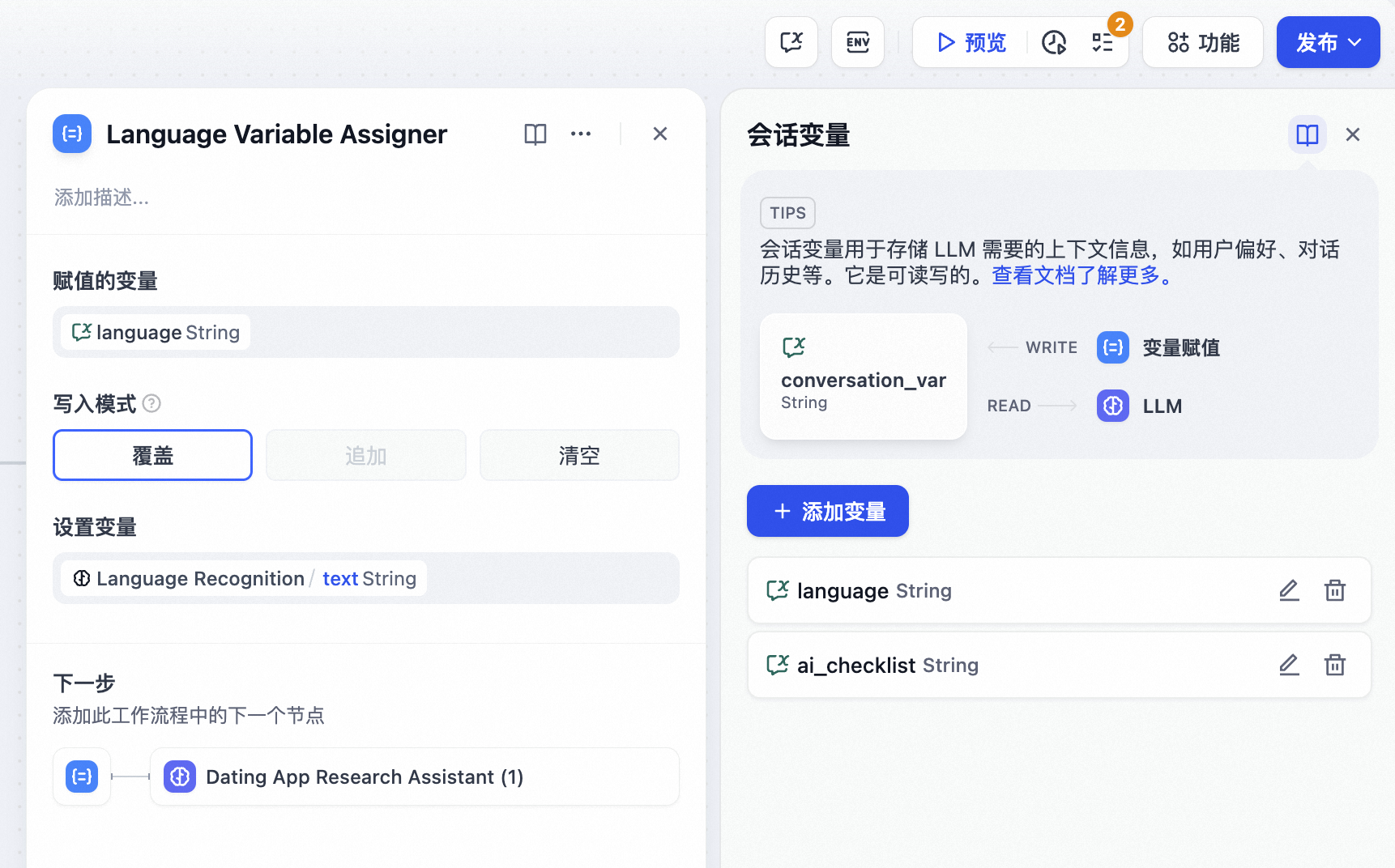
- 使用场景示例:通过变量赋值节点,你可以将会话过程中的上下文、上传至对话框的文件(即将上线)、用户所输入的偏好信息等写入至会话变量,并在后续对话中引用已存储的信息导向不同的处理流程或者进行回复。
- 场景 1
自动判断提取并存储对话中的信息,在会话内通过会话变量数组记录用户的重要信息,并在后续对话中使用这些历史信息来个性化回复。
示例:开始对话后,LLM 会自动判断用户输入中是否包含需要记住的事实、偏好或历史记录。如果有,LLM 会先提取并存储这些信息,然后再用这些信息作为上下文来回答。如果没有新的信息需要保存,LLM 会直接使用之前相关的记忆来回答问题。
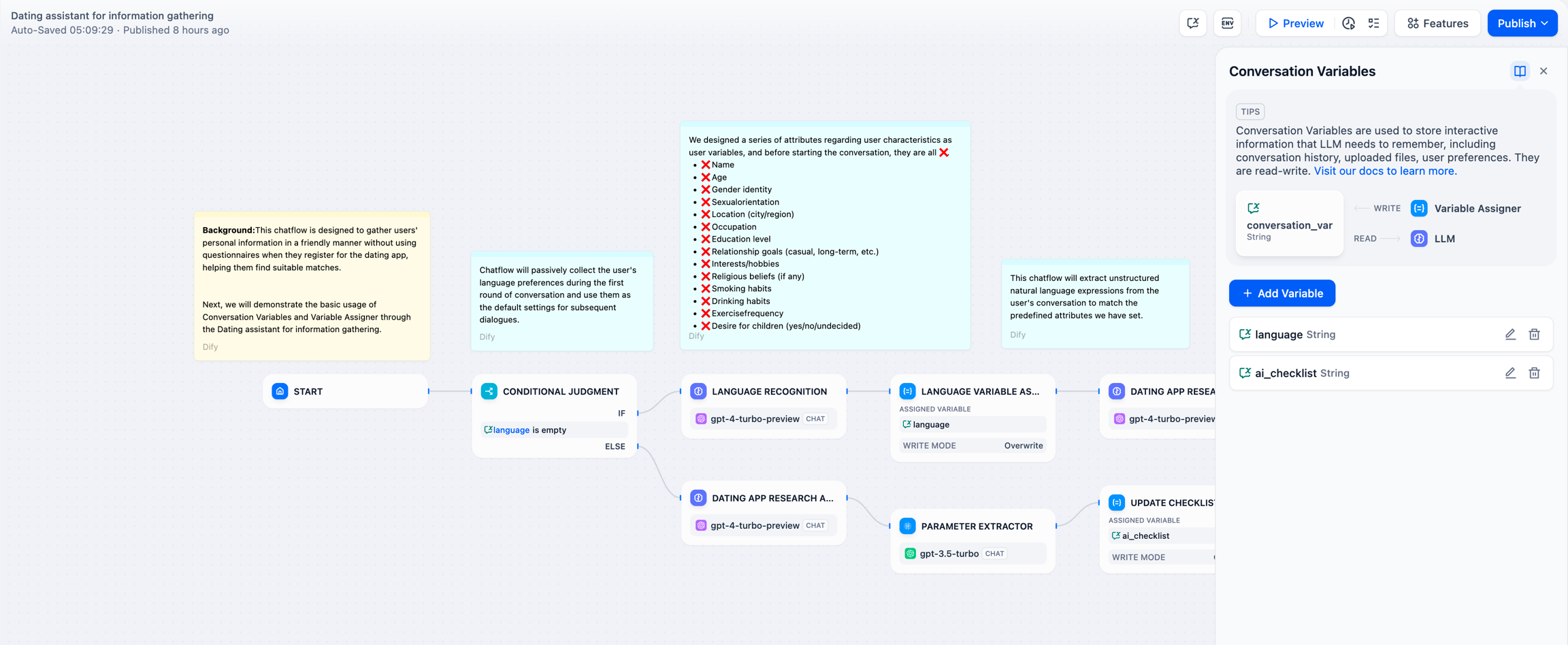
配置流程:
- 设置会话变量:首先设置一个会话变量数组
memories,类型为 array[object],用于存储用户的事实、偏好和历史记录。 判断和提取记忆:
- 添加一个条件判断节点,使用 LLM 来判断用户输入是否包含需要记住的新信息。
- 如果有新信息,走上分支,使用 LLM 节点提取这些信息。
- 如果没有新信息,走下分支,直接使用现有记忆回答。
变量赋值 / 写入:
- 在上分支中,使用变量赋值节点,将提取出的新信息追加(append)到
memories数组中。 - 使用转义功能将 LLM 输出的文本字符串转换为适合存储在 array[object] 中的格式。
- 在上分支中,使用变量赋值节点,将提取出的新信息追加(append)到
变量读取和使用:
- 在后续的 LLM 节点中,将
memories数组中的内容转换为字符串,并插入到 LLM 的提示中作为上下文。 - LLM 使用这些记忆来生成个性化的回复。
- 在后续的 LLM 节点中,将
图中的 code 节点代码如下:
- 将字符串转义为 object
复制
import json
def main(arg1: str) -> object:
try:
# Parse the input JSON string
input_data = json.loads(arg1)
# Extract the memory object
memory = input_data.get("memory", {})
# Construct the return object
result = {
"facts": memory.get("facts", []),
"preferences": memory.get("preferences", []),
"memories": memory.get("memories", [])
}
return {
"mem": result
}
except json.JSONDecodeError:
return {
"result": "Error: Invalid JSON string"
}
except Exception as e:
return {
"result": f"Error: {str(e)}"
}
- 将 object 转义为字符串
复制
import json
def main(arg1: list) -> str:
try:
# Assume arg1[0] is the dictionary we need to process
context = arg1[0] if arg1 else {}
# Construct the memory object
memory = {"memory": context}
# Convert the object to a JSON string
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
# Wrap the JSON string in <answer> tags
result = f"<answer>{json_str}</answer>"
return {
"result": result
}
except Exception as e:
return {
"result": f"<answer>Error: {str(e)}</answer>"
}
- 场景 2
记录用户的初始偏好信息,在会话内记住用户输入的语言偏好,在后续对话中持续使用该语言类型进行回复。
示例:用户在对话开始前,在 language 输入框内指定了 “中文”,该语言将会被写入会话变量,LLM 在后续进行答复时会参考会话变量中的信息,在后续对话中持续使用 “中文” 进行回复。
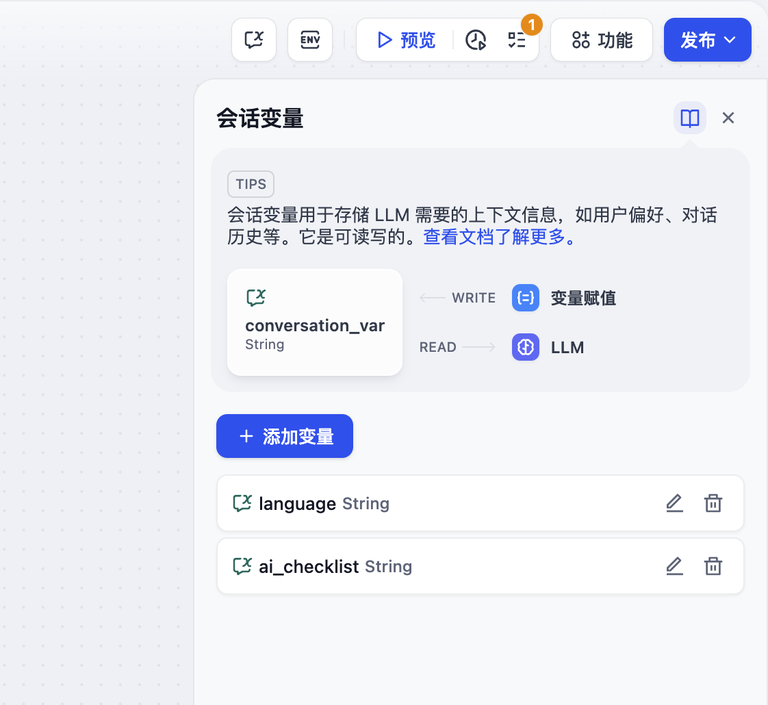
配置流程:
设置会话变量:首先设置一个会话变量 language,在会话流程开始时添加一个条件判断节点,用来判断 language 变量的值是否为空。
变量写入 / 赋值:首轮对话开始时,若 language 变量值为空,则使用 LLM 节点来提取用户输入的语言,再通过变量赋值节点将该语言类型写入到会话变量 language 中。
变量读取:在后续对话轮次中 language 变量已存储用户语言偏好。在后续对话中,LLM 节点通过引用 language 变量,使用用户的偏好语言类型进行回复。
- 场景 3
辅助 Checklist 检查,在会话内通过会话变量记录用户的输入项,更新 Checklist 中的内容,并在后续对话中检查遗漏项。
示例:开始对话后,LLM 会要求用户在对话框内输入 Checklist 所涉及的事项,用户一旦提及了 Checklist 中的内容,将会更新并存储至会话变量内。LLM 会在每轮对话后提醒用户继续补充遗漏项。
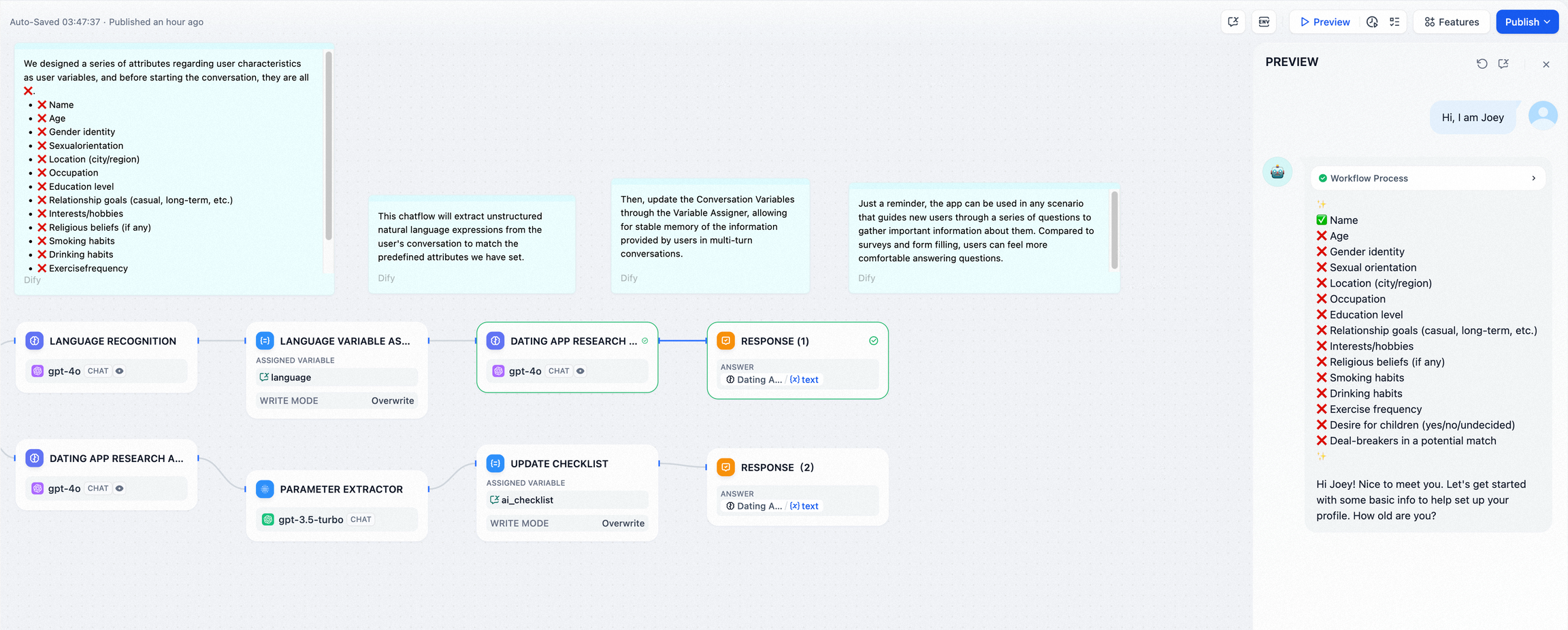
配置流程:
- 设置会话变量: 首先设置一个会话变量
ai_checklist,在 LLM 内引用该变量作为上下文进行检查。 - 变量赋值 / 写入: 每一轮对话时,在 LLM 节点内检查
ai_checklist内的值并比对用户输入,若用户提供了新的信息,则更新 Checklist 并将输出内容通过变量赋值节点写入到ai_checklist内。 - 变量读取: 每一轮对话读取
