
原载于博客。采用知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可授权,转载请注明出处。
引言
QNNPACK (Quantized Neural Networks PACKage) 是 Marat Dukhan (Facebook) 开发的专门用于量化神经网络计算的加速库。其卓越的性能表现一经开源就击败了几乎全部已公开的加速算法,甚至直至今日(2019 年中)。
QNNPACK 开源时附带了一份技术博客简要介绍了其主要的实现技巧,最近开发者又发表了论文介绍其中卷积的优化方法。然两份文献过于概略,而具体代码又比较晦涩,不方便理解。
笔者在第一时间深入研究了 QNNPACK 的实现方法,并在一个代码 fork 中留下了相关注释。不过注释本身依然不够系统不够直观,笔者一直计划综合阐述一下 QNNPACK 的具体实现,由于时间精力关系一直断断续续至今,终于完成了主体。
本文主要介绍 QNNPACK 中对矩阵乘和卷积的实现。其中矩阵乘内容从通用矩阵乘(GEMM)优化算法相关章节摘取,卷积内容从卷积神经网络优化算法相关章节摘取。如果有兴趣了解相关主题中在 QNNPACK 之外的更综合的信息,也可参考原文。QNNPACK 针对的是量化神经网络,对量化相关问题感兴趣的可以参考神经网络量化简介。同时,阅读本文是也可对照相关的代码注释帮助理解。
本文是从代码逆推相关设计,存在错漏在所难免,还请帮忙指正。注释有部分内容可能有误,也请帮忙指正。
量化神经网络概念
神经网络计算一般都是以单精度浮点(Floating-point 32, FP32)为基础。而网络算法的发展使得神经网络对计算和内存的要求越来越大,以至于移动设备根本无法承受。为了提升计算速度,量化(Quantization)被引入到神经网络中,主流的方法是将神经网络算法中的权重参数和计算都从 FP32 转换为 INT8 。
(1)
两种数值表示方法的方程如上。如果对量化技术的基本原理感兴趣,可以参考神经网络量化简介。
应用量化技术后,计算方面显现了若干个新的问题。首先是 NNPACK 这样用于 FP32 的计算加速库无法用于 INT8 ,这导致我们需要新的加速计算方法。再者是输入输出都转化成 INT8 后,内存带宽需求直接下降为 1/4 。随之而来的内存容量需求变化出现了一些新的优化机会。而 QNNPACK 充分利用了这些优化方法,并结合神经网络领域的特点,大幅改进了计算性能。
矩阵乘优化
本节介绍 QNNPACK 的矩阵乘优化方法,源自通用矩阵乘(GEMM)优化算法中的「神经网络量化中的矩阵乘优化」一节。如果对矩阵乘的其他优化方法感兴趣可以参考原文。
计算划分与削减维度
QNNPACK 的计算也是基于对输出的划分,拆分成如_图一_的 × 小块。这里需要注意的一点是,原文图例中对 的标记有笔误, 的列高度应该是 而非 。(我们向 QNNPACK 报告了这一问题,目前尚未得到修正。)
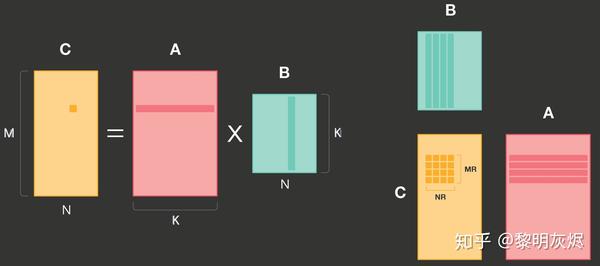
图一:QNNPACK 矩阵乘划分示例
QNNPACK 实现了 4×8 的和 8×8 两种计算核(micro kernel),分别用于支持 armv7 和 arm64 指令集的处理器。这两种计算核在原理上区别不大,后者主要利用了更多的寄存器和双发射(Dual Issue)以提高计算的并行度。
