
本文由 datacrunch 的博客作者 @Paul Chang 授权转载和翻译并发表到本公众号。
DeepSeek V3 SGLang 优化
继续我们的 DeepSeek V3 与 SGLang 集成的技术系列,我们旨在全面概述可用于提高性能和效率的各种优化策略。最终目标是在为 DeepSeek V3 模型系列(包括 R1)提供基于原生优化的竞争性推理性能的同时,培养 LLM 前沿改进的专业知识。作为推理服务引擎,SGLang 与 ML 基础设施堆栈的多个组件交互,为不同级别的优化提供了机会。大多数优化都以 launch_serverCLI 的标志形式出现。这些标志为了解 SGLang 生态系统中随时间实现的各种性能增强提供了一个便捷的入口点。
优化总结表

kernel 执行优化
相关标志:
--disable_cuda_graph: # 禁用CUDA Graph。
--cuda_graph_bs: # 由`CudaGraphRunner`捕获的批量大小。
--cuda_graph_max_bs: # 使用CUDA Graph时调整最大批量大小。
--enable-torch-compile: # 启用捕获的CUDA Graph的torch.compile编译。背景:
CUDA Graph(https://pytorch.org/blog/acce...)和torch.compile(https://pytorch.org/tutorials...)标志都致力于提高 kernel 操作的效率。CUDA Graph 通过记录和重放 CUDA 操作序列作为单个单元,显著减少了 kernel 启动开销,消除了推理期间每个 kernel 的启动成本。同时,torch.compile 采用 kernel 融合、算子消除和专门的 kernel 选择来优化计算图。然而,SGLang 的 torch.compile 可以使用 PyTorch 生成的图或 CUDA Graph 来连接这两种优化。
提交:
支持 triton 后端的 CUDA Graph(https://github.com/sgl-projec...),支持DP注意力的CUDA Graph #2061(https://github.com/sgl-projec...)
基准测试:
$ python3 -m sglang.bench_one_batch --batch-size 1 --input 256
--output 32 --model deepseek-ai/DeepSeek-V3 --trust-remote-code --tp 8
--torch-compile-max-bs 1 --disable-cuda-graph
--profile
$ python3 -m sglang.bench_one_batch --batch-size 1 --input 256
--output 32 --model deepseek-ai/DeepSeek-V3 --trust-remote-code --tp 8
--torch-compile-max-bs 1 --cuda-graph-max-bs 1
--profile
$ python3 -m sglang.bench_one_batch --batch-size 1 --input 256
--output 32 --model deepseek-ai/DeepSeek-V3 --trust-remote-code --tp 8
--enable-torch-compile --torch-compile-max-bs 1 --cuda-graph-max-bs 1结果:

compile-bench
正如预期的那样,当堆叠优化(torch.compiler / CUDA Graph + torch.compiler / torch.compiler(CUDA Graph) + torch.compiler)时,我们减少了总延迟(7.322 / 1.256 / 1.011 s)并提高了总吞吐量(39.34 / 229.27 / 284.86 token/s)。
注意:我们看到预填充阶段延迟的下降,这是由于 torch.compiler 编译和 CUDA Graph 未捕获预填充阶段操作导致的初始计算增加(0.21180 / 0.25809 / 0.26079 s)和吞吐量(1208.67 / 991.92 / 981.64 token/s)。
bf16 批量矩阵乘法 (bmm)
背景:
批量矩阵乘法是 LLM 中执行的主要工作负载。由于 DeepSeek-V3 使用不同的量化 fp8 数据类型(float8_e5m2 和 float8_e4m3fn)进行训练(从而减少内存分配),我们测试了具有不同 fp8 和基础 bf16 数据类型组合的随机 bmm 集合的精度和延迟。此优化不依赖于标志。
提交:
(修复 MLA 的 fp8 并支持 DeepSeek V2 的 bmm fp8(https://github.com/sgl-projec...),在AMD GPU 上启用 DeepseekV3(https://github.com/sgl-projec...),将bmm_fp8 kernel 集成到 sgl-kernel 中(https://github.com/sgl-projec...))
