YOLOv5 自从问世以来,让多目标检测任务在速度和精度上都达到了非常好的表现效果。所以最近被国内优秀的人工智能产品和解决方案公司[链接]

NVDLA(NVIDIA Deep Learning Accelerator),是英伟达开源的深度学习加速器的软硬件参考方案,通过其模块化架构,NVDLA 具有可扩展性和高度可配置性的特点,实现降低深度学习加速器的设计门槛。让更多行业能够快速的将 AI 加速能力融合进自己的 AI SoC 中。

Tengine 组负责模型转换工具的小伙伴愉快的开始支持 PaddlePadde 2.0 的静态图模型。

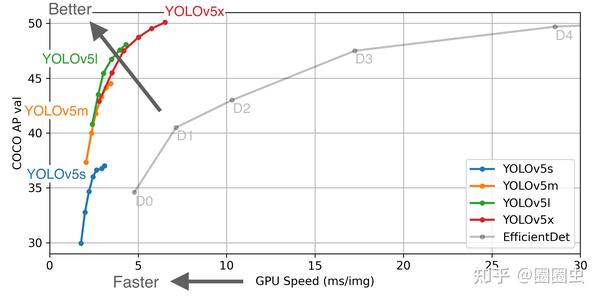
今天我们试着基于 AI 边缘计推理框架 Tengine 在 Khadas VIM3 的 AI 加速器上部署 YOLOv5s。
2020年以来由于特殊的国际环境的影响下,原本在 AI边缘计算占有绝对优势的海思平台Hi35xx系列SoC 最终一货难求,导致国内其他AI SoC平台如同雨后春笋般激增。无论是真正的自主研发,还是套壳NVDLA,或直接购买已有NPU IP,只要能解决行业刚需问题,就是一颗优秀的AI SoC。本文主要介绍国内优秀的NPU IP供应商最新开源的T...
2020年以来由于特殊的国际环境的影响下,原本在 AI边缘计算 占有绝对优势的海思平台 Hi35xx 系列 SoC 最终一货难求,导致国内其他 AI SoC 平台如同雨后春笋般激增。无论是真正的自主研发,还是套壳NVDLA,或直接购买已有 NPU IP,只要能解决行业刚需问题,就是一颗优秀的 AI SoC。本文主要介绍国内优秀的 NPU IP 供应商—...
背景2020年风云变幻,原本以为嵌入式端侧 AI 芯片“大菊已定”。但国内最大智能电视芯片厂商——晶晨半导体(Amlogic)却在从2019年开始,陆陆续续(悄悄咪咪)发布了S905D3,A311D,C308X 等几款能覆盖边缘计算盒子、智能IPC应用场景的 AI SoC。参数对比先简单介绍下当前国内可满足采用 NPU方案的 IPC 或 边缘计算盒子,市...

点击上方“AIWalker”,选择加“星标” 精品干货,瞬时送达标题&作者团队paper:[链接]【Happy导语】该文提出了一种轻量型任意尺度超分方案,它将任意尺度数据制作思路引入到OSM设计中。作者通过实验证实了所提OSM的有效性,性能比MetaSR更高,速度更快。那么你还有什么理由不去了解一下呢?AbstractDCNN在超分领域取得了...
点击上方“AIWalker”,选择加“星标” 精品干货,瞬时送达标题&作者团队paper:[链接]【Happy导语】该文提出了一种轻量型任意尺度超分方案,它将任意尺度数据制作思路引入到OSM设计中。作者通过实验证实了所提OSM的有效性,性能比MetaSR更高,速度更快。那么你还有什么理由不去了解一下呢?AbstractDCNN在超分领域取得了...
各种机缘巧合来到深圳,抓住人工智能火箭尾巴,挂着 嵌入式Linux驱动工程师 的羊头,卖起了 NNIE 的狗肉。当初团队的理想很丰满:借 Hi3559AV100 神器,造超一流 AI Camera。事与愿违,PoC版本不到一周,项目却光速下马……后来转战 arm neon 优化圈子,成为一名 土法 HPCer + 野生调优师。


订阅极术公开课,即时获取最新技术公开课信息

Arm相关的技术博客,提供最新Arm技术干货,欢迎关注
炼丹师在转换模型的时候,经常会发现给转换前后的模型输入同样的图片,模型结果有微小的差别。其中的原因有数值算法的误差、不同 jpeg 解码库产生的结果不同等等,也有不同框架内部对某些算子的实现差异。

前阵子看到Tengine为OpenCV4.3版本贡献了ARM CPU底层汇编代码,加速深度学习计算。最近也看到Tengine的不少同学在做相关PR。可能有小伙伴不了解Tengine。根据ARM官网也有介绍Tengine,其介绍如下。Tengine 是OPEN AI LAB 针对前端智能设备开发的软件开发包,核心部分是一个轻量级,模块化,高性能的AI 推断引擎,并支持...