拆分后 × 计算块使用的内存为 ∗ + ∗ + ∗ 。由于常规的神经网络计算 <1024 , 那么这里的内存消耗一般不超过 16KB,可以容纳在一级高速缓存(L1 Cache)中。QNNPACK 的这一发现是其矩阵乘优化的基础。
如_图二_所示,在计算 × 小块时,传统的方法(即上一节的方法)是在 维度上拆分,在一次计算核的处理中,仅计算 K 维的局部。那么在每次计算核的处理中,都会发生对输出的加载和存储——要将本次计算产生的部分和累加到输出中。
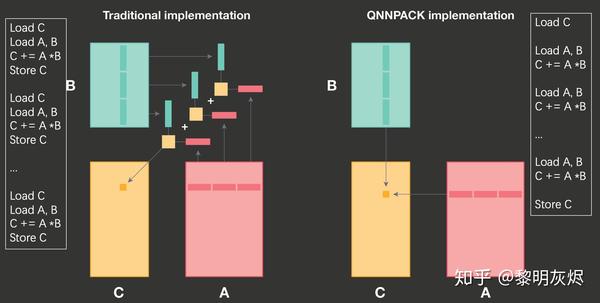
图二:QNNPACK 和传统方法计算削减维度的对比
而 QNNPACK 的做法是将整个 维全部在计算核中处理完,这样就几乎完全消除了输出部分和的访存。两种的差异的细节可以参考图二两侧的伪代码。这里所说的「将整个 维全部」并不是指 维不拆分——在实际计算中 维还是会以 8 为基础拆分——而是指拆分后不和其他维度交换(interchange)。
内存组织的特点
上节中曾提到,对内存的重新组织(Repacking)可以改进高速缓存命中率,从而提高性能。但是这种重新组织也是有开销的。
计算核中最小的计算单元处理的是两个 4×4 矩阵相乘。传统的方法由于 可能很大,需要对输入内存进行重新组织,防止相邻的访存引起高速缓存冲突,如_图三_。
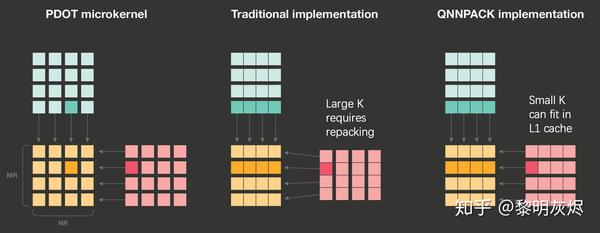
图三:QNNPACK 和传统矩阵乘对局部计算的处理
而在量化神经网络中,由于 比较小,计算核处理中使用到的内存完全可以容纳在一级高速缓存中,即使不重新组织内存,高速缓存的重用率也足够高。
参考_图三_左侧部分,QNNPACK 计算核一次会使用 8 行输入(假定图中绘制以 8 为基础分块)。尽管对第一个 8×8 矩阵块的向量化加载可能全部是高速缓存缺失(Cache miss),第二个 8×8 则全部命中——因为它们已经作为同在一个高速缓存行的内容随第一个矩阵块加载到了高速缓存中。其他矩阵块也是类似情况。
采用了这些基于神经网络领域先验知识的优化方法后,QNNPACK 击败了所有神经网络量化领域的用于移动端加速库。
卷积优化
本节介绍 QNNPACK 中的卷积方法,摘自卷积神经网络优化算法的「间接卷积优化算法」一节。如果对卷积的其他优化方法感兴趣可以参考原文。QNNPACK 作者近期发表了相关的文章来介绍其中的主要思想,亦可交叉参考。
计算工作流
间接卷积算法的有效工作以来一个关键的前提——网络连续运行时,输入张量的内存地址保持不变。这一特性其实比较容易满足,即使地址真的需要变化,也可以将其拷贝到固定的内存区域中。
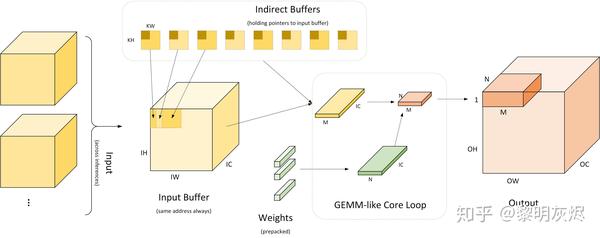
图四:间接卷积算法工作流
_图四_是间接卷积算法工作流的详细过程。最左侧部分表示多个输入使用相同的输入缓冲区(Input Buffer)。间接卷积算法会在该输入缓冲区基础上构建如_图五_的「间接缓冲区」(Indirect Buffer),而间接缓冲区是间接卷积算法的核心。如图中右侧,在网络运行时,每次计算出 × 规模的输出,其中 为将 × 视作一维后的向量化规模。一般 × 为 4×4、8×8 或 4×8 。在计算 × 规模大小的输出时,经由间接缓冲区取出对应使用的输入,并取出权重,计算出结果。计算过程等价于计算 × 和 × 矩阵乘。
