对长尾数据集的tricks进行了分析和探索,并结合一种新的数据增强方法和两阶段的训练策略,取得了非常好的效果。

这是前一篇文章的继续,在这第篇文章中,我们将讨论纹理分析在图像分类中的重要性,以及如何在深度学习中使用纹理分析。
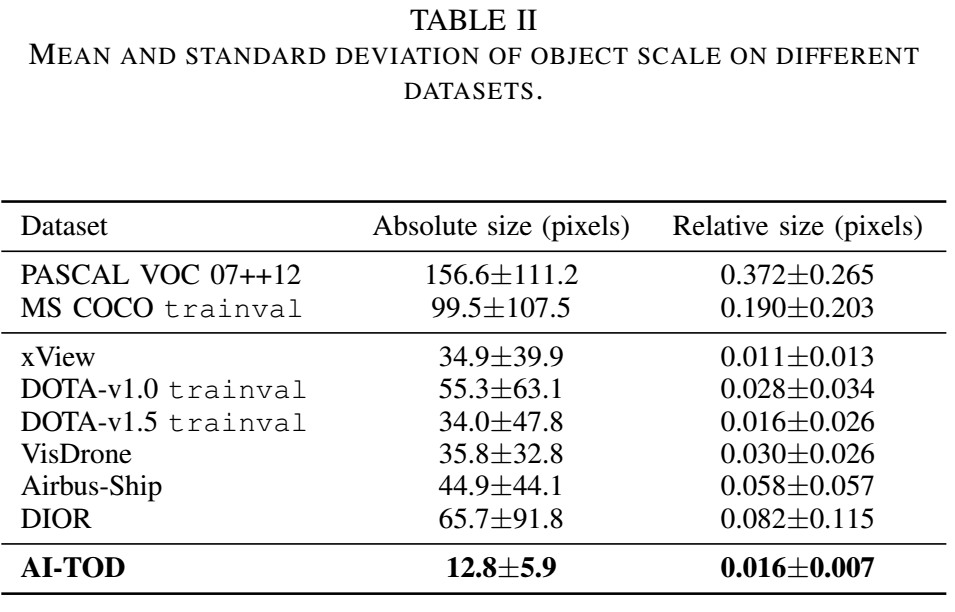
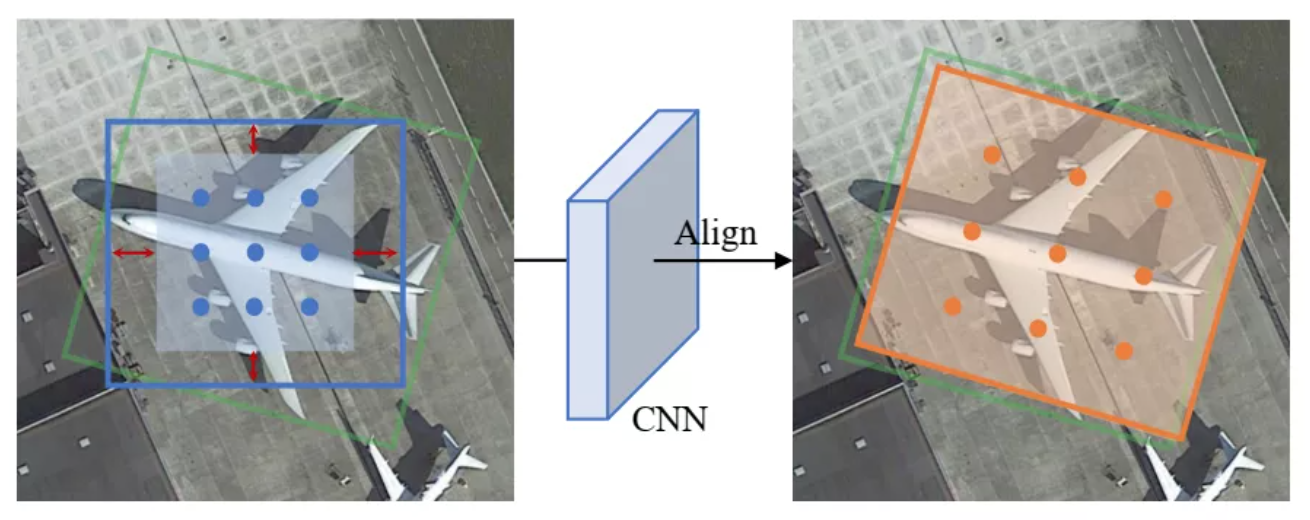
使用RFLA,实验表明,在4个数据集上都是有效的,特别是在AI-TOD数据集上,超过了当前的SOTA达到4.0AP。

人工智能的一个独特应用领域是帮助验证和评估材料和产品的质量。在IBM,我们开发了创新技术,利用本地移动设备,专业的微型传感器技术,和AI,提供实时、解决方案,利用智能手机技术,来代替易于出错的视觉检查设备和实验室里昂贵的设备。

导读你应该知道的18个PyTorch小技巧。调试深度学习的pipelines就像找到最合适的齿轮组合你为什么要读这篇文章?深度学习模型的训练/推理过程涉及很多步骤。在有限的时间和资源条件下,每个迭代的速度越快,整个模型的预测性能就越快。我收集了几个PyTorch技巧,以最大化内存使用效率和最小化运行时间。为了更好地利用这...

