
把手机芯片的架子搭好后,需要看看怎么加入多媒体部分。
作者:djygrdzh
来源:https://zhuanlan.zhihu.com/p/32370404
所谓多媒体,包含三个模块:图形处理器(GPU),显示模块(Display),视频模块(Video)。显示模块负责把所有的内容输出到屏幕,视频模块负责解码片源,也负责编码摄像头的录制内容。图像信号处理(ISP)模块暂时不算在内,以后另说。
GPU是大家喜闻乐见,津津乐道的部分,各种跑分评测都会把GPU性能重点考量。但是实际上,在定义一个手机芯片多媒体规格的时候,我们首先要确定的参数,不是GPU有多强大,而是显示输出的分辨率:是720p,1080p,2K还是更高。这个参数,决定了GPU填充率(fill rate)的下限,系统带宽大小,内存控制器的数量,还会影响CPU和ISP的选择,从而决定整体功耗及成本。所以,这一参数至关重要。
举几个典型的例子:
超低端:展讯的SC9832,显示分辨率720p,ARM Cortex-A7MP4,Mali400MP2, 1xLPDDR3
低端:联发科的MT6739,显示分辨率1444x720,ARM Cortex-A53MP4@1.5GHz,IMG PowerVR GE8100,1xLPDDR3
中端:高通的骁龙652,显示分辨率2560x1600,Cortex A72MP4/Cortex A53MP4,Adreno 510,2xLPDDR3
高端:海思的麒麟970,显示分辨率不高于2K,Cortex A73MP4/Cortex A53MP4,G72MP12,4xLPDDR4
我们可以看到,随着显示分辨率上升,芯片规格越来越高,但到2K就停止了。下面通过定量分析,让我们看看其中每个参数背后的考量。
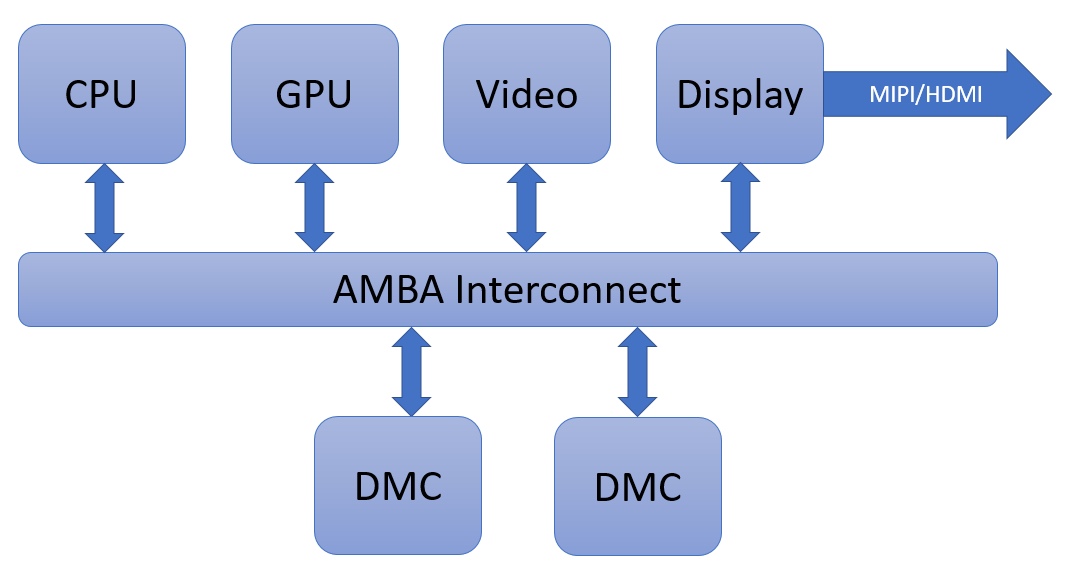
如上图所示,手机多媒体一定包含图形,视频和显示三个模块。为什么桌面图形处理器囊括了视频和显示输出,而手机要把它们分开?再极端一点,其实所有的多媒体和图像处理都是计算,为什么不全用CPU做了?把省下来的面积全做成CPU,岂不更好?不好意思,这不可行。原因很简单,功耗。请记住,由于没有风扇,手机芯片无论怎么设计,在各种长时间运行场景下,功耗一定得低于2.5瓦,短时间运行也不宜超过5瓦,瞬时运行倒是可以更高。这个2.5瓦,除了跑多媒体,还得包括CPU,总线和内存带宽。而多媒体的每个模块,在做其擅长的事情时,功耗远低于CPU。16nm上视频编解码器在处理4K30FPS帧的功耗在60毫瓦左右,而相同的事情让CPU做,我粗略的估计了下,至少得四个跑在2Ghz的A53,还得是NEON指令(功耗为Dhrystonex2.5),那就是1.5瓦以上的功耗。相差25倍。
再看显示模块的功耗,分辨率2K60帧下,16nm工艺需要50毫瓦左右。而用GPU做相同的事情,粗略的算,需要300毫瓦左右。用CPU还要乘以2到3,近1瓦。
所以,只是放个4K的视频并输出到屏幕,就已经到了功耗上限了,还没有计算访存功耗呢,更不用说支持10小时以上的视频播放。所以,手机多媒体必须把GPU,视频和显示模块分化出来。
当然,如果手机非常低端,一定要用CPU来进行软件解码,从而省了硬件面积,也不是完全不可行。因为超低端可能只要支持1080p视频就可以了,并且由于CPU数量小还是小核,功耗虽然高些但也不是完全不能接受。同时,低端的手机CPU本身处理能力弱,软件优化和多核负载均衡一定要做好。而中高端手机不会为了省面积这么做的。
