
本文是本系列第二篇,我们将通过分析一个 SM3 的开源软件实现,来进一步了解算法的实现流程和软件实现思路
首发知乎:https://zhuanlan.zhihu.com/p/89264895
在 GitHub 上搜索 SM3 可以得到很多,各种语言实现的结果(当然也有 Verilog,比较少就是了)。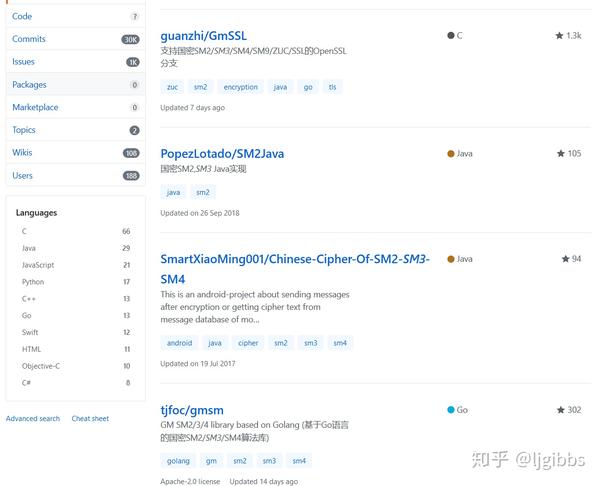

Github SM3 搜索结果
这里我们选择点赞数最高的 GmSSL,支持国密SM2/SM3/SM4/SM9/ZUC/SSL的OpenSSL分支
在以下目录可以找到独立的 SM3 实现源代码
<u><font color="#0b0118"></font></u>https://github.com/guanzhi/GmSSL/tree/master/crypto/sm3
SM3 的实现都在 sm3.c 中。sm3\_hmac.c 中实现的是基于 sm3 实现的上层加密认证协议,这里我们暂不研究。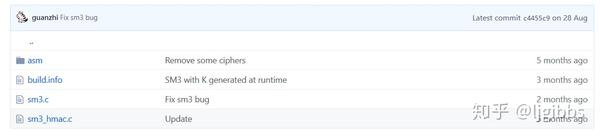 cropty/sm3
cropty/sm3

首次运行
PS:笔者看了下,目前的代码相比笔者当时研究的代码已经有了一些改动,但应该没有太大区别,还是以我当时的代码为准。
准备头文件,运行还需要两个头文件。从 openssl/sm3.h ; internal/byteorder.h 下载头文件
因为我们只需要运行 SM3 这部分,所以可以直接把头文件下载后放到当前目录,并修改 SM3.c 的头文件 include 部分。
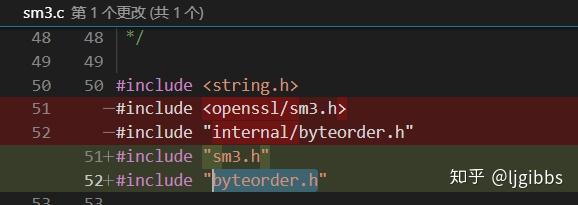
编译时会产生很多错误。

这是因为使用的 uint32\_t 在运行环境中没有定义,这里可以手动使用 unsigned int 代替,可以使用 sizeof( unsigned int ) 查看变量长度,一般平台上就是 32 字节的,所以没有问题。 上方的报错是因为我们独立编译 SM3.c 没有定义主函数导致的,这里我们增加一个测试用的主函数。
上方的报错是因为我们独立编译 SM3.c 没有定义主函数导致的,这里我们增加一个测试用的主函数。

int main(int argc, char *argv[])
{
unsigned int len = 16;
unsigned char *str = "1234567812345678";
unsigned char res[32];
unsigned long long start,end;
//start = clock();
sm3(str, len, res);
//end = clock();
//printf("time=%lld\n",end-start);
unsigned long long *long_ptr = (unsigned long long*)res;
printf("i=%d\n", len);
for (int j = 0; j < 4; j++)
{
printf("%llX:\n",(*long_ptr));
long_ptr+=1;
}
system("pause");
}这样就可以得到运行结果:

数据结构与宏定义
sm3\_ctx\_t 结构体用于存储 SM3 运算流程中的信息和中间变量
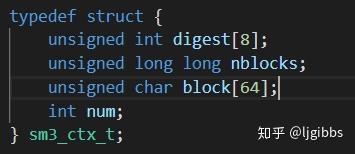
其中包括:
- 8 个 32 位寄存器,组成 digest[8] 数组,在迭代期间缓存寄存器值。
- 消息块数量 nblocks,使用一个 64 位变量存储,理论上支持最多 2^64 个数据块。
- 缓存当前消息块的 block[64] 数组, 存有当前 512bit 消息块。
- num 是一个中间临时变量,用作数组的索引,指向消息的特定字节
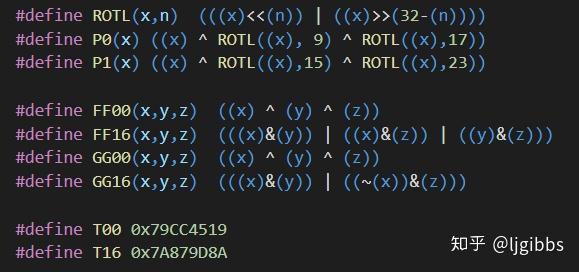
宏定义中定义
- 常量初值
- 迭代函数 P0 ,P1,FF00,FF16等
- 循环移位函数 ROTL
用于后续的迭代压缩函数。
代码结构
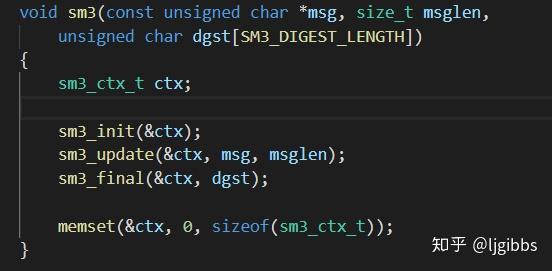
主函数中调用 SM3 函数开始一次计算,传入消息指针,消息的长度以及存放结果的指针,SM3 函数中依次调用 init,update,以及 final 函数进行消息的填充分块,消息扩展以及压缩,并将杂凑值存到结果指针中。
SM3 函数相当于 SM3 运算的接口,依次调用函数,中间变量使用 sm3\_ctx\_t 结构体传递。
sm3\_init 函数在第一个消息块时使用,使用 SM3 规定的初始值初始化 8 个寄存器。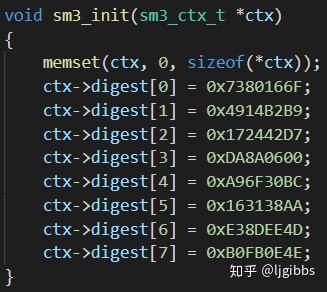

