
在今天的数据中心 AI 硬件产业链中,NVIDIA 可能比手机界的苹果过得还舒服?市场份额和利润都拿着大头——我是指的训练和推理芯片(GPU)部分。在这背后离不开 CUDA 相关的软件生态,以及 NVLink(Scale-Up 网络)互连的技术优势。
AI 集群中的跨节点 Scale-Up 互连难题
搞 AI 服务器/数据中心算力硬件的朋友,估计对下面这张 DGX H100 架构图不陌生了。8 个 H100 GPU 通过 4 颗 NVSwitch 芯片组成高速互连,在节点内能充分发挥每个 GPU 900GB/s 的 NVLink 带宽。另外 NVSwitch 还能对外通过 OSFP 连接到 NVLink 交换机,实现更大范围的跨主机 Scale-Up 互连,这里的收敛比是 2:1。
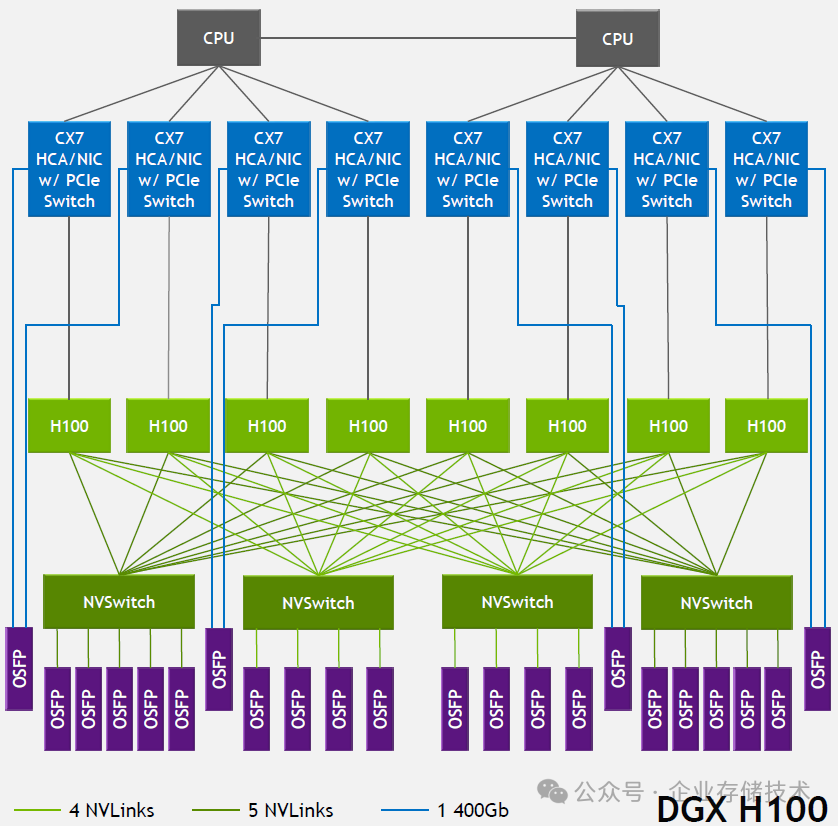
下面引用一段 NVIDIA 官方说明:
全带宽服务器内 NVLink
- 所有 8 个 GPU 可同时饱和连接服务器内其他 GPU 的 18 条 NVLink
- 仅受限于多 GPU 的过载争用
半带宽 NVLink 网络
- 所有 8 个 GPU 可半占用连接其他服务器 GPU 的 18 条 NVLink
- 4 个 GPU 可饱和连接其他服务器 GPU 的 18 条 NVLink
- 通过 SHARP 实现与全带宽等效的 AllReduce 性能
- All2All 带宽的降低是服务器复杂度与成本的权衡结果
多通道 InfiniBand/以太网(Scale-out 互连)
- 所有 8 个 GPU 均可通过独立的 400Gb/s 专用 HCA/NIC 进行 RDMA 数据传输
- 与非 NVLink 网络设备间实现 800GB/s 聚合全双工带宽
由于 AMD 是 UALink 的发起者并贡献了 Infinity Fabric Links (xGMI) 内存一致性互连协议,下面我就拿 AMD 当前的 GPU 做个简单对照:
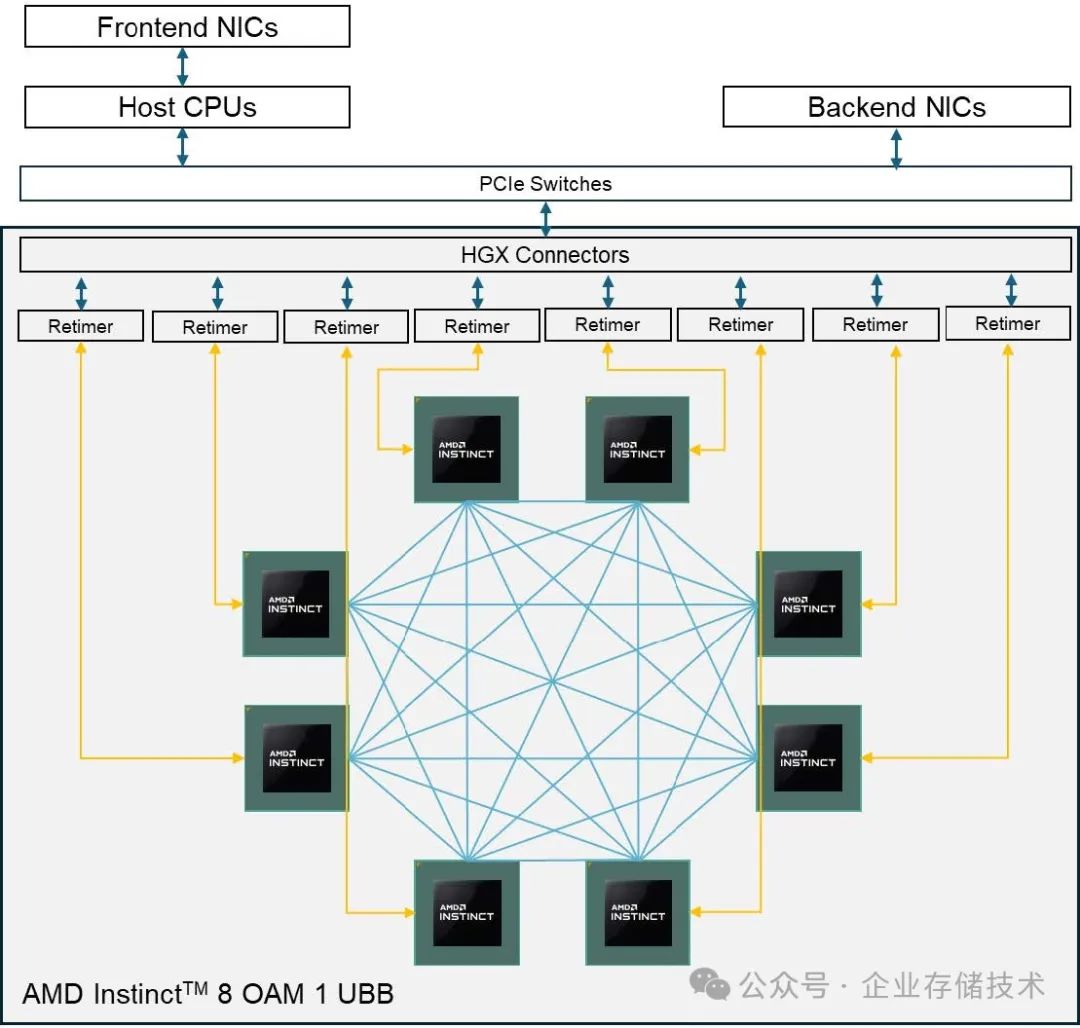