看到这可能有人会问,为什么视频是4K的,而显示只有2K呢?分辨率不匹配,多出来的像素不是浪费么?确实如此。不过由于受到手机屏的限制,目前就算高端手机也还没支持4K。并且屏幕分辨率提高一倍,功耗也提高一倍。这对于本就是耗电大户的屏幕来说,是个大问题,要解决就等着以后更低功耗的屏幕出现了。
反过来,为什么不把视频解码降到2K呢?那是因为视频源的格式是片源决定的,4K的片源没法用2K的解码器去解,只能解完再降分辨率。
还有一个问题,为什么上文中视频是30帧,而显示是60帧呢?我曾经做过实验,特意把屏幕刷新率改成30,结果完全没发现什么不同。但是,据说大部分人的眼神比较好,动态视觉强,对于非自然图像很敏感,所以对于手机背景等图像,一定要做到60帧才能感到流畅。而对于自然图像,比如看视频,30帧就感到流畅了。所以,这两类刷新率就约定成俗了。
下面,我们来看下,屏幕分辨率是如何影响GPU,系统带宽以及内存控制器的。
显示模块的任务和操作系统的用户界面(UI)中图层的概念有关系。我们看到的最终屏幕画面就是多层图层合成叠加的。同时,显示模块还可以对每一层进行旋转,缩放等操作,最终生成一幅图,转成所需的信号格式输出。显示模块的输入可以是解码后的视频,也可以是GPU丢过来的完成初步合成的图层。上图中,显示模块支持3路输入,外加背景图输入,我们一般关注前者。
以安卓为例,用到的图层一般在4-8层。假设显示是1080p60fps,那每一层的带宽就是1920x1080x60x4(RGBA)=480MB/s,8层就是4GB/s。这是系统给显示模块的输入,总线上还得有输出。假设这时候再播放4K30fps视频,所需带宽未压缩是1.2Gx1.25=1.5GB/s。
而GPU跑用户界面时的典型带宽开销,根据UI的复杂度不同,每60帧需要的带宽可达到1GB/s(压缩后),没压缩时在1.5-2GB/s。其他的还有CPU跑驱动,APP等开销,加一起算1GB/s的话,总共9GB/s左右。
单通道的LPDDR4带宽大致在12.8GB/s,如果带宽利用率70%,那差不多正好用满一个DDR控制器,此时每GB带宽消耗在DDR PHY的功耗是100毫瓦(16nm),加上总线和DDR控制器的功耗,总共需要1瓦左右。
这里我们可以算出来,除了CPU/GPU/Video/Display之外,带宽也非常费电,而且增加带宽会较明显的增加内存控制器,DDR PHY和内存颗粒数量,成本上升。相应增加的总线面积和功耗到相对并不大,可以忽略。至于解决由此带来的复杂度,那是设计SoC的基本功,架构篇提过,这里不再重复。
至此,我们已经可以看到如何由显示分辨率反推对于系统带宽,功耗和成本的需求。而GPU的最小需求也可以由此推导出来。
定义GPU有三个重要参数,三角形输出率,像素填充率和理论浮点性能。对用户界面来说,意义最大的是像素填充率。
填充率有什么意义?对于上文提到过的每层图层,如果分辨率是1080p,那就需要1920x1080x60=120M/s的像素填充率。如果8个图层全部由GPU画出,那么就需要1G/s的填充率,对应上图的MP2。这还不止。还记得显示模块里面的合成,缩放和旋转功能吗?这些其实GPU也能做。如果显示模块能力不够,只支持4路输入,那我们就需要GPU把8层图层先合并为4层,然后才能交给显示模块。每两层合成相当于重画一层,于是又额外的需要4层,共1440M/s的像素。如果还涉及缩放和旋转,那还需要更多。通常来说,显示模块不会支持到8层,因为这样的场景并不多,会造成硬件冗余。而极端场景下,GPU就被用来完成额外工作,增加灵活性,又能防止屏幕因图层过多造成的卡顿。