基准测试:
$ pytest -s test_bmm_fp8.py- 使用修改版的 test_bmm_fp8.py 获得的结果
结果:

bmm-bench
结果之间的相似度接近相同(余弦相似度=1 相同),这表示没有精度损失,而 fp8 的延迟比 bf16 差,这是由于类型转换计算导致的。
支持 nextn 推测解码
相关标志:
--speculative-num-steps: # 从草稿模型中采样的步骤数。
--speculative-eagle-topk: # 在EAGLE-2的每个步骤中从草稿模型中采样的token数。
--speculative-num-draft-tokens: # 在推测解码中从草稿模型中采样的token数。
--speculative-draft: # 要使用的草稿模型。它需要与验证器模型相同的分词器(默认:SGLang/DeepSeek-V3-NextN)。背景:
推测解码通过引入草稿模型(一个更小、更快的模型)来加速推理,该模型一次生成多个 token。然后验证步骤检查这些草稿 token 是否与更大、更准确的 LLM 的预测匹配。
其主要缺陷是,由于 Naive 的推测解码生成单个线性草稿 token 序列,如果序列中的单个 token 被拒绝,所有后续 token 都会被丢弃,降低了接受率。
SGLang 的 NextN 实现基于 EAGLE-2 和 SpecInfer:

speculative_decoding.png
使用基于树的推测解码(SpecInfer 和 EAGLE-2),预测被组织为树,其中每个节点代表一个可能的下一个 token。通过这种方法,我们生成多个可以并行验证器 LLM 验证的推测分支,提高了接受率。
EAGLE-2 的关键改进是基于上下文的动态草稿树和基于草稿模型置信度分数的节点剪枝。
提交:
([Track] DeepSeek V3/R1 nextn 进度 #3472,(https://github.com/sgl-projec...),支持DeepSeek-V3/R1的NextN (MTP)推测解码 #3582(https://github.com/sgl-projec...),支持Triton后端的Eagle2 #3466(https://github.com/sgl-projec...),Eagle推测解码第4部分:添加EAGLE2工作器 #2150(https://github.com/sgl-projec...))
基准测试:
无标志。
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 256 --random-output 32 --random-range-ratio 1 --num-prompts 1 --host 127.0.0.1 --port 30000--speculative-algo NEXTN --speculative-draft SGLang/DeepSeek-V3-NextN --speculative-num-steps 2 --speculative-eagle-topk 4 --speculative-num-draft-tokens 4
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --speculative-algo NEXTN --speculative-draft SGLang/DeepSeek-V3-NextN --speculative-num-steps 2 --speculative-eagle-topk 4 --speculative-num-draft-tokens 4 --tp 8 --trust-remote-code
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 256 --random-output 32 --random-range-ratio 1 --num-prompts 1 --host 127.0.0.1 --port 30000 结果:

spec-bench
我们实现了总体吞吐量(请求、输入和输出)的改进,并显著(x6)减少了端到端延迟。
GiantPandaLLM 注:这里的测试结果存疑,应该没这么大加速,不过先了解这是一个有用的优化就可以。
MLA
TP+DP 注意力
相关标志:
--enable-dp-attention:### 启用兼容的MLA数据并行。背景:
张量并行(TP)通过将 KV Cache 按 TP 设备(通常是 8)分割来与 MHA 一起工作,因此每个设备处理 KV Cache 的 1/TP。 [1]
如果我们将其应用于多头潜在注意力(MLA)和 TP,每个 GPU 沿 head_num 维度分割 kv cache。然而,MLA 的 kvcache 的 head_num 为 1,使其无法分割。因此,每个 GPU 必须维护一个完整的 kvcache→kvcache 在每个设备上被复制。
当对 MLA 使用 DP(数据并行)时,它按请求分割,不同请求的潜在状态缓存存储在不同的 GPU 中。例如,由于我们无法分割唯一的 KV Cache,我们将数据分成批次并将它们并行化到执行不同任务(预填充、解码)的不同工作器中。
在 MLA 之后,执行 all-gather 操作,允许每个 GPU 获取所有序列的 hidden_state。然后,在MOE(专家混合)之后,每个 GPU 使用slice操作提取其对应的序列。

dp_attn.png
提交:
(支持 DP 注意力的 CUDA Graph(https://github.com/sgl-projec...),支持多节点DP注意力(https://github.com/sgl-projec...),多节点张量并行(https://github.com/sgl-projec...),支持DP MLA(https://github.com/sgl-projec...))