本文介绍了一种新的计算注意力的方式,相比于之前的注意力机制,无需额外的全连接,卷积等额外的计算和参数,直接使用BN中的缩放因此来计算注意力权重,并通过增加正则化项来进一步抑制不显著的特征。
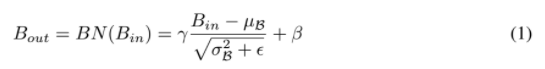
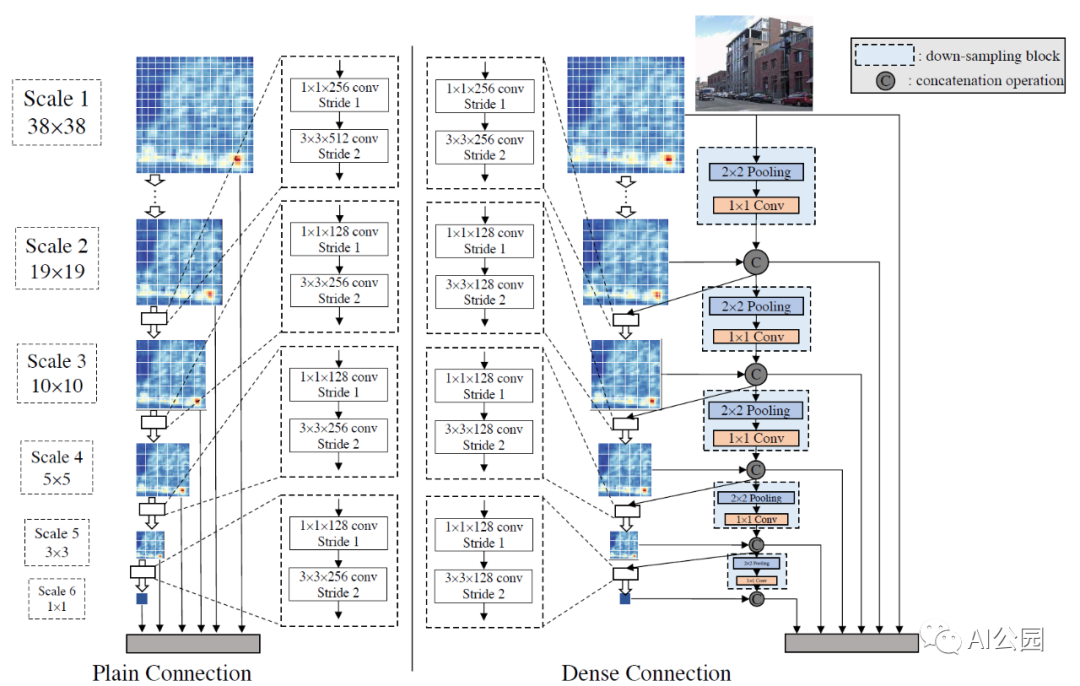
本文针对小目标检测,在CenterNet上进行了改进,将CenterNet上的一个中心点改成了4个中心点,取得了不错的效果,改动很小,但很有效。