ai_cheklist内的值并比对用户输入直至所有 checklist 完成。
- 使用变量赋值节点
点击节点右侧 + 号,选择 “变量赋值” 节点,填写 “赋值的变量” 和“设置变量”。
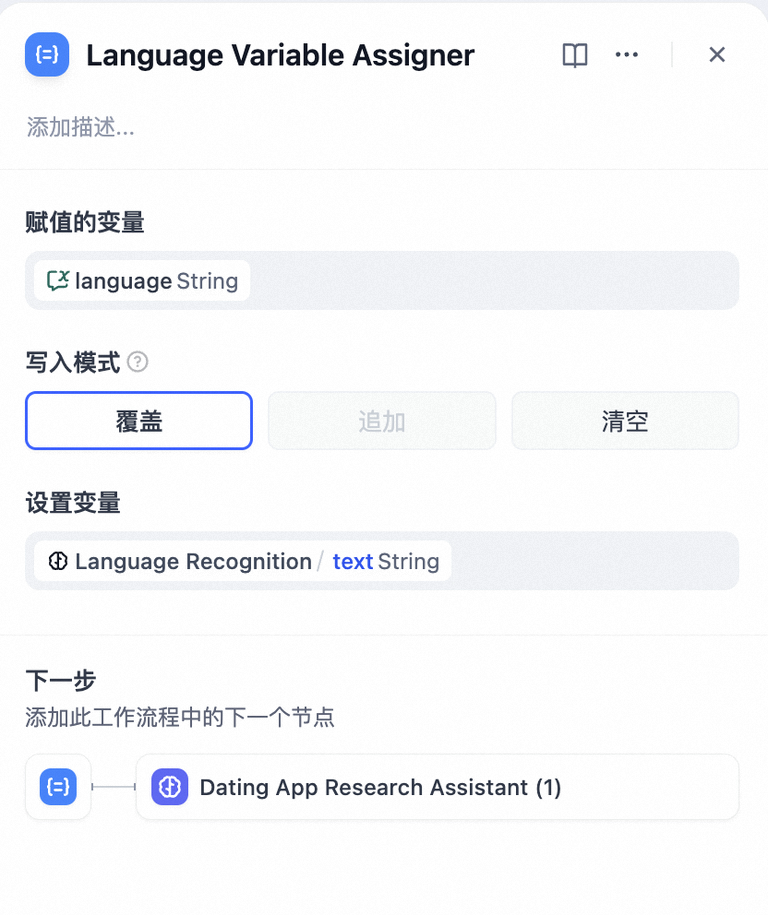
设置变量:
赋值的变量:选择被赋值变量,即指定需要被赋值的目标会话变量。
设置变量:选择需要赋值的变量,即指定需要被转换的源变量。
以上图赋值逻辑为例:将上一个节点的文本输出项 Language Recognition/text 赋值到会话变量 language 内。
写入模式:
- 覆盖,将源变量的内容覆盖至目标会话变量
- 追加,指定变量为 Array 类型时
- 清空,清空目标会话变量中的内容
12 参数迭代
利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。
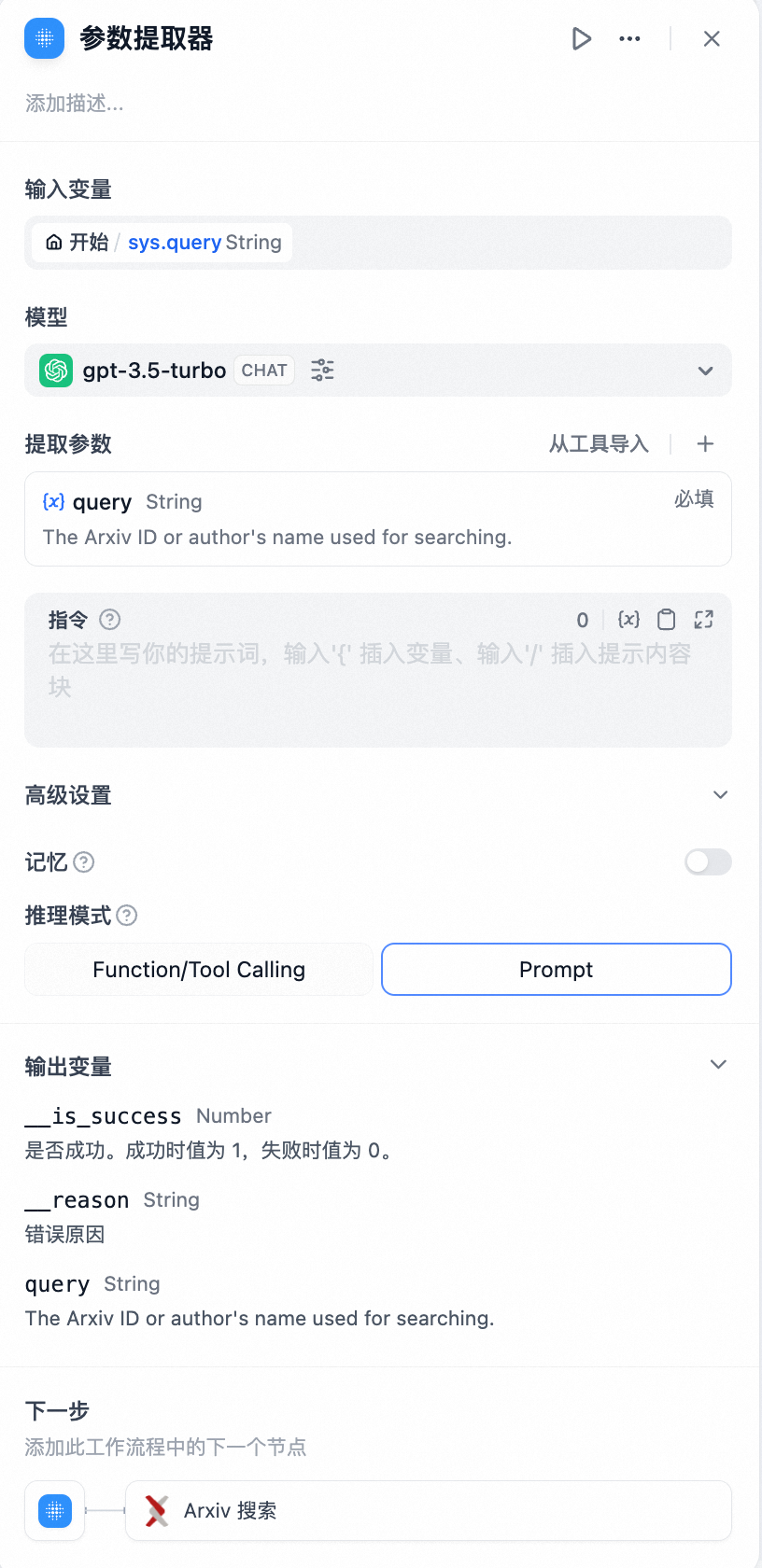
Dify 工作流内提供了丰富的[工具]选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
工作流内的部分节点有特定的数据格式传入要求,如[迭代]节点的输入要求为数组格式,参数提取器可以方便的实现[结构化参数的转换]。
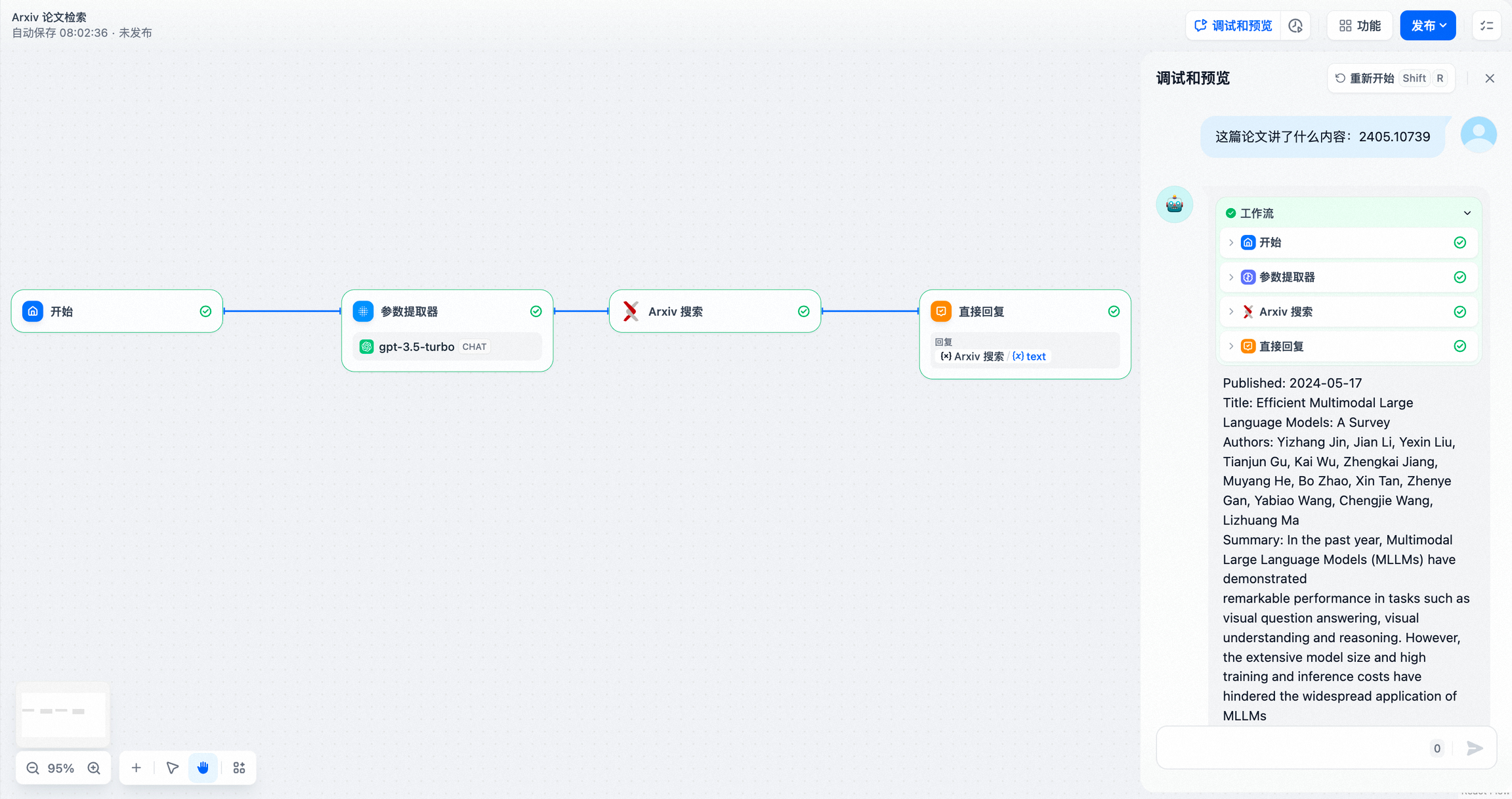
- 从自然语言中提供工具所需的关键参数提取,如构建一个简单的对话式 Arxiv 论文检索应用。
在该示例中:Arxiv 论文检索工具的输入参数要求为 论文作者 或 论文编号,参数提取器从问题 “这篇论文中讲了什么内容:2405.10739” 中提取出论文编号 2405.10739,并作为工具参数进行精确查询。
- 将文本转换为结构化数据,如长故事迭代生成应用中,作为[迭代节点]的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理