上图引用自技术文档《AMD Instinct™ MI300 Series Cluster Reference Architecture Guide》,新推出的 MI325X 应该也是同样的互连架构——8 颗 OAM 形态 GPU 在 UBB 板上,形成点对点全网状互连的方式。这个总带宽也不错,没有 NVIDIA DGX 系统上那 4 颗 NVSwitch 成本还能降低。不过一旦需要跨主机扩展 AI 集群,GPU 就要通过 PCIe Switch 连接的网卡(Backend NICs),走 Scale-out 的方式来互连。
如果是推理应用还好,单机 8 块 GPU 的内存能容纳下绝大多数的 AI 大模型(包括 DeepSeek V3/R1 671B)。而一些较大参数量模型的训练应用,内存语义 Scale-Up 网络能够扩展的规模,在有些情况下还是有影响的。这也是 UALink 诞生的理由。
AI 芯片 UALink 带宽:达到 NVLink4 还是 5 水平?
下表中部分规格是我推测的,不一定准确。接下来我会列出相关素材和推断过程。

注 1:NVIDIA 官方资料习惯写全双工网络的双向总带宽,而在上表中我统一按照单向带宽来比较。
注 2:NVLink 每端口由 2 个 lane 组成;UALink 每端口支持 1、2 或 4 个 lane。所以在对比时,NVLink 的 18 端口相当于 36 个 lane。
下图引用自《Ultra Accelerator Link Consortium Inc. (UALink) - UALink_200 Rev 1.0 Specification》规范文档,由此基本可知,未来支持 UALink 的加速器(xPU)应该至少有能达到 32 lane 产品。
注 3:如果按照 200Gbps 和 32 lane 来计算,单芯片提供的 UALink 总带宽为 640GB/s(全双工)。
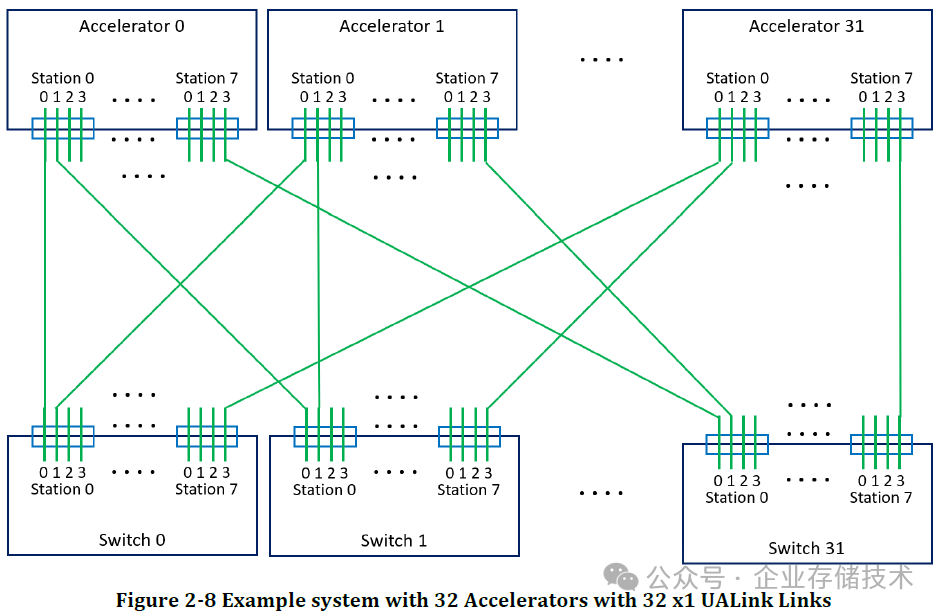
在上面的示例系统中,32 个加速器各自通过 32 个 x1 UALink 来连接到 32 个 Switch,这样应该是个理想的无阻塞全互连。我尝试着列出可能被认为不足之处:
