

AMD即将上市的ZEN2架构可以说是赚足了大众的眼球。很多文章也对其进行了全面分析,认为是AMD“从优秀到卓越”的一次跨越。正是ZEN架构帮助AMD从低谷中走了出来,一直到今天被重新视作INTEL的挑战者。本文不再关注PPT中那些耀眼的数字,而是从处理器设计者的角度分析ZEN2的具体细节,向世界级的处理器架构学习。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/74059505
Summary:ZEN2的核心目标就是服务器市场,因此主要进行了2方面的增强:AVX256的支持以及单线程IPC的提升。前者通过翻倍整个浮点执行通路和存储通路实现,后者主要提高了分支预测和多发射的能力。同时为了在7nm工艺下控制成本以提升竞争力,采用了CPU核心和IO分离的chiplet设计。较低的售价和优异的性能是AMD和INTEL争夺服务器市场份额的利器。从这个角度看,ZEN2在设计上的取舍是很合理的,芯片的表现也证明了ZEN2架构的成功。
先来看几个重要信息。首先,ZEN2架构是AMD第一款采用7nm工艺的处理器,第一次从工艺上领先了INTEL。从给出的数据来看,7nm在面积上的提升还是很明显的,也能大幅降低其运行功耗。AMD在最新工艺上放弃global foundry转投TSMC可以说是至关重要的一步,在INTEL 14nm到10nm转换的这个关键时间点上占得了先机。领先的制程一直是INTEL的看家法宝,而这次INTEL 10nm的跳票,给了AMD难得的机遇,而后者很好的把握住了。其次,ZEN架构的单核性能较之前有大幅的提升,初代ZEN的IPC提升高达50%,ZEN2架构又提升了15%。单核性能火箭般提升的速度,是AMD能在消费领域和服务器领域挑战INTEL的根本。尽管当前处于多核时代,但在服务器领域,大量的核心应用仍然非常依赖于单核单线程的执行性能,游戏市场也同样如此。之前AMD孱弱的单核性能正是其叫好不叫座的问题所在。而这次ZEN架构漂亮的翻身,一举持平了INTEL Ice Lake系列。当然性能的提升中制程占了一部分因素,但ZEN架构的成功设计也功不可没。从这两点来看,一个产品的成功,有时候就在某几个关键的点上,需要去发掘市场真正需要要或者即将需要的关键因素,而不是淹没在众多指标的追逐中。

AMD E3 Tech Day Presentation June 19th 2019
在系统层面,ZEN2架构一个突出的特点是其CPU核心和IO分离的chiplet设计。Chiplet技术是未来芯片的重要基础技术,简单来说,就是把一些裸片如同搭积木一样集成封装在一个package中。这种硅片级的重用可以带来更高的灵活性和更好的成本控制。然而当前处理器设计的趋势是不断地把各个模块尤其是内从控制模块都整合在一个大核心里,这样可以获得更大的交互带宽和总线频率以提升性能,AMD这么干似乎是开了倒车。采用CPU和IO分离的设计,最重要的优势就是成本。由于7nm工艺的流片费用及其高昂,采用chiplet设计,在性能比较重要的CPU核心采用7nm工艺,而IO部分则使用较为便宜的12nm。而单裸片面积减小以后,也有利于提升良率。其次,IO独立裸片的设计,可以灵活配置CPU核心的裸片数量,如同乐高积木一样搭建出不同级别的平台,而只需要付出封装的费用。AMD的精打细算可以使它能以较低的售价和INTEL同级别的产品竞争,从而获取比较优势。
