
ncnn的模型结构+Tengine的速度,试试?
作者:圈圈虫
背景
自从arm家Cortex-A系列的armv8.2发布以来,让端侧AI推理框架开源社区比较感兴趣的也就两个点:
- 针对FP16计算的FMLA指令;
- 针对Int8计算的SDOT指令。
毕竟在CNN网络中,耗时占比最大的Operator依然是计算量繁重的Convolution乘加计算。今天暂时不讨论Int8计算的改进,让我们先来看看armv8.2架构上fp16计算单元有何神秘的地方?(说得好像大家不知道一样……)
苦哈哈的虫叔,唯一的armv8.2平台
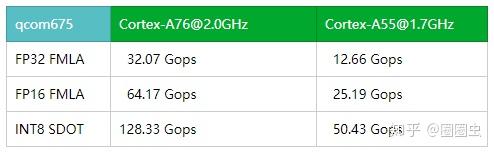
上表中的数据为通过一个简单的Perf-test小程序,粗暴的获取高通675芯片上大小核心的不同精度峰值算力。从表中得知采用Int8 SDOT、FP16相比FP32的NEON矢量计算峰值算力分别有4倍、2倍的性能提升。看来arm的CPU也能单核上0.1Tops的算力啦……O(∩\_∩)O哈哈~
《arm-solutions-brief-machine-learning-at-the-edge-for-devices》
有理有据
为了验证测试程序是否正确,我们可以打开arm官方的软件优化手册《Arm Cortex-A55 Software Optimization Guide》求证。
好看的封面.jpg
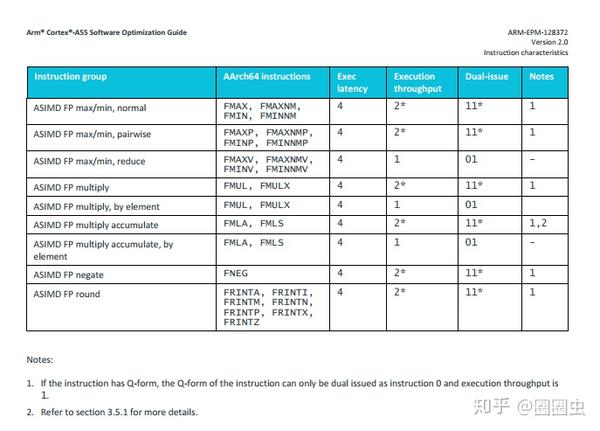
FMLA

SDOT
看来是对的,FMLA与SDOT的Execution Throughput(吞吐率)一样了!
实践
既然这样,那么实际在推理框架中,是否能采用全部FP16计算呢?原则上是可以的,但是为了更好的保证精度,Tengine开源版本在实现时,采用Hybrid-FP16策略,即仅仅在计算核心模块(im2col+sgemm)采用FP16,而从整个网络的计算图外部观察,每个Node的输入/输出Tensor数据类型依然保持原有FP32精度
(图片)Float32 -> Cast -> Float16 -> Sgemm\_FP16 -> Float16 -> Cast -> Float32
当然,有同学就要质疑:这样做还有加速效果吗?答案是肯定的:
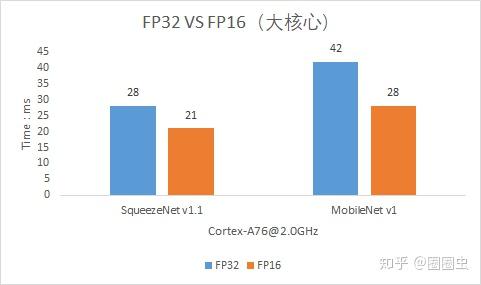
Cortex-A76,有点烫
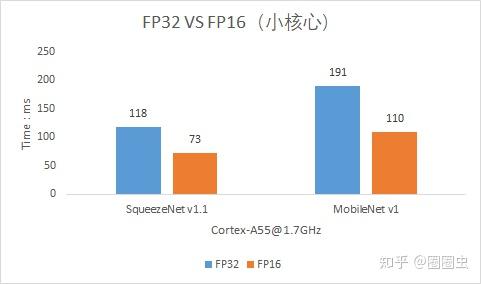
Cortex-A55,业界良心
目前在Tengine的开源版本来看是有可见的加速效果(后续团队会持续更新,尽力榨干硬件的最大剩余价值)
奇怪的操作
其实开源这么久以来,最成功的端侧推理框架莫过于ncnn,然而由于ncnn作者只能采用业余时间来进行框架优化。但是大家就是想用ncnn的模型结构,却想尝试Tengine的速度怎么办呢?(up主:欢迎pr……)
不用担心,毕竟Tengine是一个基于plugin的模块化设计的框架,让我们加入ncnn serializer(ncnn模型适配器)即可。技术细节请参考:
那么我还要,能不能尽可能的少改动原有的ncnn的代码呢?已经使用习惯了呀。

伸手一时爽,一直伸手一直爽!
先来下面来找茬吧,李逵 和 李鬼?

在下李逵(ncnn的API)

在下李鬼(Tengine的API)
在最新的Tengine开源代码中,已经采用“俄罗斯套娃的方式”新增了适配ncnn example的api,尽可能减少代码移植困难。
欢迎Star三连击
到底比ncnn快多少呢?请各位看官自行体验(差不多可以参考上面的FP32与FP16速度对比)
Tengine Github链接:https://github.com/OAID/Tengine,Star+Fork+Watch 三连哦~
预告一下,Tengine-Lite已经完成功能扩充,初版提测(Pass 大于 BUG),相信很快就能和开源社区见面。
相关阅读:
更多Tengine相关技术干货请关注Tengine-AI开发平台专栏 及知乎账号圈圈虫