在实现中,软件的执行过程分为两部分:
- 准备阶段:加载模型,配置输入缓冲区;重排权重,使其内存布局适用于后续计算;
- 运行阶段:对于每个输入,运行 ⌈ ∗ / ⌉∗⌈ / ⌉ 次核心循环,每次使用 GEMM 方法计算出 × 大小的输出。
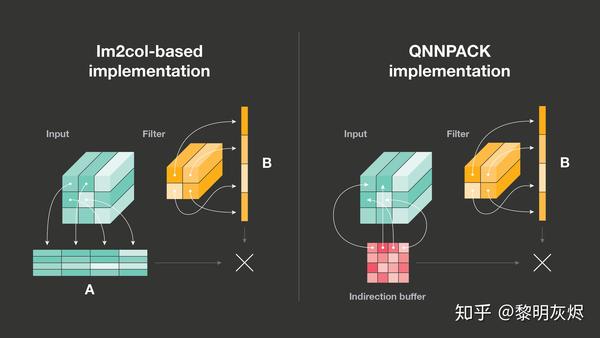
图五:间接缓冲区
如相关章节的讨论,Im2col 优化算法存在两个问题,第一是占用大量的额外内存,第二是需要对输入进行额外的数据拷贝。这两点如何才能解决呢?间接卷积算法给出的答案是间接缓冲区(Indirect Buffer),如_图五_右半所示。
_图十_是常规的 Im2col 优化算法和间接卷积优化算法的对比。正如相关小节介绍的那样,Im2col 优化算法首先将输入拷贝到一个矩阵中,如_图五_中 Input 的相关箭头,然后执行矩阵乘操作。间接卷积优化算法使用的间接缓冲区中存储的其实是指向输入的指针(这也是间接卷积优化算法要求输入内存地址固定的原因),在运行时根据这些指针即可模拟出类似于 Im2col 的矩阵计算过程。
间接缓冲区布局
间接缓冲区可以理解为是一组卷积核大小的缓冲区,共有 × 个,每个缓冲区大小为 × ——每个缓冲区对应着某个输出要使用的输入的地址。每计算一个空间位置的输出,使用一个间接缓冲区;空间位置相同而通道不同的输出使用相同的间接缓冲区,缓冲区中的每个指针用于索引输入中 个元素。在计算时,随着输出的移动,选用不同的间接缓冲区,即可得到相应的输入地址。无需再根据输出目标的坐标计算要使用的输入的地址,这等同于预先计算地址。
_图六_绘制了当 × 为 4 、 和 均为 3 时,间接缓冲区的实际使用方法与计算过程。图中命名为局部间接缓冲区意指目前考虑的是计算 × 时核心计算的过程。
当计算 × 大小的输出时,使用的输入为卷积核在对应输入位置上滑动 步所覆盖的趋于,即规模 ( )×( +2( −1))× 的输入。在间接卷积算法中,这些输入内存由 个间接缓冲区中的指针索引,共有 × × 个。_图六_中标识出了输入空间位置左上角输入和相应的输入缓冲区的对应关系。可以看到,这里的 A、B、C、D 四个输入缓冲区,相邻的两个缓冲区所指向的地址区域有 ( − )/ ,这里即为 2/3 ,各个缓冲区中指针的坐标也已标明。
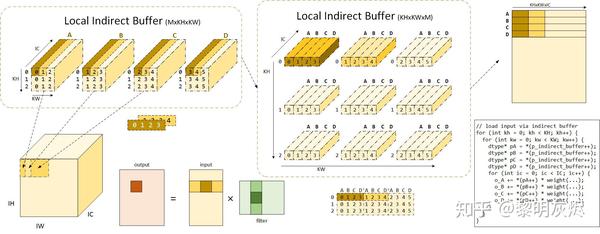
图六:间接缓冲区详解
图中将平面缓冲区绘制成三维形式(增加 IC 维度),意在说明间接缓冲区的每个指针可索引 IC 个输入元素,而每个间接缓冲区索引的内容即为与权重对应的输入内存区域。