那么怎么解决由于IO独立裸片带来的总线延迟的损失呢?最重要的一点就是7nm工艺的加成。相比INTEL的14nm,CPU核心可以获得更高的性能,这样在很大程度上弥补了独立IO带来的延迟,这也算是托了INTEL的福。其次,重新设计的Infinity Fabric总线直接采用了PCIE4.0,带宽从256bit升级到了512bits。这样通过翻倍的带宽也能平衡掉一部分损失。第三,由于剥离掉内存控制模块的CPU核心面积缩小了不少,因此采用了更大的L3 cache,直接到16MB。这么大的cache加上良好的pre-fetch算法,可以大幅降低CPU和内存的数据交互,这样对总线的延迟也就不那么敏感了。当然这些只是理论上的估计,真实的性能可能还需要拿到成片后测试才能得知。但这个chiplet的设计还是很有启发:没有最完美的架构,只有最适合的架构。很多时候,一个通常有缺陷的设计在某些特殊环境下,却能更大的发挥它在特定领域的优势,成为产品胜出的制胜法宝。
接下来就是重头戏,AMD还是很厚道的,很多细节都在PPT中有体现。首先来看整体框架。

AMD E3 Tech Day Presentation June 19th 2019
基础结构包括:单核双线程,32K 8-way Icache, 32K 8-way Dcache,I+D share的512K 8-way L2 cache。标准的physical register renaming架构,前端6 dispatch,整型流水线部分7 issue,包括4个ALU,2 Load,1 Store。浮点流水线部分2个浮点单元,4条pipe。这些都算是这个级别处理器的典型配置了。有几个值得注意的点。第一,Icache size缩水了,从初代的64K减少到32K,但是增加了way数量。推测是为了控制前端流水的timing和面积,以way数换容量。肯定有点下降吧。不过也不是太大的问题,和INTEL配置相当。第二,增大了micro-op cache,这样可以支持更多的微操作,同时也一定程度弥补了Icache容量下降的损失。第三,为了更高的分支预测准确率,采用了TAGE predictor。这是目前预测器竞赛中准确率最高的一种,通过离散的tagging hash进行索引和预测,硬件实现上较通常的Tournament预测器要复杂不少。在当前的处理器架构下,分支预测准确率的高低是至关重要的因素,对于深流水的高性能CPU而言更是如此,一次预测失败的代价就是数十条指令的flush。后边可以看到,TAGE可以减少30%左右的预测失败率,看来AMD在predictor上调优的功力还是很足的。第四,大幅提高了浮点的能力,支持到了AVX256,主要面向服务器领域的高性能计算。可以看出,ZEN2的设计还是有的放矢,集中提升了Vector的计算能力,同时增强分支预测期以提升单核性能,然后有选择的减少了指令cache的面积,从而比较合理的平衡了整个核心的面积和性能。可以看出,ZEN2架构的目标就是面向INTEL最赚钱的服务器领域,利用后者工艺青黄不接的间隔抢占市场,很高明的设计。
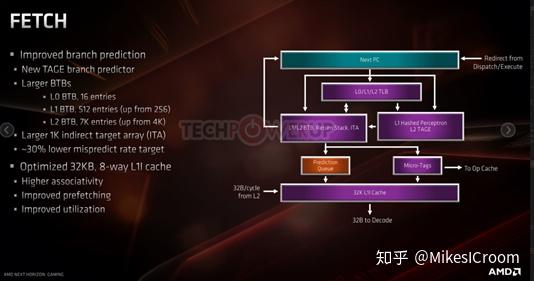
AMD E3 Tech Day Presentation June 19th 2019
前端流水中规中矩,指令cache和TAGE的改进刚才已经说过,另外针对分支预测的提升就是采用了3层的BTB,包括16个entry的L0 BTB(zero cycle penalty),512 entry的L1 BTB,以及7K entry的L2 BTB。后两层BTB都是接近翻倍的提升。还支持了一个1K大小的indirect target array用来做寄存器跳转预测。看来AMD为了更高的分支预测率真是下了不少功夫。其他的如associativity,prefetch等主要是细节上的改进。当然AMD这张图画的还是比较抽象,我根据正常的前端流水线结构重新画了一下,可以做一个参考。