当然,由于系统延迟和带宽的存在,像素利用率不可能达到100%.之前的几年,我看到的有些系统只能做到70%的利用率,主要原因是平均延迟太长,而并行度不够大.这时候,简单的增加GPU核心数量并不是一个明智选择,并且如果瓶颈是在系统带宽不够,或者系统调度没做好,即使增加像素输出率也无济于事。近两年的手机芯片基本上可以做到90%的利用率.但是,就算是低端手机,还是会留出更多的填充能力,来应付多图层下复杂操作的突发情况.此时,提高利用率的意义就成了减小功耗.
此外,在很多移动GPU上,像素填充率还意味着同等的材质填充率。因为用户界面基本都是拿图片或者材质来贴图然后混合,不需要大量计算三维图形,三角形输出和浮点能力用处不大,但是材质填充率必须匹配。
按照上文的功耗和面积,下面我们来看两个极端的例子:
支持VR的芯片,显示分辨率4K120fps(双眼),在虚拟房间内播放4k视频,显示模块支持8路输入,那么就可能需要4x1080x1920x120x7=6.4G/s的像素填充率,外加一路4k视频解码。换成GPU就是至少G72MP8,而考虑3D性能,MP16都是不够的。仅仅GPU部分的面积就要几十平方毫米,功耗5瓦以上,系统不加风扇没法跑。
低端的芯片,仅支持1080p,4k30帧播放视频,4层场景,一个GPU核就能搞定,面积2平方毫米,功耗0.5瓦不到。加上视频和显示模块也不会超过5个平方毫米,功耗之前我们也算过,较低。
这里还没有考虑GPU驱动对CPU的需求。满负载的话,G72MP12就需要一个A73跑满2.5Ghz且很难均衡负载(OpenGL ES的限制),而低端芯片只需一个A53就轻松完成。这里面大核小核,4核8核又造成了非常大的面积和功耗区别。
所以,提升显示分辨率绝不仅仅是图像细致一些这么简单,提升一倍的话,系统成本和功耗基本也会上一大截。简单来说,显示分辨率决定了一个芯片的下限。
把GPU在系统中的基本角色介绍完,下面从设计GPU的角度来分析。
想要做好一款GPU,先要分析市场。GPU市场主要有四大块:桌面和游戏机(3亿颗以下),手机和平板(20亿颗以下,其中近15亿颗被高通和苹果占住),电视和机顶盒(2亿颗以下),汽车面板和自动驾驶(小于1亿颗)。其中桌面和游戏机,自动驾驶暂不考虑,其他几类需求如下:
手机和平板:显示分辨率1080p到2K,4-8层图层,3D性能从弱到强,功耗2.5瓦,成本敏感。
电视和机顶盒:显示分辨率1080p到8K,8层图层,3D性能弱,功耗2.5瓦,成本敏感,需要画质增强。
汽车面板:显示分辨率1080p到2K,4层图层,3D性能弱,功耗2.5瓦,成本较敏感,不太需要汽车安全设计。
由于Vulkan成为安卓的下一代图形接口,固定图形流水线设计必将退出舞台,通用图形处理器,也就是所谓的GPGPU,成为必然趋势。
分辨率的变化可以提炼为可配置多核设计,UI和游戏的不同需求可提炼为大小核的设计。这里,大小核代表着同样填充率下不同的计算能力。两者结合,以期达到最高能效比和面积比。说到大小核,自然就衍生出一个问题,有没有必要像CPU那样在一个芯片内集成GPU的大小核?答案是否定的。CPU大小核之所以有用,是因为能效比会有4到5倍的差别,以及单线程性能的硬需求。而一个好的GPU设计,大小核无论跑UI还是图形,由于存在天然的多线程属性,同样的性能所消耗的能量应该是一致的。大小核面积会有差别,但是即使某段时间只用UI,不用计算能力,也得把计算能力放在芯片里,所以小核的意义就不大了,除非就是以UI为主要应用场景的GPU,不追求3D性能。
