

论文名:TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
论文链接:https://arxiv.org/pdf/2504.00996
开源代码:https://liangbinxie.github.io...

导读
图像修复,即填充图像中缺失区域的任务,随着深度生成模型的兴起取得了显著进展。现有的基于扩散的修复方法在各种应用中显示出了有前景的结果,如物体移除、再生和文本引导的物体插入。
简介
本文介绍了 TurboFill,一种快速图像修复模型,它通过一个修复适配器增强少步文本到图像扩散模型,以实现高质量和高效的图像修复。虽然标准扩散模型能生成高质量的结果,但它们会产生高昂的计算成本。我们通过在少步蒸馏文本到图像模型 DMD2 上训练一个修复适配器来克服这一问题,使用一种新颖的三步对抗训练方案,以确保修复区域逼真、结构一致且视觉和谐。为了评估 TurboFill,我们提出了两个基准:DilationBench,用于测试不同掩码大小下的性能;HumanBench,基于人类对复杂提示的反馈。实验表明,TurboFill 优于多步的 BrushNet 和少步修复方法,为高性能修复任务树立了新的基准。

图 2. (放大查看效果最佳)1. 多步适配器实现了高质量的修复结果,但推理成本显著,需要超过 50 个扩散步骤。2. 将预训练的多步 BrushNet 适配器直接应用于少步 U - Net(DMD2)会产生伪影,包括颜色过饱和和语义不一致(例如,生成一条有两条尾巴的狗)。3. 仅使用扩散损失训练适配器 - DMD2 会产生模糊的输出和低质量的修复结果。4. 相比之下,使用所提出的三步对抗训练方案训练适配器 - DMD2 可产生高质量的修复结果,仅需四个扩散步骤。
方法与模型
在这项工作中,我们提出了一种快速图像修复模型 TurboFill,它直接在少步文本到图像扩散模型之上训练一个图像修复适配器。如图 3 所示,有三个组件:快速生成器、慢速生成器和扩散判别器。这三个组件的目标都是增强适配器修复掩码图像的能力。具体来说,慢速生成器帮助适配器朝着生成最逼真图像的方向对噪声潜变量进行去噪。快速生成器使适配器能够在训练期间生成清晰的图像以供评估。扩散判别器引导适配器生成具有更好纹理、细节和内容协调性的图像。基于这三个组件,TurboFill 采用了三步对抗训练方案。在整个训练过程中,训练在三个步骤之间交替进行。在接下来的部分,我们将详细描述每个步骤的训练过程和组件。
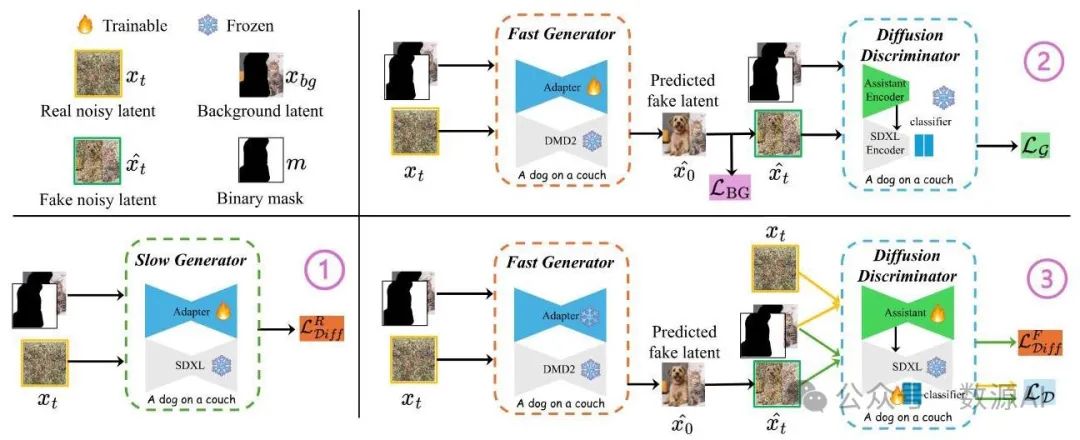