1、需要的 Switch 数量有点多?和加速器一样了。这个问题其实不难解释,未来的 UALink Switch 芯片很可能不只 32 lane,参考 200Gbps 以太网,64/128 lane 应该都有可能?另外单个交换机盒子里也可以包含多个(如 2 个)Switch 芯片。
2、“全线速”的扩展规模。UALink 定义了加速器(xPU/计算芯片)最多支持 1,024 个。在上图的基础上,如果有 128 Lane 的 UALink Switch 芯片,使用 32 颗就可以把这种单层理想带宽的网络规模扩大到 128 个加速器。进一步的扩展,网络结构应该会复杂些,本文先不展开讨论了。

根据这个 AMD MI325X 的规格表,其中 Scale-up 网络是 7 个 Infinity Fabric™ Links——xGMI 的物理层与可以与 PCIe 复用,所以每条链路 128 GB/s 就相当于 PCIe Gen 5 x16 的双向带宽,一共 896GB/s(折算到单向为 448GB/s,比 NVLink4 略低)。
如果单芯片 UALink 200Gbps 能做到 56-64 lane,其 Scale-up 互连带宽将达到 1,120GB/s(全双工)乃至更高,是不是比当前 AMD GPU 的 Infinity Fabric 提高比较多了?我是这样看的:反正 PCIe 也要从 5.0 的 32GT/s 升级到 6.0 的 64GT/s,后续 Instinct GPU 本身就面临带宽提高的需求——不然怎么追赶 NVIDIA。
从 UALink 1.0 发布,到第一批产品发布大概还要 12-18 个月。我们当前看 NVLink5 有点高高在上,而对于未来的产品定义也要带着发展眼光,毕竟大家都不会停滞不前的。
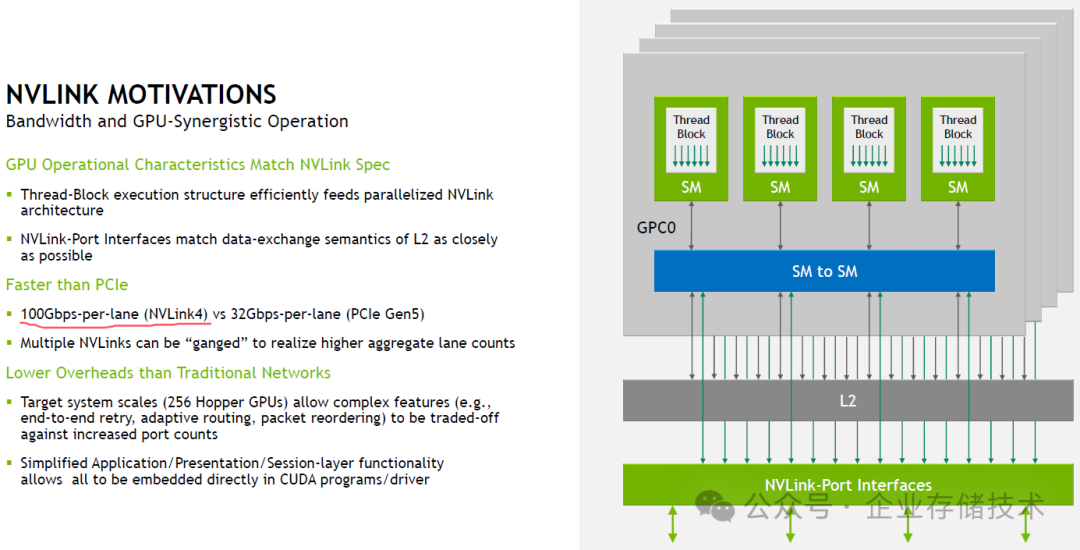
补充材料 1:NVLink4 的 100Gbps-per-lane
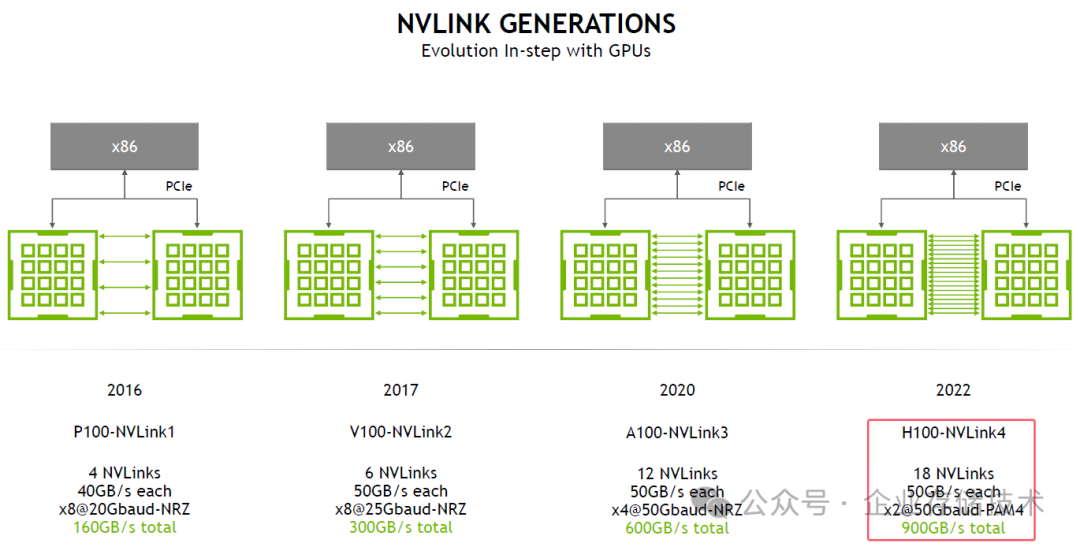
补充材料 2:18 NVLinks,每端口 25GB/s 全双工,x2@50Gbaud-PAM4;每颗 H100 芯片整体 450GB/s 全双工。