渲染方式上,目前主要有即时渲染和块渲染,这个话题已经有些年头了。前者是按照图元为基准,渲染相关顶点,几何,像素,然后合成输出。后者是以像素为基准,选取相关顶点和三角形,计算覆盖关系,最终合成输出。初一看,块渲染似乎更经济,因为它可以计算像素覆盖关系,避免重复渲染。但是反过来,块渲染时所需的三角形,顶点,属性和Varying信息,都是需要从内存读取的。如果存在大量的三角形,就需要多次重复读取,很可能省掉的带宽还不如用即时渲染。所以,决定哪个方式更优,关键在于顶点和像素的比例。就目前手机上的应用看来,像素远大于三角形或者顶点数量,这个比例大致在50:1到30:1。这时,用块渲染就更适合嵌入式设备。
从计算密度看,即时渲染的GPU面积一定小于块渲染的GPU,但是增加了带宽,变相增加了手机成本。至于增加的功耗,未必会比块渲染方式多。所以定性的讨论还是不够的,需要经过定量计算才能确定。
有个例子:某即时渲染的GPU A和块渲染的GPU B,填充率和曼哈顿3.0跑分比例一致,两个GPU都相差5.5倍。GPU A功耗低了30%,面积只有一半,但是带宽却是3.4倍。
这3倍多的带宽,几乎占了1.5个DDR4通道,并一下子带来了2瓦的功耗(28纳米),之前的GPU自身功耗优势当然无存,哪怕面积小一半也无济于事。
反过来,如果按照GPU B的绝对性能,那GPU A其实只需要2.3GB/s的带宽,虽然很大,却远不到一个DDR4通道最大带宽,同时功耗也很低,达不到2.5瓦的功耗上限,还能省一半面积,何乐而不为呢?
由此可以得出结论,低端手机完全可以用即时渲染的GPU,而中高端上还是得使用块渲染的GPU。随着工艺进步,即时渲染的GPU适用范围会更广。这应该出乎很多人的意料。
关于带宽还有一点,和CPU的延迟敏感不同,GPU是靠增加并行度来提高效率的。CPU的预取机制,虽然缩短了延迟,但是增加了带宽和功耗,对与带宽吃紧的GPU来说并不合适。所以GPU的缓存并不适合预取机制。
接着我们来看看图形渲染的流程:
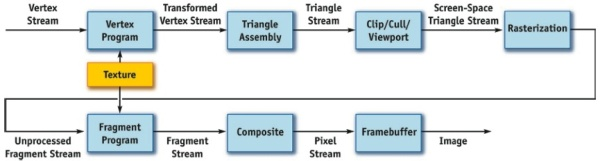
每一步的过程不具体解释,我们关心的是哪些可以用通用计算单元做,哪些还是要固化为硬件做,这和性能面积功耗强相关。我们把上图流水对应到GPU上,如下图:

其中,顶点和像素的处理,计算量相对大,算法相对变化大,可以用通用的着色器,也就是上图中的执行单元Execution Engine。
曲面细分模块Tessellation,由于并不是必须的,在Mali的Norr中,并没有对应的硬件模块,可以用软件使用着色器通用处理单元来做。
深度和模板的测试以及合成,这些都属于像素的后处理,可以用专用硬件直接做,因为操作简单,计算量也和像素线性相关。
材质需要一个额外的单元来做,因为材质有许多专用的操作,而且每个像素点的输出都需要材质单元参与,输出线性相关。此外材质访存带宽也很大,所以拥有自己的访存单元,不占用着色器的存取单元。
在顶点和像素计算中用来传递数据的属性和Varying,需要根据顶点的属性数据,读取数据,插值计算像素的值,提供给像素着色器。计算量和顶点或者像素线性相关,适合固化为硬件单元。
根据图元的顶点位置信息,计算转换后的坐标与法向量,如果在边界之外或者在背面,那就不用输出,直接扔掉,节省带宽。这步就是背面剔除Culling和裁剪Clipping,可以用专用模块配合通用计算单元办到。最后剩下的有效部分,可以用来生成三角形列表,并增加到基于块状像素的队列中去,以便于光栅化。
