前段时间申请了CSK6视觉AI开发套件,心想MCU算力有限不太可能搞定视觉任务,经过简单的试用发现效果很不错,不得不感叹现在芯片发展太快啦。

采用 NPU+DSP+MCU 三核异构技术,算力达到 128 GOPS。使芯片能以较低功耗满足音频及图像视频的 AI 应用需求。

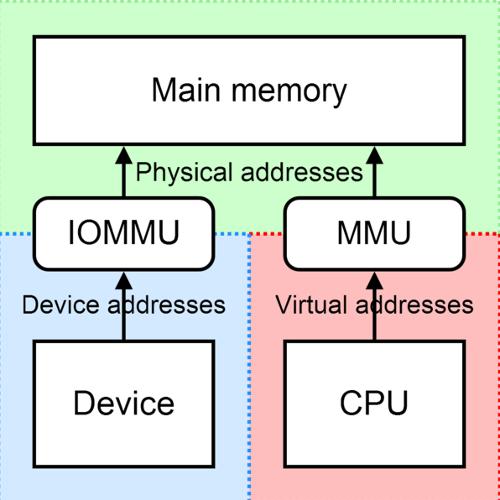
近年基于arm应用处理器的移动,infrastructure SoC平台都包含SMMUv3 IP(MMU-600,MMU-700),用于DMA mapping,VFIO,Shared Virtual Address(SVA)等场景。在这些使用场景中,SMMUv3是这样使用的呢?SMMUv3的硬件设计方面比较灵活,但是软件使用方面是有些限制的。本文不是介绍SMMUv3构架或IP,而是站在应用SMMU的角度...
在访问极术社区时,偶然发现聆思科技的CSK6开发板的评估活动,看CSK6的硬件配置和技术规格,300M的M33核 + 300M的HIFI4 + 128TOPS的NPU,完全有机会在我们公司内部的音视频产品上用上,因此申请了该方案的测评,以便更详细的了解该方案,也期待后续的音频模块,以便集中测试方案的音频部分以及音视频结合部分,确认是否...
今天,云计算正在创造越来越多的终端新形态。手机不再只是通信,是一款手中的计算机;汽车不再只求“马力”,需要比拼“算力”,是一台“四轮计算机”。

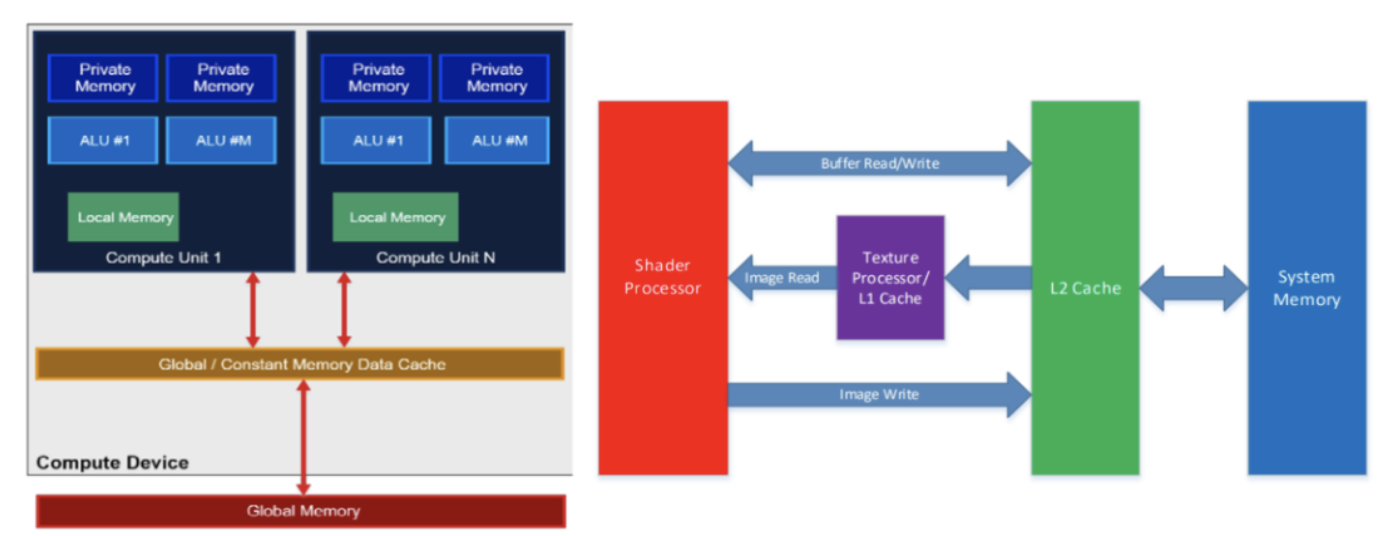
2020年8月TensorFlow Blog关于TensorFlow Lite的文章,就是提到OpenCL后端比OpenGL后端性能好,但事实真的是如此么?前几天我们刚发布有关《ShaderNN推理框架:来自OPPO的着色器深度学习推理引擎》的介绍,其GPU Kernel实现是基于OpenGL的Compute Shader(计算着色器),且性能好于TensorFlow Lite的OpenCL,也有实测的b...

聆思科技官方专栏,专注AIOT芯片,持续分享有趣的解决方案。商务合作微信:listenai-csk 技术交流QQ群:825206462

Arm相关芯片文章,涵盖AI,5G,自动驾驶等,欢迎关注。

本专栏为极术社区推荐图书及课程专栏,覆盖半导体,人工智能,物联网及人工智能等智能计算领域。

分享arm服务器软件应用经验、测试方法、优化思路、工具使用等。