sm3\_update 函数处理最后一个之前的数据块的迭代压缩,这些数据块不用考虑消息扩展,只需要对总消息分块,进行迭代压缩即可。
这个函数的第一部分,笔者觉得在现有的工作模式应该是不可达的,欢迎大家讨论。
之后对数据分块,计算杂凑值,此时的数据块不需要考虑填充。记录剩下的数据量,即最后一个消息块的数量,拷贝最后一个消息块到结构体中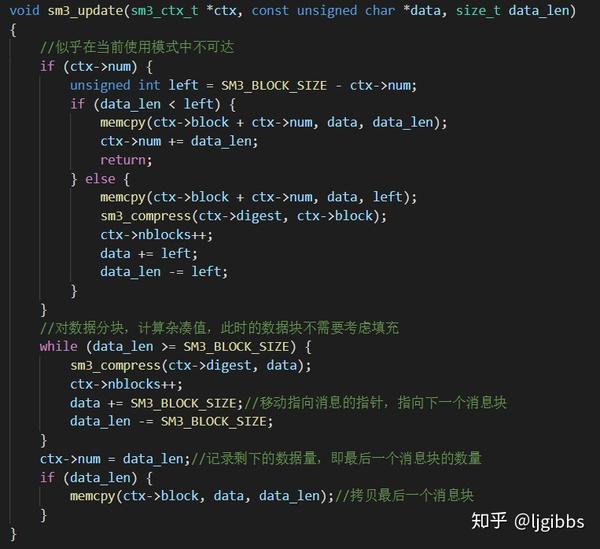 sm3\_final 函数处理最后一个数据块,最后一个数据首先需要扩展,再对扩展后的数据块进行压缩。
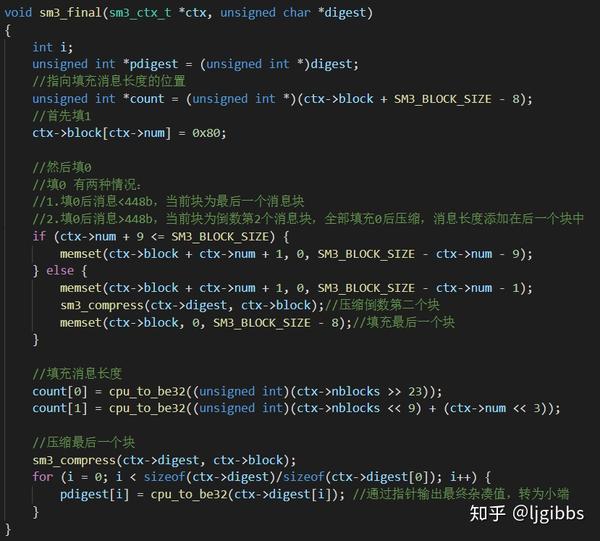
sm3\_final 函数处理最后一个数据块,最后一个数据首先需要扩展,再对扩展后的数据块进行压缩。
消息扩展时首先填 1,然后填0, 有两种情况:
1.填0后消息<448b,当前块为最后一个消息块
2.填0后消息>448b,当前块为倒数第2个消息块,全部填充0后压缩,消息长度添加在后一个块中
最后填充消息长度,并压缩最后一个块。通过指针输出最终杂凑值,转为小端。
sm3\_compress 函数进行 64 轮迭代压缩,使用到的置乱函数通过宏定义的方式已经预先定义好了。在函数中进行消息扩展和迭代。迭代分为两个阶段,两阶段只是置乱函数 FF GG 定义有所不同,可以见宏定义。
最后输出摘要值。
void sm3_compress(unsigned int digest[8], const unsigned char block[64])
{
unsigned int A = digest[0];
unsigned int B = digest[1];
unsigned int C = digest[2];
unsigned int D = digest[3];
unsigned int E = digest[4];
unsigned int F = digest[5];
unsigned int G = digest[6];
unsigned int H = digest[7];
const unsigned int *pblock = (const unsigned int *)block;
unsigned int W[68], W1[64];
unsigned int SS1, SS2, TT1, TT2;
int j;
//消息扩展
for (j = 0; j < 16; j++)
W[j] = cpu_to_be32(pblock[j]);
for (; j < 68; j++)
W[j] = P1(W[j - 16] ^ W[j - 9] ^ ROTL(W[j - 3], 15))
^ ROTL(W[j - 13], 7) ^ W[j - 6];
for(j = 0; j < 64; j++)
W1[j] = W[j] ^ W[j + 4];
//迭代压缩阶段1
for (j = 0; j < 16; j++) {
SS1 = ROTL((ROTL(A, 12) + E + ROTL(T00, j)), 7);
SS2 = SS1 ^ ROTL(A, 12);
TT1 = FF00(A, B, C) + D + SS2 + W1[j];
TT2 = GG00(E, F, G) + H + SS1 + W[j];
D = C;
C = ROTL(B, 9);
B = A;
A = TT1;
H = G;
G = ROTL(F, 19);
F = E;
E = P0(TT2);
}
//迭代压缩阶段2 使用的 FF 和 GG 函数不同
for (; j < 64; j++) {
SS1 = ROTL((ROTL(A, 12) + E + ROTL(T16, j % 32)), 7);
SS2 = SS1 ^ ROTL(A, 12);
TT1 = FF16(A, B, C) + D + SS2 + W1[j];
TT2 = GG16(E, F, G) + H + SS1 + W[j];
D = C;
C = ROTL(B, 9);
B = A;
A = TT1;
H = G;
G = ROTL(F, 19);
F = E;
E = P0(TT2);
}
//输出摘要值
digest[0] ^= A;
digest[1] ^= B;
digest[2] ^= C;
digest[3] ^= D;
digest[4] ^= E;
digest[5] ^= F;
digest[6] ^= G;
digest[7] ^= H;
}结语
本文我们通过学习一个 SM3 软件开源项目的实现,进一步了解了 SM3 的实现过程。同时也了解软件实现的思路:首先依次将数据分块,缓存一块后迭代计算,在最后一块上填充消息后迭代计算。是一种基于顺序计算和缓存的软件思维。我们后面将分析一个开源硬件代码,包有你今天得到的软件思维,之后我们再来个软硬思维的对比。
系列篇:
以SM3算法为例,构建一个软硬协作算法加速器:算法篇
更多FPGA相关知识请关注我的FPGA 的逻辑专栏

