
前面我们有介绍过如何使用TVM编译CNN并生成IR中间件,然后用TVM C++ Runtime在android-arm64-v8a平台中进行部署。第一篇文章介绍的是使用平台中的默认配置生成的中间件,并编译目标平台的so、graph、parameters,本文我们跟大家介绍如何使用TVM中提供的AutoTVM来自适应的根据目标平台进行调优。
首发:https://zhuanlan.zhihu.com/p/71558181
作者:张新栋
这里我们再明确一下,模型frontend我们采用的tensorflow训练好的模型,目标平台为arm64-android-8.1。自适应调优需要经过如下几个步骤,建立PC与目标平台的RPC通讯、配置调优参数。
- 建立PC与目标平台的RPC通讯
由于PC处没有目标平台的硬件信息,无法根据目标平台进行合适的调优。TVM中提供了RPC通讯机制,以此让PC与目标平台进行通讯,协同调优CNN网络。由于android平台中无法运行tvm提供的脚本,需要在Android目标平台中安装RPC通讯的软件,安装的过程可参考TVM Android RPC APP。在进行通讯前,我们需要确保PC与Android设备连接于同一个局域网中。在成功进行编译后,我们可进行如下操作使PC与android平台进行通讯:
## PC 中启动rpc tracker
python3 -m tvm.exec.rpc_tracker --host=0.0.0.0 --port=9190在PC中启动rpc tracker后,需要在android平台中启动RPC通讯应用,并填上正确的配置参数,如下图:
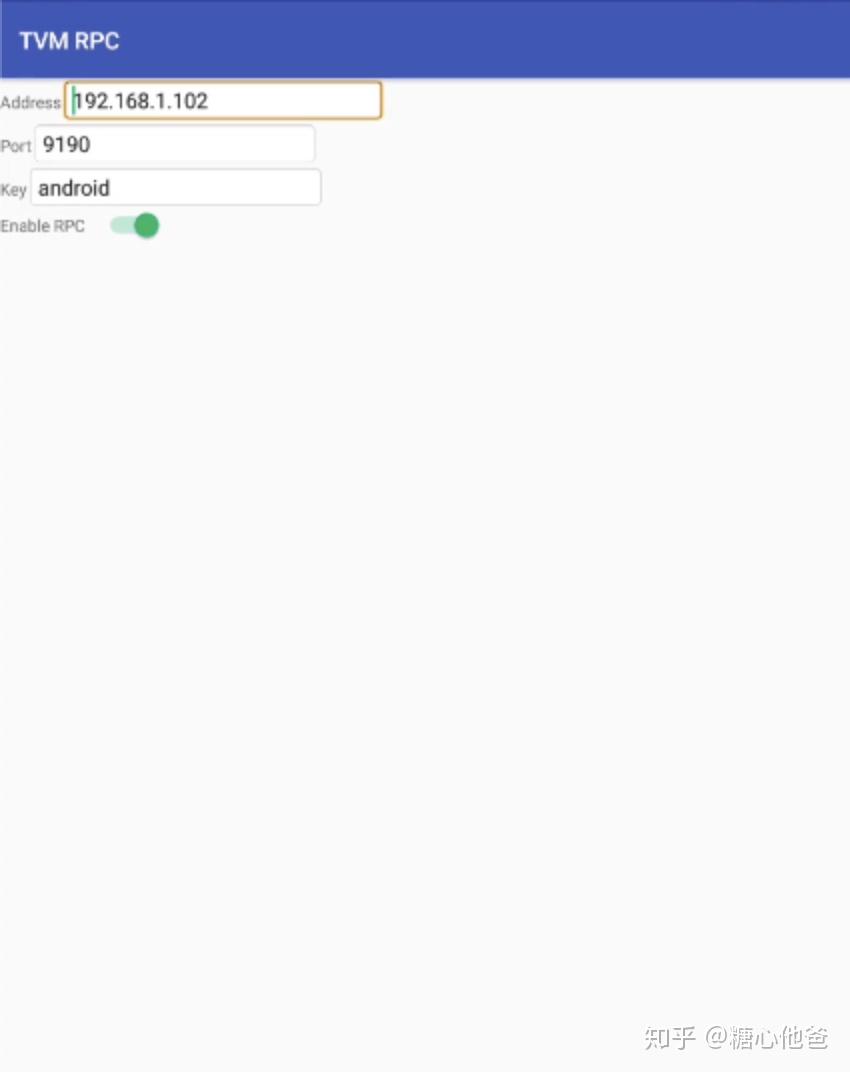
RPC应用需填参数
其中第一个参数Address是PC在局域网中的IP地址,port为启动tracker的端口(默认为9190),Key为自选的密钥(PC与android通讯时需要进行匹配)。以上填写确认无误后,PC则可与Android设备建立RPC通讯。可用如下脚本在PC上进行检查,
python3 -m tvm.exec.query_rpc_tracker --host=0.0.0.0 --port=9190如正确无误,则会出现如下结果:

返回结果
- 配置调优参数
调优的代码tvm中有提供,可参考/tutorials/autotvm/tune\_relay\_arm.py。里面有许多需要进行配置的参数:
tuning_option = {
'log_filename': log_file,
'tuner': 'xgb',
'n_trial': 500,
'early_stopping': 200,
'measure_option': autotvm.measure_option(
builder=autotvm.LocalBuilder(
build_func='ndk' if use_android else 'default'),
runner=autotvm.RPCRunner(
device_key, host='0.0.0.0', port=9190,
number=5,
timeout=1000,
),
),
}其中需要注意的几个参数,一个是tuner,可选的有xgb、ga(遗传算法)、random、gridsearch(网格搜索)。当搜索空间比较小的时候,可以采用gridsearch或者random。若搜索的空间比较大,则建议采用xgb、ga;n\_trial为迭代的最大步数;device\_key为建立RPC通讯时在APP上设置的key,另外host和port参数也需要对应上。
另外由于我们采用的frontend为tensorflow ,我们可以参考如下脚本来获取net、graph、params:
layout = 'NCHW'
with tf.gfile.FastGFile(model_name, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
graph = tf.import_graph_def(graph_def, name='')
graph_def = tf_testing.ProcessGraphDefParam(graph_def)
shape_dict = {'normalized_input_image_tensor': (1, 300, 300, 3)}
dtype_dict = {'normalized_input_image_tensor': 'float32'}
mod, params = relay.frontend.from_tensorflow(
graph_def,
layout = layout,
shape = shape_dict,
outputs = ['raw_outputs/box_encodings', 'raw_outputs/class_predictions']
)
net = mod[mod.entry_func]由于我们优化的目标为android-arm64的cpu,所以需要定义好对应的target及target\_host
target_host = None
target = tvm.target.arm_cpu(model = 'rk3399')- 最后
在以上步骤都确认完毕后,你就可以使用tutorial中的脚本进行调优了。调优的过程,以我的Mobilenet-SSD为例,里面一共有60个task,需要花3-4个小时进行调优;调优的过程比较耗CPU,所以选择好的电脑对调优的速度是有帮助的。如果大家在调优的过程中碰到什么问题或者坑,可以留言讨论,记得关注专栏哦。谢谢大家!
推荐阅读
专注嵌入式端的AI算法实现,欢迎关注作者微信公众号和知乎嵌入式AI算法实现专栏。

更多嵌入式AI相关的技术文章请关注极术嵌入式AI专栏。

