
原载于博客。采用知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可授权,转载请注明出处。
两年前,当我参与到深度学习软件系统的研发和优化时,一个观念逐渐在我脑海中形成——相关的软硬件系统会逐步收敛成标准,或一两个巨无霸。两年过去了,深度学习生态有了很大的变化。
这篇文章主要分析当下深度学习系统的现状,对一些_热门_话题做一些探讨,简单谈一下对未来趋势的理解。因个人视野的局限性,大家还是将此文当做路边杂谈比较合适~
当下的概况
软件系统
我们主要讨论用于云端(或工作站、主机端)的模型训练系统,和用于移动端的推理引擎,以及深度学习_编译器_这一特别的主题。
模型训练系统
Comparison of deep-learning software 列出了一些主要的深度学习框架的信息。忽略诸如 Intel MKL-DNN 这样的加速库、Keras 这样的封装层、以及 Chainer 这样的小众系统后,(曾)被大规模使用的(开源)软件系统只剩 TensorFlow、PyTorch、Caffe、Theano、MXNet 等五个。
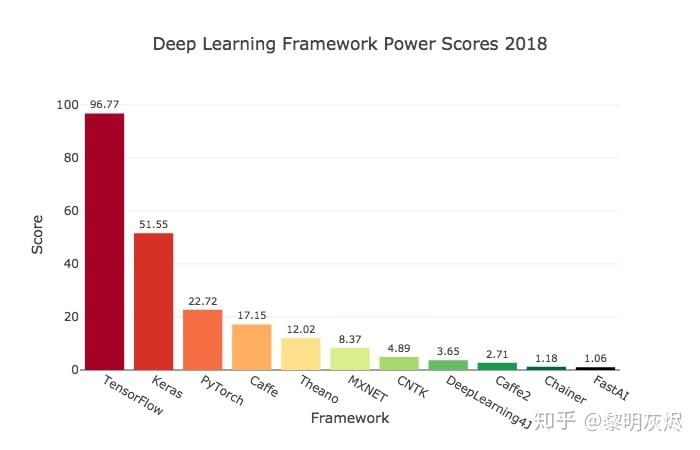
图一:深度学习框架排名
TensorFlow 和 PyTorch 作为当红互联网公司的产品分别引领工业界和学术界自不必说。对于其他三个:
- Caffe 的继任者 Caffe2 因出来得太晚,已经成为了 PyTorch 的一部分。Caffe 用户也大量转向了 PyTorch,这其中说不清有多少所以从 Caffe 转向 Caffe2 再被迫转向 PyTorch。
- Theano 的理念被 TensorFlow 继承后很快就淡出了人们的视野。
- MXNet 出现的时机其实很好,然而缺乏有力的商业公司主推(Amazon 进来得可能太晚了),工程问题一直很大。一两年前或许还可以看到一些文章推广,号称要 TensorFlow、PyTorch、MXNet 三足鼎立,现在除了还在做相关工作的人外,几乎已经没人关注了,基本凉凉。
从 Comparison of deep-learning software 列出的表格中可以看到,自 TensorFlow 和 PyTorch 分别在 2016 年和 2017 年开源后,几乎没有新的软件系统开源或发布。大型深度学习软件的格局已经基本完善,现在只是 TensorFlow 和 PyTorch 双雄之争了。
TensorFlow 的问题是接口变化太频繁,使用成本比较高,个人感觉 TensorFlow 2.0 也未必能解决。尽管如此,目前 TensorFlow 的工程完善度是 PyTorch 还无法企及的。例如 Quantization-aware Training 在 2017 年便已经完工, 几乎成为了量化的事实标准。PyTorch 最近刚刚发布的类似工作则晚了两年。
双雄之争恐怕要持久地进行下去,剩下的工作无非是你来我往,互相学习借鉴,直到深度学习软件系统不再是人们热衷的话题。可以说,在这个时间点,深度学习框架的研究和工作会逐渐变得平淡。就像大家不再争论 Hadoop 和 Spark 了。
移动端推理引擎
自 2012 年伊始的深度学习热潮,到今年已经是是第 8 年了。TensorFlow、PyTorch 系统不断完善,算法应用「落地」的呼声也日益高涨,尤其是在移动端。