基准测试:
无标志
# 使用分析器环境启动服务器
export SGLANG_TORCH_PROFILER_DIR=/sgl-workspace/profiler_env_folders/ # 可选用于分析
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
# 预填充
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 512 --random-output 1 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000
# 解码
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 1 --random-output 512 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000
````
—enable-dp-attention
使用分析器环境启动服务器
export SGLANG_TORCH_PROFILER_DIR=/sgl-workspace/profiler_env_folders/
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code --enable-dp-attention
预填充
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 512 --random-output 1 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000
解码
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 1 --random-output 512 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000
##### 结果:
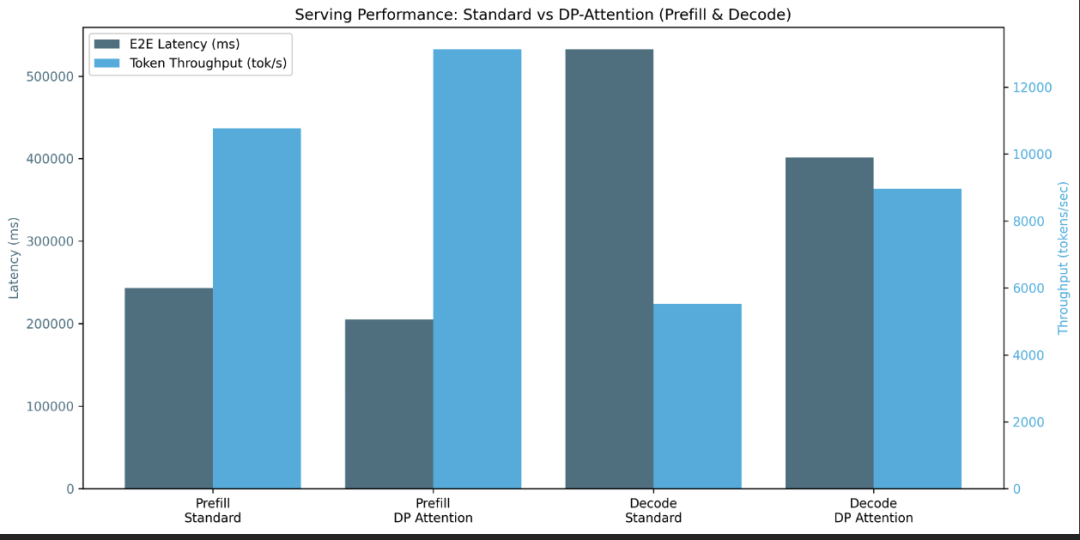
dp-bench
由于它是一个调度器范式,在使用大批量大小时表现更好。否则,添加的开销大于实际的数据并行化。
对于较大的批量大小(在这种情况下为 10,000),我们看到从端到端延迟到总体吞吐量和并发性的预填充和解码阶段都有整体改进。##### 支持与 DP 注意力重叠调度器
##### 相关标志:
```
--disable-overlap-schedule:### 禁用开销调度器
```
##### 背景:
我们可以将 CPU 调度与 GPU 计算重叠。调度器提前运行一个批次并准备下一个批次所需的所有元数据。通过这样做,我们可以让 GPU 在整个持续时间内保持忙碌,并隐藏昂贵的开销,如 radix cache 操作。

overlap_scheduler.png
