今天给大家分享一份调研报告《_Responsibly Deploying Al Clusters at Scale - 650 Group_》,来自2025 OCP Canada Tech Day——即Open Compute Project的首次加拿大技术日活动。
引言:伴随着UALink的出现,AMD也会在一_AMD的战略挺明显:今年MI350先把FP4/FP6性能追上来(B200);明年MI450再用UALink_些高端GPU中集成高速I/O枢纽,就像有的NVIDIA系统那样不再需要PCIe Switch了。_等互连技术加强,进一步缩小与NV(Rubin)之间的差距。_
在转发过《DeepSeek-671B纯CPU部署:配置选型、性能测试与量化对比》之后,我一直想找个合适的时机也给大家分享下CPU+GPU混合推理DeepSeek R1等MoE大模型的方案。
今天分享的是OCP AI/ML Physical Infra Workshop第二阶段会议的资料。在国际领先厂商的介绍中,越来越多地出现1MW(兆瓦)的字样,当然目前单机柜还达不到,有些是一排(几个Rack)就差不多了。

AI/ML 应用的发展和密度要求,对机架 & 供电、散热等数据中心物理基础设施提出了更高的挑战。OCP AI/ML Physical Infra Workshop 1 资料网盘下载链接: [链接] 提取码: 9xsg大家也可以在关注本微信公众号之后,从后台对话框发消息 ocp0419__来获取以上分享链接。来源 [链接](含qiang外视频回放)会议日程以下 ppt 内...

如下图,NVIDIA 的 HGX B200 8-GPU 模组早已不是新闻了,这张照片引用自国外网站在OCP 2024 峰会期间的报道。

做为面向办公需求为主的商用本,其性能往往不见得有高端游戏本和移动工作站那样出色,相关的评测文章被追捧的亮点通常也不太多。而我则希望本文能给读者朋友带来一点新鲜的视角。

AMD Radeon GPU 正式支持 ROCm,且满足与行业标准软件框架的兼容性。本 Jupyter notebook 利用 Ollama 和 LlamaIndex(ROCm 皆已支持)构建检索增强生成 (RAG) 应用程序。LlamaIndex 促进了从阅读 PDF 到索引数据集和构建查询引擎的通道创建,而 Ollama 则提供了大语言模型 (LLM) 推理的后端服务。

自从通义千问推出 Qwen3 系列大模型,人们的注意力一下子从 DeepSeek 上转移出不少。有一点遗憾是 235B 的参数量,不见得能达到或者超过 671B 的效果?

我们都知道,多线程能够充分利用硬件资源,从而提升程序的吞吐量。然而,在实际的程序实现中,往往无法达到真正的多线程效果。由于各种因素的影响,线程之间会相互制约,导致性能与线程数量无法呈现线性扩展。本文将结合 zStorage 在性能调优方面的经验,总结线程之间制约的具体因素,以及 zStorage 为解决或缓解这些制...