接下去就是光栅化。这一步中涉及到深度和颜色等的计算,用通用着色器来做。具体做的时候,还需要一个硬件的三角形设置模块,对于某一块像素区域所涉及的三角形,读取上一步中形成的三角形列表,计算三角形每条边所对应方程的参数,以及平面和重心。由于和三角形输出率相关,算法固定,所以也适合固化。
此外,还需要一些额外的单元,来处理系统相关的事务,比如内存子系统,内部总线,以及负责管理任务和线程的模块。其中,任务管理模块又可以在不同层面细分,是一个GPU设计的精华所在。
以Mali为例,在最上层,以图元,顶点和像素为基准,把所有的任务都划分成三类Job,交给不同的处理单元,也就是Tiler,顶点/像素着色器。下一层,按照像素块为单元,又可以把整个屏幕分成很多像素点,也就是线程。在同一瞬间,每个着色器上都可以跑多个线程,这些线程的组合又被称作一个Warp。而提高计算密度的秘密,就在于在一个核内塞入更多的线程数。
再下层,具体到每一个着色器里面的执行引擎,每个时钟的输入是一个程序块Clause。Clause就是某段既没有分支也没有访存的程序,当所有的输入数据都已经从内存读取并存放于寄存器后,这段程序会被无间断执行,直到结果输出。执行过程中,临时寄存器会被用来解决通用寄存器不够用的问题。而当输入数据还未取到,那么就切换到另一个准备就绪的程序块。

所有这些任务,Warp和Clause的管理,需要有专门的硬件来做,以保持整个流水线利用率的最大化。
总之,只要是一直出现在图形流水上的工序,操作固定,计算量稳定,就可以用专用硬件单元来做,并不会浪费,相反还更省功耗面积。而计算变化较大的部分,就可以交给通用计算单元。
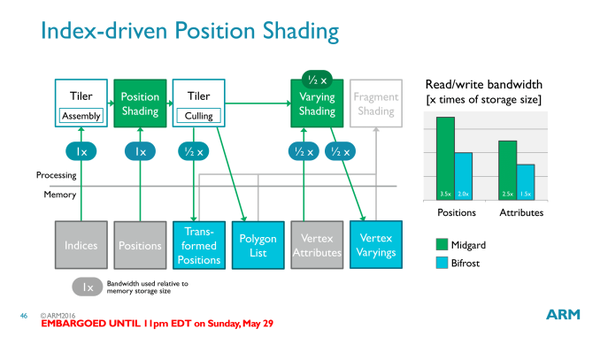
确定了通用和专用单元,接下来需要优化渲染流程,并调整硬件。先看顶点计算,如上图。在生成三角形列表的时候,有些三角形代表着背面,那只要算出法向量,那么就可以直接确定是否抛弃,省掉输出。
更进一步,如果根据顶点的远近关系,做某些简单计算,直接可以得出某些三角形被完全覆盖,那么也可以直接抛弃。在之后的像素渲染以及合成中,可以完全省掉处理。这被称作Early-Z。不过这还存在一个限制,在多个绘制函数Draw call中,如果命令被先后发送到GPU,不同函数间不容易做early-Z优化,因为如果要保留上一个同一区域绘制函数的结果一起做优化,可能需要花更大的代价。但是其块渲染的任务却可以等到所有绘制函数都完成后再开始。在这种情况下,从后往前画的绘制函数区,就不容易优化,而从前往后画的直接就能完成覆盖。这被称为forward killing,需要图形引擎预先计算出物体的深度信息,在生成脚本阶段就做好预判,提高渲染效率。
以上优化并不能解决所有的三角形覆盖问题,还可以再进一步。在像素渲染阶段,得到像素点对应的三角形以及深度信息后,一样可以抛弃被遮住的三角形,只计算被看到的那个三角形的颜色和光照,纹理,同样也免了后续的混合。这一步中的操作被称为TBDR,延迟块渲染。这是可以甚至是跨越Draw call的。如果顶点数足够少,被覆盖的三角形足够多,Early-Z和TBDR可以极大的减少像素渲染计算量。
在合成阶段,我们还可以做一个优化,就是在输出最终的块内容时,对整个区域计算一个CRC值.如果是16x16的块,其CRC大小通常只有1%,1080p的屏幕是100K字节左右。在下一次渲染时,我们再从DDR甚至内部缓存读出这个CRC值,来判断是不是内容有变化。如果没有,那直接放弃输出,节省带宽。不过,之前所做的渲染计算还是没法节省。
如果知道屏幕有一块区域在一段时间内不会有内容变化,那我们可以预先就告诉GPU,让它把这块区域从像素渲染里直接取消,从而免掉上一段中的计算。不过这需要和显示模块一起配合完成。
