
本文第一部分主要介绍SnaPEA这篇文章的主要思想,以及论文中的应用范围。第二部分主要是我对这种算法能否应用于普通的处理器的探索实验。
作者:魏亚东,深圳市大疆创新科技有限公司 芯片开发工程师
授权转自https://zhuanlan.zhihu.com/p/42667332
SnaPEA: Predictive Early Activation for Reducing Computation in Deep CNNs(文末可下载)
1.这篇论文核心思路其实很简单,论文利用了我们最常用的激活函数ReLU,ReLU导致activation都是大于等于0的,那么如果将权重按照符号进行排列,在实际计算的时候先算权重是正数的部分,然后算权重为负数中较小的部分,随时判断部分和的值,当部分和小于0时停止计算。这个方案其实是使用判断开销以及存取开销替代了部分的计算开销。论文提出的体系结构如下:
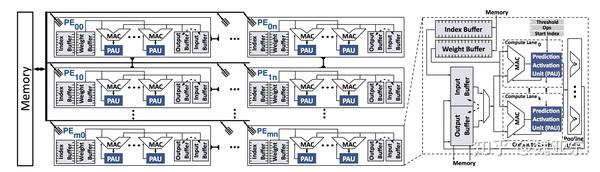
在weight离线排好序之后,会设置一个index的buffer用来在input数据读入的时候进行数据读取
2.对于其是否可以应用于通用的处理器
import matplotlib.pyplot as plt
import pylab
import numpy as np
import math
threshold = 0
class LinearMap(object):
def __init__(self):
self.items = []
def add(self, k, v):
self.items.append((k,v))
def get_by_key(self, k):
for key, value in self.items:
if key == k:
return value
def get_by_value(self, v):
for key, value in self.items:
if value == v:
return key
def get_size(self):
return len(self.items)
def dot(x, y):
x_width = np.shape(x)[0]
x_height = np.shape(x)[1]
y_width = np.shape(y)[0]
y_height = np.shape(y)[1]
result = np.zeros((x_width, y_height))
temp = 0
for i in range(x_width):
for j in range(y_height):
for k in range(x_height):
temp = temp + x[i][k]*y[k][j]
result [i][j] = temp
return result
def dot_snaPEA(x, y, index):
x_width = np.shape(x)[0]
x_height = np.shape(x)[1]
y_width = np.shape(y)[0]
y_height = np.shape(y)[1]
result = np.zeros((x_width, y_height))
for i in range(x_width):
for j in range(y_height):
temp = 0
for k in range(x_height):
temp = temp + x[i][index[k]] * y[index[k]][j]
if (temp < 0):
result[i][j] = 0
break
else:
result[i][j] = temp
return result
##build a hush map of filter
def build_map(x):
x_sort = LinearMap()
for i in range(np.shape(x)[0]):
for j in range(np.shape(x)[1]):
x_sort.add(i*np.shape(x)[1]+j,x[i][j])
return x_sort
##sort filter by sign
def sort_x(x):
hashmap = build_map(x)
sort_hashmap = []
hashmap_size = hashmap.get_size()
index = []
for i in range(hashmap_size):
if hashmap.get_by_key(i) > 0.000001:
sort_hashmap.append(hashmap.get_by_key(i))
for m in range(hashmap_size):
if hashmap.get_by_key(m) == 0:
sort_hashmap.append(hashmap.get_by_key(m))
for j in range(hashmap_size):
if hashmap.get_by_key(j) < 0:
sort_hashmap.append(hashmap.get_by_key(j))
for n in range(hashmap_size):
index.append(hashmap.get_by_value(sort_hashmap[n]))
return sort_hashmap, index
##calculate sum of a list
def calculate_sum(x):
count = 0
for i in range(len(x)):
count = x[i] +count
return float(count)
#sort a dict by keys
def sortedDictValues2(adict):
keys = adict.keys()
keys.sort(reverse=True)
return [adict[key] for key in keys]
#sort filter into certain groups
def sort_by_group(x, group_num):
sort_hashmap = []
index =[]
x_list = []
for i in range(np.shape(x)[0]):
for j in range(np.shape(x)[1]):
x_list.append(x[i][j])
epoches = int(math.floor(np.size(x)/group_num))
dict = {}
for i in range(group_num):
temp = calculate_sum(x_list[(i * epoches): ((i+1) * epoches)])
dict[temp] = tuple(x_list[(i * epoches): ((i+1) * epoches)])
if np.size(x)%group_num != 0:
temp = calculate_sum(x_list[(np.size(x) - np.size(x)%group_num):(np.size(x))])
dict[temp] = tuple(x_list[(np.size(x) - np.size(x)%group_num):(np.size(x))])
dict_list_group = sortedDictValues2(dict)
dict_list_group_cp = []