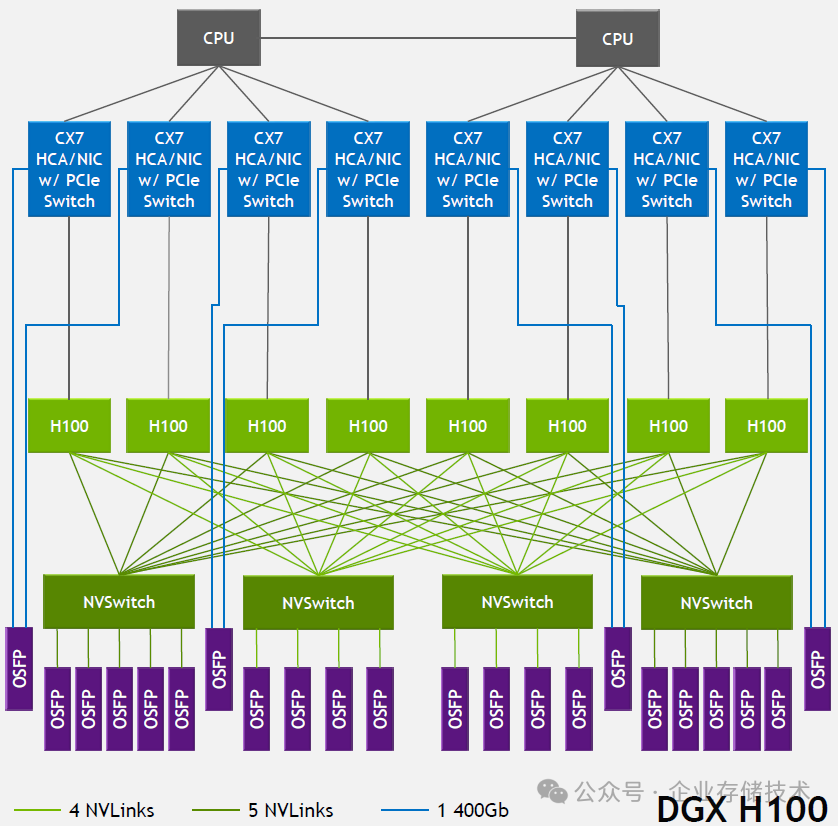
在今天的数据中心 AI 硬件产业链中,NVIDIA 可能比手机界的苹果过得还舒服?市场份额和利润都拿着大头——我是指的训练和推理芯片(GPU)部分。在这背后离不开 CUDA 相关的软件生态,以及 NVLink(Scale-Up 网络)互连的技术优势。
本文参考自 SNIA Webcast《Unlocking CXL's Potential: Revolutionizing Server Memory and Performance》。

编者注:几个月前我写过一篇《MLPerf Llama 大模型推理测试:一款 GPU 独战 NVIDIA 群雄》,随着最新一期的 MLPerf Inference: Datacenter 5.0 榜单更新,基本上没太多意外。

技术背景说明:根据 Meta 在 2024 年 OCP 峰会的披露,Catalina 是其基于 NVIDIA Blackwell 平台开发的 AI 机架解决方案。该项目在保留标准 GB200 NVL72 液冷机架核心设计的同时,针对性优化了网络架构和冷却系统,既缩短了 6-9 个月的开发周期,又实现了与 Meta 现有 AI 基础设施的无缝集成。这种"80%标准化+20%关键定...

本文参考自 2 篇博客文章《Speculative Decoding - Deep Dive》、《Speed Up Text Generation with Speculative Sampling on AMD GPUs》,来源链接见文末。

在一个月之前,我曾提到随着 DeepSeek 的出现,在 AI PC 上尝试本地部署 LLM 大模型的人多了不少。除了 Ollama、LM Studio、Chatbox 这些工具,关注 Dify 等构建知识库的用户也增加了。

我们之前关于这个主题的博客文章 讨论了 DeepSeek-R1 如何在 AMD Instinct™ MI300X GPU 上实现具有竞争力的性能。我们还提供了与 Nvidia H200 GPU 的性能比较和一个简短的演示应用程序来说明实际使用情况。在本博客中,我们将深入探讨如何使用 SGLang 框架、关键内核优化(如 ROCm™ 的 AI Tensor Engine)和超参数调整...

私有化部署大模型能够有效保护数据隐私、便于开展大模型安全研究和知识蒸馏。目前主流部署方式包括纯 GPU、CPU/GPU 混合以及纯 CPU 三种部署方式。本文介绍了我们针对 DeepSeek 大模型纯 CPU 本地化部署的推理探索与实践方案。我们以约 3.8 万元的整体成本,基于 llama.cpp 框架,经过硬件选型与量化精度的综合考量,实...

过去几年,大模型训练使用的算力从千卡增长到了十万卡。业界预测,未来 5 到 10 年,通用人工智能(AGI)在庞大的算力支撑下成为现实。然而,随着算力需求的急剧膨胀,园区物理资源的瓶颈问题正日益凸显。

zStorage 典型的部署拓扑结构如下图所示:采用 3 个存储节点,数据保存 3 副本,2 个或更多计算节点。存储节点用于承载 zStorage 分布式块存储系统,通过 FrontEnd(简称 FE)向外提供 NVMe-oF/iSCSI 块存储协议。计算节点用于承载计算任务,例如 Oracle、MogDB 等数据库业务。计算节点通过 NVMe-oF/iSCSI 块存储协议映...