类似的渲染流水层面的优化还有很多,几乎每一步都能找出来。
在综合了所有的优化之后,我们终于做出了一个初始GPU。其中计算引擎,面积50%左右,占了一半,材质单元,面积大概在20%,其余所有的加起来30%。显然,优化的核心应该放在前两块。这其实又引出了图形处理器的一个奋斗目标:更高的计算密度。前面提到过,计算密度的定义,在以UI为主的低图形处理器上以像素输出率来衡量,在以游戏为主的高端上以浮点密度来衡量。
要提升UI像素输出密度,在合成单元能力固定的情况下,计算单元不重要,材质单元必须与输出能力匹配,一般是像素材质比1:2或者1:1。1:2的比例能做到两个材质点混合为一个后,配合一个像素输出,这在有些UI场景下很有用,提升了一倍的像素输出率。但是反过来,如果用不到,那多出来的材质单元面积就是浪费。具体是什么比例,只能见仁见智。
要提升浮点密度,方法也不难,就是堆运算单元,然后匹配上相应的图形处理器固化硬件,指令,缓存和带宽。
在具体设计运算单元的时候,还是有些考量的。之前,ARM一直使用SIMD+VLIW的结构。也就是说,以一个像素为一个线程,以其RGBA四个维度为矢量,形成一个32位数据的SIMD指令。然后,尽量找出可以并行的6个线程,放到一起并行。这6个线程分别是向量乘,向量加,标量乘,标量加,指令跳转还有查表。其实就是对应了运算单元的设计,如下图:
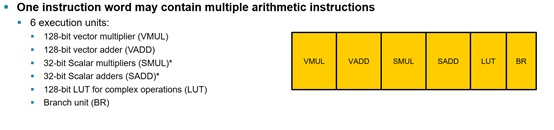
由于Mali是基于块渲染的,一个块内有16x16个像素,也就是256个线程,这些线程可以处于不同的程序段,有些在计算深度,有些在计算颜色。如果线程管理器能够一直找到这样的6个像素,对应不同的运算单元,把这些单元一直排满,那自然可以得到最高的单元利用率。可惜事与愿违,这样的高利用率场景并不好找,很多的时候是只有矢量单元被用上了,其余的都空着。
于是,Mali画风一转,把上图的标量乘和加去掉,且放弃VLIW,从而把指令跳转单元抽出来。最后形成了一个新的处理单元,如下图:

这里,一个128位宽的乘加和同样宽度的加法单元承担了之前标量和向量乘加,而查表运算也和加法单元混合在一起。和之前完全不同的是,这里的输入始终是128位宽的单个指令,而不是VLIW的6条指令,从而提高计算单元利用率。每时钟周期进来的数据,只能到FMA和ADD/TBL单元中的一个,没法同时进去,某种程度上减少了面积的有效利用率。

为了配合这一设计,Mali还做出了一个新的调整,如上图。由之前的按照像素点的RGBA四通道的矢量运算方式,改成四个像素各抽取一个颜色通道,塞到上面的FMA,同时运行四线程。由于大部分情况下,一个块上的256个像素的相同通道总是做一样的计算,保证了这个设计的高利用率。如果相邻四个点每个通道的运算都不一样,那效率自然会降低。
有些GPU还有另外一种运算单元形式:

在这里,乘加被放在小单元,比例更高;大单元除了乘加,还有查表,比例低;跳转单元单独放。这样可以使得计算单元比例更合理,面积利用率更高。
确定了计算单元的能力之后,有没有一个统一的方法,来精细的调整每个配套模块的比例呢?答案是有,先确定跑分标准,然后细化成子测试,最后在模型上统计出来:
目前移动上比较流行的标准是GFXBench,主流的有三个版本,2.x,3.x和4.x。每一个版本都有侧重,比如2.0侧重三角形生成,3.0侧重计算单元与材质,4.0侧重计算。Antutu也是一个标准,目前侧重阴影和三角形生成率。有时候,芯片和手机公司还会统计出主流的游戏,在芯片或者仿真平台甚至模型上跑,以期得到下一代GPU对计算能力的需求。