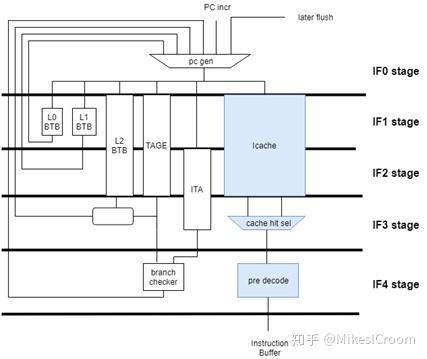
IFU pipeline Sturcture, by Mike
根据3级BTB结构来看,整个normal fetch pipeline应该在4\~5个stage左右。L 0 BTB是zero cycle penalty的CAM结构。L1 BTB 1个cycle。L2 BTB 估计是SRAM结构,2个cycle,timing上应该可以直接使用TAGE predictor的预测结果。cache hit经过3级流水,在第四级做pre decode,主要是处理指令边界和branch。由于cache中存有预译码信息,因此一级中可以完成对branch target的计算和预测检查。各个predictor的预测值会在各自stage返回到IF0的PC gen mux中,产生下一拍的PC value。以上均是个人推测。
AMD E3 Tech Day Presentation June 19th 2019

译码部分,还是标准的micro-op decode,加强了op cache size以及指令fusion,能更高效的dispatch指令package。注意op cache的吞吐量还是很高的,是正常decode的2倍,这样是足够6 dispatch的输入的。当然X86的译码向来是比较麻烦,其中各种拆分,融合,以及Microcode的拼接等,这里就不仔细分析了。
AMD E3 Tech Day Presentation June 19th 2019
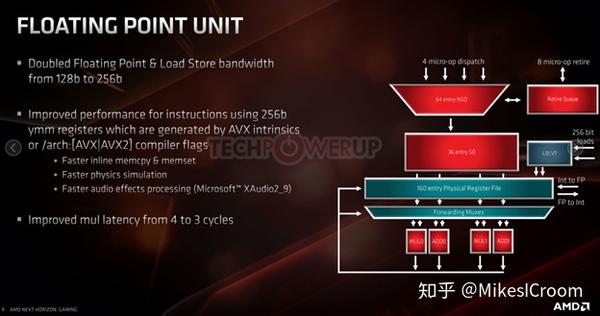
ZEN2的重头戏在浮点上,从128bits翻倍到256 bits,性能直接就翻翻了。浮点单元的整体设计还是比较经典的方案,可以看到它的配置:4条浮点微指令的dispatch,32 entry的schedule queue,160个浮点物理寄存器,双FADD和FMULT执行单元,256 bits的FP load/store。这么大的SQ和PRF能meet timing,不得不说大公司的后端团队实力的强悍。其中还有个很重要的点,AMD成功的浮点乘法减少了1个cycle。在当前浮点算法已经比较固定的时代还能有这样的提升是很难得的,不知道AMD会不会发篇论文介绍下算法上的改进策略。
AMD E3 Tech Day Presentation June 19th 2019
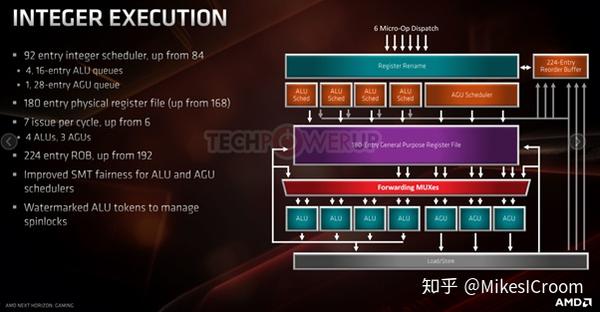
整型执行部分,同样是豪华配置,值得注意的发射数目从6增加到了7,因此ROB的entry数目响应的也从192增加到了224,SQ从84增加到了96,PRF从168增加到了180。这样主要是在芯片面积允许的情况下尽可能的提高单线程的执行能力。可以看到,ZEN采用了分离schedule queue的设计,每个ALU有自己的SQ。这样在timing上要好不少,代价就是需要在dispatch后就需要分开进入不同的SQ,这样在不同Queue之间的schedule能力会变弱,性能上会有一定的损失。不过ALU性能的核心是single cycle forwarding的能力,而制约其entry数目的主要因素就是timing。两相权衡,还是选择数量较小但支持single cycle fwd的SQ更为合理。