1. 在慢速生成器中训练适配器
为了捕捉条件信息并向扩散模型引入额外特征,我们使用了一个与 Brush - Net [12]具有相同 ControlNet 架构的图像修复适配器。鉴于 SDXL 是一个多步文本到图像生成器,我们将图像修复适配器和 SDXL 的集成指定为“慢速生成器”。相比之下,DMD2 是一个少步文本到图像生成器,因此图像修复适配器和 DMD2 的组合被命名为“快速生成器”。在这两个生成器中,通过连接噪声潜变量Xt、背景图像潜变量Xbg和下采样的二进制掩码m来引入条件信息。这个连接后的输入随后由图像修复适配器处理,同时Xt被同时输入到 UNet 中。然后,图像修复适配器产生的特征通过残差连接与 UNet 的特征进行融合。
如图 3① 所示,慢速生成器中图像修复适配器的参数基于实际扩散损失进行更新:

其中 T=1000 并且使用 DDPM 调度器 [10] 来生成Xt。
2. 在快速生成器中训练适配器

其中T=1000。

3. 训练扩散判别器

实验与结果
1. 数据集和指标
1.1. 训练数据集
为了能够通过输入局部掩码和掩码区域的相应提示进行编辑,我们构建了一个包含局部掩码及其相关文本描述的数据集。具体来说,我们从互联网上爬取了约 120 万张图像,并使用 Florence - 2 [28] 以 <DENSE_REGION_CAPTION> 提示执行密集区域字幕任务。此任务识别图像中的主要对象并生成其相应的简短描述。然后将这些描述输入到 SAM2 [20] 中,以获取对象的分割掩码。我们将此数据集命名为 LocalCaptionData。
1.2. 评估数据集
图像修复领域常用的公共数据集主要有 OpenImage V6 [13]、MSCOCO [15] 和 BrushBench [12]。其中,OpenImage V6 和 MSCOCO 提供精确的分割掩码和边界框掩码,用于根据类名对掩码区域进行修复。BrushBench 仅提供准确的分割掩码,使用全局图像描述对掩码区域进行修复。然而,考虑到用户通常使用粗略的掩码和相应的描述(有时可能很复杂且包含多个属性)进行图像修复,这三个数据集与现实场景有很大差异。为了更好地模拟用户操作,我们构建了两个评估数据集:
- 膨胀基准(DilationBench):这些掩码是通过随机膨胀分割掩码创建的,提示词描述了原始图像中被掩码区域内的内容。膨胀基准包含 300 对掩码和提示词。
- 人工基准(HumanBench):这些掩码是手动标注的,提示词是手动编写的。人工基准包含 150 对掩码和提示词。
两个基准数据集的描述和可视化结果包含在补充材料中。
1.3. 评估指标
为了评估修复后图像的质量,我们使用了三个指标:Q - 对齐(Q - Align)[26]、CLIPIQA + [25]、TOPIQ [4]。它们从不同角度评估视觉质量。Q - 对齐利用大语言模型(LLM)生成视觉分数,在各种图像质量评估(IQA)排行榜上处于领先水平。除 Q - 对齐外,CLIPIQA + 和 TOPIQ 分别在无参考和图像美学基准测试中排名第一,这使它们成为视觉质量的可靠指标,并提供互补的见解。为了更全面地评估修复结果,我们不仅考虑被掩码区域,还考虑整个图像,确保评估修复区域的局部质量和整个图像的整体视觉连贯性。为了衡量文本与掩码区域生成内容之间的一致性,我们使用 CLIP 相似度指标[19]。这四个指标的值越高,表明性能越好。
2. 实验设置
2.1. 网络配置
修复适配器采用与画笔网络(Brush - Net)相同的架构,并对 SDXL 模型进行了修改。具体来说,移除了自注意力和交叉注意力模块。请注意,我们的方法对修复适配器不施加任何架构约束。辅助器也采用类似 U - Net 的结构,为简单起见,我们直接采用与修复适配器相同的架构。分类器由卷积层、组归一化(GroupNorm)[27]和 SiLU [8]激活函数组成,它们共同将特征图映射到一维向量。分类器的详细信息在补充材料中描述。
当使用 SDXL 作为噪声预测的基础模型时,我们采用 DDIM 调度器[24],并从 1000 个时间步中随机采样。相比之下,当使用 DMD2 作为基础模型时,我们使用 LCM 调度器[16],并从四个特定的时间步中随机采样:{999,749,499,249}
。
2.2. 实现细节