##### 提交:
(更快的重叠调度器(https://github.com/sgl-project/sglang/pull/1738),默认启用重叠(https://github.com/sgl-project/sglang/pull/2067),为triton注意力后端默认启用重叠调度器(https://github.com/sgl-project/sglang/pull/2105))
##### 基准测试:
--disable-overlap-schedule
```
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code --disable-overlap-schedule
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 256 --random-output 32 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000无标志 → 启用重叠调度器:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 -m sglang.bench_serving --backend sglang --dataset-name random --num-prompts 2500 --random-input-len 1024 --random-output-len 1024 --random-range-ratio 1
````
##### 结果:
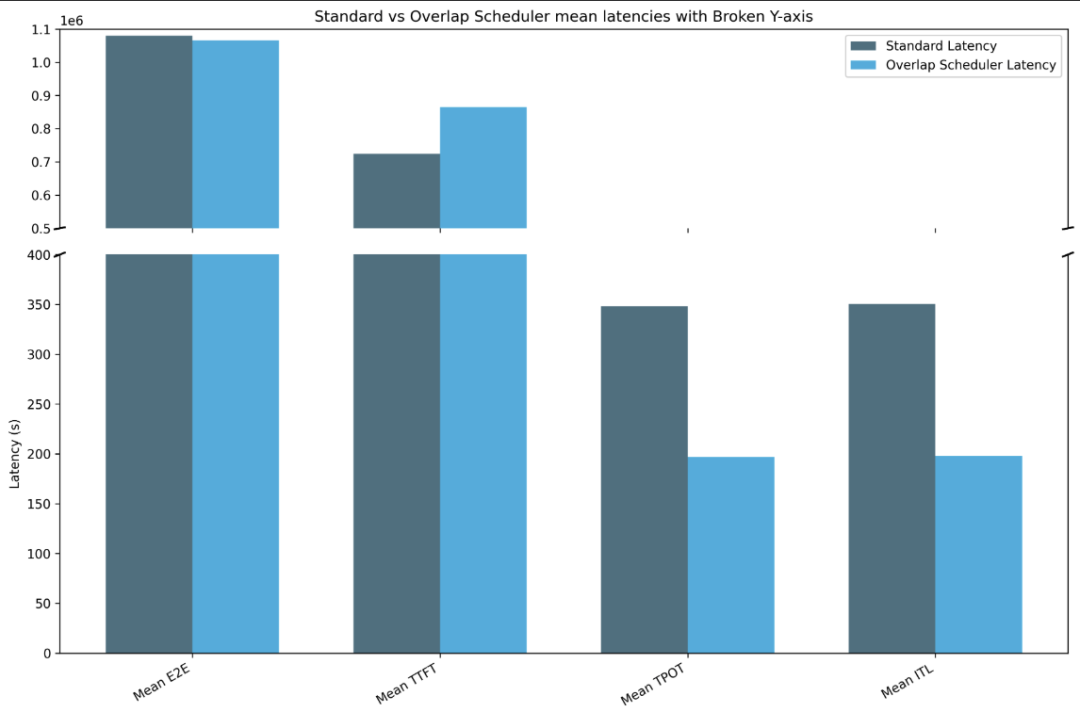
fig_overlap
我们看到延迟的普遍减少:端到端(标准:1080152.26s|重叠:1066166.84s),每个输出 token 的时间(标准:348.10s|重叠:196.79s)和 token 间延迟(标准:350.62s|重叠:197.96s),尽管第一个 token 的时间呈现了调度开销的下降结果(标准:724050.93s|重叠:864850.926s)。
对于更大的输入和输出请求大小,重叠调度器的效果将更加明显。
#### FlashInfer 预填充和 MLA 解码
##### 相关标志:
--enable-flashinfer-mla:### 启用FlashInfer MLA优化
##### 背景:
使用 FlashInfer 后端代替 triton。
##### 提交:
(为 flashinfer mla 添加快速解码 plan,(https://github.com/sgl-project/sglang/pull/3987) 无权重吸收的 MLA 预填充(https://github.com/sgl-project/sglang/pull/2349))
##### 基准测试:
无标志:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 benchmark/gsm8k/bench_sglang.py --num-shots 8 --num-questions 1319 --parallel 1319
Accuracy: 0.951
Latency: 77.397 s
Output throughput: 1809.790 token/s
