
最近在学习RISCV相关的东西,发现了Berkeley一个很有意思的项目:HWACHA。这是一个使用RISCV开源处理器构建的类vector的多核异构系统,可以用来做低算力的深度学习应用。当然HWACHA本身也是开源的,有兴趣可以去github下载源码跑跑看。这里还是从硬件设计的角度来分析下这种多核异构系统的特点。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/87038542
Summary:HWACHA使用了自定义的类Vector指令集,通过内嵌调用的形式和RISCV ISA整合在一起。HWACHA的执行类似于紧耦合的coprocessor,RISCV core负责循环的控制,Vector units负责主要的向量运算。两者通过特殊的指令进行co-work,实现控制和运算错拍的并行执行。相比传统的处理器Vector扩展,HWACHA将integer和vector完全隔离,硬件设计相对简单且易于扩展,可以提供良好的并行性。不过由于是独立的指令集,需要和RISCV ISA一起联合编译,对compiler有特殊的要求。
HWACHA是Berkeley的一个research 项目,从2011年第一代起,几乎每年都有流片,到V4架构推出,已经是第14款芯片了,好快的迭代速度。HWACHA项目的初衷是探索一个energy-efficient的Vector architecture,基于RISC open ISA,设计一种数据高并行的可扩展结构。
这里先简单介绍下vector的背景。向量计算(Vector)是一种特殊的单指令流多数据结构,主要面向科学运算,加解密,建模分析等高强度的计算任务。例如ARM的SVE。相比于传统的SIMD结构(如ARM的Advanced SIMD扩展),Vector的主要优势是良好的软件可移植性,也就是说相同的binary code,在不同规模的Vector机器上可以不经改动直接执行,同时软件编程中不需要考虑根据具体硬件执行的宽度进行数据重排。这种软件透明的设计大大减轻了软件设计和维护的代价,因此在服务器领域应用广泛。
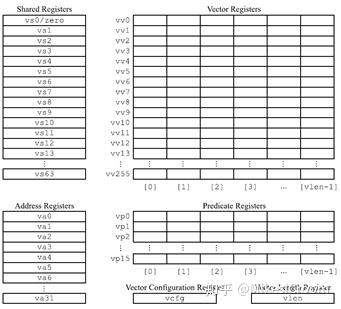
HWACHA的Vector指令集基本上类似于SVE,主要包括Vector寄存器堆VV0-VV255,Predicate寄存器堆VP0-VP15,以及向量控制寄存器VLEN。注意这里的vector寄存器有256个之多,大量的寄存器当然有利于编译器优化,提升执行性能,但是会对硬件设计主要是频率带来影响,后边可以硬件为了支持这么大的寄存器寻址采取了特殊的机制。由于HWACHA是单独的指令集,因此增加了一组标量寄存器堆用作控制和标量计算。这里比较特殊的是有独立的地址寄存器堆VA0-VA31,这样load和store就不会占用标量寄存器号,有利于更好的schedule计算和存储。不过这样就需要在指令编码中有专用位来指定寄存器的类型。对传统的32位指令编码,这当然是个问题,会侵占指令编码空间,不过HWACHA非常激进,直接采用了64位指令宽度,这样一来编码空间就不是问题了。指令密度当然会大不少,不过考虑到vector本身会以循环方式执行,指令数目有限,那么这也不算是个很大的缺点。
HWACHA的执行方式是很有特点的。首先整个Vector Engine作为一个coprocessor,和主CPU之间是de-couple开的,通过特殊的指令和传输buffer进行交互。而这种交互过程是interleave的,可以实现back2back的并行,因此从这个角度来看,又是couple在一起的。例如一个简单的for循环code:

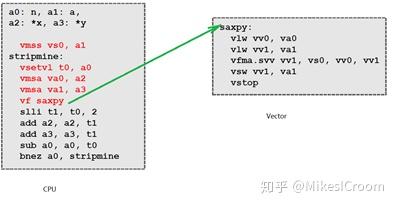
HWACHA的编译器会将其分解为循环控制部分和向量执行部分,前者在主CPU中执行,后者在Vector engine中执行。CPU通过一条特殊指令VF(Vector Fetch)来通知Vector engine开始执行,VF的参数即为Vector执行的起始PC。在后者执行完成后,通过vstop(Vector Stop)指令来表示执行暂停,等待下次VF的输入。在Vector engine执行的同时,CPU继续执行,进入下一拍循环进行数据和控制准备。这种方案可以提供CPU和Vector错开的并行执行能力,同时控制和数据又能有效的隔离,一方面简化控制复杂度,另一方面Vector不受限于CPU的硬件结构和带宽,有很大的设计灵活性,比如HWACHA V4的一拖多结构:
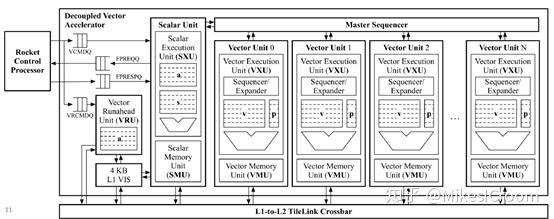
CPU和Vector之间通过若干个Buffer进行交互。当CPU执行到VF指令后,会将其push到VCMDQ中。Vector通过内部的Scalar Unit从VF指定的PC开始取指执行,取到的Vector指令会发送到Master sequencer中,由其负责分发到各个Vector unit中去执行。每个Vector Unit就是一个in-order的Vector核,包括local sequencer负责内部调度,Vector和Predicate寄存器堆,以及独立的Vector Load&Store unit,通过Crossbar和片外存储相连。在执行过程中,每个Vector Unit都是独立运行的,只有指令(操作)从Master sequencer中统一取得。左边还有一个Vector runahead Unit,应该是负责提前计算一些执行所需的信息,保证Vector Units的数据流的连贯性。整个架构是一种特殊的SIMD形式,用较少的控制来驱动大量的计算,而各个计算单元间又是独立的,不需要像传统SIMD指令那样进行同步。这样控制当然会简单,但同时也无法支持精确异常等控制流事件。不过考虑到Vector的主要应用场景,这并不算是一个很大的问题。
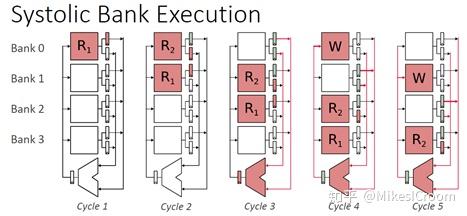
整个执行单元的设计并没有太多的特殊之处,该有的arithmetic unit都有了。比较有特点的是它把ALU放到了寄存器堆的BANK里,每个BANK都有一个。这样的设计主要用来加速单cycle ALU的执行,是对HWACHA SRAM寄存器堆结构读写效率不高的缺陷的一种弥补。
整体来说,HWACHA是一个偏研究性质的架构,很多问题的解决并非从工程的思路出发,选择简洁高效的方案,而是更多地进行多种可能性的探索。除去这些,HWACHA的控制数据de-couple的想法,以及Vector部分并行运算的软硬件协同支持,都很有特点,同时HWACHA中指令集层面的部分思路,也已经提交作为RISCV open ISA vector extension的标准。从这个角度来看,HWACHA的探索很有意义,也很成功。
[1]文中图片来源 http://hwacha.org/
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

