
序言
作为非算法同学,最近被 Cursor、DeepSeek 搞的有点焦虑,同时也非常好奇这里的原理,所以花了大量业余时间自学了 Transformer 并做了完整的工程实践。希望自己心得和理解可以帮到大家~
如有错漏,欢迎指出~
本文都会以用 Transformer 做中英翻译的具体实例进行阐述。
从宏观逻辑看 Transformer
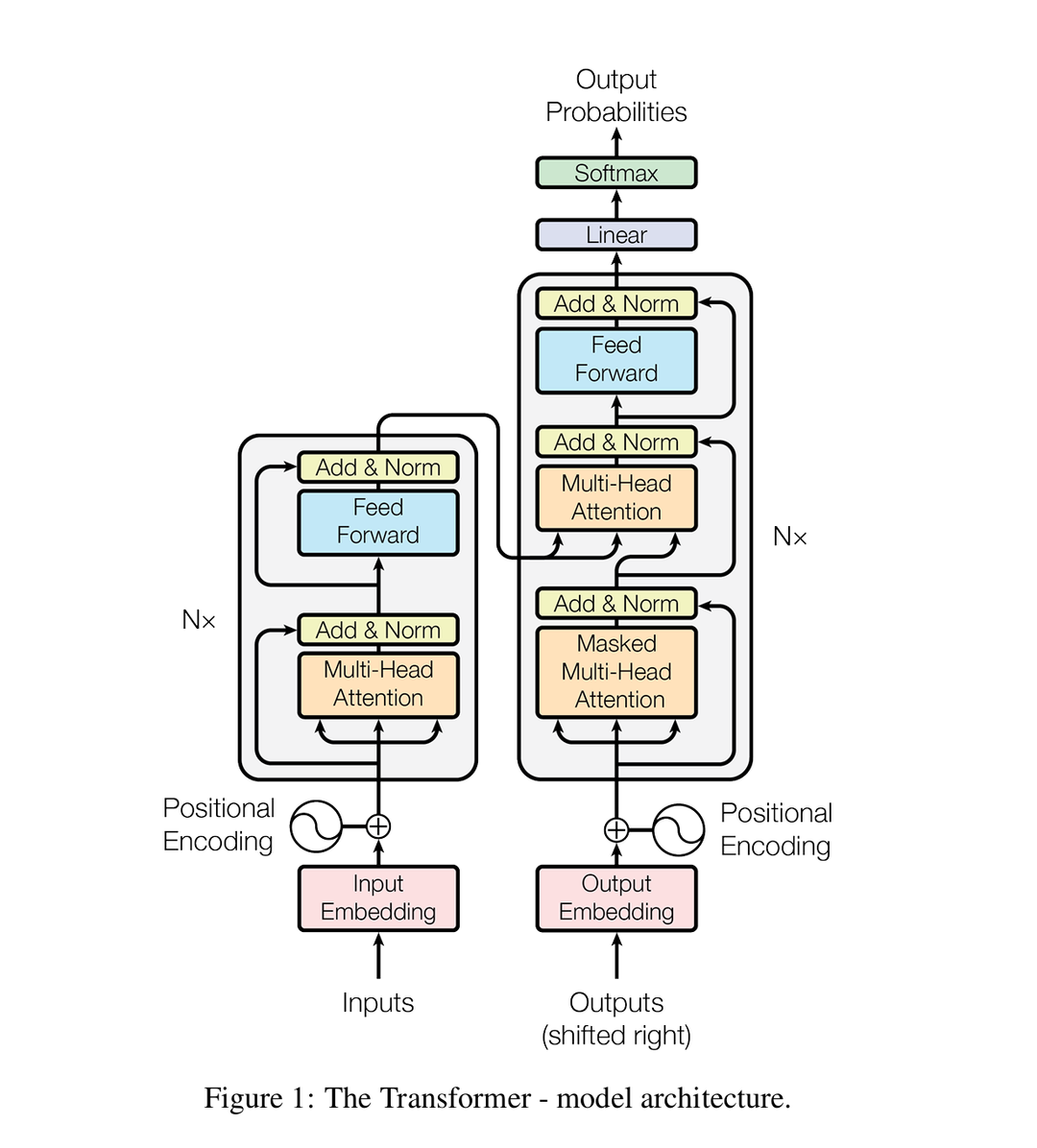
让我们先从宏观角度解释一下这个架构。
首先 Transformer 也是一个神经网络,神经网络的本质是模拟人脑神经元的思考过程,数学上是一种拟合,当然,人脑内部的信号处理是否连续或者可拟合我们不得而知,但 Transformer 在我的机器上实实在在地思考并输出了正确的答案。
Transformer 主要是设计用来做翻译的,分两大块,如上图,左边的编码器和右边的解码器。
编码器负责提取原文的特征,
解码器负责提取当前已有译文序列的特征,并结合原文特征(编码器解码器的连线部分),给出下一个词的预测。
GPT 基本可以认为就是 Transformer 的解码器部分。
接下来我们分几个部分逐步讲解并附上代码实践,很长 得慢慢看....
输入和输出
我认为大部分文章都没有把输入和输出讲得很细,其实理解了输入输出,你就基本可以理解 Transformer 的大半了。
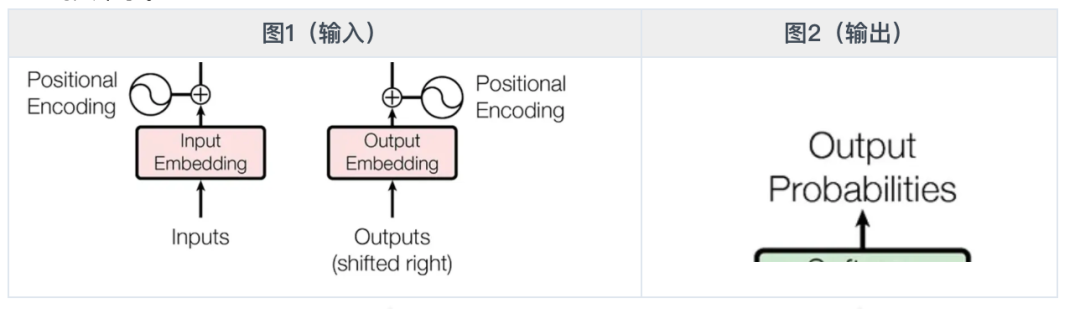
模型的输入
以中英翻译为例,Transformer 的输入分两部分
- 源文序列(中文) 即图 1 左侧部分,输入到编码器。 举例: 我爱 00700
- 目标译文(英文)即图 1 右侧部分,输入到解码器。 一开始只有一个,仅用于告诉模型开始翻译
模型的输出
很显然,对于上述输入,我们期待的输出是 I love 00700
的作用是表示翻译结束,因为翻译的英文不一定和输入的中文等长,所以需要有一个结束符。
模型并不能一下子输出完整的句子,他是一个词一个词( /token/ )吐出来的,并且每一个词都需要作为下一词的输入,这也是为什么大模型都是打字机交互的原因。 具体例子:
第一个循环
编码器输入我爱00700
解码器输入<bos>
输出I
第二个循环
编码器输入我爱00700
解码器输入<bos>I
输出love
第三个循环
编码器输入我爱00700
解码器输入<bos>Ilove
输出00700
第四个循环
编码器输入我爱00700
解码器输入<bos>Ilove00700
输出<eos>
//输出了结束符,翻译完成
请注意上述是为了简化理解的一个陈述,实际上模型真正的输出并不是一个词,而是整个 /词表/ 内任意一个词可能的概率,也就是图 2 所示的probabilities。
具体说,就是一个数组[0.2, 0.7, 0.1], 序号为 0 的词的概率是 0.2,序号为 1 的词的概率是 0.7,序号为 2 的词的概率是 0.1。 假设这是第二轮循环,词表是[I, love, 00700] 取最大概率 0.7 的词,然后得到第二轮输出是 love, 和第一轮输出拼起来就是 I love。
词表 & token
划线的两个词 /token/ /词表/ 你可能仍有疑惑。这正是我们真正弄清楚整个输入输出的关键。
显然,计算机只能理解二进制数据,我们说输入"我爱 00700"的时候,实际上输入的是处理好的二进制数据。
如何把句子转化成模型可以理解的二进制数据呢? 不妨先想想我们怎么学英语的, 没错,背单词啊! 我们需要先认识词,然后理解句子,模型也是一样的。
我们背的英文单词表,和这里的模型 /词表/ 其实是一个意思,当然,形式略有不同。 词表里的每一个词,就是我们说的 /token/ ,请注意 token 不一定是一个英语单词。上述例子的英文词表可能是: [I, lo, ve, 00, 7] 。 显然,token 不是按照空格分的。 原因是算力难以覆盖,英文单词有几十万个(不权威),老黄听了都摇头 😂。 而更低维度的分词,可以压缩词表的数量,[I, lo, ve, 00, 7]是我瞎写的,理解意思就行,让 DS 给我们举一个更好的例子:
假设语料库包含以下高频单词:
- play (10 次)
- player (8 次)
- playing (6 次)
- plays (5 次)
- replay (7 次)
- replaying (4 次)
直接按空格分词会生成独立词表:
空格分词词表大小:6
[play,player,playing,plays,replay,replaying]
#bpe分词算法最终词表(目标大小=4)
#Ġ表示这个token只会出现在开始,想一想还原句子的时候你需要知道两个token是拼起来还是插入空格
[Ġplay,re,ing,er]
对比空格分词, /bpe 分词算法/ (想了解的自行 ds,限于篇幅不赘述)可以有效压缩词表大小,在大量语料的情况下会更明显,40GB 数据的 GPT2 也仅 5w 词表大小
嵌入(embedding)
现在,我们有了词表,很容易就可以得到二进制的序列了
还是老例子:
我 爱 00700 被编码为 [1, 2, 3] (为了方便,这里假设分词就这样。)
我们可以直接输入到网络训练了吗? 答案是否定的,不过我们也终于来到了有意思的地方。
在在训练之前需要做一个 /嵌入/
来一个 youtobe 的动图看下 /嵌入/ 大概是啥。