3. 定量比较
我们将 TurboFill 与现有的最先进的图像修复方法进行比较,即 BLD [1]、高清绘画器(HD - Painter)[17]、SDXL 修复、随机画笔网络(BrushNet - Rand)[12]和强力绘画(Power - Paint)[5]。所有这些方法都采用多步方法,在推理过程中需要 50 步来生成修复结果。虽然随机画笔网络使用随机掩码进行训练,能有效处理不精确的掩码,并在推理过程中使用完整的图像描述,但其他方法仅依赖于被掩码区域的描述。
由于我们采用了 BrushNet 的架构设计,为了进行公平比较,我们还使用局部字幕数据(LocalCaptionData)训练了 BrushNet,并将此配置称为 BrushNet*。值得注意的是,作为一个外部模块,BrushNet 可以直接适配到一个 4 步扩散模型(例如 DMD2)中,形成一个 4 步的 BrushNet 配置。相比之下,像 HD-Painter 和 SDXL-Inpainting 这类修改基础模型结构的方法,无法与 4 步扩散模型集成。PowerPaint V2 是 BrushNet 和 SD1.5 的高级版本,它在四个不同的图像修复任务中融入了可学习的任务提示和专门的微调策略。然而,由于 PowerPaint 没有 SDXL 版本,它无法适配 4 步的 DMD2 模型。
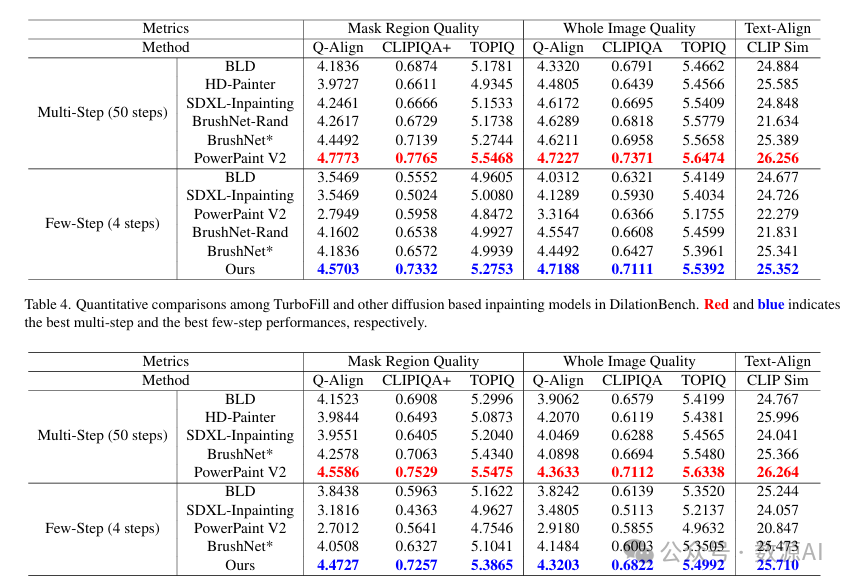
这些方法在膨胀基准数据集(Dilation-Bench)和人体基准数据集(HumanBench)上的比较结果分别列于表 4 和表 5。鉴于人体基准数据集(HumanBench)与实际的图像修复任务一样,没有提供整个图像的全局描述,我们将随机版 BrushNet(BrushNet-Rand)排除在该数据集的评估之外。从表 4 中我们发现,使用局部字幕数据(LocalCaptionData)训练的 BrushNet*,在 50 步和 4 步模型的文本对齐指标上,分别比 BrushNet 提高了 3.755 和 3.52。这表明,使用分割掩码和配对的局部描述而非全局描述进行训练,能显著增强 BrushNet 的文本对齐能力。