而 TensorFlow 和 PyTorch 对移动端来说太重了。于是,轻量级的、专注于预测的「推理引擎」出现了,TensorFlow 的 TFLite 是典型代表。然而,TFLite 属于 TensorFlow 生态,不支持工业界遗留的大量的 Caffe 模型,也不支持 PyTorch 等框架。此外,TFLite 的计算性能也不够强大,在中低端手机上的运行效果堪忧。虽然 Android 和 iOS 分别提出了 Neural Networks API 和 Core ML 尝试改善计算性能,但毕竟需要升级新版本系统,软件适配和更新速度也是个大问题。
由于这些问题,和当初深度学习训练框架一样,新的推理引擎不断出现。下面的表格罗列了几个比较常见的推理引擎的信息(忽略 Arm NN 这类由芯片厂商提供的加速库)。这里的 Multi-Frontend 指支持多种训练框架的模型,_Multi-Backend_ 指支持多种硬件运行环境。
图二:深度学习推理引擎信息

这些推理引擎提供的功能一般包括:
- 多种前端支持,即能够导入多种训练框架的模型文件。
- 大多数都支持模型量化(Quantization)技术,一些系统还能优化模型结构,例如融合 BN。
- 多种后端的支持,虽然一般主打的还是 ARM CPU。
这些功能本身复杂度不高,用的都是比较成熟的技术(类似 Caffe 的架构),同质化严重。可见的差异也就是神经网络算子支持的完善程度,和网络运行的计算性能。又由于算子支持是很简单的工程问题,实质性的差异只有计算性能,这也很可能是决出最后的赢家的关键因素之一。
目前在 ARM 设备侧,QNNPACK 拥有最好的性能,可惜得用 Caffe2 部署才行。其次是 Tengine,但整体生态很差。NCNN 和 MNN 分别是国内两大互联网厂商的产品,在自家平台上久经验证,MNN 则有后发优势。MACE 和 Paddle Mobile/Lite 的用户似乎在收缩,不过自家运营应该不成问题。TensorFlow Lite 目前性能有点落后,是各家产品宣发时爆锤的对象,不过 Marat Dukhan(QNNPACK 作者)加入 Google 后的工作令人期待。(笔者曾和 Marat 有过短暂的交流,其在加入 Google 后依然专注于计算性能优化这一方向。从近期开源的 XNNPACK 看,Marat 将间接卷积算法应用到了浮点系统中。)
随着时间的推移,推理引擎的工作也基本完善,计算性能方面的工作会在一年内逐步填平。当然,各大厂家应该还是会自己维护系统,可控是很重要的。
硬件系统
我们都知道,这一波深度学习的热潮的掀起有赖于硬件算力的提高。也因此,经营计算生态多年的 Nvidia 赚得盆满钵满,股价翻了很多倍(即使剔除挖矿因素)。
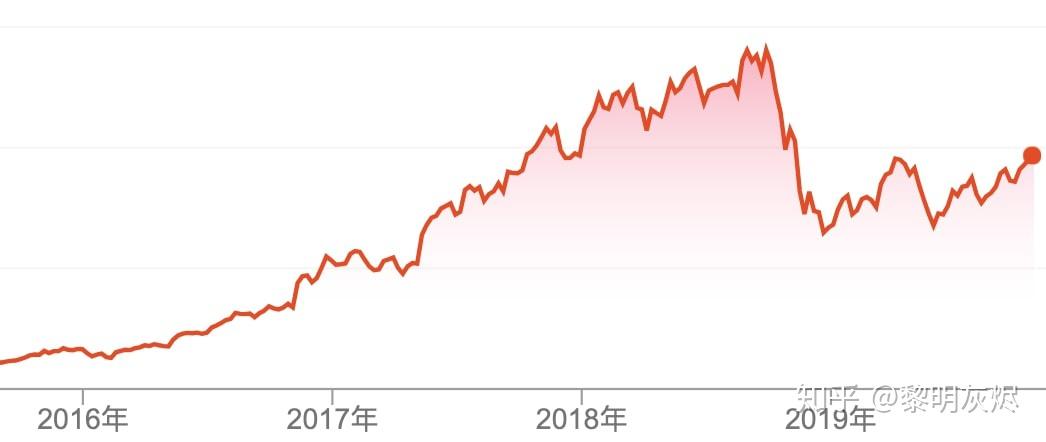
图四:Nvidia 股价
GPU 并不是为深度学习算法专门设计的,而深度学习需要的计算量是如此之大,专用处理器随之涌现。值得自豪的是,在这方面迈出引领脚步的 DianNao 系列工作(后孵化为寒武纪)正来自笔者求学的中国科学院计算技术研究所,笔者也曾在寒武纪服务半年。简单起见,这里将相关的专用加速器统称为 NPU(Neural Processing Unit)——无论相关系统如何命名,主要还是为神经网络设计。
从 2017 年开始,以寒武纪和 Google 为代表优先应用在移动端(麒麟970)和云端(TPU Cloud)部署相关系统。在随后的两年中,苹果、高通、华为等厂商逐步在移动端增加相关功能,移动端的 AI 硬件加速已经得到了广泛的应用。除手机和自动驾驶外,国内特殊的安防市场也涌入了大批拥有软硬件一体加速系统的厂商,如寒武纪、地平线(现在他们已经不说机器人了)等。