再来一个 DS 的灵魂解释:
嵌入(Embedding)的核心思想是 将复杂、高维的数据(如文字、图像)转化为低维、连续的数值向量,同时保留其内在的语义或关系 。这种转化让计算机能像人类一样“理解”数据的含义,并用数学方式计算相似性、分类或生成。
额... 有点抽象,似乎讲了些什么,又似乎什么都没讲......
没关系,让我来举一个形象的例子
观察下面的句子:
红色
当红明星
生意好红火啊
注意"红"这个字,发现了吗,在不同语境(或者说维度)它有不同的意思,如果我们直接输入 token 编码,这些信息是缺失的,模型就不太可能理解句子的意思。
那么,一个字或者说一个 token 到底有多少维度的语义呢?不知道啊 🤷,但是没关系,猜一个, 512。 没错,就是这么朴实无华!
于是我们就有了

即 E 是一个 32000x512 的二维矩阵 (代码里就是数组)
E[1,1] E[1,2] ...... E[1,512] 的值表示词表中序号为 1 的词在维度 1、2、512 的语义, 由此同样一个“红”的 token,就可以有多种语义,这样模型就可以理解词和句子了。
当我们输入 我 爱 00700 被编码为 [1, 2, 3] , 实际上我们应该输入:

请注意请注意,所谓一个字有不同维度的语义,是我现编的比喻,如果它帮到你理解这个东西那最最好,如果觉得比喻得不太对,大可一笑了之。
继续

(以三维举例,512 维可以发挥想象力自行脑补)
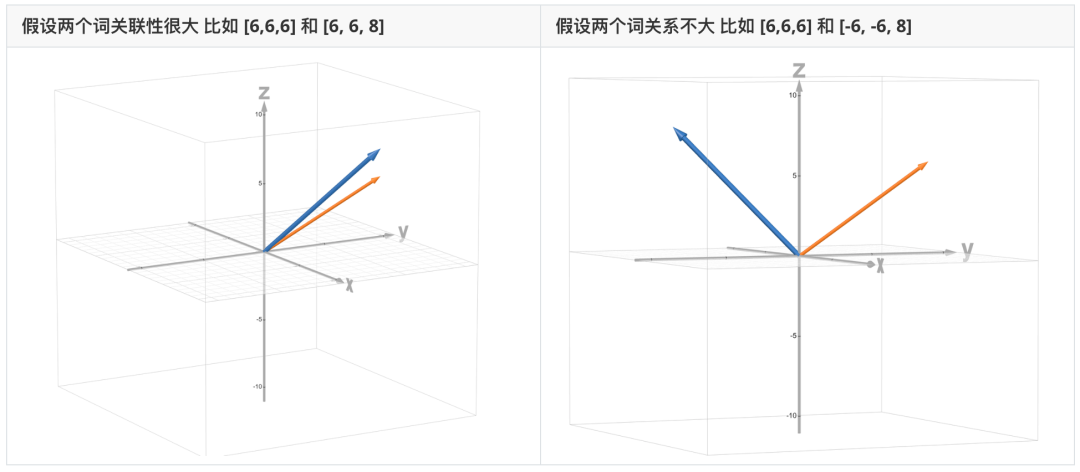
为了让模型理解词和词的关系,我们用数学语言去描述这种关系,就是向量的内积:

就算忘记了向量内积怎么算也没关系,我们只需要理解,夹角越小,向量内积越大, 两个词的关联越紧密就行了。 实际上大部分复杂公式的计算都是封装好了的。 这里的内积,在自注意力的时候我们也会用到。

答案是模型自己学习出来的,E 是模型的参数的一部分,一个词每个维度的值,初始化是一个随机值,模型训练的时候会被更新。
怎么学出来的? 试想一下: 语料里面有无数的词,但是他们是有一定的关联的,比如 I love 这两个词经常同时出现,那么他们的内积就应该较大,反之也一样。实际上有点像聚类,怎么理解都行,模型学得差不多的时候,token 的分布或者说嵌入向量的关系,一定是有规律的。
让我们来用数学语言总结一下嵌入:

就是我们的查表或者说嵌入操作:


为什么这里也会叫查表? 实际上对索引为 1 的 token 做嵌入,就是在嵌入矩阵里到找第一行然后拿出来,就是 E[1,1] E[1,2] ...... E[1,512] 。这个过程不就是查表么。
Batch 处理
细心的你可能发现了问题,这里多了一个维度 B,输入的结果
,是三维的。这里解释一下,我们的例子只有一句话,但是在模型的训练中,其实是一次性输入多句话并行计算的,batch_size 的值就是你一次性输入多少句子来训练,一般来说,这取决于你的显存大小,自行尝试调整就可以了。
假设 batch 为 2,一次输入两句:

两句话的 embedding 矩阵合并,得到一个 2x3x512 的三维矩阵 就是我们给编码器的输入了。 此时 B=2 L=3 D=512

padding 掩码矩阵
还没完,让我们来一点刁钻的问题。 上述例子 L=3,两个句子长度都一样=3。 如果句子长度不一样呢?batch 矩阵岂不是拼不出来? 当然不会,实际写代码的时候,L 一般都是取一个较大值,比如语料中最长句子的值。L=100。 不够长的句子怎么办呢? 补 padding,注意不是 0,因为神经网络的某些中间计算如 softmax 输入 0 也是有值的。 一般是用一个特殊的 token 作为 padding。

在自注意力计算的时候(下文会讲)会根据 padding 的位置,生成 mask 矩阵,计算时候 padding 替换为一个极小值比如-1e9,就可以不影响计算了。
PositionalEncoding
现在这个带 padding 的矩阵可以输入模型开始训练了吗? 还是不行..... 我们还缺少一个重要的信息,位置。
举一个例子:
[[0.3,0.5,0.1,0.4]
[猫,吃,鱼]=>Transformer=>[0.1,-0.6,-0.2,0.3],
[0.3,0.5,0.3,-0.1]]
[[0.3,0.5,0.1,0.4]
[鱼,吃,猫]=>Transformer=>[0.1,-0.6,-0.2,0.3],
[0.3,0.5,0.3,-0.1]]
很明显,虽然只是交换了一个字的顺序,但其实是两个完全不同意义的句子, 而 Transformer 输出的分布却是不变的,说明网络没有办法识别位置信息。
为了解决这个问题,Transformer 的论文里的方案是添加位置编码,也就是 PositionalEncoding。
其实没有那么神秘,我们把 Transformer 看成函数 T, 现在的问题是:

我们可以加上一个位置编码 P 去规避这个问题

- i: 当前的位置序号
来一个简单粗暴易理解的 P(i) = i
猫0
吃1
鱼2
然后呢?就是简单的直接加上去

没错,这样其实我们的输入就包含了位置信息了,只要信息在那里,模型总能学明白
当然,这里只是为了方便说明位置编码本身,所以用了最简单的方案,你说它能不能跑,那肯定也是能跑的,就是会有不少问题,实际上论文里实现是正弦 torch.sin(position div_term)和余弦函数 torch.cos(position div_term)来生成位置编码, 解释起来就篇幅太长,大家可以自己探索。
位置编码不改变矩阵的维度,只是改变了数值, 我们给编码器的最终输入总结如下:

但是对于解码器的输入,还需要额外处理,继续往下。
并行计算 & Teacher Forcing
回顾下一开始的例子
第一个循环
编码器输入我爱00700
解码器输入<bos>
输出I
第二个循环
编码器输入我爱00700
解码器输入<bos>I
输出love
第三个循环
编码器输入我爱00700
解码器输入<bos>Ilove
输出00700
第四个循环
编码器输入我爱00700
解码器输入<bos>Ilove00700
输出<eos>
//输出了结束符,翻译完成
我们给编码器的输入始终是整个句子序列的 embedding。而给解码器的输入,则是当前已经预测出来的 n-1 个词的序列的 embedding。
并行计算
当你真的上手去写代码的时候,你就会发现, 在训练阶段,代码里我们给解码器直接输入完整的句子 I love 00700
,且模型输出直接就是整个句子。 只有一个循环。你现在肯定满脑子问号,直接输入正确答案了,还学什么?
别急,实际上我们输入不是全部的 ground truth,是 n-1 序列的 ground truth。怎么理解呢?真正的 ground truth 是 I love 00700 eos 。 我们的输入是 I love 00700。 当然这样仅仅是少了最后一个 token 的答案而已。
实际上解码的输入(姑且叫 trg_input)在做计算的时候还需要做一个 causal mask,叫做因果掩码,字面意思就是为了防止计算的时候知道未来的信息。
>>>trg_input#假设我们的input长这样1234代表<bos>Ilove00700
tensor([[1,2,3,4],
[1,2,3,4],
[1,2,3,4],
[1,2,3,4]])
#因果掩码矩阵是这样的,对角线上移一位的上三角矩阵,上三角的元素是极小值
>>>mask=torch.triu(torch.ones(4,4),diagonal=1)
>>>mask=mask.float().masked_fill(mask==1,float(-1e9))
>>>mask
tensor([[0.,-inf,-inf,-inf],
[0.,0.,-inf,-inf],
[0.,0.,0.,-inf],
[0.,0.,0.,0.]])
>>>
#执行causalmask
>>>trg_input+mask
tensor([[1.,-inf,-inf,-inf],
[1.,2.,-inf,-inf],
[1.,2.,3.,-inf],
[1.,2.,3.,4.]])
看看 causal mask 结果的第一行,[1., -inf, -inf, -inf] 其实就是相当于第一轮循环的输入 bos, 因为无限小在计算的时候可以忽略。 后续的 2、3、4 行刚好也就是 对应的 2、3、4 轮循环。 get 到了吗, 直接作为一个矩阵输入,在模型里并行计算,4 个循环优化成了一个!能够并行计算,这正是 transformer 一个重要特性。
Teacher Forcing
想一想为什么我们可以实现并行计算? 因为训练的时候,我们提前知道了正确答案,在生产环境推理过程中,我们不可能知道第一个 token 应该输出 I,第二个 token 应该输出 love ...., 所以推理的时候,只能顺序执行循环。
再多想一点,在训练的时候,模型还并不成熟,第一个字符输出的未必是 I,假设输出了 He 呢? 然后第二轮循环我们的输入就是 bos He, 这样继续循环下去只会越来越错,非常不利于学习的收敛。 所以,我们第二轮循环不输入 He, 而是用正确答案 I 来继续下一个 token 预测,实验表明这样学习的速度会更快。 这种训练方法,我们就称之为 Teacher Forcing。
关于并行计算和 Teacher Forcing 感觉大部分文章都是一笔带过,而我感觉这里很重要,包括理解架构本身或者是去理解为什么 transformer 带来了技术的爆发,并行计算是一个很重要的因素。
输入输出的代码实现
作为一个严谨的工程师,最后我贴一下我自己的实现,并做简单讲解:
#关于语料我的数据集来自wmt17v13zh-en大约100m30+w行长句子
#从csv读出来,第一列是中文第0列是英文
train_data=read_tsv_file(opt.train_tsv,1,0,opt.delimiter)
valid_data=read_tsv_file(opt.valid_tsv,1,0,opt.delimiter)ifopt.valid_tsvelse[]