使用--enable-flashinfer-mla
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code --enable-flashinfer-mla
python3 benchmark/gsm8k/bench_sglang.py --num-shots 8 --num-questions 1319 --parallel 1319
Accuracy: 0.948
Latency: 71.480 s
Output throughput: 1920.021 token/s
##### 结果:
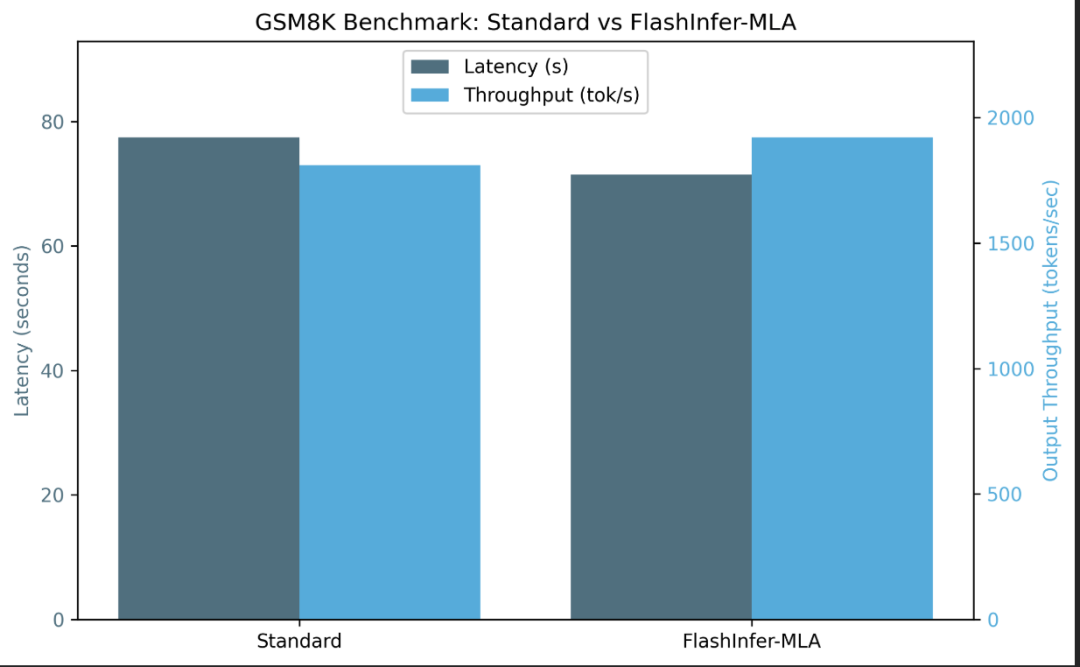
flashinfer_mla png
由于FlashInfer融合操作,我们在相似精度下获得了更低的延迟和更高的输出吞吐量。
### FP8
#### 提高FP8的精度
##### 背景:
当值超过给定数值格式(如FP8)的可表示范围时,会发生数值溢出,导致不正确或无限值。在Tensor Core上FP8量化的上下文中,溢出发生是因为FP8具有非常有限的动态范围。为了防止数值溢出,在量化之前使用矩阵的最大元素将值缩小,尽管这使其对异常值敏感。为了避免这种情况,DeepSeek团队提出了分块和分片缩放,其中权重矩阵的每个128×128子矩阵和激活向量的每个1×128子向量分别进行缩放和量化。
NVIDIA H800 Tensor Core上的FP8 GEMM累加限制在约14位精度,这显著低于FP32累加精度。这就是为什么DeepSeek使用CUDA Core的单独FP32累加器寄存器,从而减轻精度损失。反量化缩放因子也应用于这个FP32累加器。
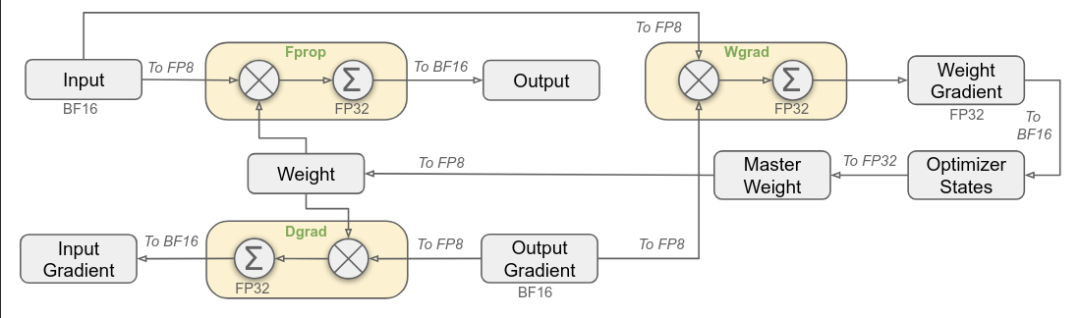
fp8_deepseek.png
##### 提交:
(支持分块fp8矩阵乘法 kernel #3267(https://github.com/sgl-project/sglang/pull/3267),添加分块fp8的单元测试#3156(https://github.com/sgl-project/sglang/pull/3156),集成分块fp8 kernel#3529(https://github.com/sgl-project/sglang/pull/3529),[Track] DeepSeek V3/R1精度(https://github.com/sgl-project/sglang/issues/3486))
##### 基准测试:
```
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1 --tp 8 --trust-remote-code
python3 benchmark/gsm8k/bench_sglang.py --num-shots 8 --num-questions 1319 --parallel 1319
```
##### 结果:
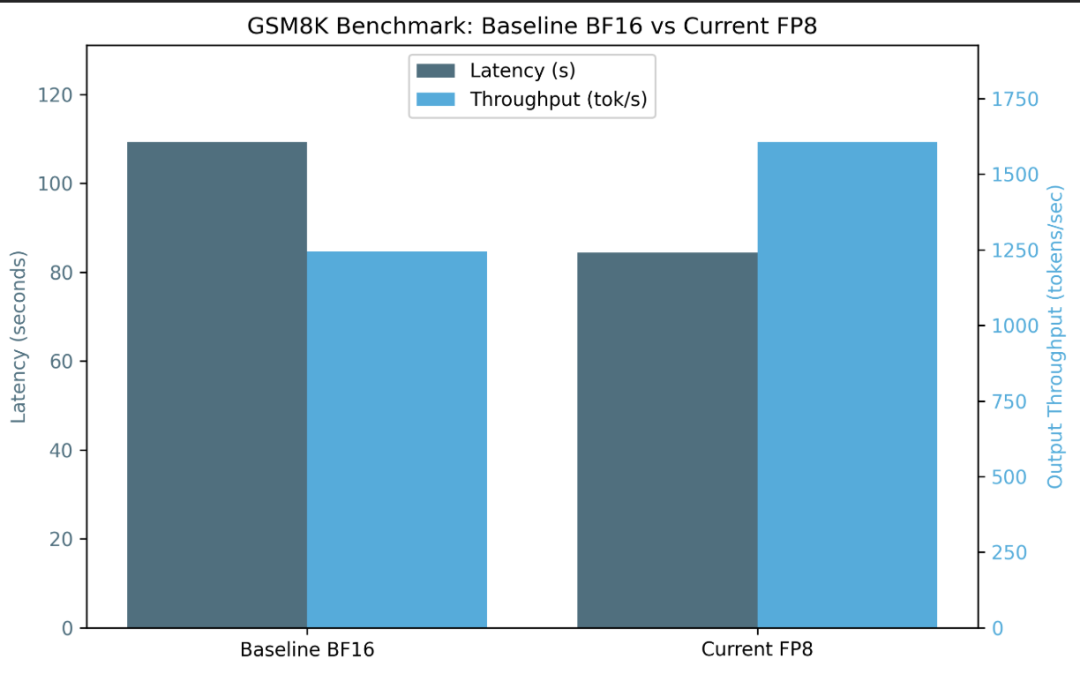