- 提取结构化数据并使用 [HTTP 请求] ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
配置步骤
- 选择输入变量,一般为用于提取参数的变量输入
- 选择模型,参数提取器的提取依靠的是 LLM 的推理和结构化生成能力
- 定义提取参数,可以手动添加需要提取的参数,也可以从已有工具中快捷导入
- 编写指令,在提取复杂的参数时,编写示例可以帮助 LLM 提升生成的效果和稳定性
高级设置
推理模式
部分模型同时支持两种推理模式,通过函数 / 工具调用或是纯提示词的方式实现参数提取,在指令遵循能力上有所差别。例如某些模型在函数调用效果欠佳的情况下可以切换成提示词推理。
- Function Call/Tool Call
- Prompt
记忆
开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
输出变量
- 提取定义的变量
- 节点内置变量
__is_success Number 提取是否成功 成功时值为 1,失败时值为 0。
__reason String 提取错误原因
13.HTTP 请求
允许通过 HTTP 协议发送服务器请求,适用于获取外部数据、webhook、生成图片、下载文件等情景。它让你能够向指定的网络地址发送定制化的 HTTP 请求,实现与各种外部服务的互联互通。
该节点支持常见的 HTTP 请求方法:
- GET,用于请求服务器发送某个资源。
- POST,用于向服务器提交数据,通常用于提交表单或上传文件。
- HEAD,类似于 GET 请求,但服务器不返回请求的资源主体,只返回响应头。
- PATCH,用于在请求 - 响应链上的每个节点获取传输路径。
- PUT,用于向服务器上传资源,通常用于更新已存在的资源或创建新的资源。
- DELETE,用于请求服务器删除指定的资源。
你可以通过配置 HTTP 请求的包括 URL、请求头、查询参数、请求体内容以及认证信息等。
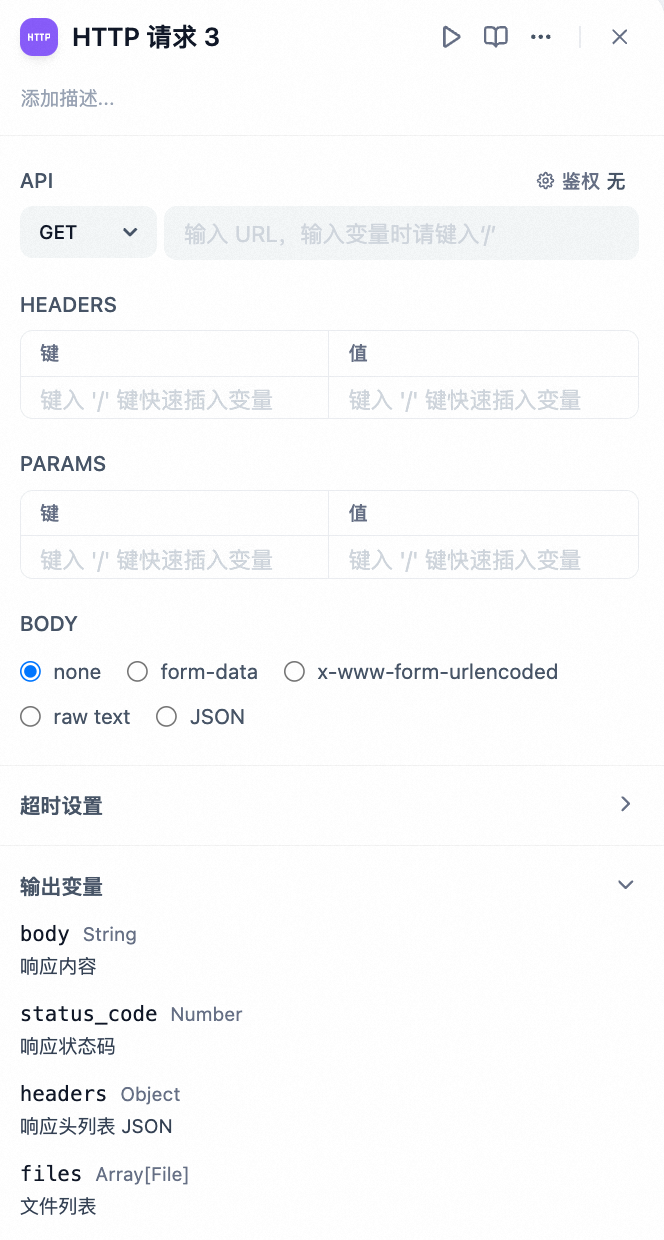