本文是对CenterNet的一种改进,主要是增加了训练时参与回归的样本,提升了收敛速度,加快了训练时间,同时使用了椭圆高斯核来代替CenterNet中的圆形高斯核,感觉更加合理。
这篇文章提供了一种使用不同proposal来分别做检测和分类的二阶段物体检测方法,相比之前的方法有稳定的performance的提升。

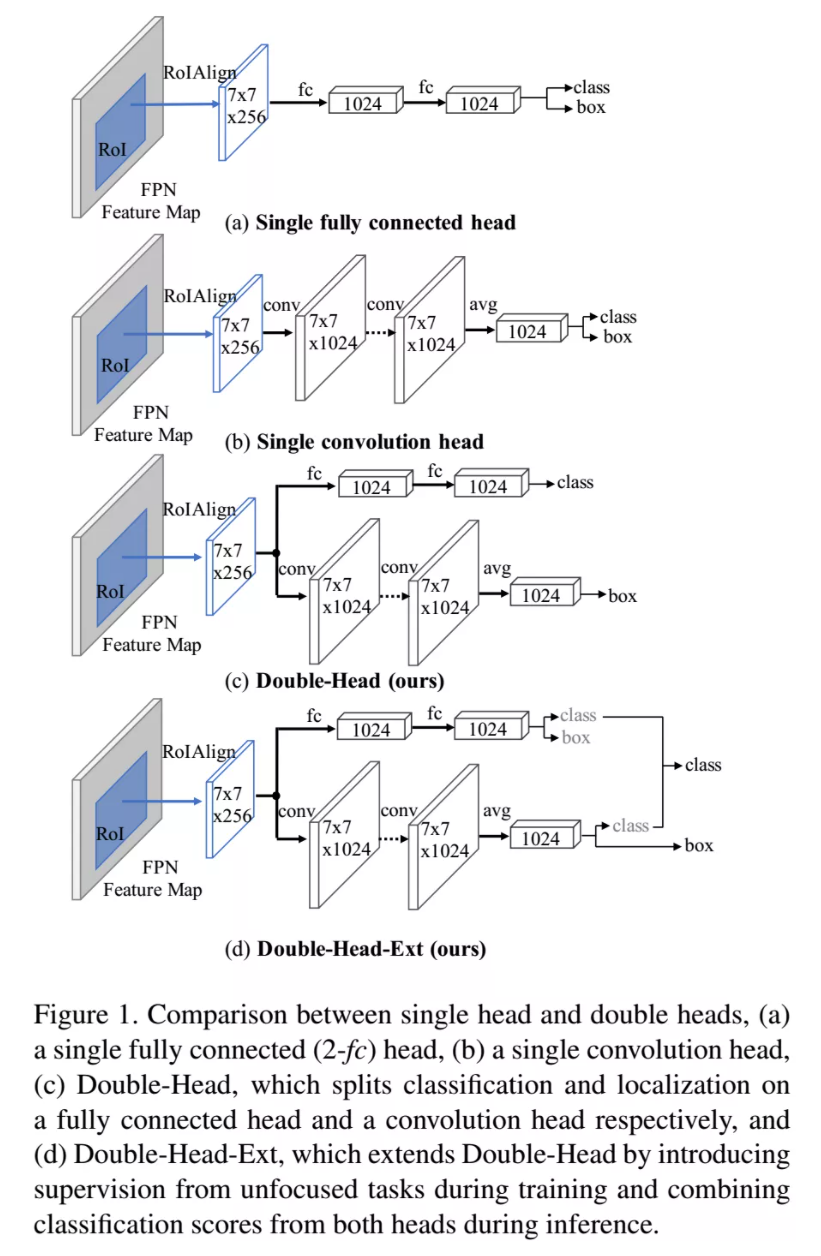
这篇文章对物体检测器的head进行深入的研究,提出了Double-Head-Ext 的方法,效果对比基线模型有明显的提升。
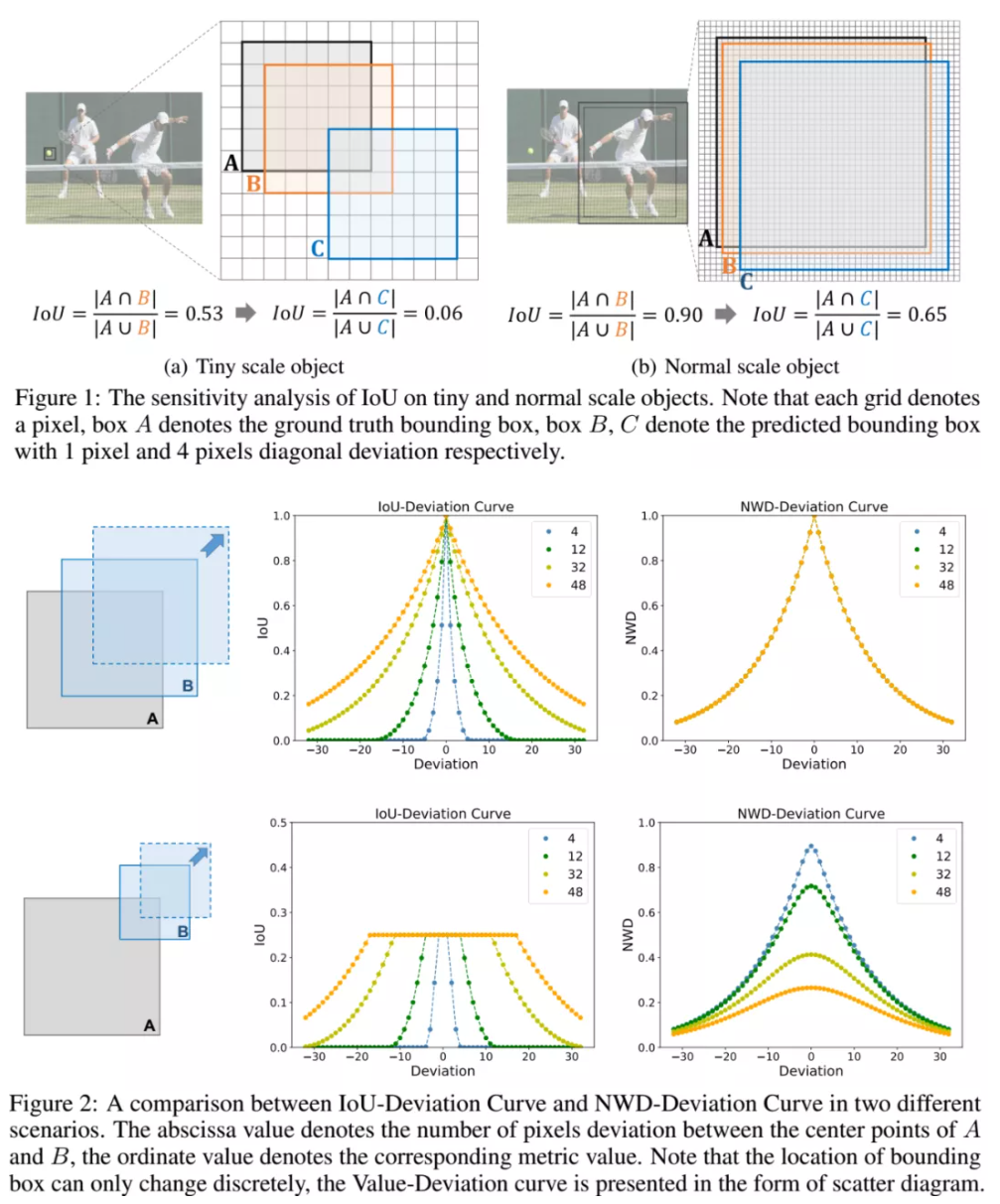
本文分析了小目标检测中使用IoU的最大缺点,对于位置的微小变化太过敏感,因此提出了一种新的度量包围框相似度的方法,用来替换IoU,从实验结果来
导读显式的使用loss来对齐分类和定位任务。TOOD: Task-aligned One-stage Object Detection论文链接:后台发送“tood”获取论文和代码链接。1、介绍现有的物体检测方法的2个局限性:(1)分类和定位的独立性。目前,分类和定位一般用的是2个独立的分支,这样使得2个任务之间缺乏交互,在预测的时候就会出现不一致性。得分...