for i in range(len(dict_list_group)):
temp_list = list(dict_list_group[i])
for j in range(len(temp_list)):
dict_list_group_cp.append(temp_list[j])
hashmap = build_map(x)
for n in range(np.size(x)):
index.append(hashmap.get_by_value(dict_list_group_cp[n]))
return dict_list_group_cp, index
def count_non_zeros(x):
count =0
for i in range(np.shape(x)[0]):
for j in range(np.shape(x)[1]):
if abs(x[i][j]) >0.0001:
count +=1
return count
def img2col(img, width, height):
img_width = np.shape(img)[0]
img_height = np.shape(img)[1]
channels = np.shape(img)[2]
out_width = img_width - width + 1
out_height = img_height - height + 1
result = np.zeros((out_width*out_height, channels * width * height))
for i in range(out_height * out_width):
for j in range(channels * width * height):
result[i][j] = img[i/out_height + (j%(width * height))/height][i%out_height +j%height][j/(width * height)]
return result
def img2col_group(img, width, height):
img_width = np.shape(img)[0]
img_height = np.shape(img)[1]
channels = np.shape(img)[2]
out_width = img_width - width + 1
out_height = img_height - height + 1
result = np.zeros((out_width*out_height, channels * width * height))
for i in range(out_height * out_width):
for j in range(channels * width * height):
result[i][j] = img[i/out_height + (j%(width * height))/height][i%out_height +j%height][j/(width * height)]
return result
#the channels of input feature map
channels = 32
#filter size
fil_size = 3
#image size
img_size = 50
img = np.zeros((img_size,img_size,channels))
for i in range (channels):
img[:,:,i] = np.abs(np.random.randn(img_size, img_size))
fil = np.zeros((fil_size, fil_size, channels))
for i in range(channels):
fil[:,:,i] = np.random.randn(fil_size, fil_size)
imgcol = img2col(img, fil_size, fil_size)
filtercol = img2col(fil,fil_size, fil_size)
group_list = []
percent_list = []
for group_num in range(fil_size*fil_size*channels):
print 'the group number is:' +str(group_num)
##build hashmap for snaPEA
a,b = sort_x(filtercol)
c , d= sort_by_group(filtercol,group_num +1)
original_result = np.dot(imgcol, filtercol.T)
relu_original_result = np.where(original_result<0, 0, original_result)
new_result_1 = dot_snaPEA(imgcol, filtercol.T, b)
relu_new_result_1 = np.where(new_result_1<0, 0, new_result_1)
new_result_2 = dot_snaPEA(imgcol, filtercol.T, d)
relu_new_result_2 = np.where(new_result_2<0, 0, new_result_2)
percent = float(count_non_zeros(relu_original_result - relu_new_result_2))/float(np.size(relu_original_result))
group_num1 = group_num + 1
group_list.append(group_num1)
percent_list.append(percent)
print 'the error output percent is:' +str(percent)
plt.plot(group_list, percent_list, linewidth = 5, color = 'mediumpurple')
plt.xlabel('group number', fontsize = 40)
plt.ylabel('error output percent', fontsize =40)
plt.xticks(fontsize = 30)
plt.yticks(fontsize = 30)
plt.legend(loc = 'best', fontsize = '25')
plt.grid(True, linestyle = '-.', linewidth = 1)
plt.show()
plt.plot(group_list, percent_list------------------------------------------------
知乎专栏:Paper Reading,集聚自动驾驶知名大咖的前沿知识分享平台,欢迎申请加入或直接投稿。
更多嵌入式AI算法部署等请关注极术嵌入式AI专栏。
| 文件名 | 大小 | 下载次数 | 操作 |
|---|---|---|---|
| SnaPEA Predictive Early Activation for Reducing Computation in Deep CNNs.pdf | 1.59MB | 4 | 下载 |