- HTTP 请求配置
这个节点的一个实用特性是能够根据场景需要,在请求的不同部分动态插入变量。比如在处理客户评价请求时,你可以将用户名或客户 ID、评价内容等变量嵌入到请求中,以定制化自动回复信息或获取特定客户信息并发送相关资源至特定的服务器。
- 客户评价分类
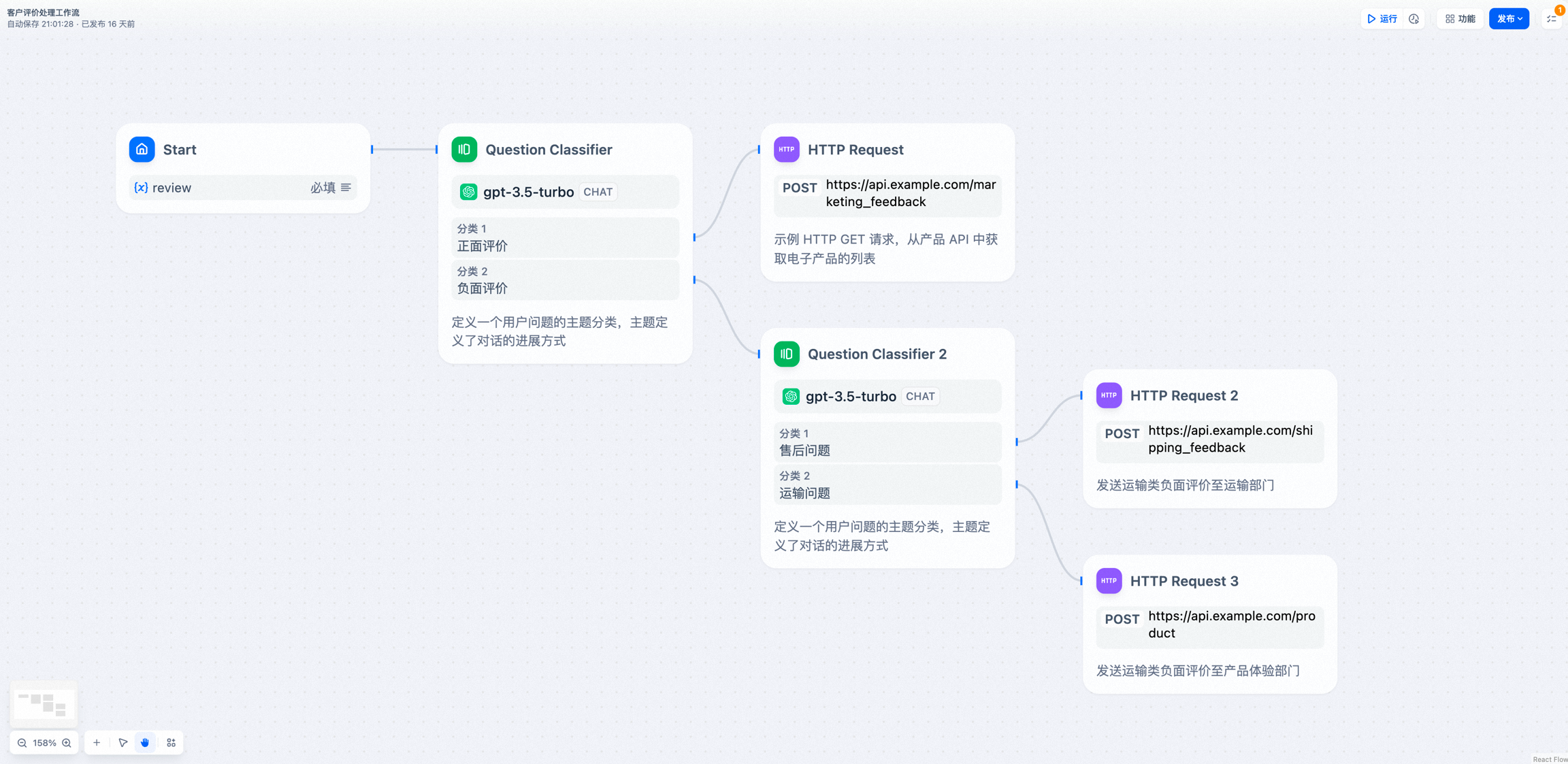
HTTP 请求的返回值包括响应体、状态码、响应头和文件。值得注意的是,如果响应中包含了文件(目前仅支持图片类型),这个节点能够自动将文件保存下来,供流程后续步骤使用。这样的设计不仅提高了处理效率,也使得处理带有文件的响应变得简单直接。
14 .迭代
迭代步骤在列表中的每个条目(item)上执行相同的步骤。使用迭代的条件是确保输入值已经格式化为列表对象。迭代节点允许 AI 工作流处理更复杂的处理逻辑,迭代节点是循环节点的友好版本,它在自定义程度上做出了一些妥协,以便非技术用户能够快速入门。
- 示例 1:长文章迭代生成器
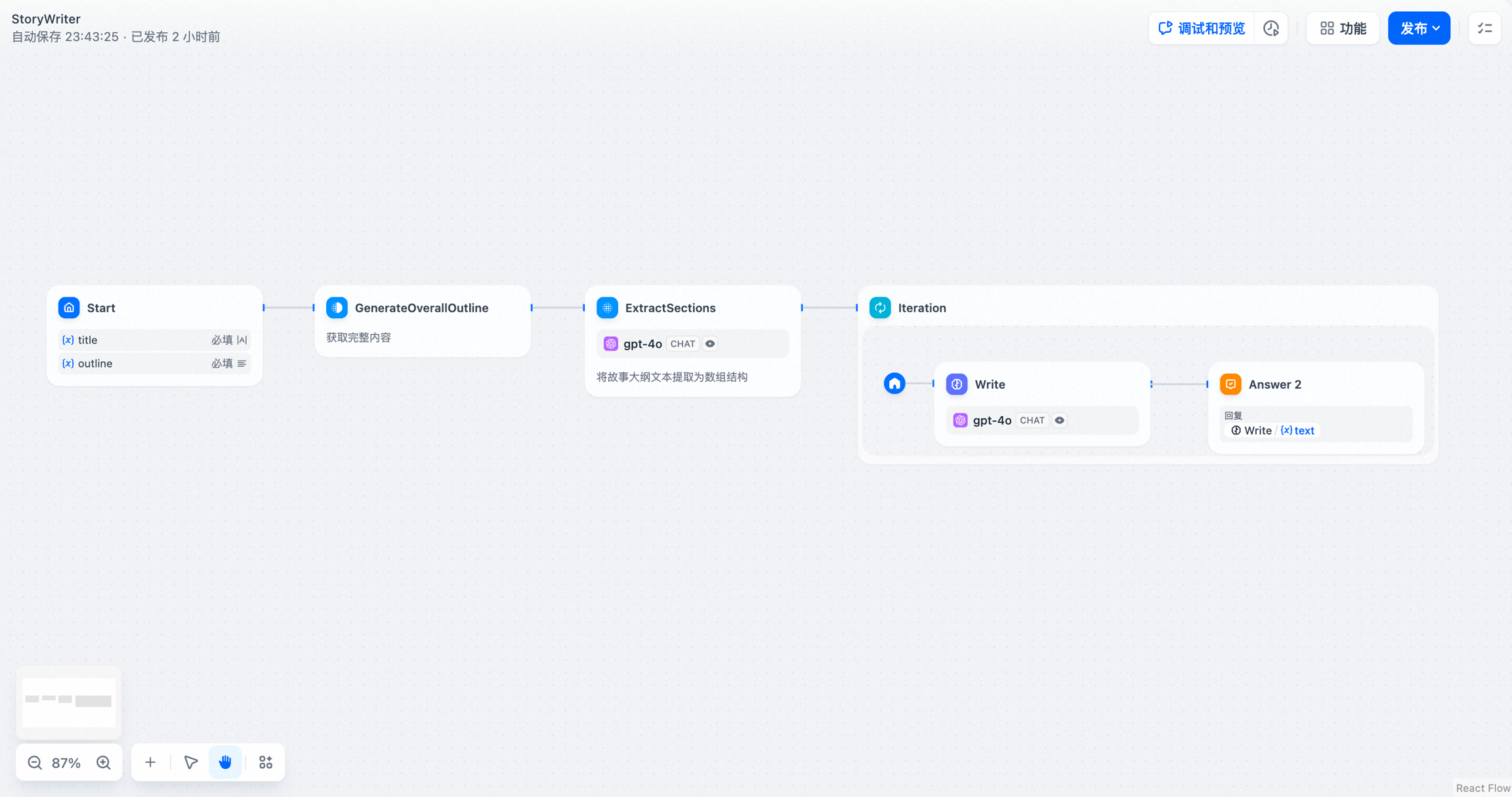
长故事生成器
- 在 开始节点 内输入故事标题和大纲
- 使用 代码节点 从用户输入中提取出完整内容
- 使用 参数提取节点 将完整内容转换成数组格式
- 通过 迭代节点 包裹的 LLM 节点 循环多次生成各章节内容
- 将 直接回复 节点添加在迭代节点内部,实现在每轮迭代生成之后流式输出
具体配置步骤
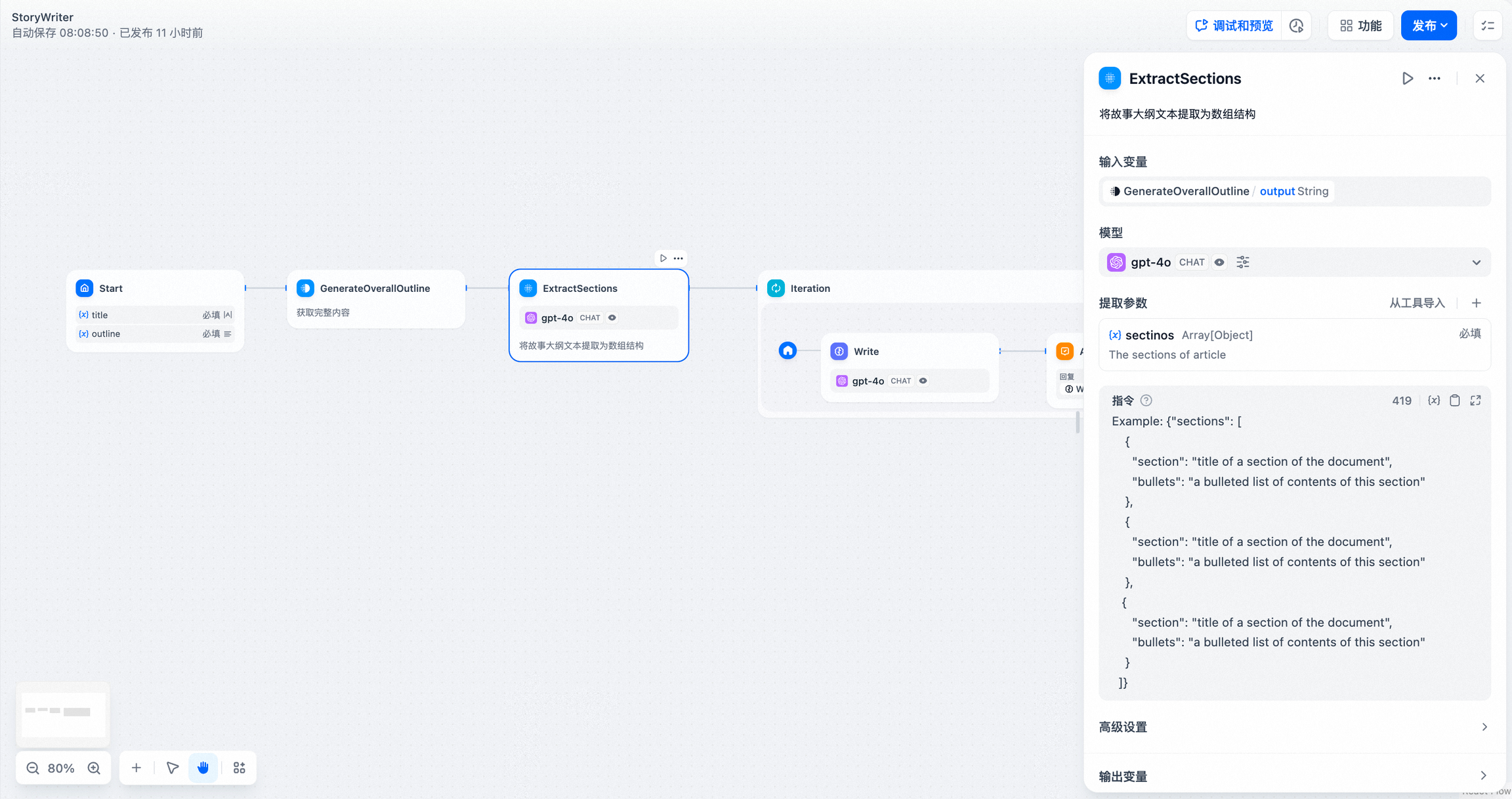
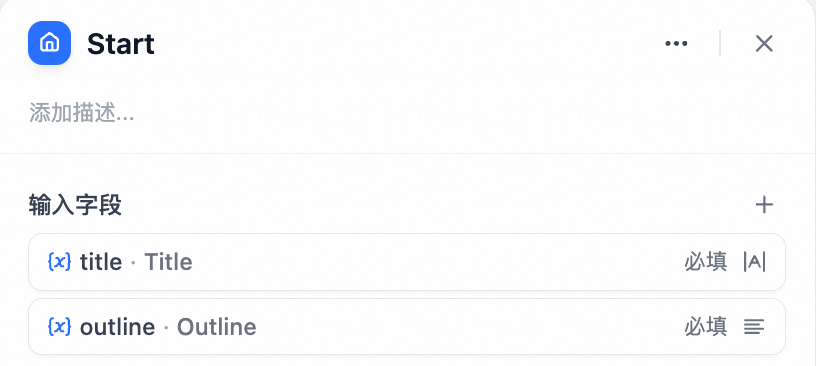
- 在 开始节点 配置故事标题(title)和大纲(outline);
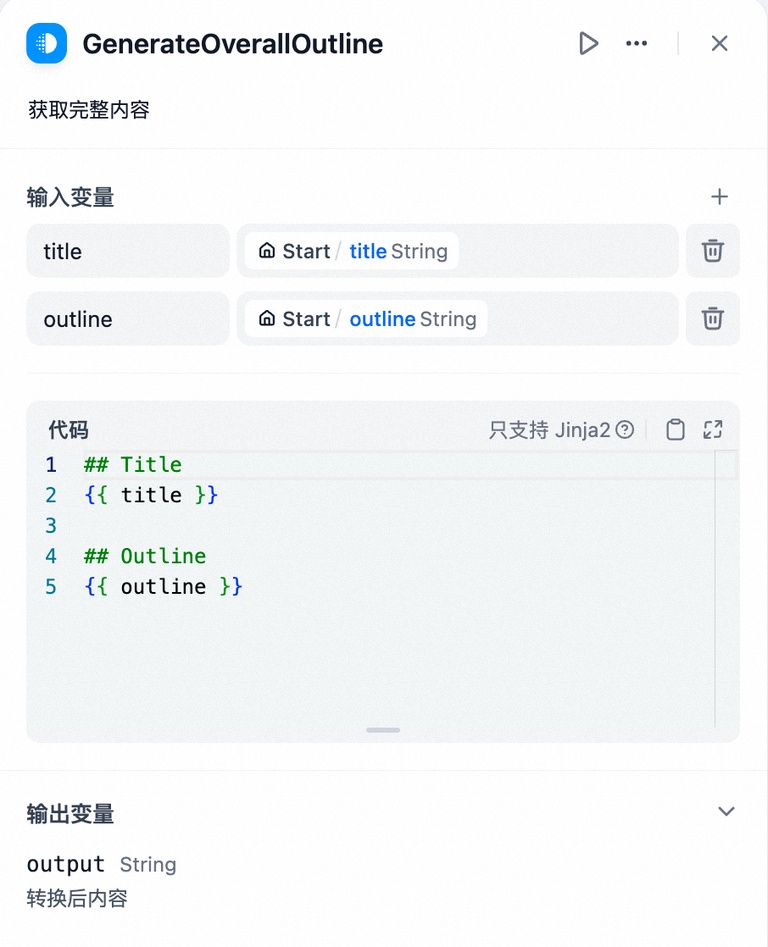
- 通过 Jinja-2 模板节点 将故事标题与大纲转换为完整文本;
- 通过 参数提取节点,将故事文本转换成为数组(Array)结构。提取参数为
sections,参数类型为Array[Object]