此外,我们观察到,将 BrushNet - Rand 和 BrushNet 直接插入 DMD2 以形成一个 4 步模型,在文本对齐性能上没有显著变化。然而,最终图像修复结果的图像质量明显下降。这表明,虽然用少步模型(DMD2)取代 SDXL 可以加速 BrushNet,但会导致质量下降。相比之下,TurboFill 可以有效缓解这个问题,在所有三个指标——掩码区域质量、全图像质量和文本对齐方面都有显著改善。即使只进行 4 步,我们的方法在许多图像质量指标(如 Q - Align、CLIPIQA+)上也优于 50 步的 BrushNet - Rand 和 BrushNet
。在两个基准测试中都可以观察到这种现象。
PowerPaint V2 目前在这些指标上取得了最佳结果。当将我们的方法与 PowerPaint 进行比较时,我们发现全图像质量的差距小于掩码图像质量的差距。视觉比较(图 4)显示,虽然 PowerPaint V2 生成了丰富的纹理,但掩码区域的结果不太自然,与背景区域相比存在明显的风格不匹配。这种不一致导致全图像质量的表现低于掩码区域质量。相比之下,我们的方法产生的结果更加连贯。由于现有的指标无法有效捕捉这些差异,我们进行了一项用户研究,详情见补充文件。
4. 定性比较
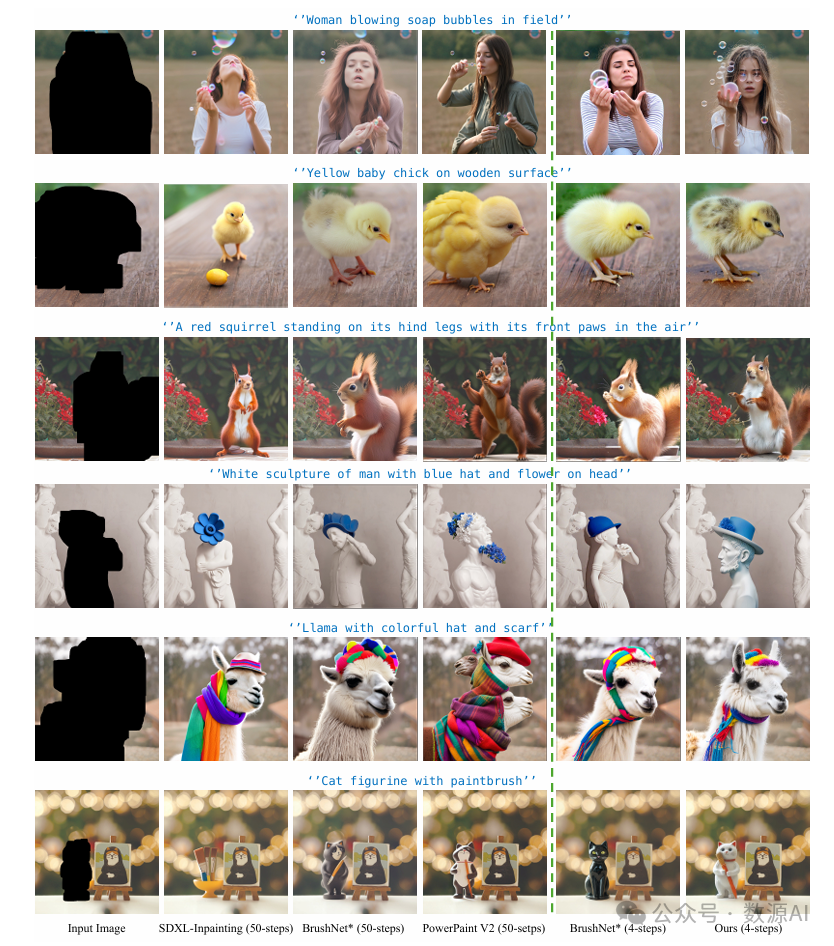
在 DilationBench 上的定性比较如图 4 所示。SDXL - 图像修复的结果呈现出偏黄的颜色偏差(如老虎、男人)且缺乏细节(如男孩、小雕像)。对于 PowerPaint V2,修复后的结果纹理非常清晰、色彩丰富,在大多数图像质量评估(IQA)指标上得分较高。然而,这些结果存在严重的失真(如双头老虎、双头人、过长的腿),看起来不太真实和自然(如第三行)。BrushNet 生成的结果存在明显的伪影,如老虎的皮毛(第一行)和男人的胡须(第五行),以及出现奇怪的背景(第五行)。当将 BrushNet
插入 4 步 DMD2 模型时,我们观察到结果缺乏显著的细节(如第五行),并存在过饱和问题(如老虎、小雕像)。与这些方法相比,TurboFill 在视觉比较中生成的结果质量更高。我们的结果在保留细节的同时,没有出现 PowerPaint V2 中的过度锐化现象(如老虎),也没有 BrushNet*(4 步)中的过饱和问题(如兔子)。生成的内容更加真实(如鸟、小雕像),使整个图像更加和谐。