定下了标准跑分,接下去就是细化成更小的目标,是三角形,顶点,像素,材质,ZS,Varying,混合还是带宽要求。然后,在模型上,把这些细化需求翻译成PPA,给到每一个小模块,看看是不是还有压缩的空间。这是最底层的优化。
经历过上面的打磨之后,我们得到了一个更好的GPU。那是不是就没什么好改进了呢?还不够。从应用角度还是不停地有需求进来:
DRM,数据压缩, 系统硬件一致性,统一内存地址,AR/VR/AI,CPU驱动。
首先,是版权保护,播放有版权的内容时,解密和解码都是在保护世界完成的,而UI的操作可能需要GPU的参与。这块在安全篇中有论述,此处不再展开。
第二,所有的媒体和材质数据都可以进行压缩,以节省系统带宽和成本。上文讨论过,此处不再展开。
第三,系统双向硬件一致性问题。要实现GPU和CPU以及加速器之间数据互访而不用拷贝和刷新缓存,就需要支持双向一致性的总线,比如CCI550,这在基础篇已经讨论。最新的OpenCL2.0和Vulkan都支持这一新的特性。在数据交互非常频繁地情况下,可以节省30%甚至90%左右的运行时间。
不幸的是,由于OpenGL ES天生就不支持这个特性,所以对于目前绝大多数的图形应用,哪怕接了CCI550,GPU也是不会发出任何带有监听操作的传输的。这种情况到了Vulkan以后会有改善。
第四,和CPU的统一物理地址。在桌面上,CPU和GPU的访问空间是完全独立的,而移动处理器从开始就统一了物理地址。当然,他们的页表还是分开的。在基础篇我们就讲过,统一的好处就是省带宽和成本,恰好块渲染的GPU的特点就是带宽相对较小。剩下的只要把总线和内存控制器的调度做好,保持内存带宽的利用率在一个相对较高的水平就行。
硬件一致性和统一地址有一个应用就是异构计算,CPU/GPU/DSP/加速器均可使用相同物理地址,并且硬件自动做好一致性维护。具体的计算可以是图像,也可以是语音。不过很可惜,在高端手机上,如果把所有的处理单元都跑起来,那功耗肯定是远高于2.5瓦的,甚至可以到10瓦。而且受限于GPU的软件,双向硬件一致性也没有得到广泛应用,目前最多是做一些ISP后处理。
第五,AI。在AI篇我们提到。如果AI跑在GPU,那肯定需要支持INT8甚至更小的乘加操作,这对于GPU没有任何问题。不过,AI更需要的参数压缩,Mali的GPU并没有原生支持。这样一来,本来的四核MP4差不多是用2个128位AXI接口,只能提供32GB/s左右的读带宽。不压缩的话,也就能支持64GB INT8的计算量,远小于GPU四核一般在1Tops的INT8计算量。
第六,VR。VR对于GPU来说有相当大的关系。首先,由于左右眼需要分别渲染,并且分辨率需要4K以上,这就对GPU性能提出了1080p时8倍的需求,对系统带宽也是一种考验。细分下来,有这样一些需求:
左右眼独立渲染:如下图,VR场景中的三角形或者顶点部分,左右眼是共享的,但是旋转和之后的像素处理,必须是分开的。由于顶点渲染只占整个工作量的10%,所以能节省的计算量相当有限,只是可以减少些顶点材质的读取。
畸变矫正:这个可以在顶点渲染最后加一步矩阵乘法,轻易做到。不过,由于这个操作夹杂在顶点和像素渲染之间,所以还是需要额外的API来提醒硬件。
异步时间扭曲ATW:其原理是当发现计算下一帧需要的时间超出预期,索性就不去计算了,而是把当前帧按照头部移动方向做一个插值,造一个假的图像。这样,就需要一个API,以估算下一帧生成时间,还需要一个额外的定时器,根据显示模块的Vsync信号计算剩余可用时间。如果时间不够,会直接拿取插值后的图像,而这个图像计算也在GPU,计算量小且优先级很高,保证赶上Vsync信号。