参数提取效果受模型推理能力和指令影响,使用推理能力更强的模型,在指令内增加示例可以提高参数提取的效果。
- 将数组格式的故事大纲作为迭代节点的输入,在迭代节点内部使用 LLM 节点 进行处理
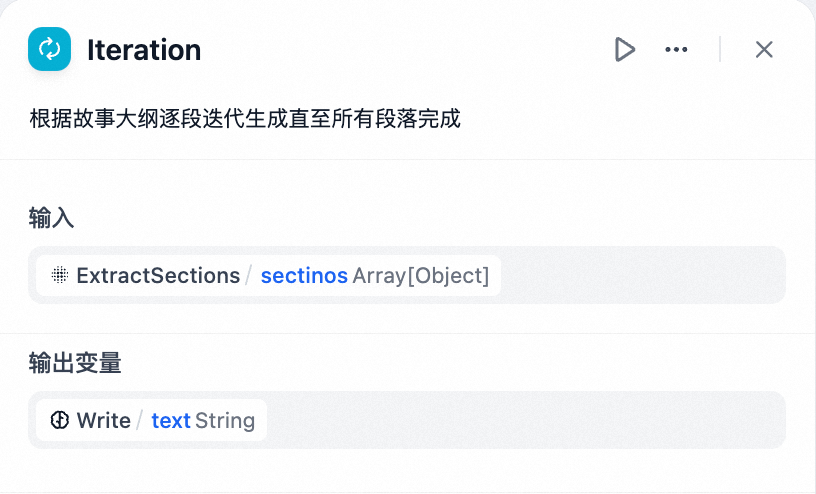
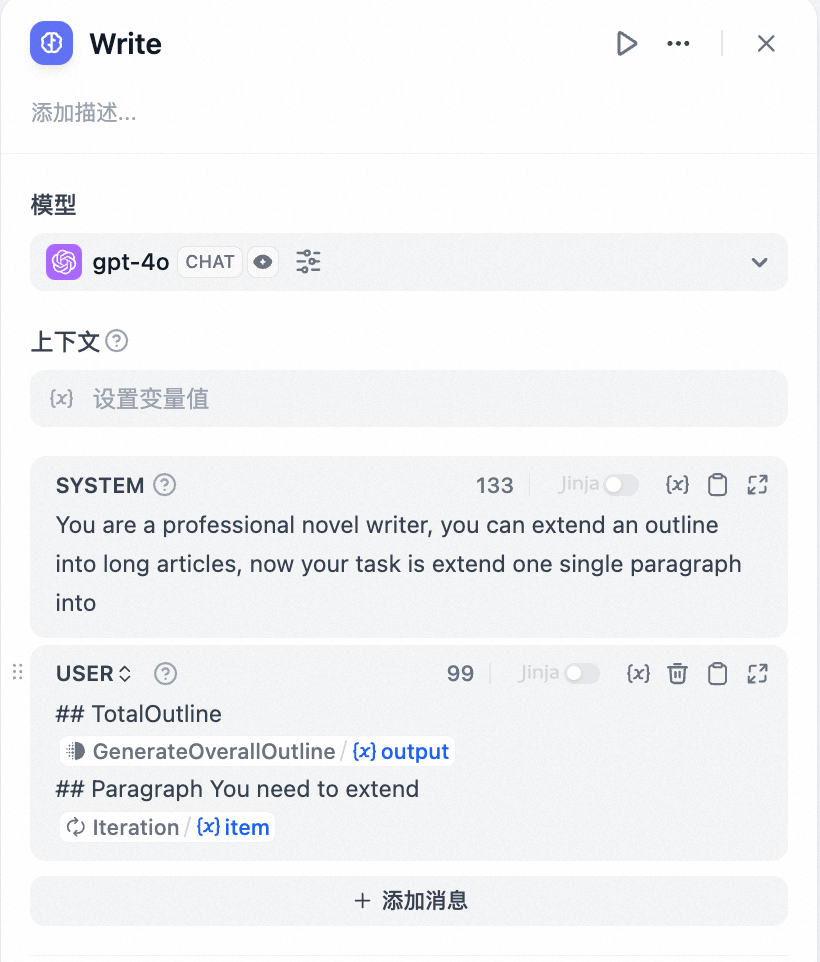
在 LLM 节点内配置输入变量 GenerateOverallOutline/output 和 Iteration/item
迭代的内置变量:items[object] 和 index[number]
items[object] 代表以每轮迭代的输入条目;
index[number] 代表当前迭代的轮次;
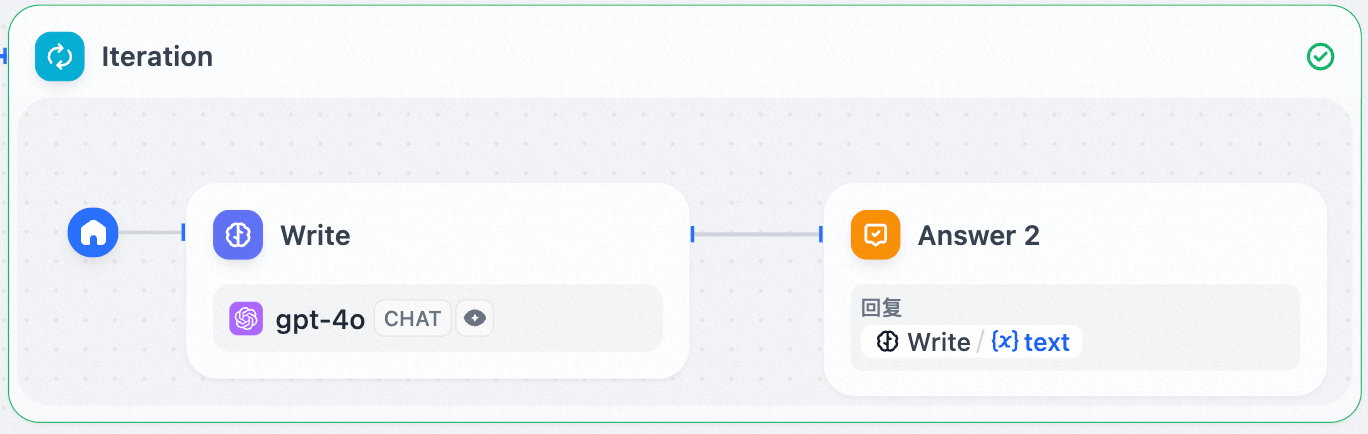
- 在迭代节点内部配置 直接回复节点 ,可以实现在每轮迭代生成之后流式输出。
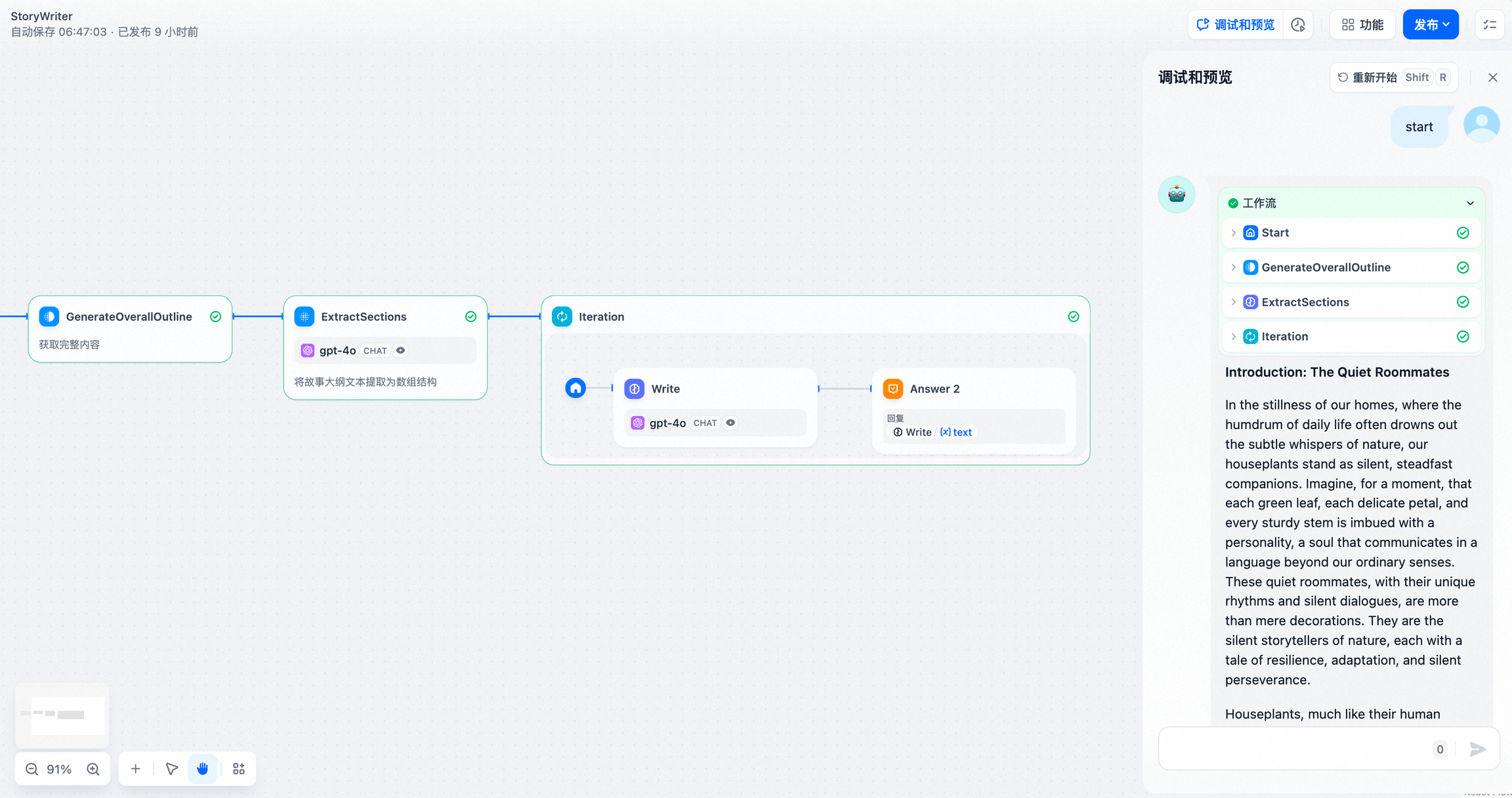
- 完整调试和预览
- 示例 2:长文章迭代生成器(另一种编排方式)
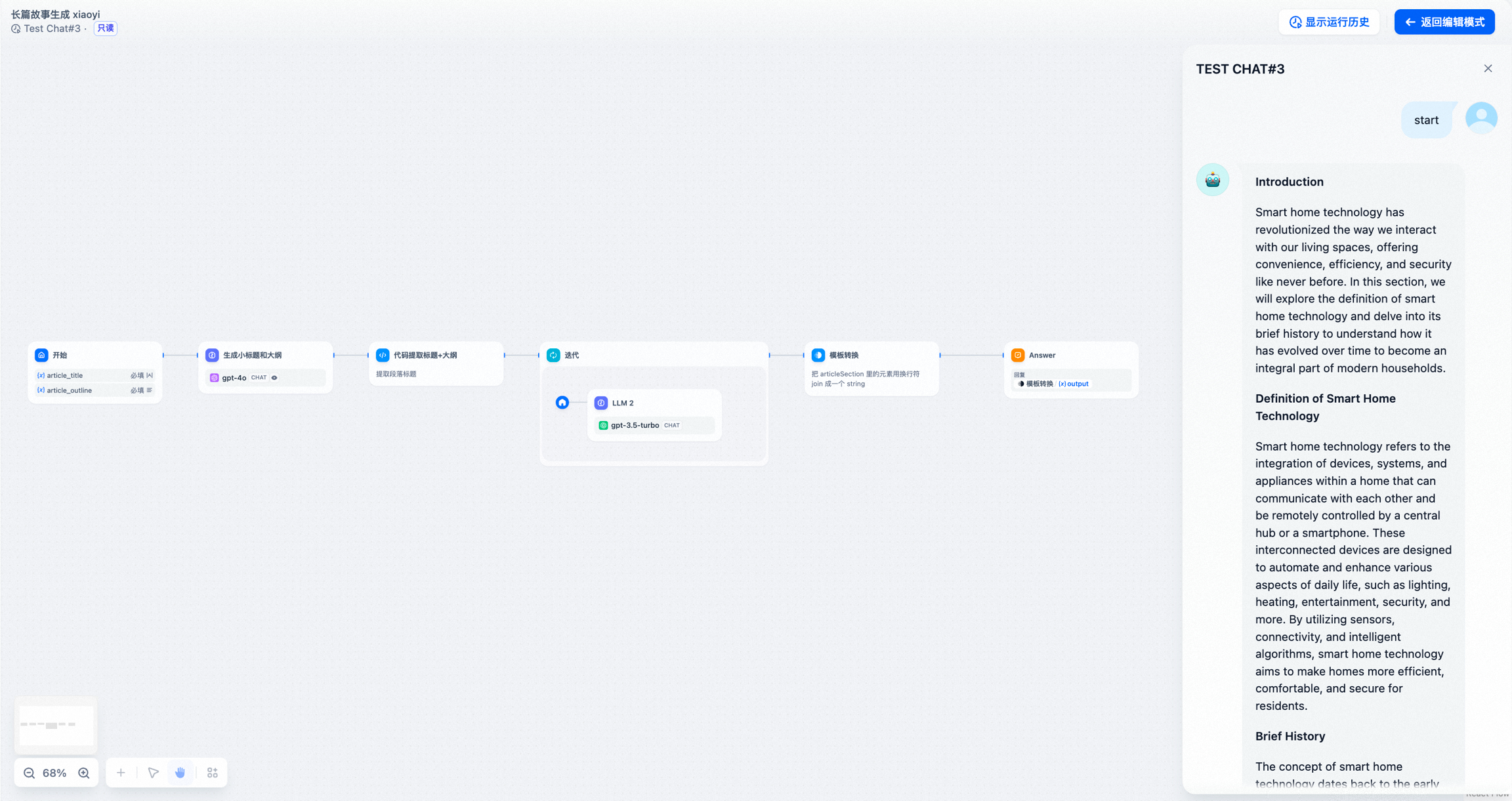
- 在 开始节点 内输入故事标题和大纲
- 使用 LLM 节点 生成文章小标题,以及小标题对应的内容
- 使用 代码节点 将完整内容转换成数组格式
- 通过 迭代节点 包裹的 LLM 节点 循环多次生成各章节内容
- 使用 模板转换 节点将迭代节点输出的字符串数组转换为字符串
- 在最后添加 直接回复节点 将转换后的字符串直接输出
- 数组内容
列表是一种特定的数据类型,其中的元素用逗号分隔,以 [ 开头,以 ] 结尾。例如:
数字型:
字符串型:
["monday", "Tuesday", "Wednesday", "Thursday"]
JSON 对象:
[
{
"name": "Alice",
"age": 30,
"email": "alice@example.com"
},
{
