订阅极术公开课,即时获取最新技术公开课信息

嵌入式端AI,包括AI算法在推理框架Tengine,MNN,NCNN,PaddlePaddle及相关芯片上的实现。欢迎加入微信交流群,微信号:aijishu20(备注:嵌入式)

Arm相关的技术博客,提供最新Arm技术干货,欢迎关注
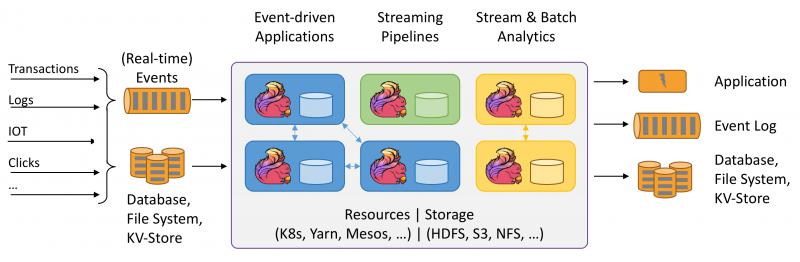
根据最新的统计显示,仅在过去的两年中,当今世界上90%的数据都是在新产生的,每天创建2.5万亿字节的数据,并且随着新设备,传感器和技术的出现,数据增长速度可能会进一步加快。从技术上讲,这意味着我们的大数据处理将变得更加复杂且更具挑战性。而且,许多用例(例如,移动应用广告,欺诈检测,出租车预订,病人监护...

状态管理是流计算系统的核心问题之一。在实现流数据的关联操作时,流计算系统需要先将窗口内的数据临时保存起来,然后在窗口结束时,再对窗口内的数据做关联计算。在实现时间维度聚合特征计算和关联图谱特征计算时,更是需要创建大量的寄存用于记录聚合的结果。而CEP的实现,本身就与常说的有限状态机(Finite-state mac...

距离上一次更新刚过了二十多天,距离0.17版本刚过了三个多月,Druid再次迎来重大更新,Druid也越来越强大了。

近日Kafka发布了最新版本 2.5.0,增加了很多新功能:下载地址:[链接]对TLS 1.3的支持(默认为1.2)引入用于 Kafka Streams 的 Co-groups用于 Kafka Consumer 的增量 rebalance 机制为更好的监控操作增加了新的指标升级Zookeeper至 3.5.7取消了对Scala 2.1.1的支持下面详细说明本次更新:一、新功能1、Kafka Streams: Add...

根据约翰斯·霍普金斯大学的最新数据显示,截止北京时间4月5号9时,全球累计报告确诊病例已达 134万+,死亡74000+ 。

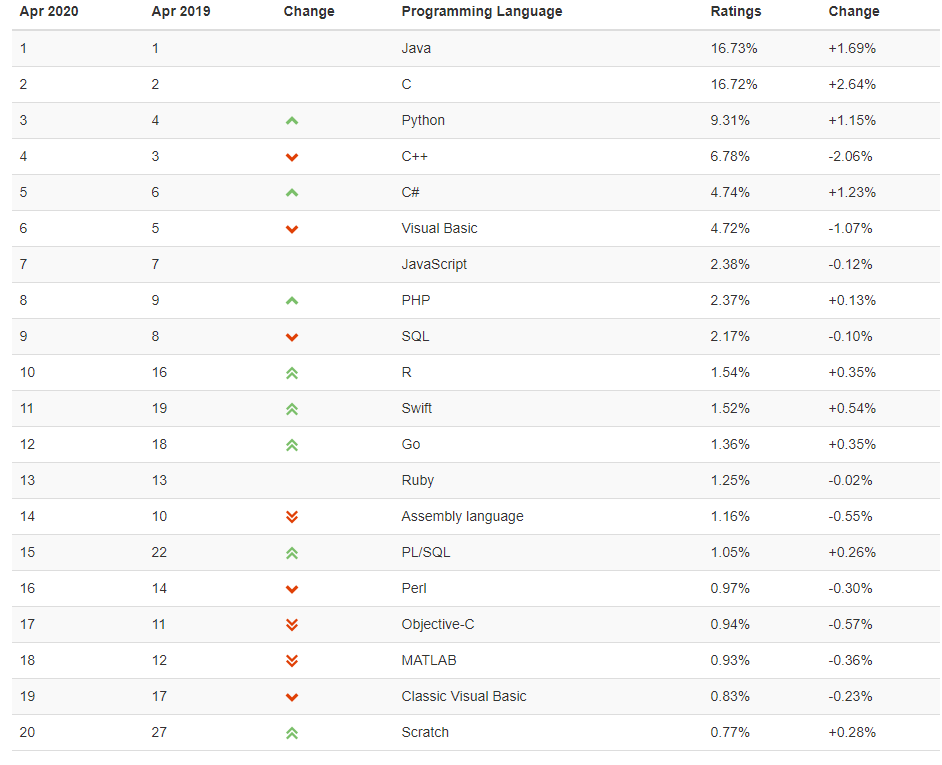
前三并没有什么悬念,依然是Java,C,Python。C与Java的差距正在缩小,不过我们不用担心,在大数据分析领域Java,Python依然都是不可或缺的。
近300页实用干货总结,帮你解决 Flink 实战应用难题!《Apache Flink电子书合辑》收录来自bilibili、美团点评、小米、OPPO、快手、Lyft、Netflix等一线大厂实时计算平台及实时数仓实践案例,更有来自阿里巴巴及Apache Flink核心贡献者们一线实战经验总结。