对于相同的精度(gsm8k上为0.955vs0.957),我们观察到更高的输出吞吐量和更低的延迟。
#### FP8 GEMM调优
##### 背景:
SGLang采用FP8分块量化调优来优化不同GPU的性能。该实现特别针对AMD和CUDA架构对FP8 GEMM(通用矩阵乘法) kernel进行基准测试,测试不同的块形状以基于延迟确定最有效的配置。
这种方法确保分块量化与GEMM操作的最佳块大小对齐,在最大化计算效率的同时最小化精度损失。计算在FP8中执行,但累加在BF16中进行以在最终输出存储之前保持数值稳定性。
关键函数:
```
# fn: benchmark_config(A_fp8, B_fp8, As, Bs, block_size, config, out_dtype=torch.float16, num_iters=10)
A: torch.Tensor, # 输入矩阵 (FP8) - 通常是激活
B: torch.Tensor, # 输入矩阵 (FP8) - 通常是权重
As: torch.Tensor, # `A`的每个token组的缩放因子
Bs: torch.Tensor, # `B`的每个块的缩放因子
block_size: List[int], # 量化的块大小 (例如, [128, 128])
config: Dict[str, Any], # kernel配置参数
output_dtype: torch.dtype = torch.float16, # 输出精度
```
```
# fn: tune(M, N, K, block_size, out_dtype, search_space):
M,N,K: int # 矩阵乘法的形状 (M × K @ K × N → M × N)
block_size: int # 定义分块量化大小的元组 ([block_n, block_k])
out_dtype: str # 输出精度 (例如, float16, bfloat16)
search_space: List[dict{str,int}] # 要测试的配置列表 (例如, 块大小, warp数量)。
# search_space示例:
{
"BLOCK_SIZE_M": block_m,
"BLOCK_SIZE_N": block_n,
"BLOCK_SIZE_K": block_k,
"GROUP_SIZE_M": group_size,
"num_warps": num_warps,
"num_stages": num_stages,
}
```
##### 提交:
(添加分块fp8调优#3242]https://github.com/sgl-project/sglang/pull/3242))
##### 基准测试:
```
$python3benchmark/kernels/quantizationtuning_block_wise_fp8.py
```
##### 结果:
kernel的最佳配置示例:N=512,K=7168,device_name=NVIDIA_H200,dtype=fp8_w8a8,block_shape=[128, 128]
```
[...]