UALink 互连延时:与 PCIe & IB 相仿,优于以太网
这部分 The Next Platform 网站报道写得很好,我就引用了:
“AMD 贡献了其 xGMI 和更广泛的 Infinity Fabric 协议,这些协议在物理传输上工作,这些物理传输是 AMD 自己的 HyperTransport NUMA 互连和成熟的 PCI-Express 的混合体,然后该小组开始研究 PCI-Express,以消除所有冗余,以创建一个新的数据层和传输层,这是 UALink 独有的,并将其与一组围绕它的经过修改的以太网 SerDes 结合起来…
这些演示还表示,UALink 端口到端口跳转延迟将小于 100 纳秒。Onufryk 表示,根据 PCI-Express 交换机的基数和品牌,PCI-Express 交换机上的端口跳转延迟最低为 70 纳秒,最高为 250 纳秒。在 2000 年代后期的早期商用硅片时代,我们看到 10 Gb/秒以太网交换机的延迟为 350 纳秒到 450 纳秒,普通以太网交换机的延迟为 1 毫秒甚至 2 毫秒并不罕见。与 InfiniBand 交换机的 100 纳秒到 120 纳秒延迟相比,这个延迟很高。UALink 联盟没有强制执行延迟限制,因此供应商将按照自己的意愿行事。
AMD 架构与战略总监、UALink 项目的联合领导人兼 UALink 联盟主席 Kutis Bowman 表示,UALink 交换机的延迟在 100 纳秒到 150 纳秒之间’感觉合适’。”
几颗 ASIC?UALink Switch/交换机端口数展望
在预测未来的 UALink Switch 之前,我还是想先参考下 NVLink 交换机。
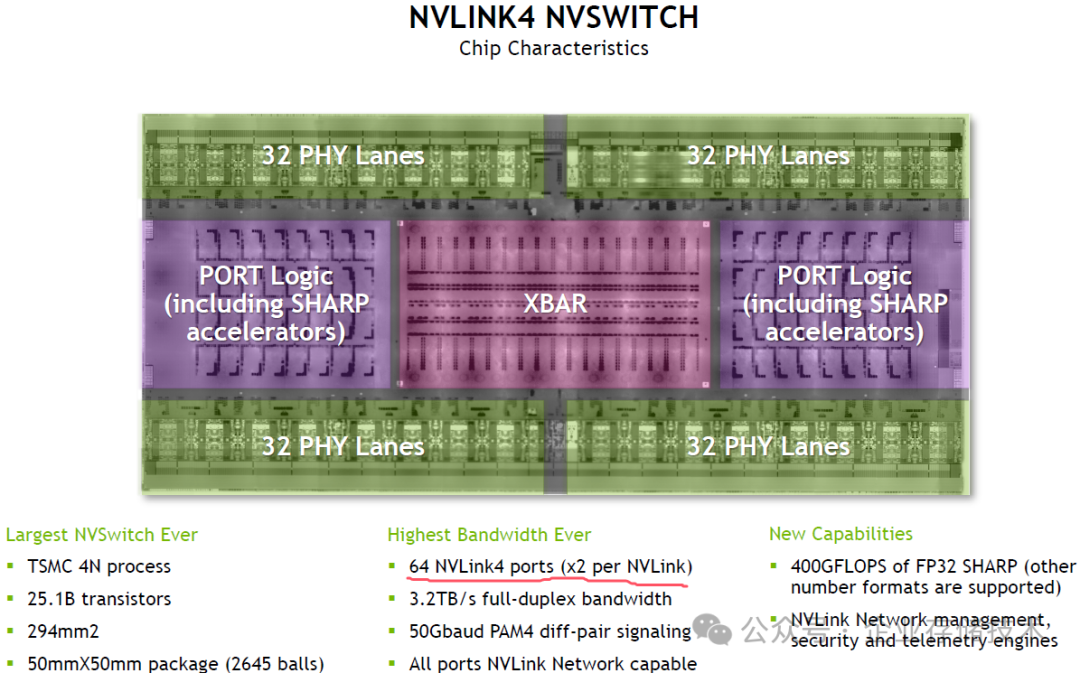
NVLink4 NVSwitch 单芯片具备 128 个 PHY Lane,由于每条 NVLink 使用 x2 lane,所以一共是 64 个 NVLink4 端口。

上图为 DGX H100 SUPERPOD(超节点)使用的 NVLINK SWITCH,用 2 颗 NVLink4 NVSwitch 芯片提供 128 端口。
