
上周Intel在加州举办的Linley秋季处理器大会上发布了X86 Atom低功耗处理器系列Tremont的架构设计细节。Intel面向终端领域的处理器主要是2个产品线,一个是高性能的CORE系列,就是我们通常所说的“酷睿”,用于桌面系统;另一个是低功耗的ATOM系列,中文称为“凌动”,主要面向移动端和IOT。Tremont作为ATOM的最新架构,其设计思路和高性能的Sunny Cove会有很大不同,对于功耗、面积等指标会更看重。本文将通过解读Tremont的公开信息来探讨intel移动端处理器的设计细节和思路。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/89399051
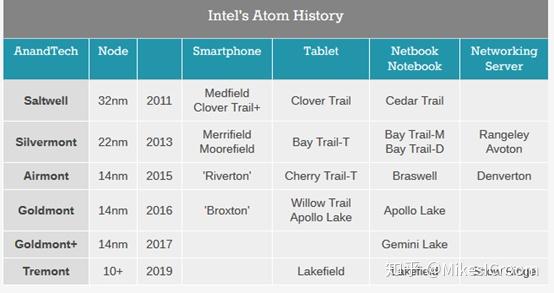
Atom芯片曾经在上网本中辉煌过一阵,不过随着智能手机的普及,ARM以绝对的优势垄断了这个庞大的市场,Atom似乎销声匿迹了。尽管Atom的功耗一直被人所诟病,不过由于其基于X86指令集,在兼容性和编程性上还是有一定的优势,尤其是需要与桌面系统配合的时候。因此在工业领域和一些专用移动市场,比如windows平板,个人存储(NAS)等领域还是有广泛的使用。
Intel在Goldmont plus之后规划了3代架构路线:Tremont, Gracemont, and ‘Future Mont’。Tremont作为第一代10nm的低功耗架构,不但是对上一代架构细节和指标上的改进,更重要的是和高性能的CORE核心一起组成异构多核系统,提供更好的能耗。这个方法跟ARM的big.LITTLE架构差不多,都是在一个系统里捆绑多个高性能核心和低功耗核心,根据不同程序的负载需求来选择对应的核心运行,其他核心进入低功耗状态,从而获取性能和功耗的良好平衡。Intel的大小端系统称为“Lakefiled”,包括一个CORE内核:Sunny Cove;还有四个ATOM核:Tremont。根据披露的信息,Lakefield可以支持1+4个核心同时工作,这个和ARM的big.LITTLE不太一样,后者只能选择其中一类进行工作。这里可以看出Intel和ARM在异构系统设计上的不同。ARM注重的是能耗平衡,而Intel更希望在高性能应用中尽可能挖掘各个核心的潜力,从而获得更高的性能。Atom虽然是低功耗核心,不过这是相对于CORE核心而言的,比ARM来说还是要高不少。Tremont核心的配置和ARM A77不相上下,可以说是intel的little core相当于ARM 的big core。这也是面向不同领域设计的选择。ARM的big.LITTLE是移动端,功耗敏感,小核心并不能提供多少性能输出;而Intel的Lakefield是桌面和服务器端,在高负载下输出尽可能高的性能更重要,同时在低负载情况下控制功耗。不过结构不同的多处理器同时运行,在软件调度上的要求不小,这个就非常考验Intel的软件优化实力了。

基于上述分析,Tremont的设计指标就很好理解。虽然是低功耗核心,performance仍然是第一位的。可以看到相对上代的Goldmont plus,Tremont有进30%的性能提升,甚至在一定的功耗下,其能效比Sunny Cove还要高一些。在性能提升的前提下,再设计相关的结构来控制功耗和成本。
Tremont的基本流水线框图,这个图画的实在是难以描述,看起来挺炫,如同PCB版图一样,对于理解并没有多大帮助。可以看到Tremont的硬件配置,6 decode,4 dispatch,10 exec,dual load store。这个小核心和ARM的大核心A77差不多。其中有几个值得关注的细节,首先就是2个decode pipe的设计,每个pipe包含3个decoder,一起组成3x2=6个decode 宽度。这个结构比较奇怪,并没有遵循通常的多位宽译码设计,尤其是在没有明确指出multi-threading需求的情况下,后边会仔细分析其细节。其次是较小的dispatch宽度,通常都会选择dispatch和decoder宽度一致,较小的dispatch宽度似乎有些浪费decoder的逻辑,对于10 execution ports的需求也有些勉强,这里应该主要考虑了功耗和成本的需求。第三是小核心仍然支持了AVX128运算,体现了在算力上的需求。因而低功耗上就比较有限了。我在wiki上也搜到了一张重绘过的Tremont结构图,可以用来参考。


前级流水的设计和传统结构没有太大的不同,主要的改进针对prefetchers and branch predictor。Tremont使用了和CORE架构中类似的prefetch和predictor,虽然增加了面积,但可以换取更好的预取性能和分支预测准确率,这个也和其性能优先的设计思路相关。和ZEN类似,Tremont也使用了zero cycle penalty的L1 predictor(应该是BTB)。这里提到了一个新概念“out of order fetch”。通常处理器的执行在renaming之前一定都是顺序的,之后开始乱序执行,但通过ROB来管理指令的程序流顺序。从fetch就开始out-of-order似乎不科学。我认为这里的out-of-order并不是通常意义上的乱序执行,而是支持了更深的instruction prefetch。通过在更长的prefetch序列上做预测,直接获取预测后的指令序列,这样体现出一定程度的乱序,但是并没有打乱程序流的顺序。可以看到Tremont可以支持8条cachelilne miss的pre-fetch操作,和上述分析是匹配的。