test_data=read_tsv_file(opt.test_tsv,1,0,opt.delimiter)ifopt.test_tsvelse[]
#分词器初始化我这里是bpebytelevel32000词表大小,具体实现太长就不贴了
src_tokenizer_path=os.path.join(opt.data_dir,"tokenizer_zh.json")
src_tokenizer=train_tokenizer([srcforsrc,_intrain_data],opt.vocab_size,src_tokenizer_path)
trg_tokenizer_path=os.path.join(opt.data_dir,"tokenizer_en.json")
trg_tokenizer=train_tokenizer([trgfor_,trgintrain_data],opt.vocab_size,trg_tokenizer_path)
#有了分词器之后,对训练数据句子分词打包成pkl格式,方便模型训练的时候读取
processed_train=process_data(train_data,src_tokenizer,trg_tokenizer,opt.max_len)
#train阶段
#从pkl加载数据略
#训练输入
fori,batchinenumerate(dataloader):
#准备数据每次循环处理一个batch的数据
src=batch['src'].to(device)#取出语料原文。我爱00700(举例,实际上batch是多句的数组,但是矩阵运算的时候都是一起并行算的)
trg=batch['trg'].to(device)#取出语料目标译文。bosIlove00700eos
trg_input=trg[:,:-1]#去掉最后一个token,bosIlove00700n-1的TeacherForcing序列
trg_output=trg[:,1:]#去掉第一个token,Ilove00700eos真实的groudtruth,用于计算损失
#前向传播清空梯度
optimizer.zero_grad()
#输入模型计算一次
#teacherforcing:trg_input实际上就是groundtruth(正确的值)
#train模式下,output是整个句子的预测值
output=model(src,trg_input)
......
#嵌入
"""初始化嵌入矩阵"""
#使用正态分布(高斯分布)初始化张量
#均值为0,标准差为0.02
#在数学上,512维的随机向量,可以认为是互相正交的(就是任意两个token之间一点关系都没有)
nn.init.normal_(self.weight,mean=0,std=0.02)
#基本的嵌入查找
#weight是模型参数,自动参与学习
embeddings=self.weight[x]
#mask
"""创建源序列和目标序列的掩码"""
src_padding_mask=(src==self.pad_idx)#srcpadding掩码
trg_padding_mask=(trg==self.pad_idx)#trgpadding掩码
#因果掩码
seq_len=trg.size(1)
trg_mask=torch.triu(
torch.ones((seq_len,seq_len),device=src.device),diagonal=1
).bool()
returnsrc_padding_mask,trg_padding_mask,trg_mask
#应用mask我这里的mask是bool矩阵,true表示需要mask
#如果mask是true,scores对应位置的元素就填充为极小值-1e9
ifmaskisnotNone:
scores=scores.masked_fill(mask==True,-1e9)
输入输出终于写完 看到这里就真的不容易 感谢~!
自注意力机制
到这里我们已经完成了输入的所有前置处理,训练数据开始进入到网络训练。 而理解Transformer网络的关键就在于自注意力机制,如下图所示的三个模块,他们是整个网络的核心。
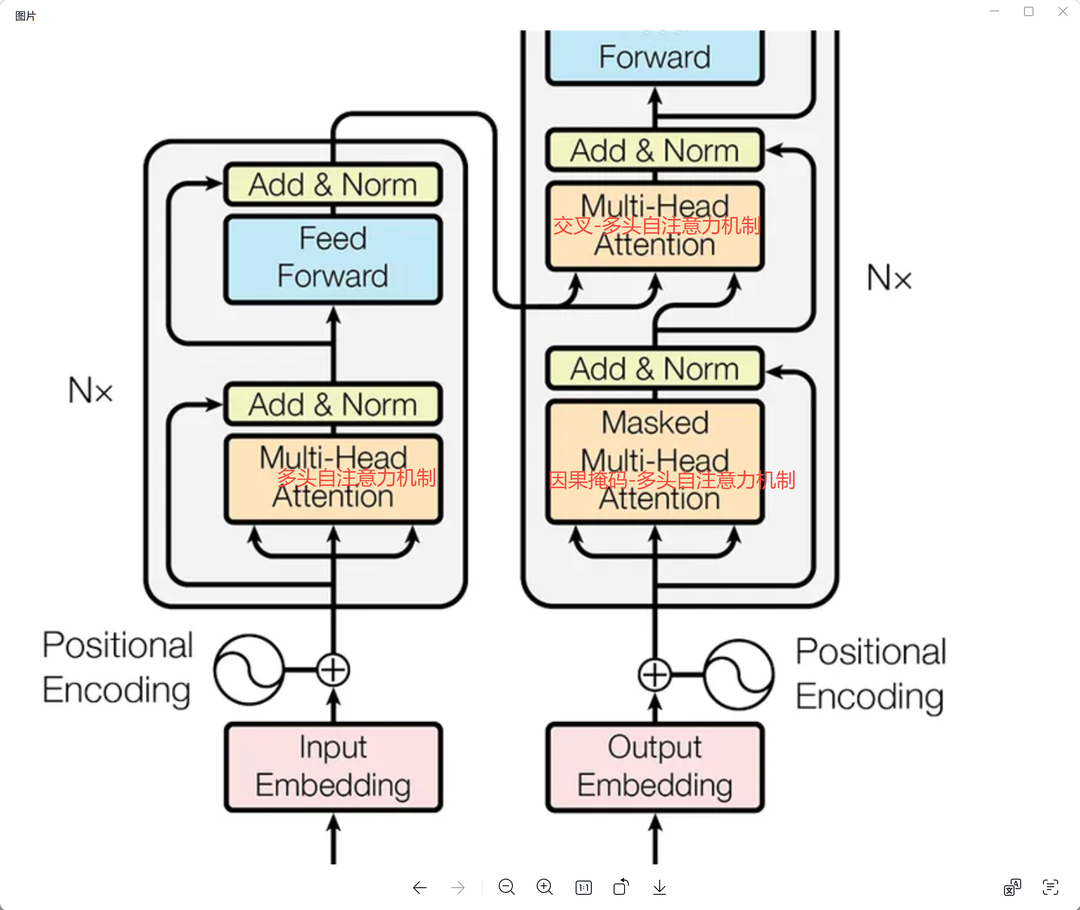
注意力机制
注意力其实非常好理解, 如下图: 万绿丛中一点红,你首先看到了红,这就是注意力。