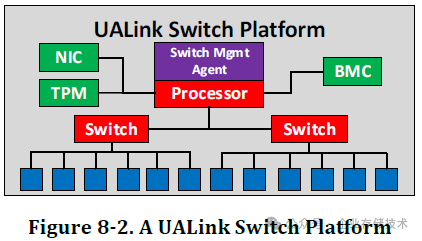
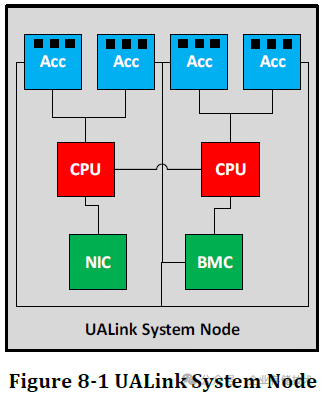
在 UALink Switch 平台架构图中,应该也支持 2 颗 Switch 芯片,交换机中还有管理 Agent 处理器、BMC、NIC 管理网口、TPM 等。
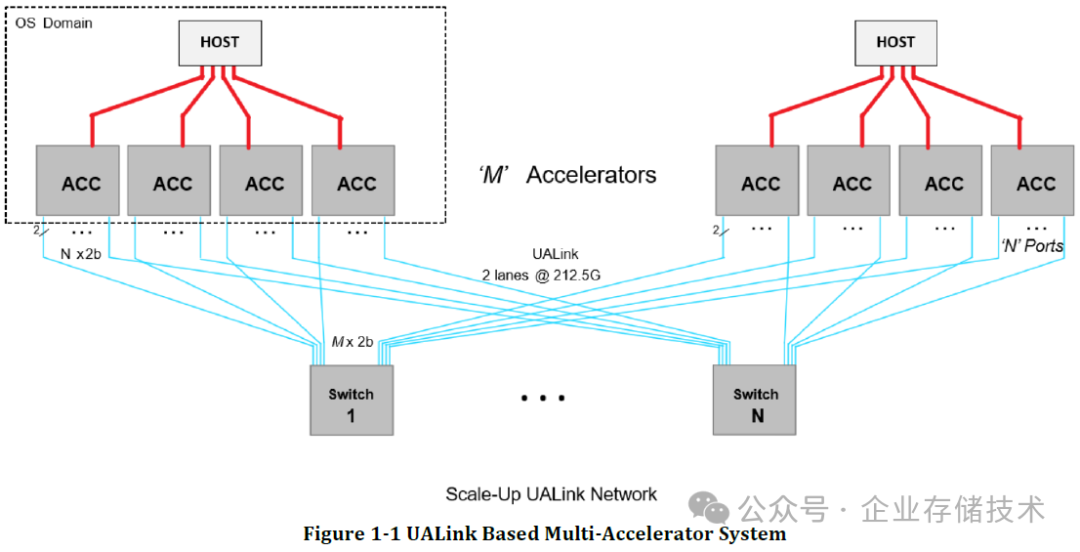
如上图,从 ACC 到 Switch 之间的 N 个连接,都是 x2b link。我觉得可能就是搭配双 Switch 芯片交换机来使用时,把每个进入到交换机的 x2b 拆分连接到 2 个 UALink Switch。
按照前文中 UALink Switch 芯片可能有 32/64/128 Lane 数的推测,如果交换机中包含 2 颗芯片,那么其支持的 Lane 数量乘以 2 就好了。
一种组合互连方式:节点内点对点+跨机箱交换
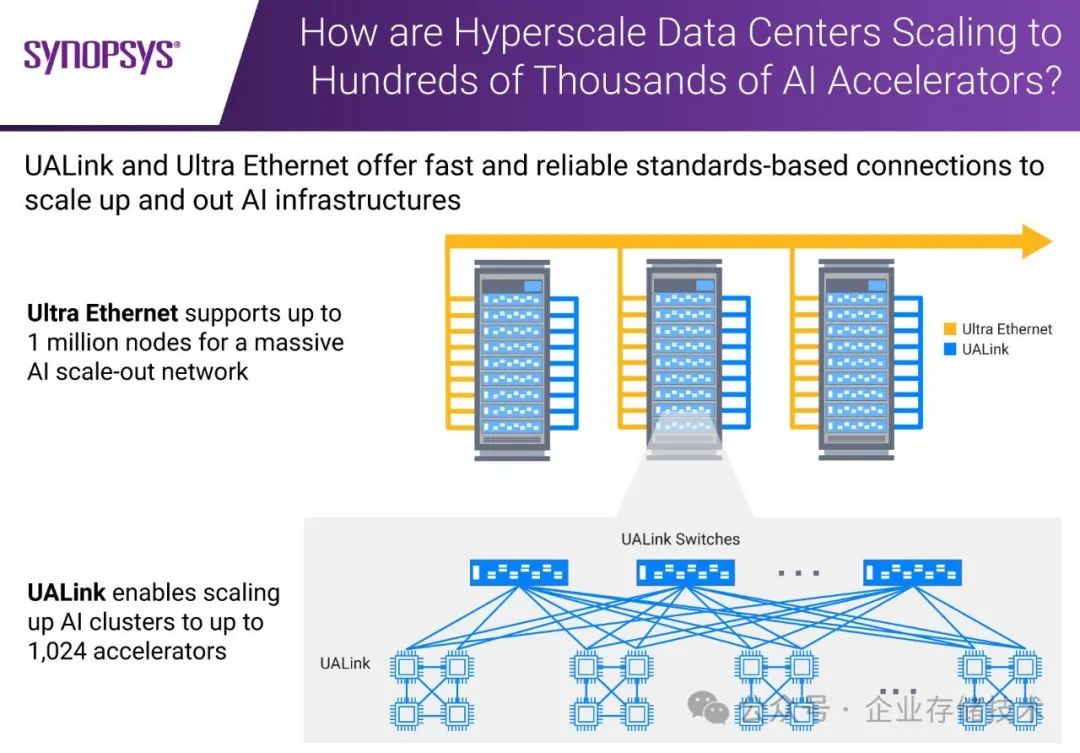
上图引用自 IP 提供商 Synopsys(新思)的资料。我看到一种 UALink 组合使用的方式:就是节点内 4 颗加速器通过 UALink 实现点对点互连,加上对外连接到 UALink Switch 的(节点间)扩展链路——虽然图中只画了上面 2 颗芯片到交换机之间的连线——看上去是不对称的,但技术原理上完全可以实现 4 颗对等的方式,所以可能只是为了方便画图而简略了。
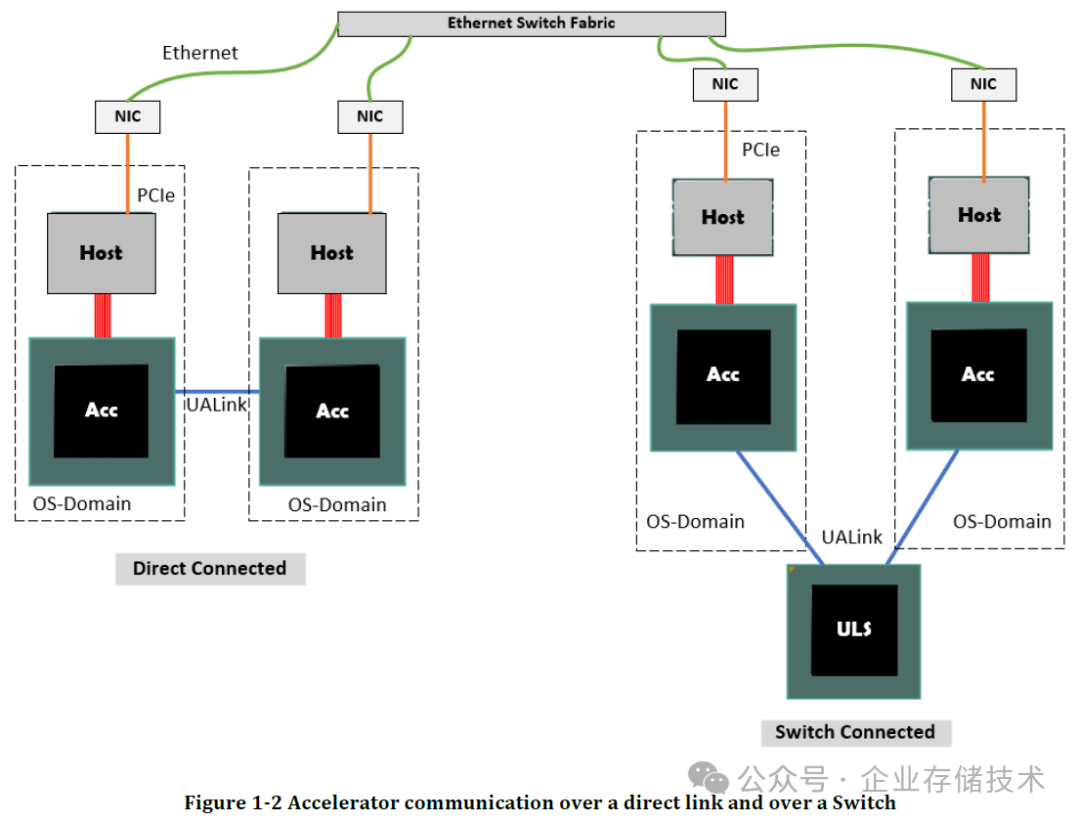
UALink 4 米铜缆的连接距离不如光纤,但在跨机箱和机架时,应该还是比 PCIe 表现好。
如果小规模使用,甚至可以无需 Switch 跨主机使用 UALink 直连——我还没看到过 NVLink 这样用。不过随着 CPU 核心数和性能越来越高,单路服务器的比例可能还会增大,如今的双 CPU+8 卡(xPU)机型,未来会不会有一部分演化成 2 节点“单 CPU+4 xPU”的形态?
UALink+UEC:有可能不需要 PCIe Switch 了?