Tremont采用了一个比较奇怪的decode流水设计。从FETCH之后,流水线被分成对称的2条,每条包括3个decoder和独立的inst Queue,然后在RENAME级重新合并。这个设计是很少见的。分离的decode虽然可以提供6宽度的译码,不过如果其硬件完全独立的话,并不能很好的处理两者之间的依赖关系,微指令的处理也会受影响。由于没有更多的细节,这里只能猜测其设计的初衷。一个可能的原因是功耗,通过关闭其中一条decoder,可以在小核心内实现一个更小的运行核心,不过这就需要单独的clock/power domain,也需要其他模块的可配置支持。其次是多线程,虽然Tremont结构没有提到multi-threading的设计,但2条分离的pipeline在微架构上是可以提供一个简单的双线程设计的。不过考虑到之前atom也能支持多线程,再设计一个特殊的多线程结构的理由并不是很能站住脚。第三就是简化设计,提高频率。通过牺牲6 decoder的译码性能来简化多位宽译码逻辑。虽然有上述分析,不过这些并不是特别有说服力的理由。希望之后能从Intel得到更多的信息。
另一个特殊的设计是6 decode,4 dispatch,10 exec的配置组合。中间的dispatch宽度似乎有点小。同时Tremont结构为了减少面积还省掉了mop cache。这个数字的比例感觉上不是特别的合理。相信Intel在选取配置的时候肯定是做过性能评估的,认为这样的组合在有限的面积上可以获得令人满意的性能。因此可能的理由应该是为了面积和功耗。由于缺少了mop cache,dispatch需要直接从decoder获取最多6条指令。而通常由于执行单元的限制,可能并不能一次将所有的指令发射下去,在这种情况下,减少dispatch端口数目可以降低硬件复杂度和时序的影响。虽然有这些可能的理由,最终的决定还是多依赖于性能评估的结果。
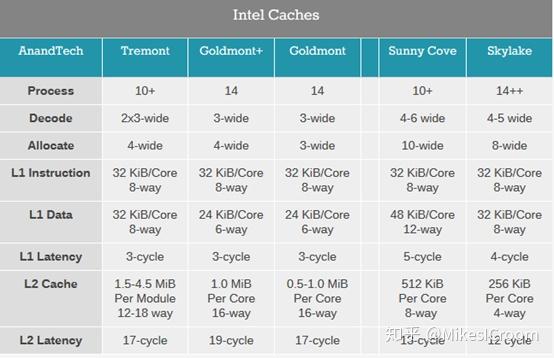
cache结构上,Tremont还是很大方的,32KB的L1,1.5\~4.5MB的L2,和主流的高端移动处理器持平。在memory hierarchy上,L2处于一个cluster内,可以被1\~4个核心共享。相比上代,Tremont还支持了L3 cache,可以cross cluster访问。这基本上是主流处理器内存系统的设计。可以看到ATOM系列的L2 latency较 Sunny Cove高不少,其中应该是将某些并行访问改为了串行访问以减少存储操作的功耗。

后端流水线的主要提升是直接把ROB的数目从95增加到了208。这样大大增加了处理器并行执行的指令数目和动态调度能力,和其10个exec pipe的能力相匹配。执行上Tremont是标准的renaming physical resigster结构。这里的RS就是我们通常所说的issue Queue。这里Tremont采用了分离式的Issue Queue,这个跟ZEN是类似的。看来现在的主流设计更注重频率和ALU的性能,从而部分牺牲了在schedule上的效率。整数执行上3个ALU,1 branch,2条LS addr流水线和1条store data流水线,和A77基本上持平。这一部分大家的思路都差不多。

AVX流水线上也是中规中矩。Tremont支持128bits运算宽度,包含2条ALU和一条store data pipeline。执行上两个ALU并不对等,一个支持 fused additions (FADD),另一个支持fused multiplication and division (FMUL)。

总结一下,Tremont的设计主要体现了Intel在异构多核上的思路,即以高性能桌面和服务器为目标,在能耗允许的前提下,尽可能挖掘小核心的运算能力,从而和大核心一起提供更强劲的性能。这个和ARM在big.LITTLE结构上的思路是有所不同的。尽管有一些类似乱序fetch,dual pipe decoder的设计,从大的结构上,Tremont并没有跟传统处理器有什么明显区别。可以说现代处理器的设计已经进入了细节为王的时代,比拼的是每个小模块的设计和技巧,通过一点点的改进,聚沙成塔,最后在整体上体现出较大的优势。Intel有上千人的设计团队,可以在算法探索,微架构设计,物理实现上做的更深入更细致,最终累积出巨大的优势。这也是目前国内设计公司比较欠缺的地方。随着更多的人参与到集成电路的事业中,并能够沉下心做设计,不断积累经验,我们就能够慢慢的缩小和这些巨头的差距,直到有能力挑战。
[1]文中图片来源: https://www.anandtech.com/show/15009/intels-new-atom-microarchitecture-the-tremont-core/2
https://en.wikichip.org/wiki/intel/microarchitectures/tremont
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

