
本文首发于 GiantPandaCV :深入理解神经网络中的反(转置)卷积
作者:梁德澎
本文主要是把之前在知乎上的回答:
重新整理了一下并且加了一些新的内容。对于像素级的任务,在decoder部分都会用一些常规操作去逐步恢复feature map的空间大小,而常用的模块有反卷积:https://arxiv.org/pdf/1603.07285.pdfarxiv.org
上采样+卷积和subpixel:【超分辨率】Efficient Sub-Pixel Convolutional Neural Network 操作等等。
对于上采样+卷积操作,就是一个最近邻或者双线插值上采样到想要的feature map 空间大小再接一层卷积。但是对于反卷积,相信有不少炼丹师并不了解其具体实现原理,即反卷积是如何实现增大feature map空间大小的,而本文主要内容就是把反卷积具体实现讲清楚。
卷积前后向传播实现细节
在讲解反卷积计算实现细节之前,首先来看下深度学习中的卷积是如何实现前后向传播的。
先来看下一般训练框架比如Caffe和MXNet卷积前向实现部分代码:
Caffe:
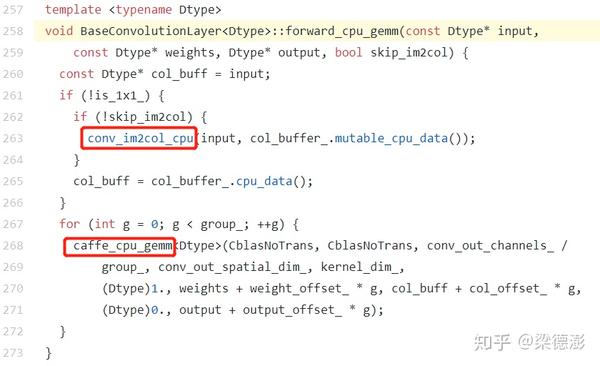
MXNet:

从实现上看,卷积的前向的实现方式都是
im2col 实现细节:

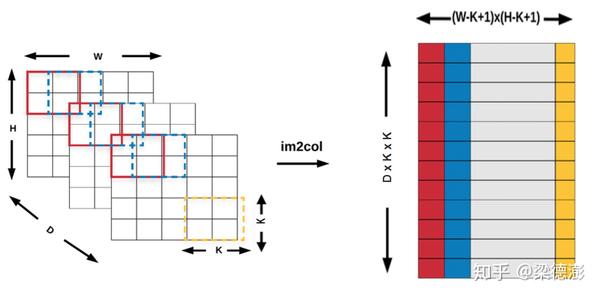
则im2col过程如入上图所示,窗口从左到右上到下的顺序在每个输入通道同步滑动,每个窗口内容按行展开成一列,然后再按通道顺序接上填到im2col buffer对应的列,且im2col buffer 按从左到右顺序填写。
因为没有padding且步长为1,所以根据卷积输出大小计算公式可得:

更一般的卷积前向计算:

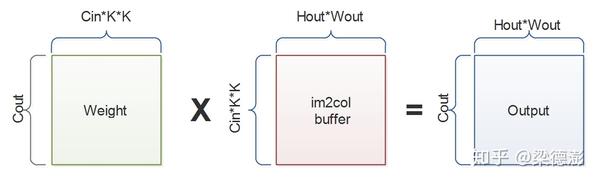
则 im2col 之前先要先根据pad在输入边缘补一圈0,然后再根据步长s去取每个卷积的位置填入buffer里面。
我们接着来看卷积反向传播是如何实现的。
其实用不太严谨的方式来想,我们知道输入对应的梯度维度大小肯定是和输入大小一致的,而上一层传回来的梯度大小肯定是和输出一致的。而且既然是反向传播,计算过程肯定是卷积前向过程的逆过程。
所以是将权值转置之后左乘输出梯度,得到类似 im2col buffer 大小的中间结果然后再接一个 col2im 操作,就可以得到输入梯度了:
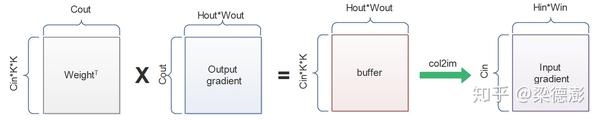
这个col2im也很好理解,就是im2col反过来,把每一列回填累加回输入梯度对应的位置,之前前向过程滑窗怎么取的就怎么填回去。