云端没看到有 Nvidia GPU 和 Google TPU 之外的大规模商业产品,但各家针对云端的产品发布会让人应接不暇,到现在笔者也没弄清楚华为和阿里的 NPU 谁是「第一」。有兴趣的话可以参考 WikiChip 的这份列表。奇特的是,除了 NVDLA 这一尝试外,领域霸主 Nvidia 目前并没有真正推出 NPU 产品。据 Nvidia 某位总监介绍,深度学习在公司营收的占比并不高,反而很好奇为何有如此之多的公司对 NPU 趋之若鹜。
除了 GPU 和 NPU 外,还有一些工作基于 FPGA 在做。事实上,基于 FPGA 的各种加速器层出不穷,例如微软的 Project Catapult、Intel 在大数据领域的尝试。作为一个行业菜鸟,笔者从来不认为 FPGA 是用于大规模计算的好设备。和其他的芯片相比,FPGA 的优势只有一个,那就是灵活性。这种灵活性在前期探索芯片架构时很有用,但当计算负载变得明确时,FPGA 在性能和功耗方面远不是专用芯片的对手—— FPGA 总是需要比专用芯片更多的电路来实现同样的功能。
最后,还得提下老东家 Intel 和 CPU。笔者之前所在的 Machine Learning and Translation 团队专注于 Intel 平台的性能优化和体验改善。当下 Intel 正在打造自己的 GPU 和相关的编程系统 Data Parallel C++(对标 CUDA)。CPU 目前有两种状态,云端因为 GPU 的存在几乎和深度学习加速无关;移动端则由于加速硬件尚未形成规模,成为了计算推理的主力。
深度学习_编译器_
除了上一小节提到的推理引擎,在过去的这一两年中,深度学习软件生态中经常被提及的一个关键词便是「深度学习_编译器_」。类似地,我们也给出一个小小的表格来罗列一些主要的_编译器_的信息。
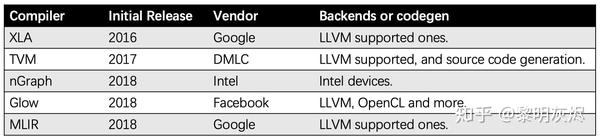
图三:深度学习编译器信息
虽然我们将表中罗列的几种都称为编译器,但它们的差别其实很大。对于目前被研究得比较多的 TVM 和 XLA ,谈谈对深度学习编译技术的一些思考在系统设计层面有很扎实的分析,本文就不多谈了。
然而深度学习_编译器_或者相关的自动优化器不是魔杖,并不能挥一挥就让网络跑得飞起。这些工具的出现降低了网络优化的门槛,能帮助我们快速获得比较好的性能,但更进一步还是要投入大量的工程。
经常会有人提出 _TVM 是在深度学习领域的 LLVM_,笔者对此持保留态度。TVM 的发展比较依赖社区,现在还不好说会不会重演 MXNet 的悲剧。尽管如此,笔者还是看好 TVM 成为一个尝试各种性能优化技巧的良好平台。不过事在人为,以华盛顿大学为核心的 TVM 作者们成立了 OctoML 推动 TVM 的产业化,让我们期待在部署和使用方面的下一步改进。
与竞品相比,MLIR 可能是目标更长远的工作。MLIR 是一套设计 IR 的基础设施,其对计算的表达能力比较增强。TensorFlow 也在尝试用 MLIR 解决不同软件系统中网络拓扑结构转换的问题,而这一点也要比 ONNX 走得更远。当然,这使得系统的复杂性变得很高,也需要更长的时间磨合。
对于目前这些深度学习_编译器_,其中一部分实际上是被当做推理引擎在用,另一部分则需要更长的时间成长。
未来可能的趋势
如上节所述,目前深度学习软硬件系统百家争鸣、百花齐放,但这种情况不会持续太久。「以古为鉴,可知兴替」。回顾中央处理器和图形计算的历史,我们大体能判断这一波深度学习软硬件系统的可能趋势。
硬件系统
硬件系统分为移动端和云端两大部分(这里将所谓的边缘计算纳入移动端,雾计算纳入云端)。我们一般会说芯片是个「赢家通吃」拿走绝大部分利润的行业,例如 Intel 的 CPU 和 Nvidia 的 GPU,因为赢家会迅速获得生态和支撑继续发展的资金。