启发式的定义anchor的质量并不好,物体和anchor之间并不能很好的对齐,比如,物体的尺寸可以是1/3到1/30,但是并不是所有的anchor都可以匹配,这种不匹配会加重前景和背景之间的类别不均衡,导致性能下降。
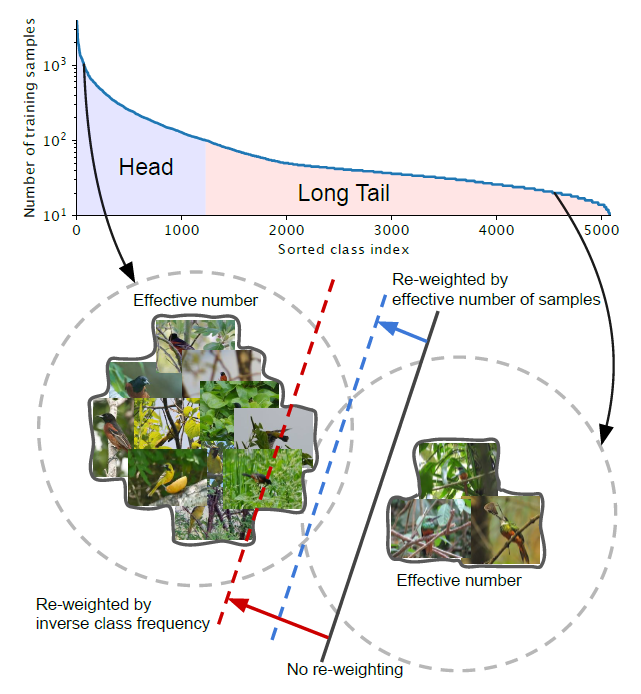
使用每个类的有效样本数量来重新为每个类的Loss分配权重,效果优于RetinaNet中的Focal Loss。
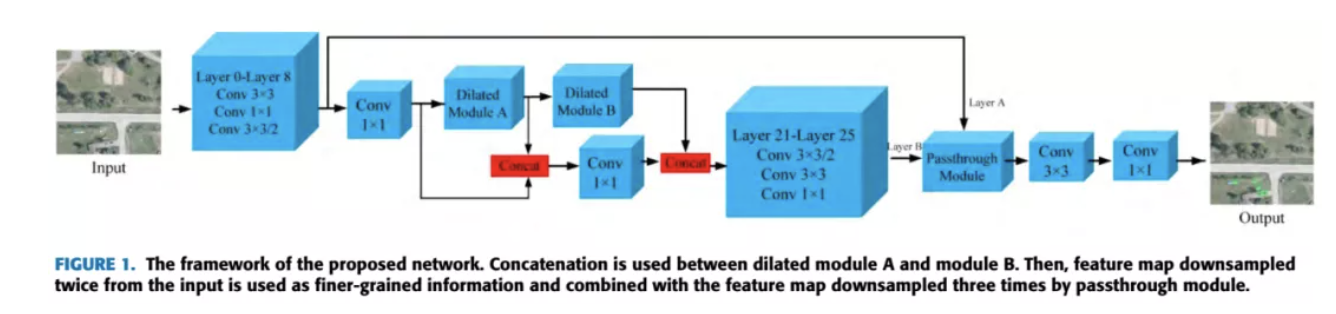
导读以Tiny YOLOV3的速度达到YOLOV3的效果。 论文链接:后台发送“小目标检测网络”获取论文链接。1. 介绍本文提出一种专门用于检测小目标的框架,框架结构如下图:我们探索了可以提高小目标检测能力的3个方面:Dilated模块,特征融合以及passthrough模块。 Dilated Module:上下文信息对于检测小目标是很重要的,一种方法...
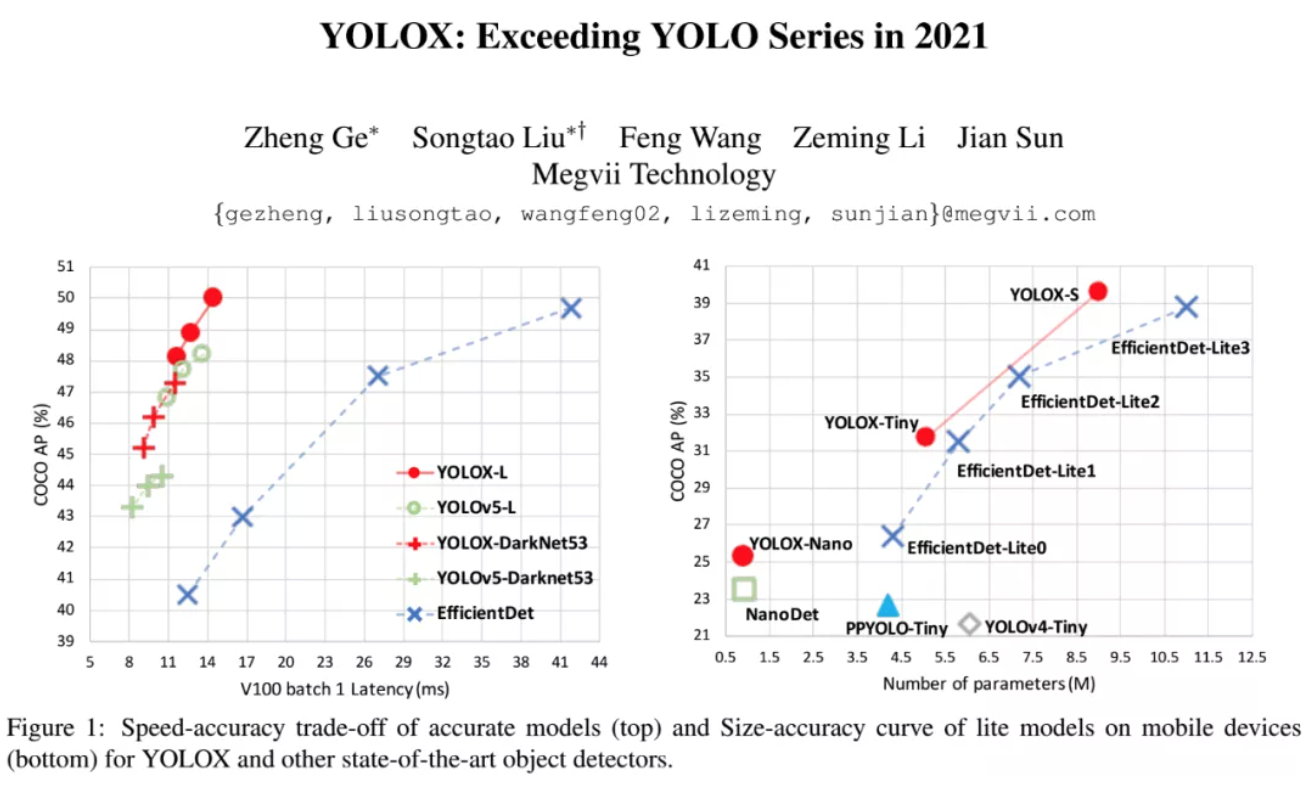
YOLOv3 baseline 以Darknet53作为Baseline,给大家介绍如何一步一步过渡到现在的YOLOX-DarkNet53。YOLOv3是以Darknet53为主干,后面再加上SPP。我们对训练策略进行了一些修改,增加了EMA weights updating,余弦学习率,IoU损失,以及IoU-aware分支,在训练分类和objectness的分支中,我们使用了BCE loss。在数据增强方...