反卷积的两种实现方式
理解卷积实现细节之后,再来看下反卷积的两种实现方式,这里只讨论步长大于1,pad大于0的情况。
GEMM + col2im
其实从前面卷积的实现过程可以看到,如果卷积步长大于1的话,输出大小是小于输入的,但是反向传播的时候,输出梯度通过
下面给出反卷积前向过程示意图:
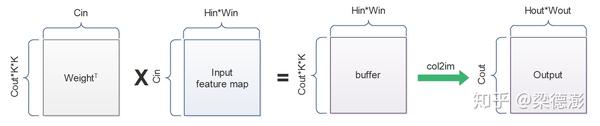
所以反卷积核的维度是
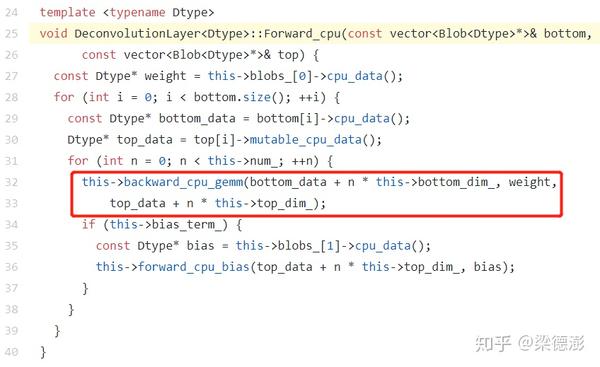
看caffe里面反卷积的实现确实也是调用的卷积的后向传播实现。
一般在用反卷积的时候都是需要输出大小是输入的两倍这样子,但是仔细回想一下卷积的输出大小计算公式:
如果根据这个公式反推,




下面画个简单的计算流程图展示下卷积的反向传播和反卷积的前向传播过程,假设卷积和反卷积核大小都是3x3,步长为2,pad为1,卷积输入大小是4x4,则假设需要卷积输出或反卷积输入大小是2x2,则现在看下如何从2x2大小的输入反推输出4x4。
为了方便理解,假设卷积输出梯度或者反卷积输入都是1,输入和输出通道都是1:
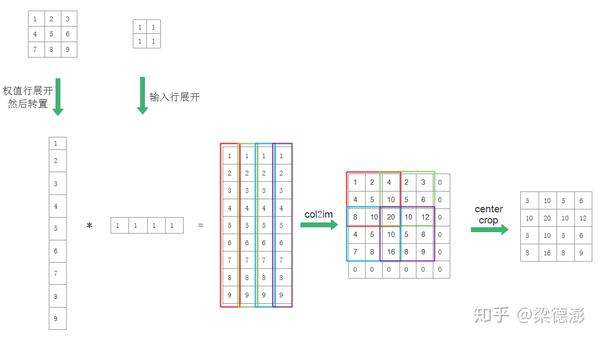
为什么要center crop,可以这样想,原来卷积输入是4x4的,然后是pad了0再卷积得到输出2x2,在梯度回传的时候我们其实是只需要中间4x4部分的梯度,相当于把pad的部分去掉。
用MXNet[7]代码验证下:
import mxnet as mx
import numpy as np
data_shape = (1, 1, 2, 2)
data = mx.nd.ones(data_shape)
deconv_weight_shape = (1, 1, 3, 3)
deconv_weight = mx.nd.ones(deconv_weight_shape)
deconv_weight[:] = np.array([1,2,3,4,5,6,7,8,9]).reshape((1,1,3,3))
# deconvolution forward
data_deconv = mx.nd.Deconvolution(data=data, weight=deconv_weight,
kernel=(3, 3),
pad=(1, 1),
stride=(2, 2),
adj=(1, 1),
num_filter=1)
print(data_deconv)
# convolution backward
data_sym = mx.sym.Variable('data')
conv_sym = mx.sym.Convolution(data=data_sym, kernel=(3, 3), stride=(2, 2), pad=(1, 1), num_filter=1, no_bias=True, name='conv')
executor = conv_sym.simple_bind(data=(1, 1, 4, 4), ctx=mx.cpu())
deconv_weight.copyto(executor.arg_dict['conv_weight'])
executor.backward(mx.nd.ones((1, 1, 2, 2)))
print(executor.grad_dict['data'])
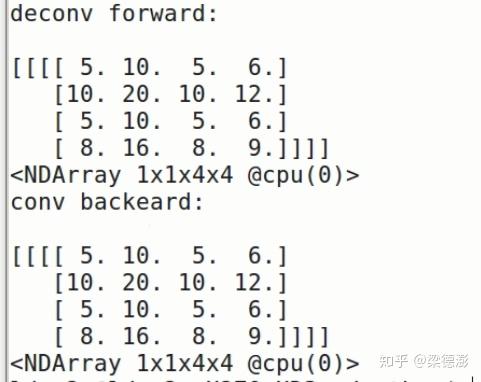
可以看到运行结果和手推是一样的:
输入插空补0+卷积
其实反卷积还有一种实现方式,就是输入插空补0再加一个卷积(这里需要注意,卷积的时候需要把反卷积核旋转180度,下面会详细讲)的方式,同上这里只讨论步长大于1,pad大于0的情况。
根据文章
https://arxiv.org/pdf/1603.07285.pdfarxiv.org
4.6节给出的推导公式,先从卷积前向方向来看 i,假设输入是,卷积核大小、步长和pad分别是k,s,p,则卷积输出大小计算公式如下:
下面看下文章[5]中给出的示意图:




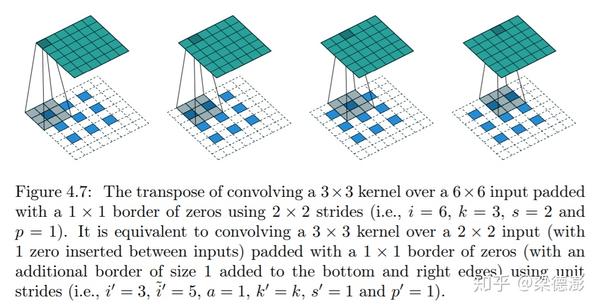

下面用实际例子来讲解下实际计算过程,假设反卷积核大小都是3x3,步长为2,pad为1,假设反卷积输入大小是2x2,则现在看下如何从2x2大小的输入反推输出4x4。
为了方便理解,假设反卷积输入都是1,输入和输出通道都是1:
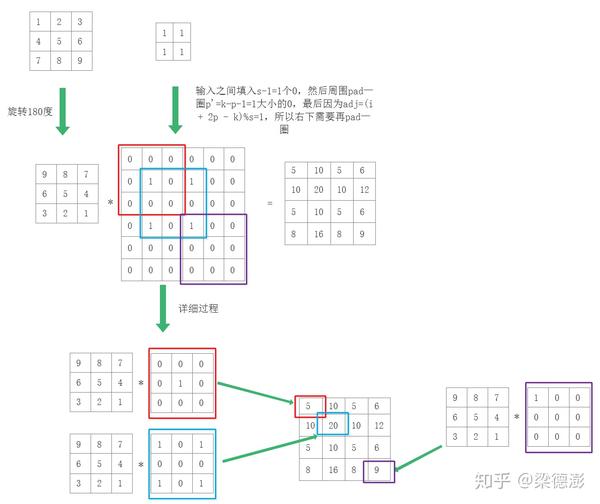
可以看到结果和上面+方式是一致的。
一般看训练和推理框架的实现的方式都是+,而插空补0这种实现,目前我在MNN[6]这个推理框架里有见到,其Metal GPU上的实现用的是这个思路:
https://github.com/alibaba/MNN/blob/master/source/backend/metal/MetalDeconvolution.metal#L83
#define UP_DIV(x, y) (((x) + (y) - (1)) / (y))
#define ROUND_UP(x, y) (((x) + (y) - (1)) / (y) * (y))
kernel void deconv_depthwise(const device ftype4 *in [[buffer(0)]],
device ftype4 *out [[buffer(1)]],
constant deconv_constants& cst [[buffer(2)]],
const device ftype4 *wt [[buffer(3)]],
const device ftype4 *biasTerms [[buffer(4)]],
ushort3 gid [[thread_position_in_grid]]) {
if ((int)gid.x >= 4 || (int)gid.y >= 4) return;
float4 result = float4(biasTerms[(short)gid.z]);
short oy = (short)gid.y + 1;
// 第一个输出:1,第6个输出:2
short ox = (short)gid.x + 1;
// 第一个输出:1,第6个输出:2
short max_sy = min((2 - 1) * 2, oy / 2 * 2);
// 第一个输出:0,第6个输出:2
short max_sx = min((2 - 1) * 2, ox / 2 * 2);
// 第一个输出:0,第6个输出:2
short min_ky = UP_DIV(oy - max_sy, 1);
// 第一个输出:1,第6个输出:0
short min_kx = UP_DIV(ox - max_sx, 1);
// 第一个输出:1,第6个输出:0
if ((oy - min_ky * 1) % 2 == 0 && (ox - min_kx * 1) % 2 == 0) {