{
"2048": {
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 64,
"BLOCK_SIZE_K": 128,
"GROUP_SIZE_M": 1,
"num_warps": 4,
"num_stages": 4
},
"3072": {
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 64,
"BLOCK_SIZE_K": 128,
"GROUP_SIZE_M": 1,
"num_warps": 4,
"num_stages": 3
},
"4096": {
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 128,
"BLOCK_SIZE_K": 128,
"GROUP_SIZE_M": 64,
"num_warps": 4,
"num_stages": 3
}
}对于所有要调优的批量大小和给定的 FP8 数据类型,给定脚本测试并比较不同的模型权重维度(N 和 K)以基于最低延迟优化 FP8 GEMM 分块量化。这为每个批量大小获得块平铺维度(BLOCK_SIZE_M/N/K)、组大小(GROUP_SIZE_M)(用于一起分组的块数量,改善 L2 缓存使用)、每个线程块(即每个块)的 warp 数量(num_warps)以及用于将块加载到共享内存作为预取的阶段数量(num_stages)的最优配置。反过来,这实现了不同配置的计算参数的自动调优。
FP8 GEMM CUTLASS 实现
背景:
量化操作可以融合到 FP8 矩阵乘法操作中以提高效率。在 sgl-kernel/src/sgl-kernel/csrc/int8_gemm_kernel.cu 中,有一个 CUDA 加速的 8 位整数(int8)缩放矩阵乘法实现,与 W8A8 量化融合。
提交:
(支持 CUTLASS 的 w8a8 fp8 kernel #3047(https://github.com/sgl-projec...),支持cutlass Int8 gemm #2752(https://github.com/sgl-projec...),支持sm90 Int8 gemm#3035(https://github.com/sgl-projec...),来自NVIDIA/cutlass的FP8分块缩放 #1932(https://github.com/NVIDIA/cut...))
基准测试:
root@cluster-h200-02-f2:/sgl-workspace/sglang/sgl-kernel/benchmark# python3 bench_int8_gemm.py 结果:
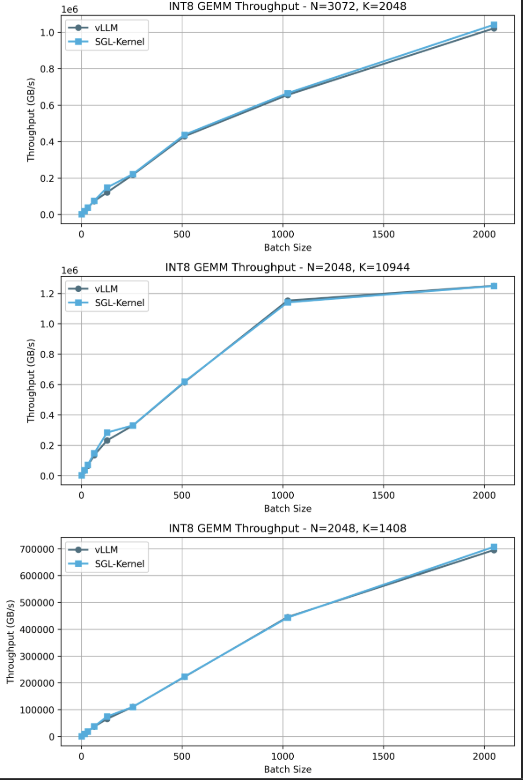
基准测试测量每个批量大小的 GB/s(吞吐量的另一种度量)。比较 vLLM kernel(int8 gemm)与 SGLang kernel,我们为不同配置(N 和 K)的不同批量大小获得更高的吞吐量。
注意: 我们使用 DeepSeek-Coder-V2-Lite-Instruct 测试了这个基准,因为 DeepSeek-V3 的代码尚未在 SGLang 中实现。
MoE
H200 的 FusedMoE 调优
以下是使用 token 和专家矩阵的专家混合(MOE)融合计算的实现,使用乘法 A @ B(token× 专家矩阵乘法)进行 top-k 路由,并支持:- fp16、bfloat16、fp8、int8 格式
- 通过 A_scale、B_scale 进行权重/激活缩放
- 分块量化
- 通过 expert_ids 进行专家路由
背景:
SGLang 的自定义融合 MoE kernel,使用 vLLM 作为参考和基准,由以下组成:
tuning_fused_moe_triton.py:用于调优 fused_moe_tritonkernel 的工具。改编自 vllm 的 benchmark_moe.py(https://github.com/vllm-proje...),增加了对各种模型架构的支持。
benchmark_vllm_vs_sglang_fused_moe_triton.py:用于比较 vLLM 和 SGLang 实现之间融合 MoE kernel 性能的工具。支持各种模型架构和数据类型。
benchmark_torch_compile_fused_moe.py:用于对融合 MoE kernel 与 torch.compile 和原始融合 MoE kernel 进行基准测试的工具。
提交:
(为 fused_moe 添加单元测试(https://github.com/sgl-projec...),MoE专家并行实现(https://github.com/sgl-projec...),benchmark/kernels/fused_moe_triton/README.md(https://github.com/sgl-projec...))
基准测试:
$ python3 benchmark/kernels/fused_moe_triton/tuning_fused_moe_triton.py --model deepseek-ai/DeepSeek-V3 --tp-size 8 --dtype fp8_w8a8 --tune
Writing best config to E=256,N=256,device_name=NVIDIA_H200,dtype=fp8_w8a8,block_shape=[128, 128].json...