图 4. 先前的修复方法和画笔网络在膨胀基准上的比较。与其他方法相比,TurboFill 仅需 4 步就能生成更逼真的细节和纹理,同时实现良好的场景协调。(放大查看效果更佳)
5. 局部字幕数据的有效性
如图 5 所示,当 BrushNet 以完整的图像描述(即全局提示)作为基础模型的输入进行训练时,其文本对齐能力相对较弱。在 BrushNet 尝试生成与图像中现有对象相似或语义相关的内容时,它通常要么默认完成背景,要么将注意力转移到提示中的其他类别(如猫)。此外,依赖全局提示限制了 BrushNet 处理更复杂提示的有效性。通过使用局部字幕数据(LocalCaptionData),BrushNet*在不改变训练方法的情况下有效克服了这些限制,从而显著提高了文本对齐性能。此外,TurboFill 在生成精细细节方面表现更优。

图 5. 局部字幕数据(LocalCaptionData)的有效性。所有结果均基于 4 步 DMD2 获得。(放大查看效果更佳)

图 6. 不同损失函数的有效性。从左到右,我们逐步去除特定的损失函数。(放大查看效果更佳)
6. 消融实验研究。


结论
在这项工作中,我们提出了 TurboFill,这是一种快速修复模型,旨在解决基于扩散模型的图像修复任务中的计算和质量挑战。通过在几步蒸馏的文本到图像扩散模型上直接训练一个修复适配器,TurboFill 以显著更低的推理成本实现了最先进的图像修复结果。所提出的三步对抗训练方案,结合了生成对抗网络(GAN)损失和扩散损失,确保生成具有精细纹理和结构连贯性的逼真和谐内容。为了评估 TurboFill 的性能,我们引入了两个新的基准测试,即膨胀基准测试(DilationBench)和人体基准测试(HumanBench),它们可以在不同的掩码复杂度和以用户为中心的场景下进行可靠评估。实验结果表明,TurboFill 能够超越现有的几步和多步 BrushNet,为实用高效的图像修复设定了新的基准。
END
作者:小源
来源:AIWalker
推荐阅读
- ContinuousSR:从离散低分图像中重建连续高分辨高质量信号
- CVPR`25 | 让暗光照片秒变电影大片!全球首个可训练的HVI色彩空间,突破低光增强瓶颈!
- 面向真实场景图像复原,字节跳动提出扩散复原适配器,表现卓越!
- 英伟达提出首个 Mamba-Transformer 视觉骨干网络!打破精度/吞吐瓶颈
- 自回归视觉生成破局:Next-X 预测,开辟视觉新路径
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏AIWalker。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