首先移动端会很快收敛为两股势力,一是 ARM 提供的_公版_ NPU。较弱势的中低端 ARM 芯片厂商为了节约成本基本上会采用 ARM 的方案,特别是 ARM 可能为了获取优势地位赠送 NPU IP。这样可以共享底层的软硬件系统生态,对 ARM 和芯片厂商都是有利的。二是以高通和海思为代表的大芯片厂会自行设计 NPU,毕竟 SoC 的方案掌握在他们手里,其赚取的利润也足以支持在中高端芯片中采用区别于 ARM NPU 的方案,形成差异化竞争。抱歉,这里真的没有太多其他厂商的位置。
云端其实也是类似的情况,一是 Nvidia 这样的 2B(To Business)厂商继续提供 GPU 或 NPU。无意自研 NPU 的云服务商或自建数据中心的企业会采用这样的标准方案。二是以 Google 为代表的云服务商自研 NPU,相关服务以 AI 算法作为接口时可以天然地屏蔽底层硬件差异(虽然不知道其他厂商什么时候能真正商用)。云是个好东西,但它正让 Intel 和 Nvidia 这样的公司远离用户和开发者,变得更像台积电。
这个演变可能需要 5-10 年甚至更长的时间,绝大多数从事相关行业的公司都会在两三年之内死去,而最后的赢家或许还没出现在大家的视野中。
这里再谈一点。寒武纪曾在很长时间内将指令集作为宣发的重点,因为创始团队认为指令集是生态的入口。笔者赞同关注生态的问题,这也是写作本文的原因之一,但笔者并不赞同在深度学习领域谈论指令集。指令集作为生态入口是 CPU 发展的结果,与龙芯同根同源的寒武纪执迷于指令集也不意外。而 GPU 之争已经不再硬件指令,而是编程系统——开发者编程使用的界面在整个软件栈中_上移_了。这一点在 NPU 时代会进一步发展,开发者使用的编程接口是 TensorFlow 这样的框架,而不是 CUDA、OpenCL,更不是机器指令集。一言以蔽之,NPU 指令集对生态的影响不大,不要刻舟求剑。
软件系统
随着领域发展逐渐成熟,硬件系统逐步定型,相关的软件标准也会一步步得到明确。中央 Khronos 的 NNEF(Neural Network Exchange Format)和 Facebook 的 ONNX(Open Neural Network Exchange)就是早期的尝试(虽然很原始)。除了深度学习或神经网络的专用标准外,从一些音视频实验室的人员需求来看,音视频领域似乎也在尝试将深度学习技术吸纳到相关的标准体系中。
相比起硬件,软件的变化灵活很多,很难说最后会演变成什么形态。即使图形这种已经发展了几十年的技术,行业还是提出了 Vulkan 。或许深度学习软件系统后续的发展会更像图形技术那样标准化,而非大数据和云计算那样由开源基金会控制。又或者会根据不同的领域有不同的演化方向。

图五:Android _Neural Networks API _架构
理想中的终极场景大体上会像 Android Neural Networks API 那样,在操作系统中形成两层抽象:底层是系统和驱动对接的接口、上层是应用和系统对接的接口。当然,具体两层接口的抽象形态值得探讨。在这种场景下,NPU 厂商无需再将自己的加速库集成到各种框架或引擎中,引擎开发者不必费尽心思为 CPU、GPU、DSP 等开发计算核,应用开发者也无需为不同的引擎框架适配头疼。
基于这样的假设,移动端的推理引擎市场会迅速收敛。不过大厂依然会「有钱任性」自建生态,毕竟淘宝的 Android 应用连 Java 虚拟机都是自带的,更不用说这两年兴起的小程序热潮。