short min_sy = max(0, ROUND_UP(oy + 1 - 3 * 1, 2));
// 第一个输出:0,第6个输出:0
short min_sx = max(0, ROUND_UP(ox + 1 - 3 * 1, 2));
// 第一个输出:0,第6个输出:0
short max_ky = (oy - min_sy) / 1;
// 第一个输出:1,第6个输出:2
short max_kx = (ox - min_sx) / 1;
// 第一个输出:1,第6个输出:2
short min_iy = (oy - max_ky * 1) / 2;
// 第一个输出:0,第6个输出:0
short min_ix = (ox - max_kx * 1) / 2;
// 第一个输出:0,第6个输出:0
for (auto ky = max_ky, iy = min_iy; ky >= min_ky; ky -= 2, iy += 2) {
for (auto kx = max_kx, ix = min_ix; kx >= min_kx; kx -= 2, ix += 2) {
auto wt4 = wt[ky * 3 + kx];
auto in4 = in[iy * 2 + ix];
result += float4(in4 * wt4);
}
}
}
}

的结构,所以实际启动线程需要把通道数需要除以4,同时上取整。
对于C4格式的解释见:
Tensor中数据摆放顺序NC4HW4是什么意思,只知道NCHW格式,能解释以下NC4HW4格式吗?
这里kernel实现的是计算一个输出点的代码,而且因为实际实现并没有真的去插空补0和Padding,所以看到绝大部分代码在计算当前线程负责的输出点所对应的权值和输入的取值索引。这里线程维度是3维的,所以gid.x表示输出宽索引,gid.y表示高索引,gid.z表示通道索引。
代码里面的注释是按照卷积顺序,计算第一个卷积输出点和第6个输出点,变量所对应的值,就是上面流程图的红框和蓝框。最后看到卷积循环,恰好就是对应各自输入和权值的取值点。
反卷积的缺点
分析完反卷积的运算过程,再来看下反卷积的缺点。
反卷积有一个最大的问题是,如果参数配置不当很容易出现输出feature map带有明显棋盘状的现象,原因就是在与回填 col2im这一步。
文献
https://distill.pub/2016/deconv-checkerboard/distill.pub
就分析的非常好,值得细读,里面提供了可动态配置反卷积的kernel size和stride然后可视化输出结果,可以看到当stride为2的时候,kernel是奇数就会出现网格:
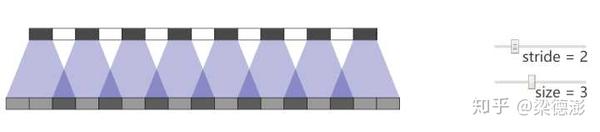