2019年已经过半,今年人工智能-计算机视觉方向在边缘计算、移动终端、嵌入式终端的产品落地进入白热化阶段。终端落地的很大一个指标依旧是Inference Time,网络模型压缩的需求越来越大,其中网络模型量化(低比特量化)开始大规模在终端设备上部署并取得了较好的市场认可,同时上游芯片设计公司依次推出了针对低比特量化...
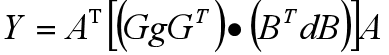
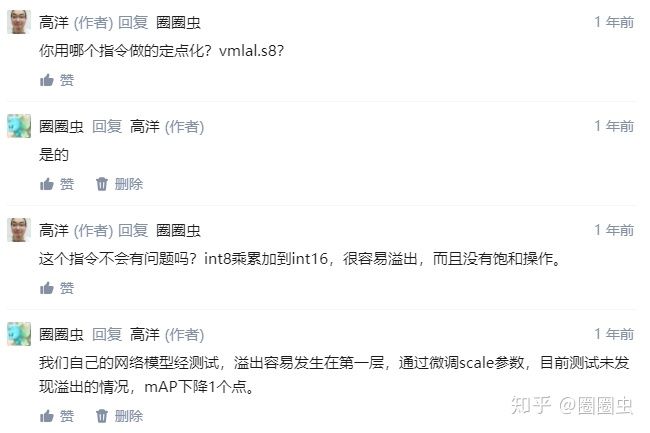
本文是对NCNN社区int8模块的重构开发,再也不用担心溢出问题了,速度也还行。作者:圈圈虫首发知乎传送门ncnnBUG1989/caffe-int8-convert-tools从去年8月初首次向社区提交armv7a版本的int8功能模块到现在过去半年了,中途经过N次迭代。原本以为提交后就可以去别处摸鱼打望,谁知已掉进不断自己挖坑填坑的过程。中间多次...
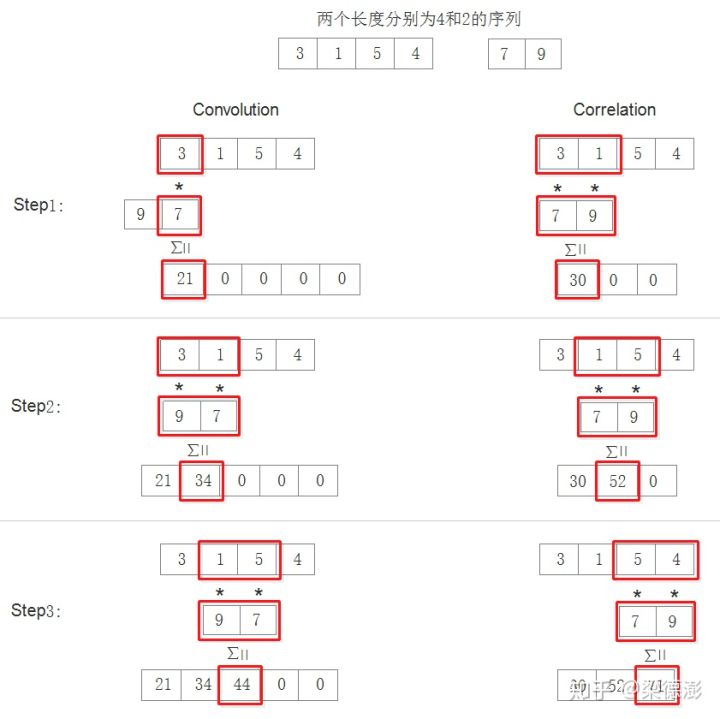
本文想把有关Winograd这个算法背后所涉及到的数学知识用比较通俗的方式给读者描述一遍,并且在这的过程中也会添加一些我个人的理解。作者:梁德澎首发知乎:[链接]

嵌入式端AI,包括AI算法在推理框架Tengine,MNN,NCNN,PaddlePaddle及相关芯片上的实现。欢迎加入微信交流群,微信号:aijishu20(备注:嵌入式)
语音交互技术的发展,给我们的生活带来了很大的改变,智能音箱就是其典型的应用产品,比如现在常见的小爱、小度、天猫精灵等智能音箱。我们通过与智能音箱对话,就可以实现听歌、听书、听新闻等等功能。

OpenCV 4.x中提供了强大的统一向量指令(universal intrinsics),使用这些指令可以方便地为算法提速。所有的计算密集型任务皆可使用这套指令加速,非计算机视觉算法也可。目前OpenCV的代码加速实现基本上都基于这套指令。