在快速开始中,我们演示了接入本地示例数据方式,但Druid其实支持非常丰富的数据接入方式。比如批处理数据的接入和实时流数据的接入。本文我们将介绍这几种数据接入方式。

在Druid快速入门其实已经简单的介绍过最简化配置的单节点部署,本文我们将详细描述Druid的多种部署方式,对于测试开发环境可以选用轻量的单机部署方式,而生产环境我们最好选用集群部署的方式,确保系统的高可用性。
本次Release版本修复1.2K个问题,对Flink作业的整体性能和稳定性做了重大改进,同时增加了对K8S,Python的支持。
一、安装准备本次安装的版本是截止2020.1.30最新的版本0.17.0软件要求需要Java 8(8u92 +)以上的版本,否则会有问题Linux,Mac OS X或其他类似Unix的操作系统(不支持Windows)硬件要求Druid包括一组参考配置和用于单机部署的启动脚本:nano-quickstartmicro-quickstartsmallmediumlargexlarge单服务器参考配置Nano-Qui...
本文中所介绍的Druid是一个分布式的支持实时分析的数据存储系统。通俗一点:高性能实时分析数据库。它由美国广告技术公司MetaMarkets于2011年创建,并且于2012年开源。MetaMarkets是一家专门为在线媒体公司提供数据服务的公司,主营是DSP广告运营推送平台,由于对实时性要求非常高,公司不得不放弃原始的大数据方案,Dru...
Apache Flink 是一个兼顾高吞吐、低延迟、高性能的分布式处理框架。在实时计算崛起的今天,Flink正在飞速发展。由于性能的优势和兼顾批处理,流处理的特性,Flink可能正在颠覆整个大数据的生态。

实时报表分析是近年来很多公司采用的报表统计方案之一,其中最主要的应用就是实时大屏展示。利用流式计算实时得出结果直接被推送到前端应用,实时显示出重要指标的变换情况。最典型的案例便是淘宝双十一活动,每年双十一购物节,除疯狂购物外,最引人注目的就是双十一大屏不停跳跃的成交总额。在整个计算链路中包括从天...

为 Consumer Rebalance Protocol 增加对增量协同重新均衡(incremental cooperative rebalancing)的支持
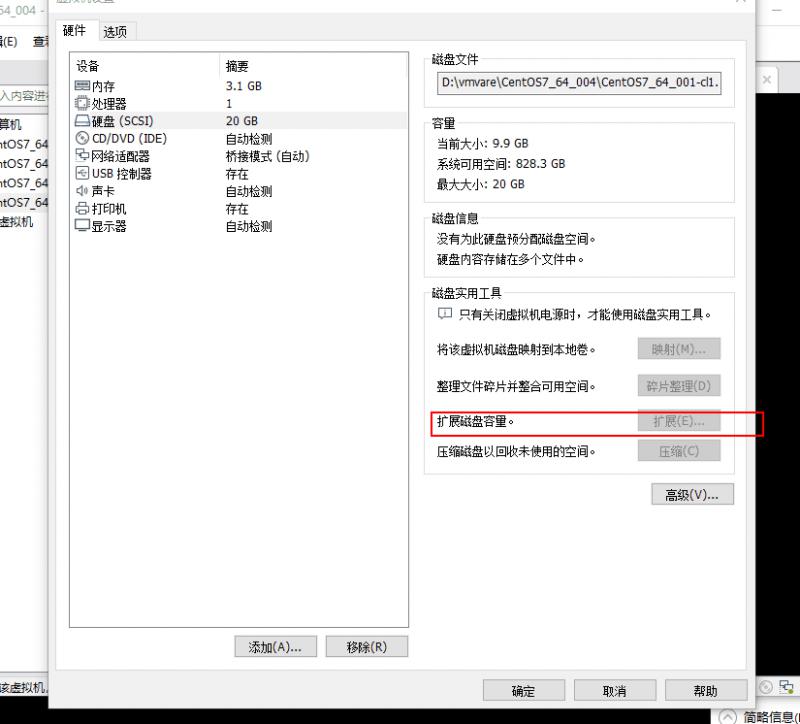
但是由于未进行分区和磁盘挂载的设置,我们启动虚拟机以后并不能使用增加的磁盘空间,这个时候怎么办呢?有两种办法
前提是大家已经安装好Ambari 2.7.3.0 这时候由于有一些组件没有添加,就需要安装新的组件。