而偶数kernel就不会:


而如果是多层堆叠反卷积的话而参数配置又不当,那么棋盘状的现象就会层层传递:
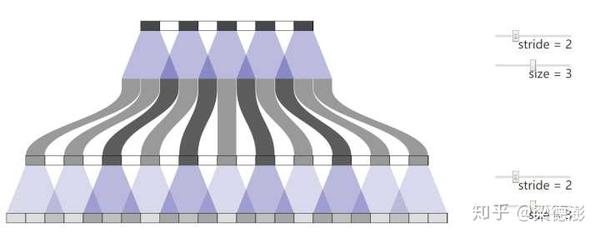
所以当使用反卷积的时候参数配置需要特别的小心。
下面就用简单的几句代码来复现使用反卷积可能会带来的的网格问题:
import mxnet as mx
batch_size = 1
in_channel = 1
height = 5
width = 5
data_shape = (batch_size, in_channel, height, width)
data = mx.nd.ones(data_shape)
out_channel = 1
kernel_size = 3
deconv_weight_shape = (in_channel, out_channel, kernel_size, kernel_size)
deconv_weight = mx.nd.ones(deconv_weight_shape)
stride = 2
up_scale = 2
data_deconv = mx.nd.Deconvolution(data=data, weight=deconv_weight,
target_shape=(height * up_scale, width * up_scale),
kernel=(kernel_size, kernel_size),
stride=(stride, stride),
num_filter=out_channel)
print(data_deconv)
data_upsample = mx.nd.contrib.BilinearResize2D(data=data, scale_height=up_scale, scale_width=up_scale)
conv_weight_shape = (out_channel, in_channel, kernel_size, kernel_size)
conv_weight = mx.nd.ones(conv_weight_shape)
pad = (kernel_size - 1) / 2
data_conv = mx.nd.Convolution(data=data_upsample, weight=conv_weight,
kernel=(kernel_size, kernel_size),
pad=(pad, pad), num_filter=out_channel, no_bias=True)
print(data_conv)
这里为了简化,反卷积和卷积的权重都是设为1,而输入与输出 feature map 通道数都是1,输入 feature map 的值都是1,然后来看下反卷积和上采样+卷积的前向结果:
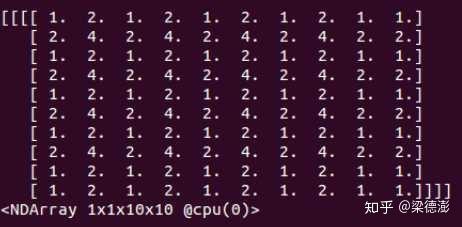

可以看到,kernel为3,步长为2的情况下,反卷积在不训练的情况下,输出就带有明显很规律的棋盘状。接着我们把kernel改为4看看:
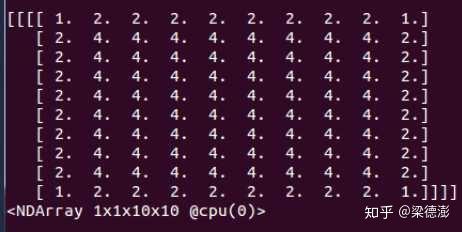
可以看到棋盘状消失了。
所以在实际应用中对于一些像素级别的预测任务,比如分割,风格化,Gan这类的任务,对于视觉效果有要求的,在使用反卷积的时候需要注意参数的配置,或者直接换成上采样+卷积。
参考资料
- [1]https://www.zhihu.com/question/328891283/answer/717113611
- [2]https://www.zhihu.com/question/48279880/answer/838063090
- [3] https://distill.pub/2016/deconv-checkerboard/
- [4]https://blog.csdn.net/shwan\_ma/article/details/78440394
- [5] https://arxiv.org/pdf/1603.07285.pdf
- [6] https://github.com/alibaba/MNN
- [7] https://github.com/apache/incubator-mxnet
- [8]https://www.zhihu.com/question/337513515/answer/768632471
推荐文章
更多AI移动端优化的请关注专栏嵌入式AI以及知乎(@梁德澎)。