在训练网络中,注意力的作用是什么呢?
老例子:“ 我 爱 00700 ” 翻译为 “ I love () ” () 为当前正在预测的词。
如上图, 前面我们介绍过 Transformer 预测下一个词的时候,会结合整个上下文,即“我 爱 00700 I love”,假如没有注意力机制,那么所有词对预测结果的贡献是一样的! 假设语料的言情文偏多,那输出很可能是 I love you, 很明显不合理, 此时我们希望网络把注意力集中在“00700”这个词上,其他词应该忽略掉。

- x ∈ R^(seq_len, d_model) seq_len 是句子长度,d_model=512 是 embdedding 的纬度,忘了的话往回翻复习下吧
- W ∈ R^(512, 512) 是权重矩阵
??? 解释了这么久 就这? 没错是的 🤷♀️ 取个高大上的名字而已
自注意力机制
自注意力毕竟多了一个字,肯定还是有点不一样的,不一样在哪呢,他乘的不是权重矩阵,它乘它自己!

如果你对矩阵乘法熟,你马上就会意识到,这不就是句子的词和词之间的内积吗?
回忆一下嵌入的内容,我们说过词向量的内积反应的是词的关系远近。
本质是,Transformer 通过句子本身的词和词之间的关系计算注意力权重! 所以我们叫它 - 自注意力 !还算自洽吧~
当然,直接相乘没有参数可以训练啊,来个线性变换吧 ,于是

不好记,得起个名字, 第一个式子是原始请求 就叫 Query 吧,简写为 Q
感觉不用纠结这个命名,反正论文没提命名的道理 自行想象吧

第二个式子是被用来计算关系的,就叫 Key 吧,简写为 K

于是:

按照论文所提,实验发现,QK 点积可能会过大,数据方差太大,导致梯度不太稳定,所以需要把分布均匀一下,于是:

我们需要的是权重,所以需要转化为 0.0~1.0 这样的值,这正是 /softmax/ 函数的能力 于是:

另外为了增加网路的复杂度,我们不直接乘 x,老办法,线性变换一下, 记为 V

最终

最终我们得到了和论文一模一样的公式~
多头注意力机制
先看一个图,这是一个自注意力计算的示例:
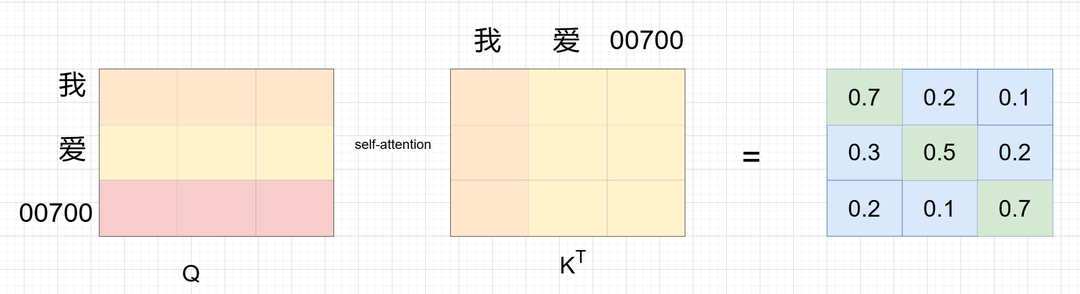
问题是: 我 - 我 爱-爱 00700-00700 的分数最高, 自己最关注自己,听起来是合理的,但论文作者应该是觉得这不利于收敛。 所以提出了多头机制
其实这里论文并没有太多解释,我理解是一种实验性的经验
那么什么是多头? 其实也很简单,就是分块计算注意力,好比原来是一个头看整个矩阵, 现在是变身哪吒三头六臂,一个头看一小块,然后信息合并。 画图说明:
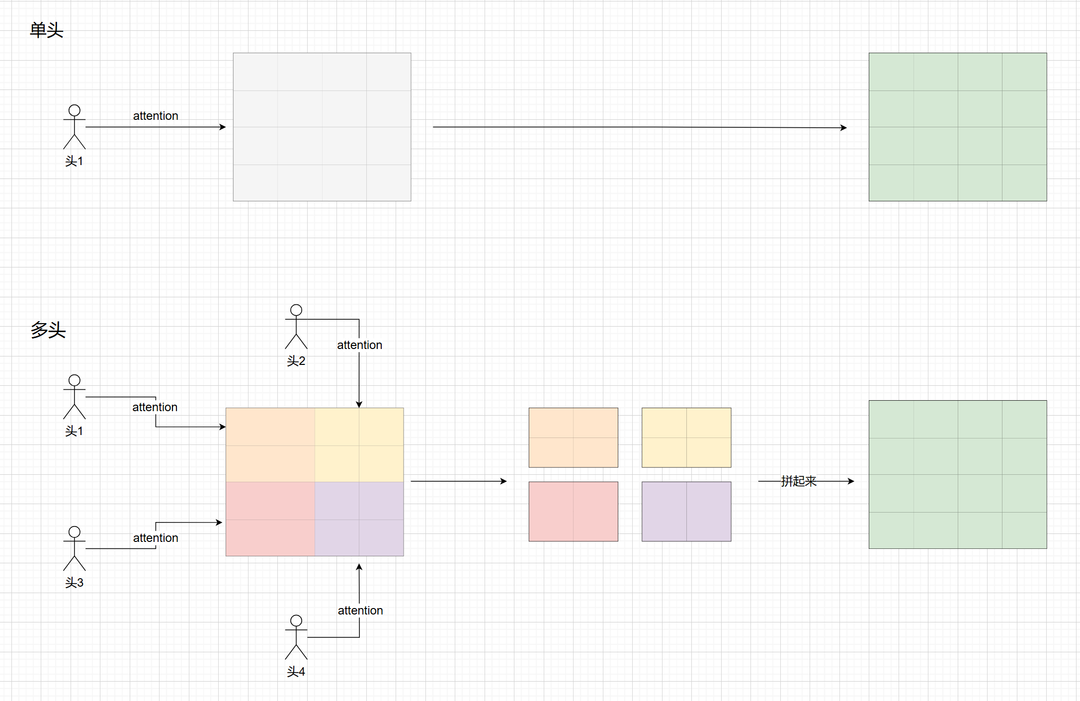
这种分头其实本质上计算量是一样的,只是注意力分块了,直接看公式就好了。