Tuning took 5267.05 secondsFusedMoE 基准测试 sgl-kernel vs vllm:
python3 benchmark/kernels/fused_moe_triton/benchmark_vllm_vs_sglang_fused_moe_triton.py
[...]
benchmark sglang_fused_moe_triton with batch_size=505
benchmark vllm_fused_moe_triton with batch_size=506
benchmark sglang_fused_moe_triton with batch_size=506
benchmark vllm_fused_moe_triton with batch_size=507
benchmark sglang_fused_moe_triton with batch_size=507
benchmark vllm_fused_moe_triton with batch_size=508
benchmark sglang_fused_moe_triton with batch_size=508
benchmark vllm_fused_moe_triton with batch_size=509
benchmark sglang_fused_moe_triton with batch_size=509
benchmark vllm_fused_moe_triton with batch_size=510
benchmark sglang_fused_moe_triton with batch_size=510
benchmark vllm_fused_moe_triton with batch_size=511
benchmark sglang_fused_moe_triton with batch_size=511
benchmark vllm_fused_moe_triton with batch_size=512
benchmark sglang_fused_moe_triton with batch_size=512
fused-moe-performance:
[...]
batch_size vllm_fused_moe_triton sglang_fused_moe_triton
505 506.0 1.014688 0.507488
506 507.0 1.011744 0.509344
507 508.0 1.007200 0.504288
508 509.0 1.007232 0.505696
509 510.0 1.007792 0.507712
510 511.0 1.011072 0.507248
511 512.0 1.012992 0.507840结果:
我们对DeepSeek-V3的融合MoE kernel进行了FP8量化调优,获得了每个批量大小的最优配置,类似于调优FP8 GEMM时:> > 对于块平铺维度(BLOCK_SIZE_M/N/K),组大小(GROUP_SIZE_M)用于一起分组的块数量,改善L2缓存使用,每个线程块(即每个块)的warp数量(num_warps),以及用于将块加载到共享内存作为预取的阶段数量(num_stages)。

然后我们比较SGLang的融合MoE kernel实现与vLLM的基准实现,获得了一个更精细的版本,在增加批量大小时几乎保持恒定延迟。

fused_moe_latency_comparison.png
作为结束语,本技术博客使用的版本是sglang: v0.4.3.post2, sgl-kernel: 0.0.3.post6, torch: 2.5.1和CUDA: 12.5。
我们强烈支持sglang的协作,它作为DeepSeek模型系列的事实上的开源推理引擎。
未来的工作计划通过分析关键组件(如FlashMLA kernel、FlashAttention和sglang Triton kernel)的性能和增量改进来进一步探索这些优化。我们还建议探索sglang团队实现的新优化,如预填充和解码阶段的分割以及DeepGemm与FusedMoE的集成。
感谢sglang团队的帮助、对本博客的审查以及他们在项目上的联合协作。
参考文献
- sglang kernel测试: https://github.com/sgl-projec...
- sglang kernel基准测试: https://github.com/sgl-projec...
- [功能] DeepSeek V3优化 #2591: https://github.com/sgl-projec...
- 博客 deepseek v3 10倍效率背后的关键技术: https://dataturbo.medium.com/...
- AI编译器Sglang优化工作: https://carpedm30.notion.site...
- lmsys sglang 0.4数据并行: https://lmsys.org/blog/2024-1...
- lmsys sglang 0.4零开销批处理调度器: https://lmsys.org/blog/2024-1...
- spaces.ac.cn: MQA, GQA, MLA博客: https://spaces.ac.cn/archives...
- 基于树的推测解码论文: https://arxiv.org/pdf/2305.09781
- EAGLE2推测解码论文: https://arxiv.org/pdf/2406.16858
- DeepSeek v3论文: https://arxiv.org/pdf/2412.19437
- 知乎博客: EAGLE: 推测采样需要重新思考特征不确定性: https://zhuanlan.zhihu.com/p/...
- 知乎博客: MLA tp和dp: https://zhuanlan.zhihu.com/p/...
- 知乎博客: MLA tp和dp第2部分: https://zhuanlan.zhihu.com/p/...
- Colfax deepseekv3 fp8混合精度训练: https://research.colfax-intl....
END
作者:datacrunch
来源:GiantPandaLLM
推荐阅读
- 视觉反馈驱动+动态规则细化,7B模型性能跃升50%,碾压10倍大模型
- TVM Relax:通过跨层次抽象实现动态 shape 的 LLM 高效部署
- 分享一个DeepSeek V3和R1中 Shared Experts和普通Experts融合的技巧
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