"name": "Bob",
"age": 25,
"email": "bob@example.com"
},
{
"name": "Charlie",
"age": 35,
"email": "charlie@example.com"
}
]
支持返回数组的节点
- 代码节点
- 参数提取
- 知识库检索
- 迭代
- 工具
- HTTP 请求
- 获取数组格式的内容
使用 CODE 节点返回
使用 参数提取 节点返回

- 如何将数组转换为文本
迭代节点的输出变量为数组格式,无法直接输出。你可以使用一个简单的步骤将数组转换回文本。
使用代码节点转换
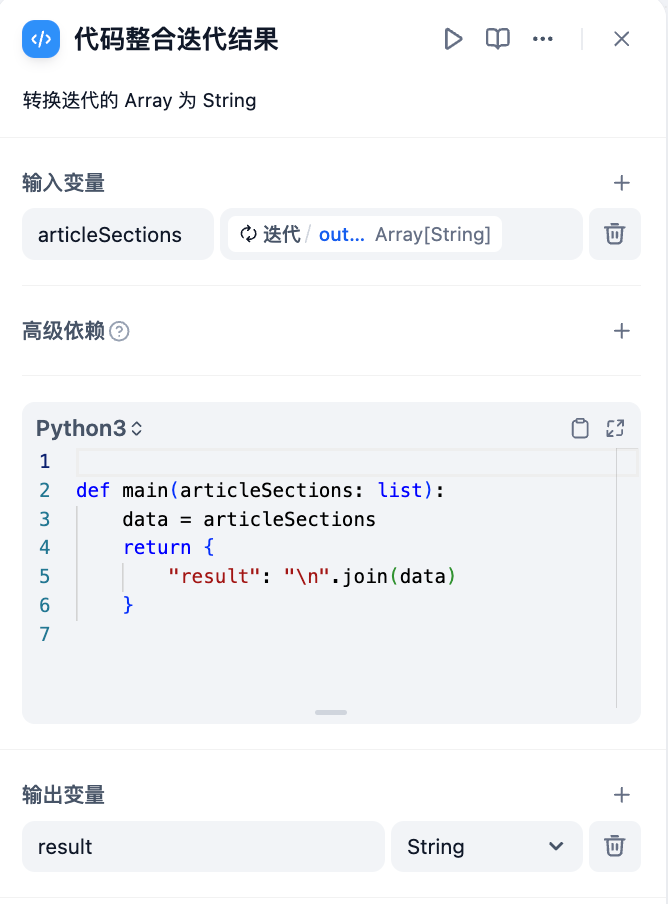
代码节点转换
def main(articleSections: list):
data = articleSections
return {
"result": "\n".join(data)
}
使用模板节点转换
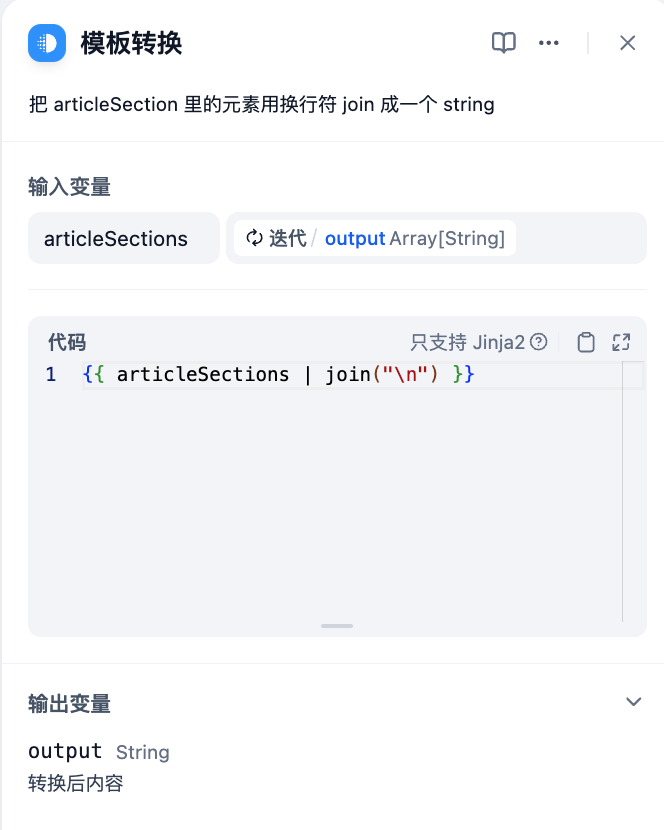
{{ articleSections | join("\n") }}
3.3 工具选择
工作流内提供丰富的工具选择,工具分为三种类型:
- 内置工具,Dify 第一方提供的工具
- 自定义工具,通过 OpenAPI/Swagger 标准格式导入或配置的工具
- 工作流,已发布为工具的工作流
使用内置工具之前,你可能需要先给工具进行 授权。
若内置工具无法满足使用需求,你可以在 Dify 菜单导航 --工具 内先创建自定义工具。
你也可以编排一个更加复杂的工作流,并将其发布为工具。
配置工具节点一般分为两个步骤:
- 对工具授权/创建自定义工具/将工作流发布为工具
- 配置工具输入和参数
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
更多优质内容请关注CSDN:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

