
深度学习在移动端的应用是越来越广泛,由于移动端的运算力与服务器相比还是有差距,所以在移动端部署深度学习模型需要精简模型的结构。
作者:梁德澎
首发知乎:https://zhuanlan.zhihu.com/p/79254846
深度学习在移动端的应用是越来越广泛,由于移动端的运算力与服务器相比还是有差距,所以在移动端部署深度学习模型的难点就在于如何保证模型效果的同时,运行效率也有保证。在实验阶段对于模型结构可以选择大模型,因为该阶段主要是为了验证方法的有效性。在验证完了之后,开始着手部署到移动端,这时候就要精简模型的结构了,一般是对训好的大模型进行剪枝,或者参考现有的比如MobileNetV2 和 ShuffleNetV2 等轻量级的网络重新设计自己的网络模块。而算法层面的优化除了剪枝还有量化,量化就是把浮点数(高精度)表示的权值和激活值用更低精度的整数来近似表示。低精度的优点有,相比于高精度算术运算,其在单位时间内能处理更多的数据,而且权值量化之后模型的存储空间能进一步的减少等等。对训练好的网络做量化,在实践中尝试过TensorRT的后训练量化算法,在一些任务上效果还不错。但是如果能在训练过程中去模拟量化的过程,让网络学习去修正量化带来的误差,那么得到的量化参数应该是更准确的,而且在实际量化推断中模型的性能损失应该能更小。而本文的内容就是介绍google的论文和复现其过程中的一些细节。本文相关实验代码:
https://github.com/Ldpe2G/DeepLearningForFun/tree/master/Mxnet-Scala/TrainQuantization
训练模拟量化
首先来看下量化的具体定义,对于量化激活值到有符号8bit整数,论文中给出的定义如下:
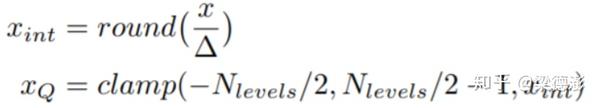
公式中的三角形表示量化的缩放因子,x表示浮点数激活值,首先通过除以缩放因子然后最近邻取整,然后把范围限制到一个区间内,比如量化到有符号8bit,那么范围就是 [-128, 127]。而对于权值还有一个小的技巧,就是量化到[-127, 127]:
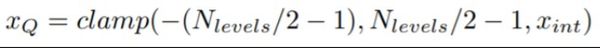
具体为什么这么做,论文中说了是为了实现上的优化,具体解释可以看论文附录B ARM NEON details这一小节。
而训练量化我理解就是在forward阶段去模拟量化这个过程,就是把权值和激活值量化到8bit再反量化回有误差的32bit,所以训练还是浮点,backward阶段是对模拟量化之后权值的求梯度,然后用这个梯度去更新量化前的权值。然后在下个batch继续这个过程,通过这样子能够让网络学会去修正量化带来的误差。

上面给这个示意图就很直观的表示了模拟量化的过程,比如上面那条线表示的是量化前的范围[rmin, rmax],然后下面那条线表示的就是量化之后的范围[-128, 127],比如现在要进行模拟量化的forward,先看上面那条线从左到右数第4个圆点,通过除以缩放因子之后就会映射124到125之间的一个浮点数,然后通过最近邻取整就取到了125,再通过乘以缩放因子返回上面第五个圆点,最后就用这个有误差的数替换原来的去forward。forward阶段的模拟量化用公式表示如下:
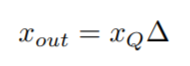
backward阶段求梯度的公式表示如下:
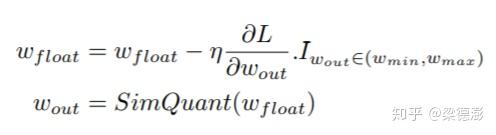
对于缩放因子的计算,权值和激活值的不一样,权值的计算方法是每次forward直接对权值求绝对值取最大值,然后缩放因子 weight scale = max(abs(weight)) / 127。然后对于激活值,稍微有些不一样,激活值的量化范围不是简单的计算最大值,而是通过EMA(exponential moving averages)在训练中去统计这个量化范围,更新公式如下:
moving\_max = moving\_max * momenta + max(abs(activation)) * (1- momenta)