导读对于检测小目标有一定的借鉴意义。 论文下载:后台回复“红外小目标检测”获取论文下载链接。1. 介绍红外小目标检测的几个困难点:1、目标尺寸很小,没有结构,纹理,形状的信息。2、背景很复杂,各种噪声很多,目标很容易淹没在背景中。3、SCR很低,信号的对比度很低,信号强度相比于周围的区域,对比度不是很强。4、...
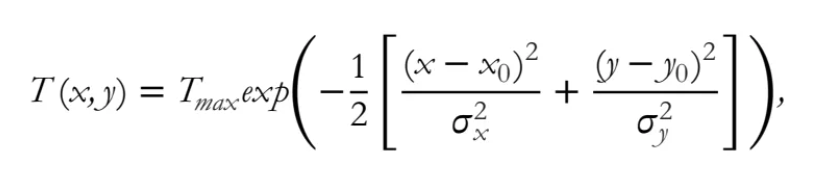
摘要:这篇文章提出了Dynamic Head的框架,将物体检测头和注意力机制整合到了一起。使用这种框架,可以在不同尺度的特征层之间做注意力,可以在空间范围内做空间注意力,可以在输出通道之间做任务的注意力。在不增加计算的情况下,该方法显著提升了目标检测头的表达能力。

首发:AI公园公众号作者:Harpal Sahota编译:ronghuaiyang导读实现了Google Research,Brain Team中的增强策略。像许多神经网络模型一样,目标检测模型在训练大量数据时效果最好。通常情况下,可用的数据有限,世界各地的许多研究人员正在研究增强策略,以增加可用的数据量。谷歌的大脑团队进行了一项这样的研究,并发...

这篇文章是对DSOD: Learning Deeply Supervised Object Detectors from Scratch,(DSOD),来自复旦大学,清华大学,英特尔实验室中国的回顾。