因为生态碎片化的问题,移动端无论如何绕不开操作系统或 SDK 这一层,趋势会相对明确一些。近年云计算的发展,云端的系统开发已经里操作系统很远了,形成了丰富的多层抽象编程模式。领先的云计算服务商可以提供集丰富多样的计算服务,例如系统集成度更高,在各个层面(从硬件基础设施到最终的应用服务)的封装抽象支持。
至于它们会不会形成一个行业标准,目前还很难说——各云服务商家可能希望用户和自己的平台绑定得更加紧密,从而形成护城河躺着赚钱。当然,会有服务标准化的尝试(这对云服务使用者是有利的),只是最终形态很难判断,笔者也缺乏相关直接经验。
深度学习_编译器_
最近恰逢团队在组织 TVM Meetup 2019 Shanghai 的活动,趋势这边也想谈一下深度学习_编译器_这个话题。
深度学习_编译器_开发团体对自身工作价值的表述通常包含两方面:一是方便用户部署,二是自动优化性能。
第一点的方便部署其实是伪命题,因为任何一个推理引擎都可以做到这一点,而且做得更好。在本文的设想中,模型部署这一当下有时候会造成麻烦的问题,会在整个生态完善后,变得像写 Hello World 那样轻而易举——我是指像用 Python 那样。
至于第二点,计算性能好往往需要足够的信息,一方面是模型的,另一方面是硬件信息,同时拥有这两点信息的是系统偏底层的部分。结合各类虚拟机,各类尝试抽象计算的系统设计,这样的编译功能应当可以放置到驱动中去。在底层抽象中,或许不一定是像 Android NNAPI 这样的表示,而是类程序语义的表示——表达能力更强,计算粒度更小的表示。
从用户价值来看,一个好的生态是不应当让用户考虑「编译」这种过程的,因为它干扰了用户尝试新想法的流程,这在深度学习环境中显得尤为重要——用户执行的是算法,而不是程序。基于这个逻辑,XLA 在易用性方面是优于 TVM 的。当然,系统总是可以持续更新迭代的,低端设备用 AOT ,其他用 JIT 或许是一个可期的状态,且对用户透明。
概念是会变的,现在声称自己是深度学习_编译器_系统未必一直都会是编译器。例如 TVM 的演化方向实际上是推理加速引擎,诸多用户也是将其作为 TFLite 的替代品。
总之,长期看来,软件硬件系统都会逐步收敛,留给新生系统的机会不多了。
多说两句
回顾过去几十年计算机产业的发展史,总体而言是一步一步变得_开放_,早期封闭的 IBM 和 HP 已经逐渐淡出了人们的视野。当然,这里说的_开放_是指对行业标准的开放,对开源社区的开放。
过去几年,以 BAT 为代表的我国第二代互联网企业成长为巨无霸,开源开放也日益显得重要。然而各个互联网巨头企业都致力于打造属于自己的封闭商业王国,各家彼此不信任,部分企业执迷于宣发自己为「世界第一」。实在很难相信能联合起来发起行业技术标准,恐怕深度学习最后还是要受制于人。幸运的是国内市场够大,养活多个巨头应该不成问题。
笔者有这些感慨主要因为自身在软件兼容系统方面的一些体会,但笔者并不是反对「自主可控」。真正的自主可控不是为了商业制衡另起一套山头,而是结合实际的应用和需求发展出自己的体系,能一步一步迭代演进,进而在某个领域引领潮流。如果这是一个造轮子的过程,重要的是业务要求演化出自己造轮子的体系,而非为了造轮子而造轮子。
然则,阶段引领者未必能笑到最后,MIPS、DEC 今天在哪儿?在此立一个 Flag,今后十年,让我们每年这个时候都看下深度学习软硬件系统的情况。
深度学习软硬件系统的明天有没有当今这些当红炸子鸡,让我们拭目以待。
推荐阅读
更多量化及嵌入式AI相关技术干货,请关注专栏嵌入式AI以及知乎(晴耕雨读— CS w/ hardcore)。