- Q, K, V 是输入矩阵,形状为 (batch_size, seq_len, d_model)
- W_i^Q ∈ R^(d_model × d_k)
- W_i^K ∈ R^(d_model × d_k)
- W_i^V ∈ R^(d_model × d_v)
- head_i 的形状为 (batch_size, seq_len, d_v)
论文中 i=8, 8 个头, dk =dv = d_model/8 = 64
因果掩码-多头自注意力机制
其实输入输出的时候就讲了,就是解码器做多头计算的时候 使用 teacher forcing,需要加上因果掩码 mask。 下面代码说明。
交叉-多头自注意力机制
解码器如何结合编码器的上下文就在这里了,如果是交叉-多头自注意力机制,那么 Q = x, K=V=编码器的输出,直接看代码最直观。
#1.线性变换这里的query=key=value就是x
#如果是解码器的交叉-多头自注意力机制,那么query=x,key=value=编码器的输出
Q=self.q_linear(query)#这里的linear就是线性变换wx+b,下同
K=self.k_linear(key)
V=self.v_linear(value)
#2.分割成多头[batch_size,seq_len,d_model]->[batch_size,seq_len,num_heads,d_k]
#实际上torch的张量(矩阵)是用一纬数组存的,所谓分割多头、转置,最终就是改一下数组元素的顺序
Q=Q.view(batch_size,-1,self.num_heads,self.d_k).transpose(1,2)
K=K.view(batch_size,-1,self.num_heads,self.d_k).transpose(1,2)
V=V.view(batch_size,-1,self.num_heads,self.d_k).transpose(1,2)
#3.计算注意力
#K.transpose(-2,-1)就是k的转置
scores=torch.matmul(Q,K.transpose(-2,-1))/math.sqrt(self.d_k)
#4.应用mask因果掩码或者padding掩码
ifmaskisnotNone:
scores=scores.masked_fill(mask==True,-1e9)
#5.softmax获取注意力权重
attn=F.softmax(scores,dim=-1)
#dropout是随机丢弃一些值(写0),为了增加随机性,训练时才会开启,避免过拟合
attn=self.dropout(attn)
#6.注意力加权求和就是乘v
out=torch.matmul(attn,V)
#7.重新拼起来多头把维度转置回来
out=out.transpose(1,2).contiguous().view(batch_size,-1,self.d_model)
#8.最后又加了一个线性变换wx+b,不要为问我为什么......实验性经验
out=self.out_linear(out)
returnout
前向传播
到这里就很简单了,核心的部分都讲完了。 还剩下几个小块简单讲一下。
Add & Norm
Add 叫残差,超级简单,直接上代码:
#self_attn就是算注意力,tgt_mask是因果掩码。
#本来应该是x=self.dropout1(self.self_attn(x2,x2,x2,tgt_mask))
#残差就是多加了x,x=x+self.dropout1(self.self_attn(x2,x2,x2,tgt_mask))
#简单解释就是加这个x,防止梯度下降太快到后面没了。详细就不展开了,可自行gpt
x=x+self.dropout1(self.self_attn(x2,x2,x2,tgt_mask))
Norm 是归一化,简单解释一下,归一化是让数据分布更均衡,一般是消除一些离谱值、不同数据量纲的影响。 比如分析年龄和资产对相亲成功率的影响,年龄只有 0-100, 资产的范围就很大,计算的时候就不好弄,需要把资产也缩放到一个合理的数值范围 比如 0-100 万。
归一化有很多种,这里用的是 /Layernorm/ ,这个公式还挺复杂,有兴趣可以自己研究,这里我是偷懒的:
#直接使用pytorch的自带公式
self.norm1=nn.LayerNorm(d_model)
#调包就完事
x2=self.norm1(x)
FeedForward
前馈全连接层(feed-forward linear layer) ,好多文章试图解释这个意义,其实没啥意义,就是普通的两层网络, 一般来说就是一层神经网络就是 线性变换+激活函数。
线性变换,无非就是升维和降维。举例:升维是类似于你看图片的时候,双指放大,然后滑来滑去找到你需要的,是特征放大。降维么,就是截图保存放大部分,然后输出,是特征提取。
一升一降就是 FeedForward 啦,直接看代码:
classFeedForward(nn.Module):
def__init__(self,d_model:int,d_ff:int,dropout:float=0.1):
super().__init__()
#从dmodel升维到d_ff=2048论文的值
self.linear1=nn.Linear(d_model,d_ff)
#降回来提取特征
self.linear2=nn.Linear(d_ff,d_model)
self.dropout=nn.Dropout(dropout)
defforward(self,x:torch.Tensor)->torch.Tensor:
#怎么找到关注特征的那不就是激活函数F.relu,很明显,神经元被激活的地方就是感兴趣的特征啊。
returnself.linear2(self.dropout(F.relu(self.linear1(x))))
解码器
到这里就没啥了,每个块我们都理解了,后续就是实现逻辑了。 直接上代码,太长了好像没必要,文末尾放 git 地址把。
编码器
同上。
反向传播
前向传播计算出一次训练的结果,反向传播就是根据结果的好 or 坏,更新参数,循环往复,最终得到一个满意的模型。
自己实现 实在是有点累,调包只需要一句:
#前向传播
output=model(src,trg_input)
......
#计算损失
loss=criterion(output_flat,trg_output_flat)
#反向传播
loss.backward()
pytorch 框架会记录你整个模型前向传播的图,然后根据损失,使用 /链式法则 / & /梯度下降算法/ 帮你回溯计算更新每一个参数,太舒服了~
/链式法则 / & /梯度下降算法/ 讲的好的文章很多,实在写不动了,况且文章也够长了.... 大家自行 gpt 吧~
参考
为什么 Transformer 需要进行 Multi-head Attention?
Transformer 模型详解(图解最完整版)
探秘 Transformer 之(8)--位置编码
END
作者:Plus
文章来源:腾讯技术工程
推荐阅读
更多腾讯 AI 相关技术干货,请关注专栏腾讯技术工程 欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