公式中的activation表示每个batch的激活值,而论文中说momenta取接近1的数就行了,在实验中我是取0.95。然后缩放因子 activation scale = moving\_max /128。
实现细节
在实现过程中我没有按照论文的方法量化到无符号8bit,而是有符号8bit,第一是因为无符号8bit量化需要引入额外的零点,增加复杂性,其次在实际应用过程中都是量化到有符号8bit。然后论文中提到,对于权值的量化分通道进行求缩放因子,然后对于激活值的量化整体求一个缩放因子,这样效果最好。在实践中发现权值不分通道量化效果也不错,这个还是看具体任务吧,而本文给出的实验代码是没分的。
然后对于卷积层之后带batchnorm的网络,因为一般在实际使用阶段,为了优化速度,batchnorm的参数都会提前融合进卷积层的参数中,所以训练模拟量化的过程也要按照这个流程。首先把batchnorm的参数与卷积层的参数融合,然后再对这个参数做量化。以下两张图片分别表示的是训练过程与实际应用过程中对batchnorm层处理的区别:
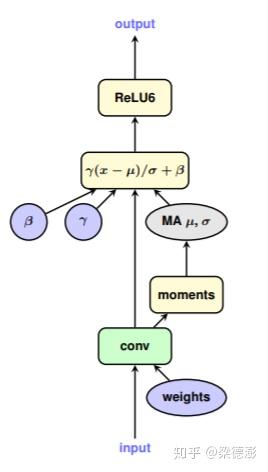
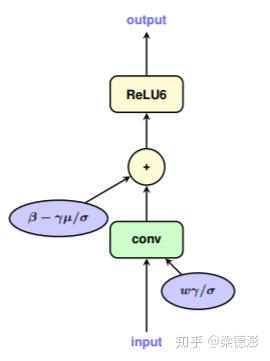
对于如何融合batchnorm参数进卷积层参数,看以下公式:
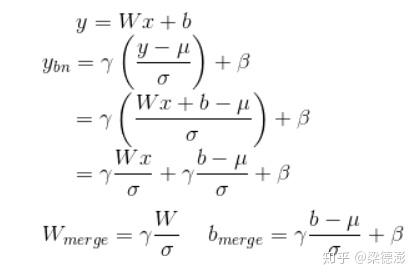
公式中的,W和b分别表示卷积层的权值与偏置,x和y分别为卷积层的输入与输出,则根据bn的计算公式,可以推出融合了batchnorm参数之后的权值与偏置,Wmerge和bmerge。这里对于融合了bn权值的偏置的公式推导结果和论文中的有些不同,论文中的结果看起来应该是没有考虑卷积层本身带有偏置的情况。
而且在实验中我是简化了融合batchnorm的流程,要是完全按照论文中的实现要复杂很多,而且是基于已经训好的网络去做模拟量化实验的,不基于预训练模型训不起来,可能还有坑要踩。而且在模拟量化训练过程中batchnorm层参数固定,融合batchnorm参数也是用已经训好的移动均值和方差,而不是用每个batch的均值和方差。
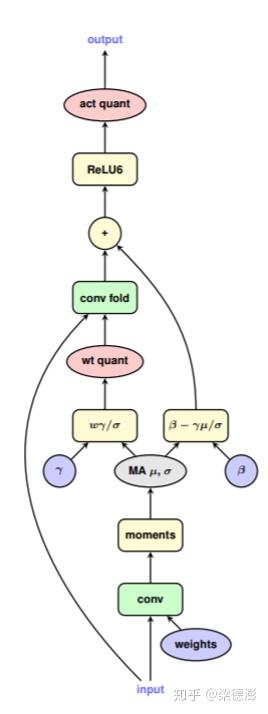
具体实现的时候就是按照论文中的这个模拟量化卷积层示例图去写训练网络结构的。
实验结果
用VGG在Cifar10上做了下实验,效果还可以,因为是为了验证量化训练的有效性,所以训Cifar10的时候没怎么调过参,数据增强也没做,训出来的模型精确度最高只有0.877,比最好的结果0.93差不少,然后模拟量化是基于这个0.877的模型去做的,可以得到与普通训练精确度基本一样的模型,可能是这个分类任务比较简单。然后得到训好的模型与每层的量化因子之后,就可以模拟真实的量化推断过程,不过因为MXNet的卷积层不支持整型运算,所以模拟的过程也是用浮点来模拟,具体实现细节可见示例代码。
结束语
以上内容是根据最近的一些工作实践总结得到的一篇博客,对于论文的实现很多地方都是我自己个人的理解,如果有读者发现哪里有误或者有疑问,也请指出,大家互相交流学习:)。
相关资料:
- https://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd
- https://github.com/google/gemmlowp/blob/master/doc/quantization.md
- https://arxiv.org/pdf/1712.05877.pdf
- https://arxiv.org/abs/1806.08342
- http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
- https://arleyzhang.github.io/articles/923e2c40/
推荐文章
更多AI移动端优化的请关注专栏嵌入式AI以及知乎(@梁德澎)。