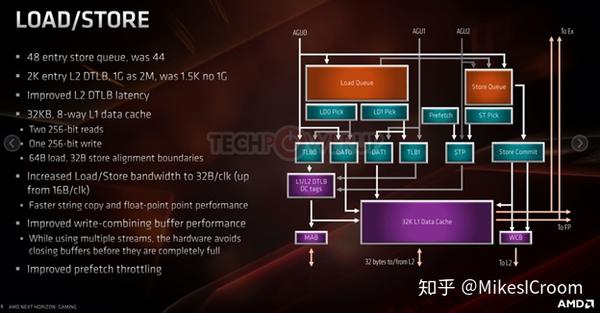
AMD E3 Tech Day Presentation June 19th 2019
Load store单元,主要是增加了load store的带宽,从16B/clk提高到32B/clk。这样是为了匹配浮点AVX256的带宽(32B=256bits),同时也可以提升memory copy的性能。其他的增强包括增加了store queue的深度,改善了L2 DTLB的latency,write merge,以及stream prefetch的能力。全乱序多路LSU向来是CPU最复杂也最有挑战的模块,其中包含了非常多的设计技巧,也有很多可以提升和平衡的细节点,这里也只能大概了解下其技术指标。

AMD E3 Tech Day Presentation June 19th 2019
ZEN2还是标准的多级cache的冯诺依曼结构,主要是加倍了L1 data cache的带宽,以及改进了prefetch和steam fetch的性能。同时增加了几条加速cache操作的指令。

AMD E3 Tech Day Presentation June 19th 2019
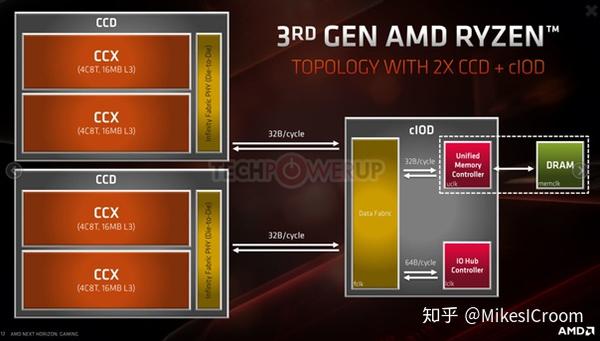
AMD E3 Tech Day Presentation June 19th 2019
之前有介绍过CPU核心和IO核心chiplet设计的特点,这两张PPT就展示了如何通过改变CPU核心的数量,组成不同级别的处理器系统的例子。
由于AMD官方并没有给出整个流水线图,这里大胆推测下。目前的X86处理器已经不在追求极限频率,因此大多流水线级数都在20级以下。ZEN2可能的划分是:4级fetch,3级decode(x86是复杂指令集),1级renaming,2级dispatch,1级schedule,2级register,1级alu,2级retire。对于LSU pipe,这个级别的处理器通常是4个cycle。因此整个ZEN流水线长度可能在19级左右。今年的hotchip,AMD会进一步展示ZEN2架构,到时希望能得到更详细的信息。
剩下的PPT就是AMD如何展示ZEN架构多么的优秀,各种秀指标,这里就不赘述了。
总体来说,ZEN2架构的设计目的鲜明,有的放矢,综合考量下没有明显的短板,同时突出增强了AVX的性能,是一个很优秀的设计。从中我们也可以看出,通用处理器的架构已经趋于稳定,在大的方面上,大家都玩不出太多的花样了。主要的经历都放在如何根据有限的芯片面积做性能的平衡,以及各种细节指标的调优。随着摩尔定律天花板的临近,单芯片的设计正在趋近它的极限。可能不用多久,我们就能欣喜的看到,国内的那些处理器厂商在快速的追进,甚至持平这些把持了多年的行业巨头。而这些巨头们,也正在奋力开发新的战场,在另一个维度上超越这些追赶者们。比如chiplet设计,比如3D堆叠,比如非CMOS的芯片制造。这些看似科幻的技术,正在逐一的变成现实。芯片的大国崛起之路,仍然任重而道远。
[1] 封面图片和文内ppt来源为AMD E3 Tech Day Presentation, June 19th 2019
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