进一步地,左上角的输入缓冲区排列方式并不是最终的排布方法,实际上这些指针会被处理成_图六_中部间接缓冲区的形式。将左上每个缓冲区中的指针打散,即可得到 × 指针,将 A、B、C、D 四个缓冲区的不同空间位置的指针收集到一起,即可得到图中上部分的缓冲区排列方式 × × 。可以看到, A、B、C、D 四个缓冲区内部相同空间位置的指针被组织到了一起。图中中上部分是可视化的效果,中下部分则是间接缓冲区的真正组织方式。图中褐色和深黄色的着色对应着相同的输入内存或指针。值得注意的是,图例中 Stride 为 1,当 Stride 不为 1 时,重新组织后 A、B、C、D 相同空间的坐标(对应于在输入的坐标)不一定是连续的,相邻的空间位置横向坐标相差 大小。
使用间接缓冲区计算
我们已经知道了间接缓冲区的组织形式,以及其指针对应于输入内存的地址趋于,现在来研究在计算过程中如何使用这些缓冲区。
和上一小节一样,本小节的讨论大体都在计算 × 规模的输出,而这些输出要使用 个 × 大小的输入,其中有数据重用。现在回顾一下 Im2col 的算法(如_图六_中下左部分),当向量化运行计算时,对于 × 的矩阵乘计算,每次取出 × 规模的输入和 × 规模的权重,对该块运行矩阵乘即可得到相应的部分和结果。其中 是向量化计算在 维度上的步进因子。
而卷积之所以可以使用 Im2col 优化算法,本质原因在于其拆解后忽略内存复用后的计算过程等价于矩阵乘。而间接缓冲区使得可以通过指针模拟出对输入的访存。在实际运行计算 × 输出的计算核(micro kernel)时,会有 个指针扫描输入。 个指针每次从_图六_中下部分的间接缓冲区结构中取出 个地址,即对应于输入 × 的内存,如图中右上角的布局。在这里的步进中,仍是以 × 形式运行,其中 在 维度上运动。当这部分输入扫描完毕后,这 M 个指针从间接缓冲区中取出相应的指针,继续下一次对 × 输入内存的遍历,每次计算出 1/( ∗ ) 的输出部分和。当这个过程运行 × 次后,即得到了 × 的输出。_图六_右下角的伪代码对应了这一过程。由于间接缓冲区已经被组织成了特定的形状,因此每次更新 个指针时,只需要从间接缓冲区指针(图中伪代码里的 p_indirect_buffer)中获取。
这个过程的逻辑不易理解,这里再做一点补充说明。当上述的 个指针不断运动扫描内存时,实际上是在扫描三维输入 Im2col 之后的矩阵。而输入缓冲区的特定是它将对二维矩阵的扫描转化为了对三维张量的扫描。对输入的扫描过程即是对_图六_中上部分可视化的输入的扫描,联系左上和左下对应的输入关系,不难发现它每次扫描输入中 × 块内存。值得注意的是,这里的 × 由 M 个 1× 张量组成,它们之间 维度的间距为 。
这样一来,只要运行该计算核心 ⌈ ∗ / ⌉∗⌈ / ⌉ 次,即可得到全部输出。
间接卷积优化算法解决了卷积计算的三个问题,第一是空间向量化问题,第二是地址计算复杂问题,第三是内存拷贝问题。一般计算卷积时都需要对输入补零(对于 × 不是 1×1 的情况),这个过程传统的方法都会发生内存拷贝。而间接卷积优化算法中的间接缓冲区可以通过间接指针巧妙地解决这一问题。在构造间接缓冲区时额外创建一块 1× 的内存缓冲区,其中填入零值,对于空间中需要补零的位置,将相应的间接指针指向该缓冲区,那么后续计算时即相当于已经补零。例如_图六_中 A 的左上角对应于输入空间位置 (0,0) 的,当需要补零时该位置一定要为零值,此时只要修改间接缓冲区的地址即可。
参考资料
推荐阅读
更多量化及嵌入式AI相关技术干货,请关注专栏嵌入式AI以及知乎(晴耕雨读— CS w/ hardcore)。