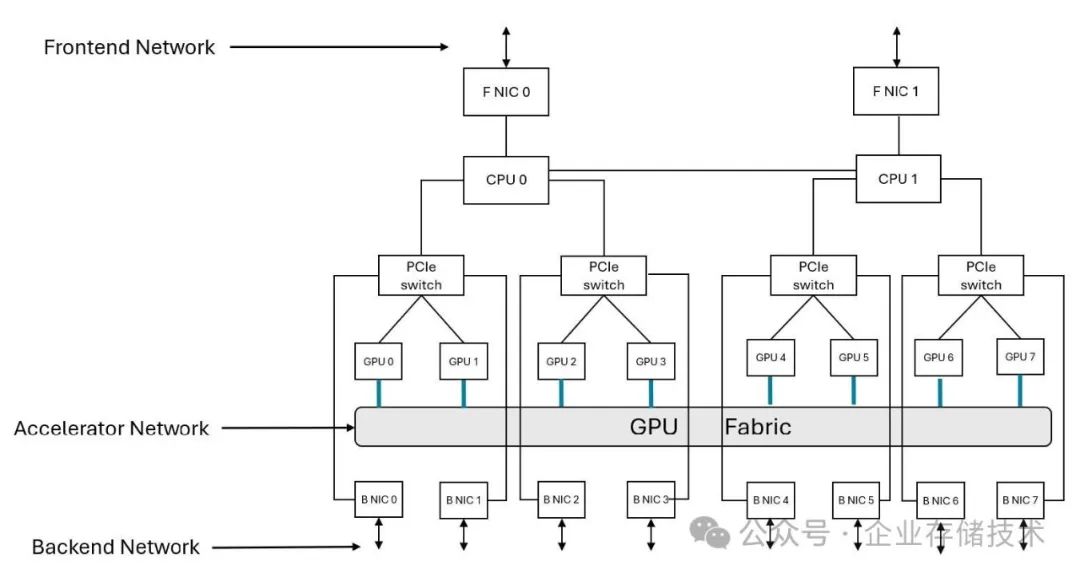
还是先看当前,NVIDIA DGX/HGX,以及 AMD M3xx 都符合上面这种典型架构。下面我来简单对比下 UALink 的节点及交换架构:
上面仅是一个简化概念图,不代表双 CPU UALink 系统只能配置 4 个 xPU 加速器。而我没看到 PCIe Switch 也是画图省略的原因吗,如果 CPU 和 xPU 的配比达到 1:4 呢?
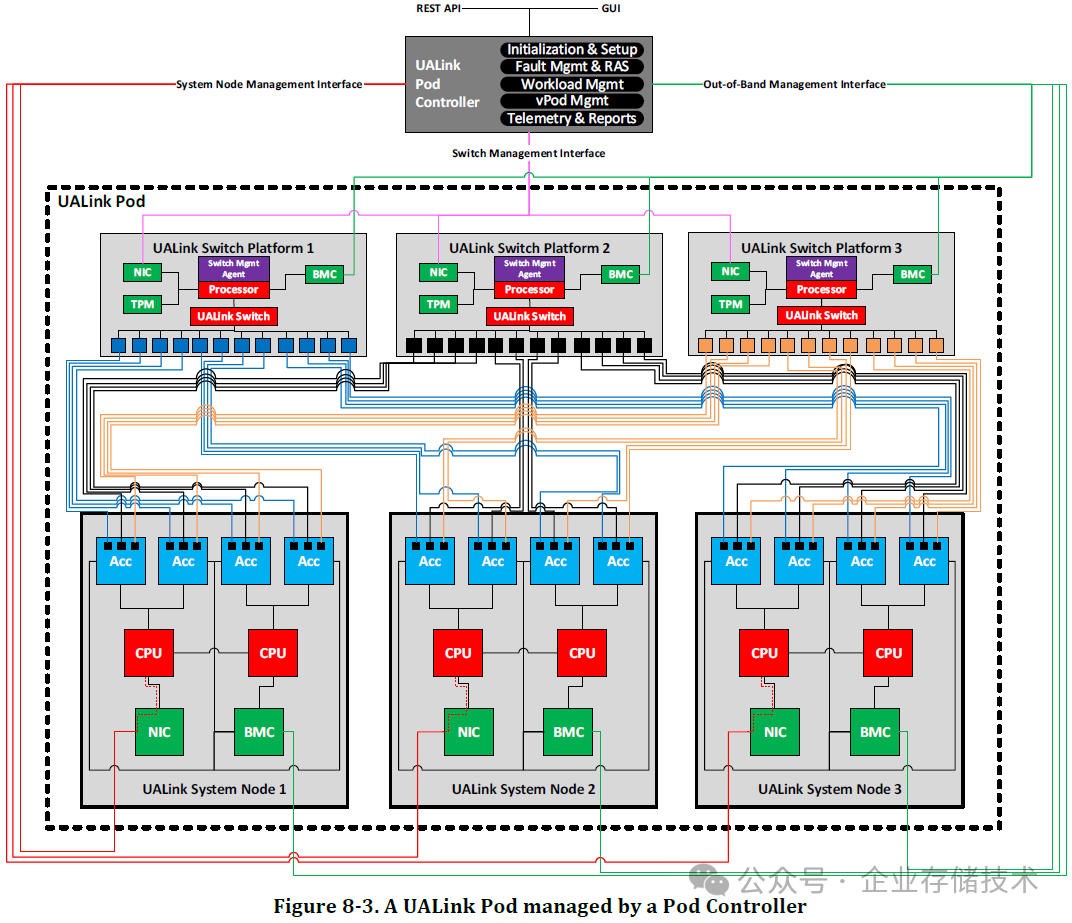
这里的 3 节点 UALink Pod 复杂程度,同样应该是按需来画的。比如我看到每个加速器有 3 个端口连接到不同的交换机;每个交换机画出了对应的 12 个端口——如果按照 4 lane 来计算,是不是代表 48 Lane 的 Switch 连接能力?可见这张应该也是概念示意图。
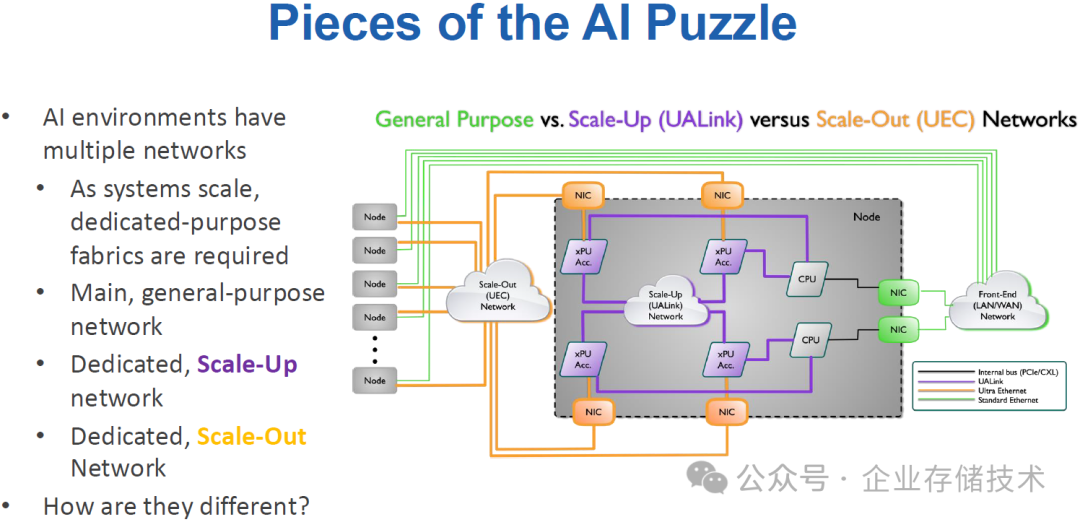
上图引用自去年 OCP 全球峰会的一份资料“Future of AI Networks: UALink and Ultra Ethernet”(不在我分享的《2024 OCP Global Summit 会议资料》中)。我倒是觉得似乎有不够严谨之处:
1、xPU 加速器到 NIC 之间的连接,如果也是橙色的 Ultra Ethernet,是不是相当于 xPU 同时提供了 UALink 和 UEC 接口——而 NIC 的角色是不是有点变成交换机了?当然这里很可能只是把 PCIe Switch 和 xPU Acc.画在了一起(并且为简单起见,隐去了一个芯片)。
2、CPU 与 xPU 加速器之间的连接是紫色的 UALink,我觉得也不是完全不可能?因为今天的 AMD CPU 具备 Infinity Fabric/xGMI,如果在未来的单路服务器配置中,CPU 通过 2-4 个 xGMI 连接 GPU 我不会觉得奇怪的。因为在 AMD 的资料中我曾经见过下图:

这里有点意思的是,不只 CPU 和 GPU 之间,还有 GPU 和 AI NIC 之间也画的 xGMI,而不是 PCIe。这是来自一份 2023 年 12 月的文档《AMD AI Networking Direction and Strategy》,原文是这样写的:

而现在支持 UEC 的“AI 网卡”(Scale-out 互连)已经发布了。如果在上图 xGMI 的基础上,再添加 GPU Scale-up 的 UALink,是不是就不需要 PCIe Switch 了呢?这一点我还没有确切的答案。
AMD Pensando Pollara 400 UEC AI 网卡
在 UALink 1.0 规范正式发布的几个月之前,我听到有一家核心成员退出的消息?(稍后我还会讨论),当然更多的厂商还在积极参与。比如下面的 Asteralabs:
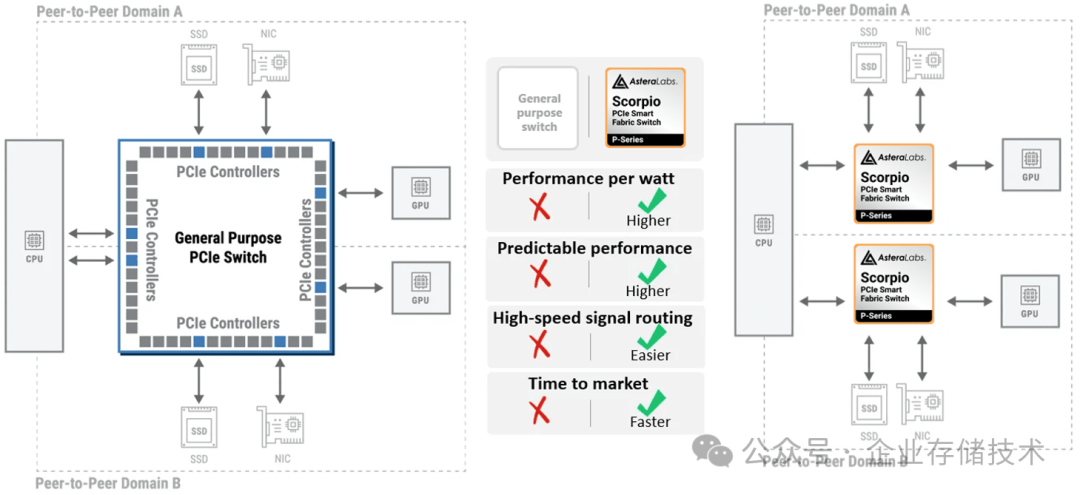
Asteralabs 当前具备 PCIe 和 CXL Switch 产品线,除了大型的 X 系列 PCIe Switch 之外,上图中他们宣传了高性价比的 P-Series PCIe Switch。看这架势是想拿 2 颗“小”芯片替换 AI 服务器上的 1 颗“大”芯片。
就像我在《DeepSeek 时代:关于 AI 服务器的技术思考(PCIe 篇)》中分享过的,当前流行的做法,是把一个高端口数的 PCIe Switch(如 144 lane)分区使用,每个 GPU 有自己“专属”到 CPU 之间的通道,以及 Scale-out 网卡和 SSD 本地存储。除非 2 颗 GPU 之间还需要通过 PCIe Switch 通信。
而在有了全互连的 NVLink 或者 UALink 之后,GPU 跨 PCIe Switch 通信的需求就没有了,使用昂贵的高端 PCIe Switch 不再是刚需——而且这类产品基本被 2 家垄断,所以价格降不下来…
Scale-Up 与 Scale-Out 融合:NVLink & UALink 未来的方向?