多视图渲染Multi-View:也就是对于视图的非焦点区域,使用低解析度,焦点区域,高解析度。要做到这点,使用高解析度,总的计算量可以降低一半左右。实际运用中,由于焦点区域的确定需要眼球跟踪,比较复杂,所以会采用中心区域来替代。
Front buffer:原来的桌面GPU设计中,显示缓冲分两块,front buffer和back buffer交替输出,当中用Vsync做同步,按帧输出。现在只使用一块front buffer,以hsync为同步标志,按行输出,这样,整个帧的渲染时间并不变,但是粒度变细。对于GPU来说,这需要加入按行渲染的次序关系。这和上一个Multi-View原理并不相同,前一个虽然分成了多视图区域,但是并不规定渲染次序,块与块之间还是乱序的,只不过最后输出的时候都是渲染完成好的。而Front buffer相当于在行与行间插入了一个同步指令,如果纯粹交由硬件来调度,很可能会降低性能。也可以GPU的frame buffer保持原样,用显示模块来做这个事情,更容易实现。
第七,AR。在AI篇中,我们提到,GPU其实也在做渲染,没有什么特殊的需求,除非把识别的工作交给GPU来做。
还有很重要的一点,就是GPU驱动对CPU造成的负载。在OpenGL ES上,由于API本身的限制,很多驱动任务必须是一个线程内完成的。这就要求必须在一个CPU核上跑。GPU核越多,单个CPU核的负载越高。在Mali G71之前,差不多10-12个900Mhz的GPU核就需要一个跑在2.5Ghz的A73来负责跑驱动,其他的大核小核再多都帮不上忙。但事实上,由于大核的能效比小核差了4到5倍,所以一定是小核来跑驱动更省电。反过来,如果使用了更多的GPU核,那最后的瓶颈会变成单个CPU的性能,而不是GPU。解决的方法有几个,一是使用Vulkan。Vulkan在设计阶段就考虑到了这个问题,天然支持CPU多线程的负载均衡,能很好的解决这个问题。我曾经看到过一款桌面GPU,在16核A53的服务器上只发挥出x86服务器上的30%性能,而从Open GL换成Vulkan后,才把瓶颈转移到GPU自身。
不过,虽然Vulkan已经是谷歌钦定的下一代图形接口,基于Vulkan的图形应用流行可能还需要3-5年时间。另外一个可行方法就是优化GPU驱动软件本身,并把一部分的软件工作交给硬件来完成,比如内存管理模块的硬件化,还可以使用一个MCU和内嵌缓存来翻译和处理命令序列,替代CPU的工作。这个MCU可以只跑在几百兆,功耗十几毫瓦,远低于小核的100多毫瓦,更低于大核的几百毫瓦。
最后,做出来的GPU在PPA上还得和高通的Adreno对比(苹果的GPU在计算密度上也不如高通)。目前世界上所有的块渲染的GPU中,高通是能效比和性能密度最好的,计算密度比最新的Mali GPU高30%以上,能效高50%,目前已经是每个Warp32线程了。其中,有几个地方是Mali难以弥补的,比如系统缓存,针对少数几个配置的前端优化(Mali需要兼顾1-32核),以及确定的后端制程和优化。这里的每一项都可以提供5%-10%的优化空间,积累起来也是不小的优势。
总之,GPU的设计是一个不断细化的过程,选好大方向,把标准跑分明确,再注意新的趋势和需求,把模型和验证流程跑熟,剩下的就是不断打磨了。
推荐阅读
授权转自知乎,欢迎关注Arm攒机指南专栏,后续还有AI等相关篇章。