下图引用自 zartbot 老师的文章《从 GTC25 谈谈 GPU 互联(修正版)》:
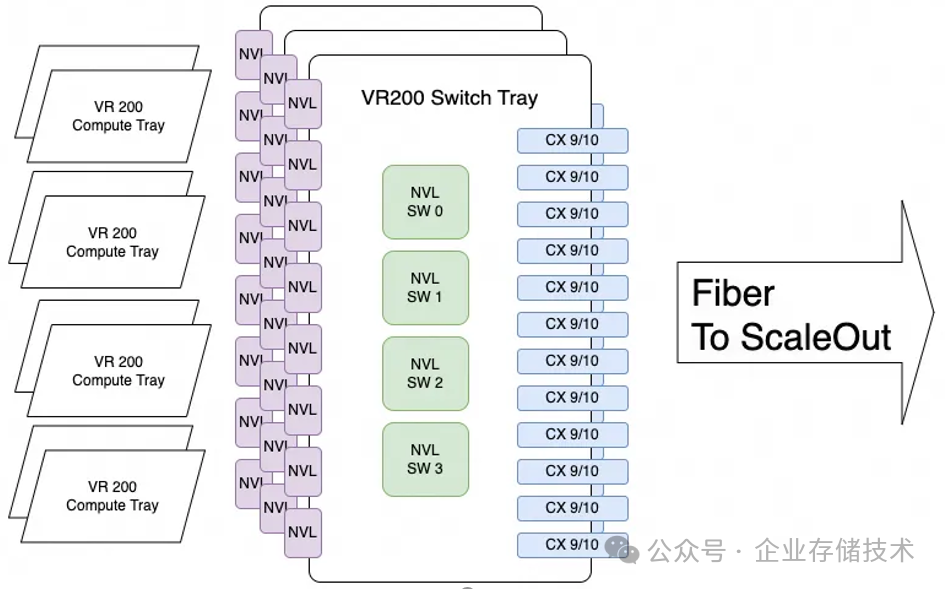
虽然这还只是一个推测,但如果 NVIDIA 将 CX 9/10 网卡直接插在 NVLink 交换机里,从 Scale-up 网络枢纽上进一步扩展出 Scale-out 网络,未来的 UALink 是不是也可以呢?(不一定是当前发布的 1.0 spec 阶段)上文中 AMD 不是也有 GPU 通过 Infinity Fabric 连接 NIC 的示意图嘛。
如果真的这么搞了,GPU 将不再需要通过 PCIe Switch 连接网卡,剩下的 NVMe SSD,以及原有的南北向网卡需求,直接连到 CPU 的 PCIe 控制器,大多数情况就够用了吧?
Broadcom 为什么“退出”UALink 了?
写到这里,我不详细讲大家可能也知道答案了吧:)
Broadcom 本来搭着 AI 服务器卖高端口数 PCIe Switch 挺舒服的,结果 UALink 换成了以太网 Serdes,虽然博通的以太网 Switch ASIC 也挺强,但这样一来能参与玩交换机的人就多了?再加上服务器节点内,GPU 跨 PCIe 通信需求的弱化,博通可能发现对自己的 PCIe Switch 生意不利。

其实 Broadcom 并没有完全从 UALink 联盟退出,只是不在董事会里,仍是贡献者。——至于未来他们将发挥的作用,到时候再具体看吧。
试谈 AMD 和 Intel 的意图
AMD 的产品线中有 CPU、GPU、SmartNIC/DPU 和 FPGA(Xilinx),但是没有 Switch。个人理解,发起 UALink 应该是想拉着一票人,联合各家 GPU/加速器的出货量,推动 UALink 交换机的加速落地和成本降低。
AI Head Node(机头节点)是当前 Intel 和 AMD 服务器发力竞争的一个重点,甚至在该领域 x86 阵营面临着 arm(NVIDIA Grace)的一定冲击。
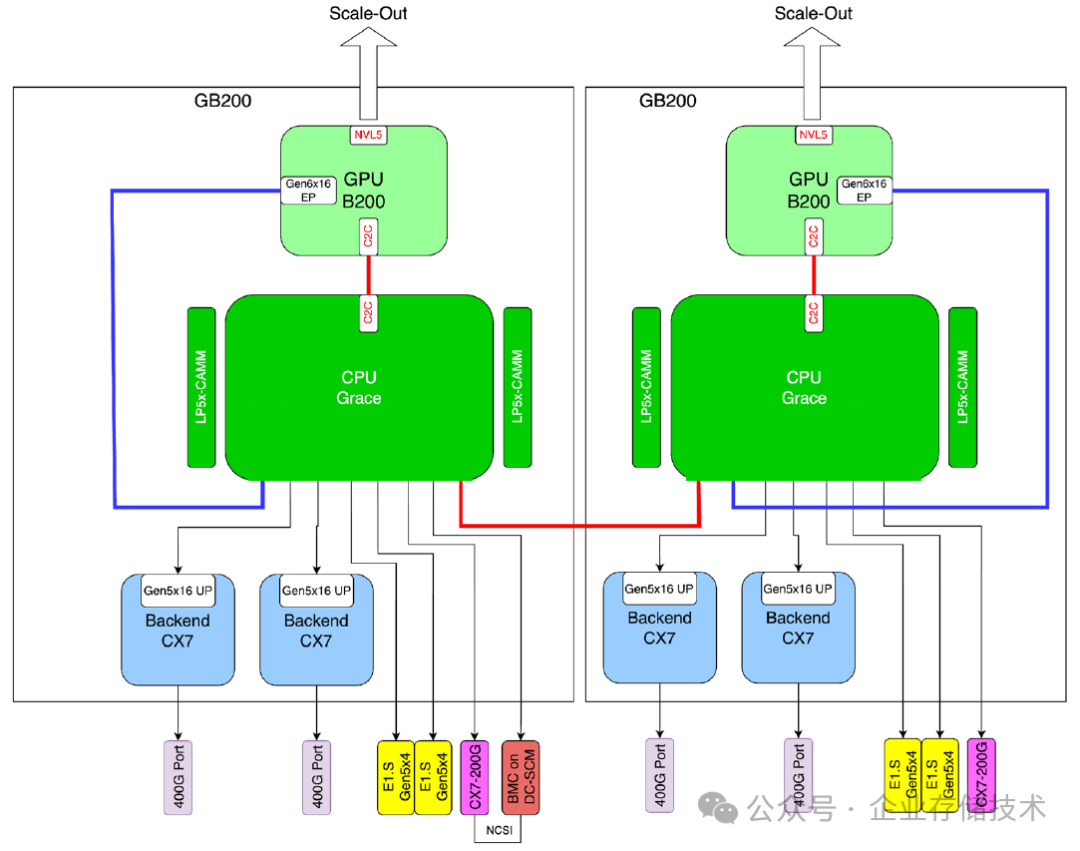
上图我在《Meta 的 GB200 液冷 AI 服务器 - Catalina》中列出过,Grace CPU 与 B200 GPU 之间应该是 NVLink C2C 互连。NV 搞这样的专用系统,就是要想办法发挥私有连接的优势——利用 GPU 来带动 CPU。
而 UALink 开放标准追求的有些相反。AMD 的服务器适配 NVIDIA、自家 GPU 没问题,如果对其他 UALink xPU 也良好兼容的话,是不是通用性就更好了?
或者,至少可以退一步说:UALink 交换机组网设备是通用的。
一旦将来 UALink 流行,Intel 当然也不希望被落在后面,所以也积极参与了组织。从某种角度来看,能让 Intel 和 AMD 坐下来共同维护 x86 阵营的利益,是因为 NVIDIA 在 AI 时代占得了先机。
END
作者:唐僧 huangliang
原文:企业存储技术
推荐阅读
欢迎关注企业存储技术极术专栏,欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

